kafka学习笔记01-kafka简介和架构介绍
一、kafka介绍
kafka 最开始是 Linkedin 用来处理海量的日志信息,后来 linkedin 于 2010 年贡献给了 Apache 基金会并成为了顶级项目。
后来开发 kafka 的一些人出来创立了一家公司 confluent,专门从事 kafka 的开发维护和在它之上提供各种服务。
现在 kafka 把它定义为一个分布式数据流处理平台。
kafka 流平台3大特性:
- 发布和订阅流式的记录数据。这一方面应用就是消息队列。
- 储存流式的记录数据,并且有较好的容错性。
- 实时大数据处理,可以在流式记录产生时就进行处理,与大数据系统结合,比如Spark、Flink等。
它的应用场景:
- 当作消息队列,它可以构造实时流数据管道,它可以在系统或应用之间可靠地存储、获取数据。比如存储各种日志、各种各种应用信息、商品数据等。由于 kafka 高吞吐高性能,还能起到错峰、削峰、缓冲、解耦等等功能。
- 构建实时流式应用程序,与大数据系统集成。
很多开源的大数据系统,比如storm,spark,flink等都可以与kafka集成,然后进行大数据处理。
kafka 也可以当作一个消息队列,那么,它是一个分布式、高吞吐量、可持久存储、高可用的消息队列。
kafka 的一些特性:
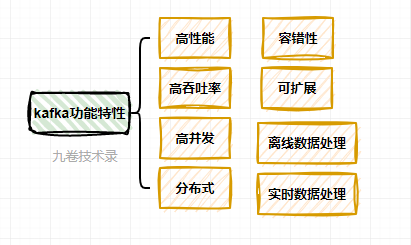
- 高性能:
kafka 可以每秒处理几十万条消息,延迟最低时却只有几毫秒。
能高性能的消费消息。时间复杂度为 O(1) 的数据持久化能力。 - 高吞吐率:
高吞吐率,在廉价机器上也能实现每秒 100k 条消息的传输能力。 - 分布式
支持Kafka Server间的消息分区,及分布式消费,同时保证每个partition内的消息顺序传输 - 容错性
允许集群中节点失败。若副本数量为 n,则允许 n-1 个节点失败。 - 可扩展
kafka 支持热扩展。 - 高并发
支持几千个客户端同时读写的能力。 - 离线和实时数据处理
同时支持离线数据处理和实时数据处理
二、kafka总体架构图
kafka 消息队列最简架构图:

kafka 总体架构图:
把上面的架构简图进一步展开,来看看 kafka 更复杂的架构,
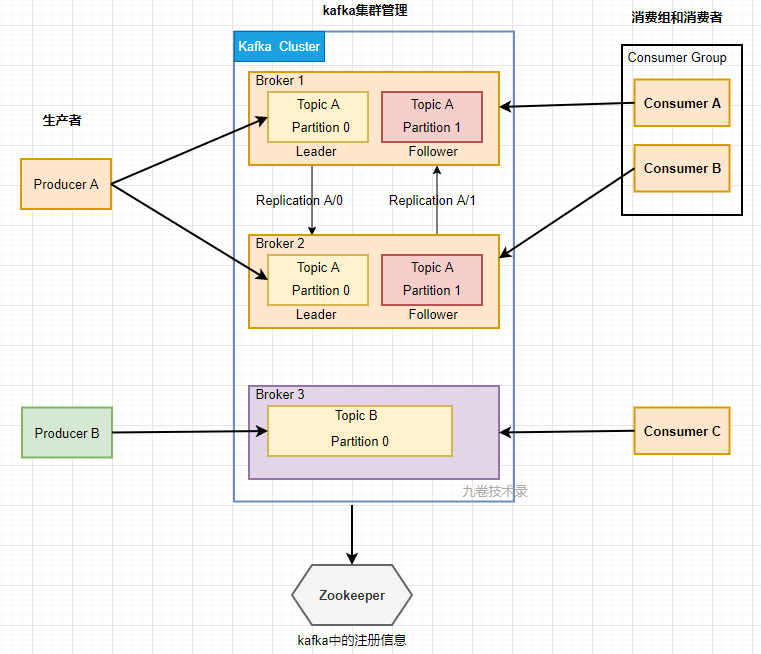
从上图可以看出,kafka 架构主要由4部分组成,生产者,kafka 集群,消费者,zookeeper(现在 kafka 要逐渐取消对 zookeeper 的依赖)。
生产者producer生成消息发送到 kafka 集群,实际上是发送数据到 Topic 主题下的不同 Partition 分区里。消费者consumer从这里消费消息。
三、kafka 中的各种概念
从上面 kafka 架构图,来看看 kafka 里的各种概念,
- Producer:
消息和数据的生产者,负责发送消息到指定的 Broker 下的 Topic 主题里。
- Consumer:
消费者,去订阅的 Topic 拉取消息消费。
- Consumer Group:
消费者组,消费者组内每个消费者负责消费不同分区的数据,提供消费能力。一个分区只能由一个组内消费者消费,消费者组之间互不影响。消费者组相当于一个逻辑上的订阅者。
它可以将 consumer 自由的进行分组而不需要多次发送消息到不同的 Topic。
- Broker:
kafka 集群的每一节点被称为一个 Broker。一个 kafka 集群由多个 Broker 节点组成。每个 Broker 里可以包含多个 Topic(主题)。一个 Topic 可以包含一个或多个 Partition 分区。
- Topic:
Topic(主题) 是在 Broker 里。同一个 Topic 的消息可以分布在一个或多个 Broker 里。一个 Topic 可以包含一个或多个 Partition 分区。我们可以根据 Topic 对消息进行分类。也可以理解为一个 Topic 就是一个队列。
- Partition:
分区,实际存数据的地方。每个 Partition 里存储一个有序队列。它不保证一个 Topic 的整体(多个 partition 间)有序。
分区也是实现 kafka 可扩展性的一个设计,比如一个非常大的 Topic 可以分布到多个 Broker 上,一个 Topic 可以分为多个 Partition。
