LLM 大模型发展简史
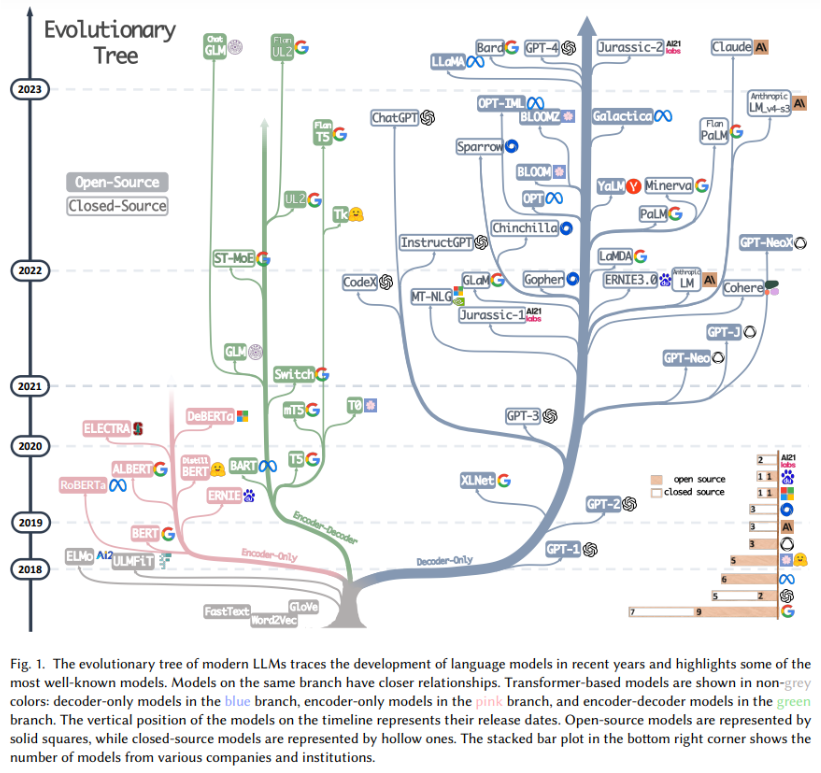
(人工智能 LLM 大模型发展图 2018 - 2023,https://arxiv.org/pdf/2304.13712.pdf)
大模型 LLM(Large Language Model,大规模预训练模型)是人工智能领域近十年最具突破性的技术之一。以下是其发展历程的关键节点和阶段简单的梳理:
一、技术奠基期(2017年之前)
-
早期神经网络与深度学习基础
- 1950-1980年代:感知机、反向传播算法等基础理论奠定神经网络框架。
- 2012年:AlexNet在ImageNet竞赛中夺冠,深度学习进入爆发期。
- 2014年:Seq2Seq模型(用于机器翻译)和注意力机制(Attention)提出,为后续模型设计铺路。
-
预训练思想的萌芽
- 2015年:Word2Vec、GloVe等词嵌入技术普及,通过预训练词向量提升下游任务效果。
- 2017年:Transformer架构诞生(Google《Attention Is All You Need》),彻底改变了序列建模方式,成为大模型的核心技术基础。
二、预训练模型兴起(2017-2018年)
第一代预训练模型
- 2018年:
- BERT(Google):基于Transformer编码器,通过掩码语言建模(MLM)实现双向语义理解。
- GPT-1(OpenAI):基于Transformer解码器,采用自回归生成式预训练,参数规模1.17亿。
- 核心突破:通过海量无标注数据预训练+任务微调(Fine-tuning),模型泛化能力显著提升。
三、参数规模跃升(2018-2020年)
模型参数突破十亿级
- 2019年:
- GPT-2(OpenAI):参数15亿,首次展示Few-Shot Learning能力(无需微调即可完成多任务)。
- T5(Google):将自然语言任务统一为“文本到文本”框架,参数达110亿。
- 2020年:
- GPT-3(OpenAI):参数1750亿,Few-Shot/Zero-Shot能力颠覆传统AI开发范式,引发行业震动。
- Turing-NLG(微软):参数170亿,推动大模型落地应用。
四、多模态与通用智能探索(2020-2022年)
-
从单一模态到多模态融合
- 2021年:
- CLIP(OpenAI):图文跨模态对比学习,实现零样本图像分类。
- DALL·E(OpenAI):文本生成图像,开启多模态生成时代。
- 2022年:
- Stable Diffusion:开源文生图模型,推动AIGC普及。
- Florence(微软)、BEiT-3(微软):多模态统一建模。
- 2021年:
-
大模型生态爆发
- 开源社区活跃:Hugging Face平台推动模型共享,Meta发布LLaMA系列开源模型。
- 垂直领域应用:医疗、法律、编程等场景涌现专用模型(如Codex、Galactica)。
五、通用人工智能(AGI)的探索与争议(2023年至今)
-
技术突破与产品化
- 2023年:
- GPT-4(OpenAI):支持多模态输入,逻辑推理能力显著提升,参数规模未公开。
- PaLM 2(Google)、LLaMA 2(Meta):优化训练效率与安全性。
- Claude 2(Anthropic)、Bard(Google):对话模型竞争白热化。
- 国内进展:百度“文心一言”、阿里“通义千问”、华为“盘古”、智谱AI“GLM”、“DeepSeek”等。
- 2023年:
-
技术争议与挑战
- 算力与成本:千亿级模型训练需数百万美元投入,中小企业难以参与。
- 伦理与安全:生成内容偏见、虚假信息、版权问题引发监管关注。
- 环境成本:大模型训练碳排放高,可持续发展受质疑。
六、未来趋势
- 模型高效化:降低训练成本(如MoE架构、模型压缩技术)。
- 多模态融合:视频、3D等多维度数据建模。
- 具身智能:结合机器人、传感器实现物理世界交互。
- 可信AI:提升可解释性、安全性和伦理对齐。
七、总结
大模型的发展从单一文本理解到多模态交互,从实验室研究到产业落地,不断突破技术边界,但也面临资源垄断、安全风险等挑战。
未来,技术普惠与伦理治理的平衡将成为关键议题。
八、参考
- https://arxiv.org/pdf/2304.13712.pdf Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond
- https://research.google/pubs/attention-is-all-you-need/ Attention is All You Need
== just do it ==

