SQL语句分类以及详解
SQL (Structured Query Language)结构化查询语言 语句分类
1)DDL:数据定义语言 关键字有:create(创建),drop(删除) ,truncate(删除表结构,再创一张表),alter(修改)
2)DQL:数据查询语言 关键字有:select
3)DML:数据操作语言 关键字有:insert(插入),update(更改),delete(删除)
4)TCL:事务控制语言 关键字有:begin,savepoint,rollback,commit
5)DCL:数据控制语言 关键字有 :grant,revoke,deny
1. DDL: Data Definition Language
DDL操作数据库:
创建数据库:
create database db
修改数据库:
alter database db add file(
NAME = db2,
SIZE=5MB
)
删除数据库:
drop database db
使用数据库:
use TEST_HZ
DDL操作表结构
创建表:
create table TEST(
id int identity(1,1) primary key , -- 主键自增
cardid int , -- id编号
name nvarchar(50), -- 姓名
sex nchar(2), -- 性别
age int, -- 年龄
address nvarchar(50) -- 地址
)
删除表:
drop table dbo.TEST
修改表:
增加一列:
alter table dbo.TEST add dept nvarchar
删除一列:
alter table dbo.TEST drop column dept
修改列字段类型:
alter table dbo.TEST alter column dept char
2.DML: Data Manipulation Language
Insert 语句 格式:INSERT [INTO] 表名 [字段名] VALUES (字段值)
插入全部字段方式一:
insert into dbo.TEST(cardid,name,sex,age,address,dept) values(100,N'张三',N'女',18,N'中国天津',1)
insert into dbo.TEST(cardid,name,sex,age,address,dept) values(101,N'李四',N'男',33,N'中国天津',2)
insert into dbo.TEST(cardid,name,sex,age,address,dept) values(102,N'王五',N'女',25,N'中国天津',1)
insert into dbo.TEST(cardid,name,sex,age,address,dept) values(103,N'赵六',N'男',32,N'中国天津',1)
insert into dbo.TEST(cardid,name,sex,age,address,dept) values(104,N'陈启',N'女',12,N'中国天津',1)
插入全部字段方式二:
insert into dbo.TEST values(108,N'张三',N'女',18,N'中国天津',1),(109,N'李四',N'男',33,N'中国天津',2),(110,N'王五',N'女',25,N'中国天津',1),(111,N'赵六',N'男',32,N'中国天津',1)
插入部分字段;
insert into dbo.TEST(cardid,name,sex,age) values(112,N'张三',N'女',18)
update 语句 格式:UPDATE 表名 SET 列名=值 [WHERE 条件表达式]
不带条件修改数据,修改所有行:
update dbo.TEST set age=19;
带条件修改数据
update dbo.TEST set age=119 where id =5 ;
一次修改多个列
update dbo.TEST set age=119,address='中国北京' where id =5 ;
delete 语句 格式:DELETE FROM 表名 [WHERE 条件表达式]
带条件删除数据
delete from dbo.TEST where id =5
不带条件删除数据
delete from dbo.TEST
使用truncate删除表中所有记录
truncate table dbo.TEST
truncate和delete的区别:
truncate 相当于删除表的结构,再创建一张表。可以消除自增长。
3. DQL: Data Query Language
select 语句 格式: select 字段名 from 表名 [WHERE 条件表达式]
1 简单查询
select * from dbo.TEST;
select * from dbo.TEST where age>20;
select id,cardid,name from dbo.TEST where id>4;
select id,cardid,name from dbo.TEST where name='王五';
between ..and 表示在两个数之间
select * from dbo.TEST where age between 18 and 30 ;
in 表示或者的关系
select * from dbo.TEST where age in(18,30);
某列数据和固定值运算想
select age+5 from dbo.TEST where id=1;
某列数据和其他列数据参与运算
select age+id from dbo.TEST where id=1;
% 匹配任意多个字符串 _ 匹配一个字符
select * from dbo.TEST where name like N'张%';
聚合函数:
统计个数
select count(*) from dbo.TEST;
求平均
select avg(age) as '年龄' from dbo.TEST;
求和
select sum(age) as '年龄总和' from dbo.TEST;
最大值
select max(age) as '最大值' from dbo.TEST;
最小值
select min(age) as '最小值' from dbo.TEST;
清除重复值
select distinct address from dbo.TEST;
3.1 多表联查
表与表之间的关系
|
