kafka学习笔记02-kafka消息存储
kafka消息存储
broker、topic、partition
kafka 的数据分布是一个 3 级结构,依次为 broker、topic、partition。
也可以理解为数据库的分库分表,然后还有记录这么一个结构。
broker 可以看作是 kafka 集群中的一个节点,可以理解为一台服务器,是对 kafka 集群中节点的抽象。多个 broker 就组成了 kafka 分布式集群。
topic 主题,可以理解为分类、队列等等,是对 broker 的进一步细分,便于对数据的管理。topic 可以分布到不同的 broker 上。
一个 topic 主题可以分为多个 partition 分区。
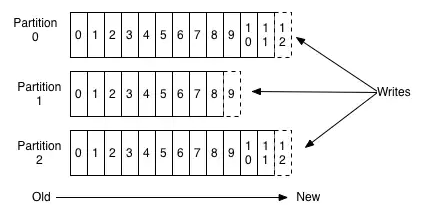
partition分区配置
在创建 topic 时,可以在配置文件中($KAFKA_HOME/config/server.properties)设置 partition 的数量。也可以在 topic 创建后修改 partition 的数量。
# The default number of log partitions per topic. More partitions allow greater
# parallelism for consumption, but this will also result in more files across
# the brokers.
num.partitions=3
kafka 中的消息数据最终都是存储在 partition 里。
partition分区
partition 是以文件的形式存储数据的。
文件存放位置,可以通过配置文件 server.properties 中的 log.dirs 指定。
文件命名,假如你新建了一个名为 student-log 的主题,partition 指定为 3 个,那么目录结构为:
student-log-0
student-log-1
student-log-2
在 kafka 中,同一个 topic 下有多个不同的 partition,每个 partition 就是一个目录。可以看到 partition 的目录命名规则:
topic名称+有序序号
第一个序号从 0 开始,最大的序号为 partition 数量减 1
partition 是实际物理上的概念,而 topic 是逻辑上的概念。可以理解为实际存储数据里并没有 topic 的文件夹,而只有 partition 的目录文件。
那 partition 目录里又有什么东西?
真正存储的数据。
而且它对 partition 又进一步的细分为 segment。segment 又是什么东西?
可以这样理解,一般存储为文件系统,如果只有一个文件来存储数据,那么随着时间越长数据越来越多,文件大小就会变得越来越大,必然会导致写入、查询文件都变得越来越慢。
就像写一个日志系统,文件大了,就会按照一定规则将大文件分割成小文件来进行读写。
实际就是一种细分的思想。
每个 partition(目录)相当于一个大型文件被细分到多个大小相等的 segment 文件中。
每个 segment 中的消息数量不一定相等。
segment存储
segment 的文件配置项:
# segment大小,默认为 1G
log.segment.bytes = 1024*1024*1024
# log.roll.{ms,hours} ,滚动生成新的segment的最大时长
log.roll.hours=24*7
# segment 保留文件的最大时长,超时将被删除
log.retention.hours=24*7
segment 文件是由 2 部分组成,分别为 .index 和 .log 结尾的文件:
- index 结尾文件表示索引文件。
- log 结尾文件表示数据文件。
这个 2 个文件的命名规则:
partition 全局的第一个 segment 从 0 开始,后续每个 segment 文件名为上一个segment 文件最后一条消息的 offset 值。
数值大小为 64 位,20 位数字字符长度,没有数字用 0 填充
比如:
00000000000000000000.index
00000000000000000000.log
00000000000000160420.index
00000000000000160420.log
00000000000000207460.index
00000000000000207460.log
00000000000000160420.index
00000000000000160420.log
上面 2 个文件中的 160420 表示该文件中 offset 从 160421 开始。那么00000000000000000000.index (.log) 的 offset 结束位置就是 160420。也就是命名规则,后面每个 segment 文件名为上一个 segment 文件最后一条消息的 offset 值。

如图所说示,.index 索引文件存储了索引数据,.log 文件存储了大量的消息数据。
索引文件中 [3, 348] , 3 在 .log 文件中表示第 3 个消息,那么在全局 partition 表中表示为 160420 + 3 = 160423。
348 表示该消息的物理偏移地址。
怎么在 .log 文件中查找数据呢?
