
基于docker的spark分布式与单线程、多线程wordcount的对比实验
 利用docker的搭建spark环境,进行分布式与单线程、多线程wordcount的对比实验
利用docker的搭建spark环境,进行分布式与单线程、多线程wordcount的对比实验
1. 分布式环境搭建
1.1 基于docker的spark配置文件
docker-compose.yml
version: '2'
services:
spark:
image: docker.io/bitnami/spark:3
environment:
- SPARK_MODE=master
- SPARK_RPC_AUTHENTICATION_ENABLED=no
- SPARK_RPC_ENCRYPTION_ENABLED=no
- SPARK_LOCAL_STORAGE_ENCRYPTION_ENABLED=no
- SPARK_SSL_ENABLED=no
ports:
- '8080:8080'
spark-worker-1:
image: docker.io/bitnami/spark:3
environment:
- SPARK_MODE=worker
- SPARK_MASTER_URL=spark://spark:7077
- SPARK_WORKER_MEMORY=1G
- SPARK_WORKER_CORES=1
- SPARK_RPC_AUTHENTICATION_ENABLED=no
- SPARK_RPC_ENCRYPTION_ENABLED=no
- SPARK_LOCAL_STORAGE_ENCRYPTION_ENABLED=no
- SPARK_SSL_ENABLED=no
spark-worker-2:
image: docker.io/bitnami/spark:3
environment:
- SPARK_MODE=worker
- SPARK_MASTER_URL=spark://spark:7077
- SPARK_WORKER_MEMORY=1G
- SPARK_WORKER_CORES=1
- SPARK_RPC_AUTHENTICATION_ENABLED=no
- SPARK_RPC_ENCRYPTION_ENABLED=no
- SPARK_LOCAL_STORAGE_ENCRYPTION_ENABLED=no
- SPARK_SSL_ENABLED=no
1.2 安装集群
在cmd中cd到yml所在的目录,执行
docker-compose up
等待安装完成并且启动完成
可在docker-desktop中查看启动的集群

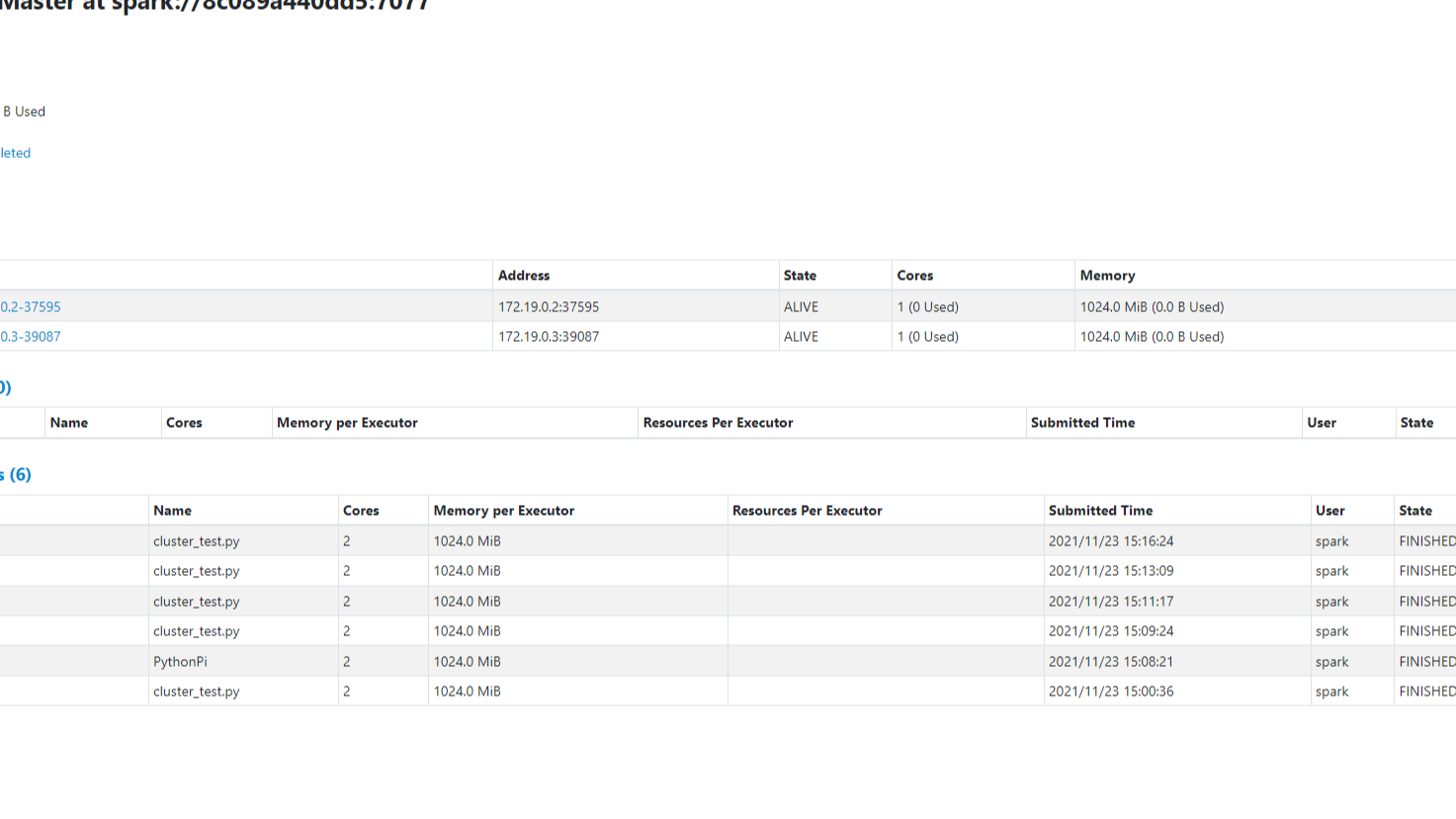
在浏览器中输入localhost:8080访问master 的web UI:

1.3 数据准备
编写利用python脚本生成1KB、1MB、10MB、100MB的文本
def txtwriter(count, file_name):
for i in range(len(count)):
for j in range(count[i]):
with open(file_name[i], mode='a', encoding='utf-8') as file_obj:
file_obj.write('apple peach pear\n')
print(str(i)+" "+str(j)+ file_name[i])
if __name__ == "__main__":
count = [64, 64*1024, 64*1024*10, 64*1024*100] #1KB 1Mb 10MB 100Mb
file_name = ["1KB", "1Mb", "10MB", "100Mb"]
txtwriter(count, file_name)
1.4 脚本准备
编写wordcount以及计时脚本
from pyspark import SparkConf, SparkContext
import sys
import time
import os
def wordcount(file_path):
counts = sc.textFile(file_path)\
.flatMap(lambda line: line.split(' '))\
.map(lambda x: (x, 1))\
.reduceByKey(lambda a, b: a+b)
output = counts.collect()
for(word, count) in output:
print('%s : %i'%(word, count))
