
浏览器端的大文件下载
1. 大文件下载
提前说明,这里的下载不是指将文件直接下载到磁盘本地,而是指类似于缓存到浏览器或者加载到内存中的场景,后续会对之前的数据进行操作
(笔者的电脑配置是32G内存,浏览器是Edge 123.0.2420.65 ,如果读者的实验结果和笔者不一致的话,亦可能是电脑配置或者操作环境的差异)
直接将文件下载到本地磁盘通常是不受大小限制的,比如下面这个直接点击a链接就下载的示例:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Document</title> </head> <body> <a href="https://software.download.prss.microsoft.com/dbazure/Win11_23H2_Chinese_Simplified_x64v2.iso?t=f9ddadcc-8aa8-4861-85fd-7a260f4c2199&P1=1712125031&P2=601&P3=2&P4=vXuSuRXrJsdlyuRgSTmOv05e7gGMRSUDRzJjQEaZzyw%2fKQwUXGsIP1bnnCD6OxbLLrKwlXrTu2kdI%2bUDlrQebcwtLcygYnGqHwEqxRmseNXIqRkS7Rvg02vu1WGzBWjaNhWPCpxDmK1N182BhNV%2foo%2bXsdOF%2ffOZKZlsPsgMSvg0fkfrnK11NN%2fFy6u2J%2b6RDlWsIGxqnE7lzyyTGaYE58I4sINHWZq8xZPMIprhIxdRdm%2b4UZ0ejlrhtIl7tsnhkuXnGN8EAs7C98ZCtutZ8QaQFEKwWp9pra78qdaIa3c9Tw%2bXbLvqNaXbETwukXoVXME8RRs0uPPeVAoxnAX9Xg%3d%3d" target="_blank" rel="noopener noreferrer">下载Windows 11 镜像</a> </body> </html>
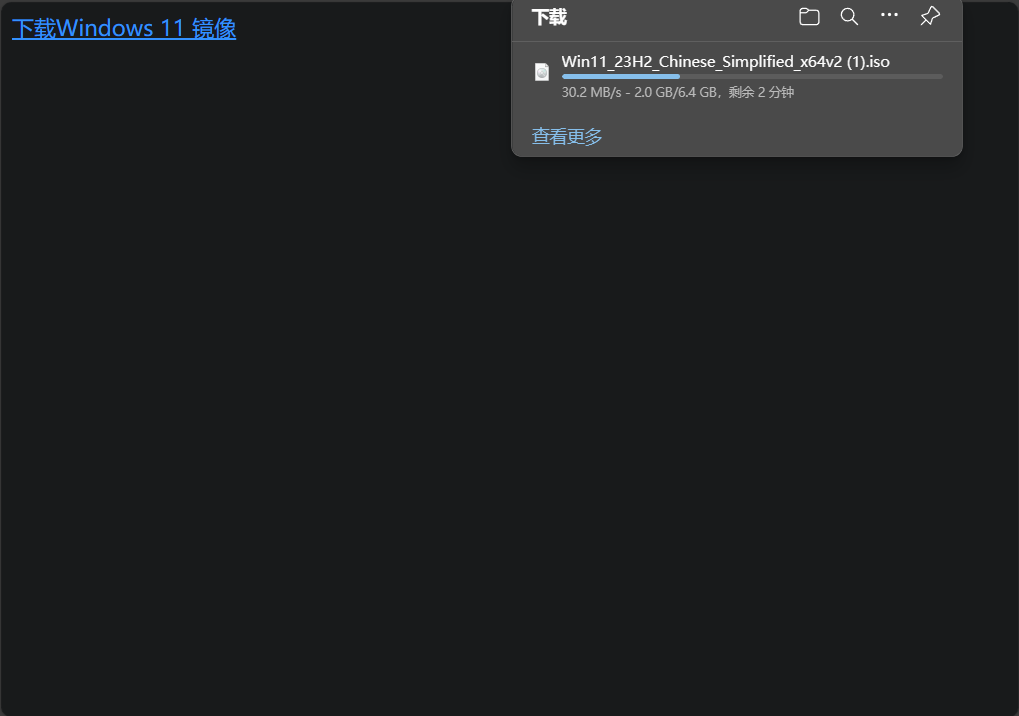
从上图可以看到,直接使用a链接下载到本地磁盘是不受大小限制的
现在,使用Fetch API来下载这个大文件