表与表之间的三种关系 |
关系如何维护 |
|
一对一 |
特殊的一对多,多方加唯一约束,从表的主键同时又是外键 |
|
一对多 |
通过主外键约束 |
|
多对多 |
通过中间表,中间表与两个表是多对一 |
数据库的三大范式
|
范式 |
特点 |
|
第1范式 |
原子性,每列不可再拆分 |
|
第2范式 |
不产生局部依赖,表中每一列都完全依赖于主键。 |
|
第3范式 |
不产生传递,表中每一列都直接依赖于主键 |
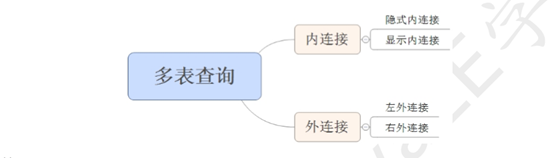
3.2多表查询的分类:
--创建部门表
create table dept(
id int primary key identity(1,1),
name nvarchar(20) )
insert into dept (name) values (N'开发部'),(N'市场部'),(N'财务部');
--创建员工表
create table emp
( id int primary key identity(1,1),
name nvarchar(10),
gender nchar(1), -- 性别
salary float, -- 工资
join_date date, -- 入职日期
dept_id int foreign key (dept_id) references dept(id) -- 外键,关联部门表(部门表的主键)
)
insert into emp(name,gender,salary,join_date,dept_id) values(N'狗蛋','男 ',7200,'2013-02-24',1);
insert into emp(name,gender,salary,join_date,dept_id) values(N'狗剩','男 ',3600,'2010-12-02',2);
insert into emp(name,gender,salary,join_date,dept_id) values(N'王倩','男',9000,'2008-08-08',2);
insert into emp(name,gender,salary,join_date,dept_id) values(N'李芳','女 ',5000,'2015-10-07',3);
insert into emp(name,gender,salary,join_date,dept_id) values(N'张凯','女 ',4500,'2011-03-14',1);
内连接
用左边表的记录去匹配右边表的记录,如果符合条件的则显示。如:从表.外键=主表.主键
隐式内连接:看不到 JOIN 关键字,条件使用 WHERE 指定
格式:SELECT 字段名 FROM 左表, 右表 WHERE 条件
select * from emp,dept where emp.dept_id= dept.id;
显式内连接:使用 INNER JOIN ... ON 语句, 可以省略 INNER
格式:SELECT 字段名 FROM 左表 [INNER] JOIN 右表 ON 条件
select * from emp inner join dept on emp.dept_id=dept.id;
总结内连接查询步骤:
1) 确定查询哪些表
2) 确定表连接的条件
3) 确定查询的条件
4) 确定查询的字段
左外连接:用左边表的记录去匹配右边表的记录,如果符合条件的则显示;否则,显示 NULL,可以理解为:在内连接的基础上保证左表的数据全部显示
格式:SELECT 字段名 FROM 左表 LEFT [OUTER] JOIN 右表 ON 条件
准备:-- 在部门表中增加一个销售部
insert into dept(name) values(N'销售部')
select * from dept
-- 使用内连接查询
select * from emp inner join dept on emp.dept_id=dept.id;
-- 使用左外连接查询
select * from dept left outer join emp on dept.id=emp.dept_id
右外连接:用右边表的记录去匹配左边表的记录,如果符合条件的则显示;否则,显示 NULL,可以理解为:在内连接的基础上保证右表的数据全部显示
格式:SELECT 字段名 FROM 左表 RIGHT [OUTER ]JOIN 右表 ON 条件
准备:-- 在员工表中增加一个赵柳
insert into emp(name,gender,salary,join_date,dept_id) values(N'赵柳','男 ',7200,'2013-02-24',null);
select * from emp;
-- 使用内连接查询
select * from emp inner join dept on emp.dept_id=dept.id;
--使用右外连接查询
select * from dept right outer join emp on dept.id=emp.dept_id
全连接查询:可以理解为左外连接+右外连接
格式:SELECT 字段名 FROM 左表 full JOIN 右表 ON 条件
--全连接查询
select * from dept full join emp on dept.id=emp.dept_id
子查询
子查询的概念:
1) 一个查询的结果做为另一个查询的条件
2) 有查询的嵌套,内部的查询称为子查询
3) 子查询要使用括号
子查询结果的三种情况:
子查询结果只要是单行单列,肯定在 WHERE 后面作为条件,父查询使用:比较运算符,如:> 、<、<>、 = 等
格式:SELECT 查询字段 FROM 表 WHERE 字段=(子查询);
-- 根据最高工资到员工表查询到对应的员工信息
select * from emp where salary = (select max(salary) from emp);
-- 1) 查询平均工资是多少
select avg(salary) from emp;
-- 2) 到员工表查询小于平均的员工信息
select * from emp where salary < (select avg(salary) from emp);
2. 子查询的结果是多行单列
子查询结果是单例多行,结果集类似于一个数组,父查询使用 IN 运算符
格式 :SELECT 查询字段 FROM 表 WHERE 字段 IN (子查询);
-- 先查询大于5000的员工所在的部门id
select dept_id from emp where salary > 5000;