partition 分区是一个顺序写磁盘。顺序写磁盘效率比随机写内存要高,这也保障 Kafka 吞吐率。
- Replica:
副本,数据的一个备份。当集群中某个节点发生故障时,保障该节点上的 Partition 数据不丢失。
kafka 提供的这个副本机制,一个 Topic 的每个分区都有若干副本,一个 Leader 和若干个 Follower。
HW (High Watermark),最高水位标记,每个副本都有一个。该标记作用是表示该副本已经成功复制了所有消息,因此这个标记之前的所有消息都已经被消费者消费了
LEO (Log End Offset),表示该副本日志文件最后一个字节的偏移量。这个偏移量会随着时间推移而不断增加。
- Leader:
生产者发送的数据都是发送到 Leader,消费者消费的数据也是 Leader。可以形象看做是多个副本的“主”副本
- Follower:
Follower 副本中的数据会实时从 Leader 中同步过来。如果 Leader 发送故障,某个 Follower 会成为新的 Leader
- Controller
Kafka 集群中的其中一个服务器,用来进行 Leader 选举以及各种 Failover。
- Offset:
消费者消费的位置信息,数据消费到什么位置。当消费者挂掉重新恢复消费时,可以从这个位置继续消费。
老版本的 kafka offset 是存储在 zookeeper 中,但 zookeeper 并不适合大批量的频繁写入操作,新版 Kafka 已推荐将 consumer 的位移信息保存在 kafka 内部的 topic 中,即__consumer_offsets topic,在消费失败时可以重置 offset 达到重新消费的效果。
- Epoch
后面引入的 Epoch,当 Leader 副本发送切换时,就会增加分区的 Epoch 值。当一个 Follower 副本发现自己的 Epoch 值比 Leader 副本的 Epoch 值更小,就会认为自己数据已经过时,需要立即从 Leader 副本复制数据。
- zookeeper:
zookeeper 帮助kafka管理和存储集群中的信息,实现 kafka 集群高可用。比如上文中的 Offset 消费位置信息,kafka 各个节点的状态信息。
(Kafka 在未来的 2.8 版本将要放弃 Zookeeper,解除对它的依赖)
四、kafka 分布式集群
从上面的架构图可以看出,kafka 集群里涉及的 3 个概念,broker,topic,partition。
broker 是 kafka 集群的一个节点,可以理解为是一台服务器。然后每一个节点可以有多个 topic。topic 里的 partition 才是具体存放数据地方。
大家看一看,这里是不是一个 3 级结构。
一个 kafka 集群可以有多个 broker 节点,每个节点可以有多个 topic,每个 topic 又可以分为多个 partition 分区,每个 partition 分区在物理上对应一个文件夹,在该文件夹下存储该 partition 的所有消息和索引文件。
Topic(主题)和Partition(分区)
每一个 topic(主题),它可以包含多个 partiton,kafka 集群会维持一个分区日志,如下图:
- topic 和 partition 关系图:

- topic、partition 和 partiton 里的 log 关系图:
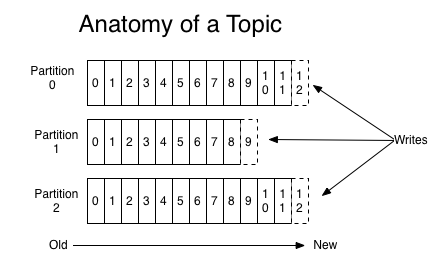
每个分区都是一个有序且顺序不可变的记录集,日志记录会不断增加到它的末尾。
分区中的每一条记录都会分配一个 id 号来表示顺序,称为 Offset,Offset 用来唯一标识分区中的每一条记录,它也叫消息偏移量。
partition 中的每条记录(Message)包含三个属性:
Offset,messageSize 和 Data。
messageSize 消息的大小,Data 消息的具体内容。
一个 topic 可以分为多个 partition(如上图),partition 可以存放在不同的 broker 中,就是将数据分布存储。
kafka 可以设置保留记录的时间,它有一个配置参数来设置。比如保留 2 天,那么一条记录在发布 2 天后,可以随时被消费,2 天后这条记录会被抛弃并释放磁盘空间。