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Document</title> </head> <body> <button onclick="downloadIsoFile()">下载Windows 11 镜像</button> <script> function downloadIsoFile(){ const url = "./Windows11.iso" fetch(url).then(res => res.blob()).then(blob => { const a = document.createElement('a') const url = window.URL.createObjectURL(blob) const filename = 'Windows11.iso' a.href = url a.download = filename a.click() window.URL.revokeObjectURL(url) }) } </script> </body> </html>
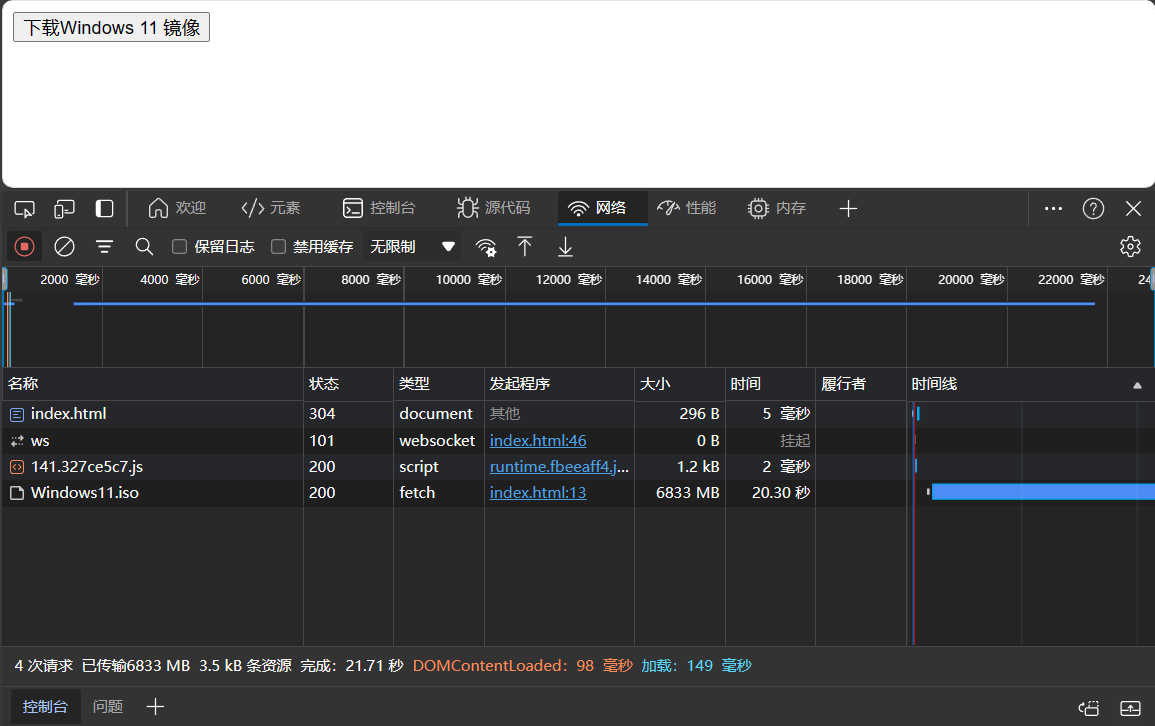
使用XHR API来下载文件
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Document</title> </head> <body> <button onclick="downloadIsoFile()">下载Windows 11 镜像</button> <script> function downloadIsoFile(){ const url = "./Windows11.iso" const xhr = new XMLHttpRequest(); xhr.open("GET", url, true); xhr.responseType = "blob"; xhr.onload = function(){ if(xhr.status === 200){ const blob = xhr.response; const a = document.createElement("a"); a.href = URL.createObjectURL(blob); a.download = "Windows11.iso"; a.click(); } } xhr.send(); } </script> </body> </html>
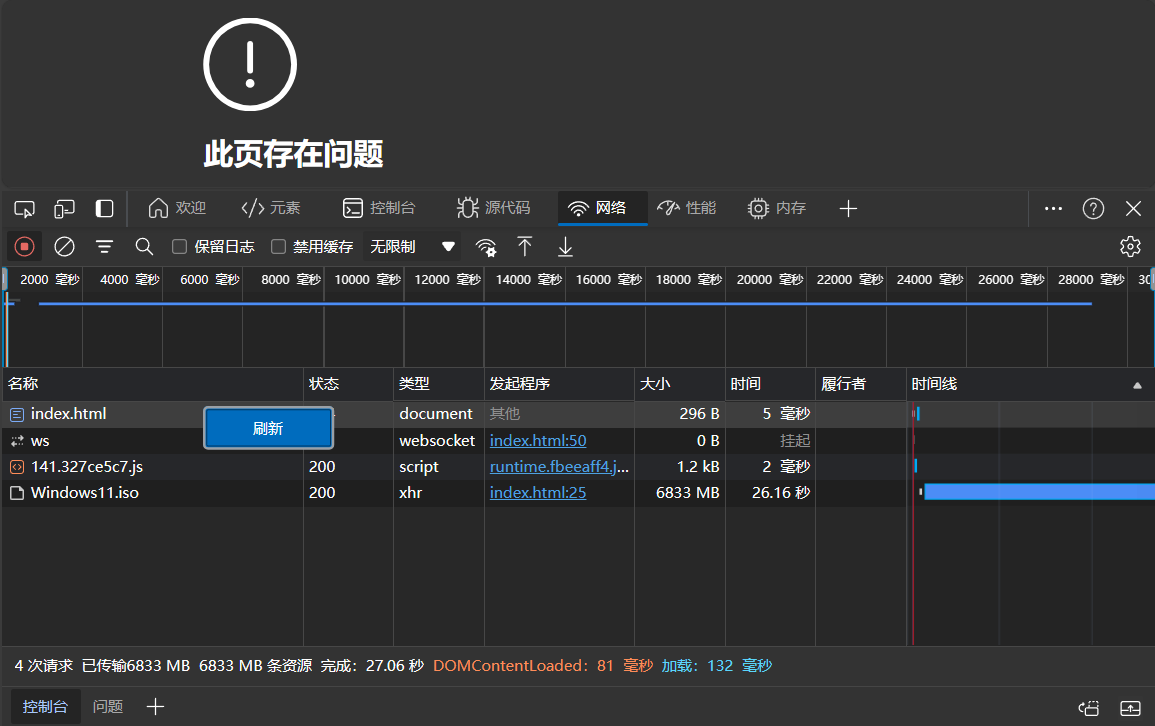
上面可以看到,使用Fetch API是没啥异常的,使用XHR API会导致页面崩溃
查阅MDN文档:ReadableStream - Web API 接口参考 | MDN (mozilla.org)
Fetch API是使用流的方式来传输数据的,而XHR API不是,可以说,使用流的方式具有更好的内存利用效率和稳定性



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!