-- 再查询在这些部门id中部门的名字
--Subquery returns more than 1 row
select name from dept where id = (select dept_id from emp where salary > 5000);
--正确
select name from dept where id in (select dept_id from emp where salary > 5000);
--查询开发部与财务部所有的员工信息
-- 先查询开发部与财务部的id
select id from dept where name in(N'开发部',N'财务部');
-- 再查询在这些部门id中有哪些员工
select * from emp where dept_id in (select id from dept where name in(N'开发部',N'财务部'));
3. 子查询的结果是多行多列
子查询结果只要是多列,肯定在 FROM 后面作为表,子查询作为表需要取别名,否则这张表没有名称则无法访问表中的字段。
格式:SELECT 查询字段 FROM (子查询) 表别名 WHERE 条件;
-- 查询出2011年以后入职的员工信息,包括部门名称
-- 在员工表中查询2011-1-1以后入职的员工
select * from emp where join_date >='2011-1-1';
-- 查询所有的部门信息,与上面的虚拟表中的信息组合,找出所有部门id等于的dept_id
select * from dept d, (select * from emp where join_date >='2011-1-1') e where d.id= e.dept_id ;
子查询小结
子查询结果只要是单列,则在 WHERE 后面作为条件
子查询结果只要是多列,则在 FROM 后面作为表进行二次查询
4 .TCL: Transaction Control Language
事务:一个或一组sql语句组成一个执行单元,这个执行单元要么全部执行,要么全部不执行。
事务的特性:
ACID
- 原子性:事务必须是一个自动工作的单元,要么全部执行,要么全部不执行。
- 一致性:事务结束的时候,所有的内部数据都是正确的。
- 隔离性:并发多个事务时,各个事务不干涉内部数据,处理的都是另外一个事务处理之前或之后的数据。
- 持久性:事务提交之后,数据是永久性的,不可再回滚。
然而在SQL Server中事务被分为3类常见的事务:
- 自动提交事务:是SQL Server默认的一种事务模式,每条Sql语句都被看成一个事务进行处理,你应该没有见过,一条Update 修改2个字段的语句,只修该了1个字段而另外一个字段没有修改。。
- 显式事务:T-sql标明,由Begin Transaction开启事务开始,由Commit Transaction 提交事务、Rollback Transaction 回滚事务结束。
- 隐式事务:使用Set IMPLICIT_TRANSACTIONS ON 将将隐式事务模式打开,不用Begin Transaction开启事务,当一个事务结束,这个模式会自动启用下一个事务,只用Commit Transaction 提交事务、Rollback Transaction 回滚事务即可。
- Begin Transaction:标记事务开始。
- Commit Transaction:事务已经成功执行,数据已经处理妥当。
- Rollback Transaction:数据处理过程中出错,回滚到没有处理之前的数据状态,或回滚到事务内部的保存点。
- Save Transaction:事务内部设置的保存点,就是事务可以不全部回滚,只回滚到这里,保证事务内部不出错的前提下。
事务的隔离级别 事务在操作时的理想状态: 所有的事务之间保持隔离,互不影响。因为并发操作,多个用户同时访问同一个 数据。可能引发并发访问的问题:
|
脏读 |
一个事务读取到了另一个事务中尚未提交的数据 |
|
不可重复读 |
一个事务中两次读取的数据内容不一致,要求的是一个事务中多次读取时数据是一致的,这是事务update时引发的问题 |
|
幻读 |
一个事务中两次读取的数据的数量不一致,要求在一个事务多次读取的数据的数量是一致的,这是insert或delete时引发的问题 |
数据库有四种隔离级别 上面的级别最低,下面的级别最高。“是”表示会出现这种问题,“否”表示不会出现这种问题
| 级别 | 名字 | 隔离级别 | 脏读 | 不可重复读 | 幻读 | 数据库默认隔离级别 |
| 1 | 读未提交 | read uncommitted | 是 | 是 | 是 | |
| 2 | 读已提交 | read committed | 否 | 是 | 是 | Oracle 和 SQL Server |
| 3 | 可重复读 | repeatable read | 否 | 否 | 是 | MySQL |
| 4 | 串行化 | serializable | 否 | 否 | 否 |
隔离级别越高,性能越差,安全性越高。
5.6.4 MySQL 事务
5 DCL: Data Control Language
授予权限操作——grant
SQL Server服务器通过授予权限表来控制用户对数据库的访问。在数据库中添加一个新用户之后,若不进行额外操作,该用户只有查询系统表的权限,而不具有操作数据库对象的任何权限。GRANT语句可以授予对数据库对象的操作权限,这些数据库对象包括:表,视图,存储过程,聚合函数等。允许执行的权限包括:查询,更新,删除等。
例:对名称为guest的用户进行授权,允许其对stu_info表执行更新和删除操作
GRANT UPDATE,DELETE ON stu_info
TO guest WITH GRANT OPTION
注:WITH GRANT OPTION意思是该用户还可以向其他用户授予其自身所拥有的权限。
拒绝权限操作——deny
例:禁止名称为guest的用户对stu_info表的操作更新权限
DENY UPDATE ON stu_info TO guest CASCADE
收回权限操作——revoke
例:收回guest用户对stu_info的删除权限
REVOKE DELETE ON stu_info FROM guest
本次用的例子的数据库是SQL server 为啥不用mysql呢,因为公司用的就是SQL server

 浙公网安备 33010602011771号
浙公网安备 33010602011771号