比如查找 offset = 160428 的消息数据。
先查找 segment 文件:
00000000000000000000.index 为最开始的文件,
00000000000000160420.index 为第二个文件,它的起始位置偏移量 offset: 160420+1
00000000000000207460.index 为第三个文件,它的起始位置偏移量 offset: 207460+1
所以 offset = 160428 就落在了第二个文件中。
从图中可以看出,索引并不是为每一条 message 都建立了索引,而是每隔一定字节数建立索引,这样避免索引占用太多空间。缺点是需要一次扫描文件并查找。不过可以根据二分查找快速定位文件位置。
在根据索引文件中的 [8, 1325] 定位到 00000000000000160420.log 文件中 1325 的位置进行读取。
开始读取后,那何时读取消息结束?
一条数据读到哪里结束才能完整的读取一条数据,而不读取多余的数据。这就涉及到一条消息的消息体结构了。
每一条消息都有固定的消息结构,就好像 http 消息体有一个结构一样,kafka 中消息体结构为:
offset(8 Bytes)- 消息偏移量
message size(4 Bytes)- 消息体的大小
crc32(4 Bytes)- crc32 编码校验和
magic(1 Byte)- 本次发布Kafka服务程序协议版本号
attributes(1 Byte)- 表示为独立版本、或标识压缩类型、或编码类型
key length(4 Bytes)- 消息Key的长度
key(K Bytes)- 消息Key的实际数据
payload(N Bytes)- 消息的实际数据
补充说明:
上面数据格式是 kafka 0.11 前的格式,具体说明看这里:Old Message Format
根据消息体结构就可以确定一条消息的大小,就可以读取到哪里截止。
kafka 0.11 以后的格式是啥,可以看下面的介绍。
消息格式
Record Batch
kafka 0.11 后的消息格式,消息集合对应的类,clients/src/main 目录下:
kafka v3.0
org.apache.kafka.common.record.DefaultRecordBatch
org.apache.kafka.common.record.RecordBatch
// common.record.DefaultRecordBatch.java
/**
* RecordBatch implementation for magic 2 and above. The schema is given below:
*
* RecordBatch =>
* BaseOffset => Int64
* Length => Int32
* PartitionLeaderEpoch => Int32
* Magic => Int8
* CRC => Uint32
* Attributes => Int16
* LastOffsetDelta => Int32 // also serves as LastSequenceDelta
* FirstTimestamp => Int64
* MaxTimestamp => Int64
* ProducerId => Int64
* ProducerEpoch => Int16
* BaseSequence => Int32
* Records => [Record]
RecordBath 里包含很多 records 。
结构图示:
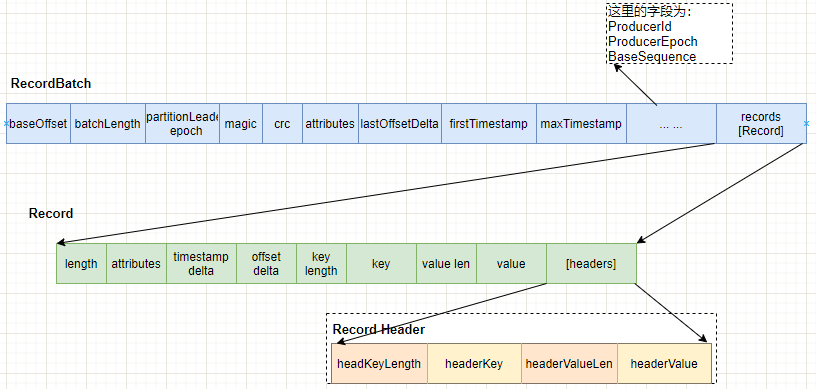
| 字段 | 类型 | 说明 |
|---|---|---|
| baseOffset | int64 | 当前 RecordBatch起始位置。Record 中的 offset delta与该baseOffset相加才得到真正的offset值 |
| batchLength | int32 | RecordBatch 总长 |
| partitionLeaderEpoch | int32 | 标记 partition 中 leader replica 的元信息 |
| magic | int8 | 版本的魔术值,V2版本魔术值为2 |
| crc | int32 | 校验码, 效验部分从开始到结束全部数据,但除了partitionLeaderEpoch值 |
| attributes | int16 | 消息属性,0~2:表示压缩类型 第3位:时间戳类型 第4位:是否是事务型记录 5表示ControlRecord,这类记录总是单条出现,它只在broker内处理 |
| lastOffsetDelta | int32 | RecordBatch 最后一个 Record 的相对位移,用于 broker 确认 RecordBatch 中 Records 的组装正确性 |
| firstTimestamp | int64 | RecordBatch 第一条 Record 的时间戳 |