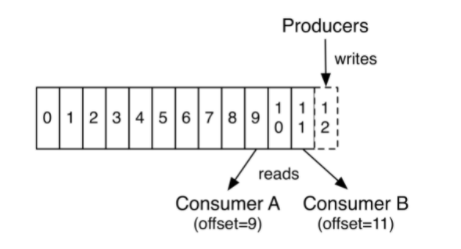
Topic、分区与kafka集群
kafka 集群是一个 Leader、Follower 模型。它的读写都是在 Leader 上进行。Follower 是用来备份 Leader 上的数据。当 Leader 宕机的时候,就可以用 Follower 上的数据继续进行服务。这就是 kafka 高可用的设计。
到这里,肯定有几个问题:
- 集群数据总不能在一台机器上进行读写,数据怎么均匀分布?
- leader 宕机后,follower 怎么选出新的 leader?
- 宕机了,数据会丢失吗?
数据的负载均衡
第一个问题,其实就是数据的负载均衡,怎么进行数据的均匀分布?
在kafka中,最终落地的数据是partition,所以数据的均衡分布也就是怎么把数据均匀分布到 partition 里,也就是数据怎么路由。kafka 会尽量的将整个 parttition 均匀的分布到整个集群上。
同时为了提供kafka的容错能力,也会努力将 partition 的 replica 尽量分散到不同机器上。
kafka 的数据分布算法:
- 将所有 Broker(假设共n个Broker)和待分配的 Partition 排序
- 将第 i 个 Partition 分配到第(i mod n)个 Broker 上
- 将第 i 个 Partition 的第 j 个 Replica 分配到第((i + j) mod n)个 Broker 上
leader 选举
第二个问:怎么进行 leader 选举?
leader 宕机了,怎么在 followers 中选出新的 leader ?
最常用的选举算法,就是少数服从多数(Majority Vote)。但 kafka 并没有采用这种方式。
leader 选举的算法也比较多,比如zookeeper的 zap,raft 的 Viewstamped Replication,还有微软的 PacificA 算法。kafka 用的算法跟微软的算法更像。
kafka 在 zookeeper 中(/brokers/topics/[topic]/partitions/[partition]/state)动态的维护了一个 ISR(in-sync replicas),这个 ISR 里的所有 replicas 都跟上了 leader,也就是 commit 上的消息跟上了 leader,只有在 ISR 里的成员才有被选为 leader 的可能。
Controller 将会从 ISR 里选一个做 Leader。
那什么叫 commit 上的消息跟上 leader?
leader 和 follower 之间复制消息,那 leader 怎么知道复制成功?发送 ack 进行确认。
那是所有的 follower 同步完后才发送 ack,还是只要半数以上同步完成,就发送 ack?
在 kafka 中都不是,kafka 中是 ISR 集合中的 follower 完成数据同步后,leader 就会给 follower 发送 ack。
如果 follower 长时间未向 leader 同步数据,则该 follower 将被踢出 ISR 集合,该时间阈值由 replica.lag.time.max.ms 参数设定。leader 发生故障后,就会从 ISR 中选举出新的 leader。
宕机副本会丢失吗
kafka 集群会对消息进行冗余备份来应对这种情况。
kafka 对消息进行冗余备份,每个分区可以有多个副本,每个副本包含的消息都是一样的。
每个分区副本集合:
- 一个 leader 副本
- 多个 follower 副本
kafka 所有读写请求都由选举出的 leader 提供服务。
follower 副本仅仅是把 leader 数据拉到本地后,同步更新到自己的 log 中。
一般情况下,同一个分区的多个副本是被分到不同的 broker 上,这样所有的 broker 宕机后,可以重新选举新的 leader 继续对外提供服务。
五、参考
- apache intro
- apache design
- Kafka 设计解析(一):Kafka 背景及架构介绍 作者:郭俊
- Kafka 概述:深入理解架构 作者:臧小晶
- Kafka学习之路 (一)Kafka的简介 作者:扎心了,老铁

 浙公网安备 33010602011771号
浙公网安备 33010602011771号