# def txtwriter(count, file_name):
# for i in range(len(count)):
# for j in range(count[i]):
# with open(file_name[i], mode='a', encoding='utf-8') as file_obj:
# file_obj.write('apple peach pear\n')
if __name__ == "__main__":
count = [64, 64*1024, 64*1024*10, 64*1024*100] #1KB 1Mb 10MB 100Mb
file_name = ["1KB", "1Mb", "10MB", "100Mb"]
# txtwriter(count, file_name)
for i in range(len(file_name)):
starttime = time.time()
conf = SparkConf()
sc = SparkContext(conf = conf)
wordcount(file_path=file_name[i])
endtime = time.time()
print('time:', endtime-starttime)
with open("time.txt", mode='a', encoding='utf-8') as file_obj:
file_obj.write(str(endtime-starttime) + '\n')
sc.stop()
# for i in range(file_name):
# os.remove(file_name[i])
1.5 数据上传
将数据上传到集群中
docker cp cluster_test.py 8c089a440dd5:/tmp/test
docker cp txtw.py 8c089a440dd5:/tmp/test
......
2. 单线程wordcount
在master主机中执行
spark-submit --master local[1] cluster_test.py
计算结果
| 数据大小 | 1KB | 1MB | 10MB | 100MB |
|---|---|---|---|---|
| 执行时间 | 6.970337629318237 | 2.368252992630005 | 11.44127345085144 | 102.59012055397034 |
3. 多线程wordcount
在master主机中执行
spark-submit --master local[2] cluster_test.py
计算结果
| 数据大小 | 1KB | 1MB | 10MB | 100MB |
|---|---|---|---|---|
| 执行时间 | 7.166856050491333 | 1.9559352397918701 | 6.257161378860474 | 61.2608277797699 |
4. 分布式wordcount
在master主机中执行
spark-submit --master spark://8c089a440dd5:7077 cluster_test.py
计算结果
| 数据大小 | 1KB | 1MB | 10MB | 100MB |
|---|---|---|---|---|
| 执行时间 | 11.847958087921143 | 9.145256996154785 | 13.520023584365845 | 68.8401427268982 |
5. wordcount结果汇总
| 数据大小 | 1KB | 1MB | 10MB | 100MB |
|---|---|---|---|---|
| 单线程(one worker) | 6.970337629318237 | 2.368252992630005 | 11.44127345085144 | 102.59012055397034 |
| 多线程(two workers) | 7.166856050491333 | 1.9559352397918701 | 6.257161378860474 | 61.2608277797699 |
| 分布式(two workers) | 11.847958087921143 | 9.145256996154785 | 13.520023584365845 | 68.8401427268982 |
由表可以看到,分布式在数据量较小时所花时间最长,推测为系统调度消耗时间较多,但数据量大时,分布式的处理时间是显著减少的。单机处理时,数据量较小的时候消耗时间是小于分布式的,并且多线程处理是显著优于单线程的,单机处理的能力毕竟有限,可以推测分布式机器数量增多时,在处理大量数据时能力是优于单机处理的。