| maxTimestamp | int64 | RecordBatch 中最大的时间戳,一般情况下是最后一条Record的时间戳,用于 broker 判断 RecordBatch 中 Records 的组装是否正确 |
| producerId | int64 | 生产者编号,用于支持幂等性(Exactly Once 语义) |
| producerEpoch | int16 | 同producerEpoch,支持幂等性 |
| baseSequence | int32 | 同上,支持幂等性,也用于效验是否重复Record |
| records | [Record] |
幂等性的详情可以参考这里:Exactly+Once+Delivery+and+Transactional+Messaging
record
kafka 0.11.0 版本开始使用的消息格式。
kafka v3.0。
Record消息,clients/src/main 目录下 :
org.apache.kafka.common.record.DefaultRecord
org.apache.kafka.common.record.Record
// common.record.DefaultRecord.java
/**
* This class implements the inner record format for magic 2 and above. The schema is as follows:
*
*
* Record =>
* Length => Varint
* Attributes => Int8
* TimestampDelta => Varlong
* OffsetDelta => Varint
* Key => Bytes
* Value => Bytes
* Headers => [HeaderKey HeaderValue]
* HeaderKey => String
* HeaderValue => Bytes
recocd 消息结构图:
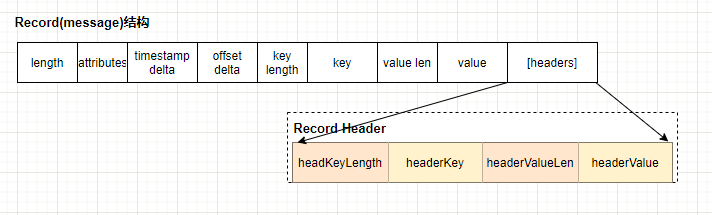
可以参考这里,kafka doc record:https://kafka.apache.org/documentation/#record
Record 消息中的关键字,字段类型好多都是采用了 varints,动态类型,这样有利于kafka根据具体的值来确定需要几个字节保存。
record 消息字段说明:
| 字段 | 类型 | 说明 |
|---|---|---|
| length | varints | 消息中长度 |
| attributes | int8 | unused,没有使用了,但仍占据了1B大小 |
| timestamp delta | varlong | 时间戳增量。一般占据8个字节 |
| offset delta | varint | 位移增量 |
| key length | varint | key的长度 |
| key | byte[] | key的值 |
| valuelen | varint | value值的长度 |
| value | byte[] | value的实际值 |
| headers | [header] | 头部结构,支持应用级别的扩展 |
header 头部结构组成
| 字段 | 类型 | 说明 |
|---|---|---|
| headerKeyLength | varints | 头部key的长度 |
| headerKey | string | 头部 key值 |
| headerValueLength | varint | 头部值的长度 |
| value | byte[] | header的值 |
header 更多信息可以参考这里:
https://cwiki.apache.org/confluence/display/KAFKA/KIP-82+-+Add+Record+Headers
根据这篇文章总结:
v2 版本的消息结构设计,不仅增加了一些功能如事务、幂等等功能,也用变长类型优化了整体空间存储,当然还有压缩算法。
其中字段类型设计参考了Protocol Buffer,引入变长类型(Varints)和 ZigZag 编码。详情查看
https://developers.google.com/protocol-buffers/docs/encoding
这些优化都是为了kafka更好用而做的设计上的努力。
kafka 的一些消息协议、消息格式、api,protocol 可以参考这里,内容比较详尽:
A Guide To The Kafka Protocol
参考
kafka protocol
kafka messages
kafka old message format
kafka github
kafka 消息格式演变
kafka-producer-consumer-overview

 浙公网安备 33010602011771号
浙公网安备 33010602011771号