Elasticsearch前沿:ES 5.x改进详解与ES6展望
转:http://www.dataguru.cn/article-11094-1.html
曾勇(Medcl),Elastic 工程师与布道师,2015 年加入 Elastic 公司。加入 Elastic 之前,在搜索和运维等方面积累了超过七年的经验。Elasticsearch 国内首批用户,自 2010 年起就开始接触 Elasticsearch,是 ES 中文社区发起人,也是 Elastic 在中国的首位员工。
我最早是从 2010 年 3 月开始接触 Elasticsearch ,后面在 2015 年 9 月加入了 Elastic ,即 Elasticsearch 这款开源软件背后的公司,一直围绕在 ES 打转,也算是 ES 半个老司机了。
自去年 10 月正式发布 5.0 以来, Elasticsearch 又新增了不少东西,让我们一起来看一下都有哪些值得关注的特性和改进吧。
数据结构方面
首先是索引这块的改进,大家知道 ES 的数据支持增删改查,比如修改文档的时候其实是需要通过 ID 找到 Lucene 文件里对应的文档先删除然后再插入一个新的,所有写操作需要进行相应的版本检查来确保没有冲突。
如果你的场景是日志,那么基本上数据进去之后是不需要进行修改的,所以现在 ES 新增了一个 append-only 的索引模式,也就是当 ES 是自动生成 ID 的时候, ES 可以跳过不必要的版本检测,大概可以提升 20% 左右的索引性能。
我们来看一组前后对比图吧,单这一块的提升还是可圈可点的。

在数据结构方面,新增了多个 range 字段类型,有什么用呢,现在你可以计算连续数据的交并集,可以是时间范围,也可以是数值范围。
比如数据存放的是会议信息,航班有一个 range 字段,里面存的是会议的开始和结束时间,你通过对应的 range 查询可以很方便的查询,得到某个时间点哪些会议同时正在进行,那段时间会议室有空闲,可以预订等等。
常见的场景,比如日历,电视节目单。

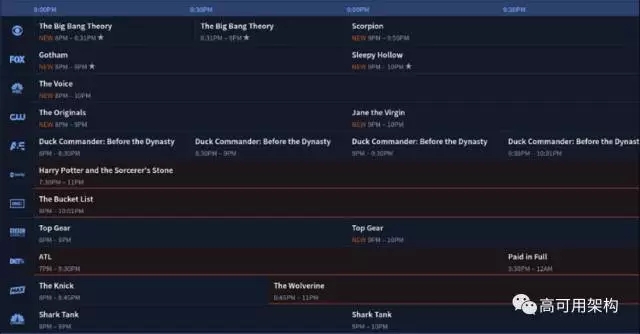
怎么使用呢?看例子会比较清晰一点。
首先看看怎么定义吧,下面的这个例子, mapping 里面设置字段的 type 为 date_range 即表示一个时间的范围字段:

然后我们插入一些数据,可以看到指定的是一个范围,有起始值。

查询呢?
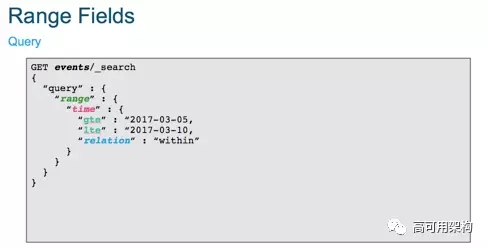
大概就是这么简单。
下一个特性值得介绍的就是 _all 字段的移除
关于 _all 这个字段,场景其实就是为了满足快速检索的需求,当你不知道 mapping 里面有什么字段的情况下,你也能够自由的进行搜索, 所以为了实现这个需求,就有一个 _all 字段,它会把其他字段的内容都拷贝到这个字段里面,然后都当成 string 类型来处理,所以就存在了数据的冗余了,另外数字当成 string 也不能很好的压缩,并且都在 _all 一个字段,所以只能用一种分析器,在高亮的时候也是对这个 _all 字段进行的高亮,而不是真实的字段值,显示起来效果也不好。
现在 query_string 和 simple_query_string 查询引入了一个 all_fields 模式,在没有指定字段的情况下,默认可以自动选择相关类型的字段分别执行查询,自动帮你展开,使用起来更加简单,另外, _all 字段将在 6.0 默认禁用且不可配置。
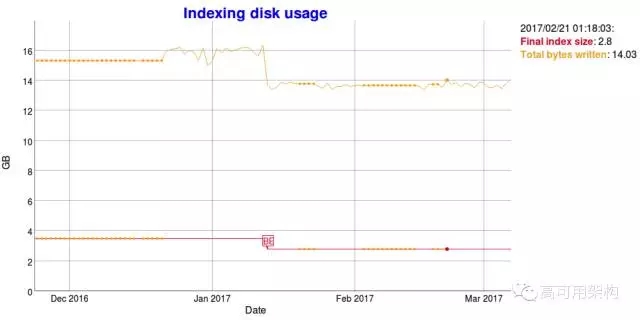
这里有一个去掉 _all 字段的前后对比,可以看到磁盘占用少了不少,索引性能也有一些提升。

索引性能的提升,图上转折点就是。下面是对应的磁盘空间的下降。
接下来,我们看看搜索的高亮,我们知道文本高亮是搜索体验的重要的一环,通过显示匹配结果的文本块并对关键字进行高亮能够让我们对搜索结果有一个直观的认识。
现在有一个新的高亮器: Unified Highlighter,大家可能会问,目前 ES 默认已经提供了 3 种不同的高亮器,为什么还会有一个新的轮子呢,因为之前的用法有点复杂 , 用户选择起来比较困难,新的 unified highlighter 目的就是简化高亮的使用,可以支持前面 3 种高亮类型的自动选择。
还有一个是 keyword 类型可以通过 normalizer 来进行标准化了, keyword 类型相比 text 类型就是不能分词,但是可能同样需要进行相应的标准化处理,比如统一转成小写,移除标点符号等等,使用方式和 analyzer 一样,比如下面的需求:

尽管设置了 keyword 类型,但是我同样是需要对文本进行处理的啊,用户不可能输入的完全都是一样,错一个大小写,可能就查不出来了。
新的 normalizer 使用起来 很简单,和 analyzer 基本一样,专门用于 keyword 类型,如下:

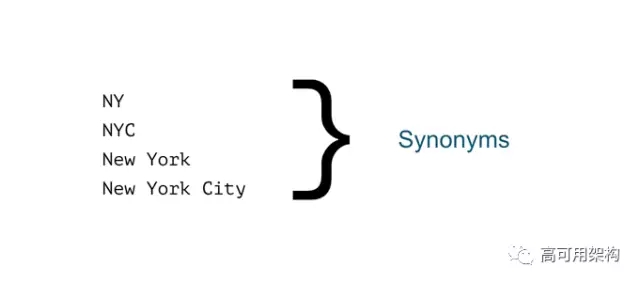
另一个就是 Multi-Word Synonyms,之前是不支持同义词中间有空格分割的,分词的时候会帮你切分开,搜索的时候不能正确处理词组这种同义词,如下面的场景。
这里有一组同义词,看起来没毛病。
有一个 phrase 查询,看起来也没毛病。


我的同义词过滤器就不对了,如下:

new is old ?这是什么情况?
因为分词的时候,把他们单个字拆开进行的同义处理。新的多词同义词采用 graph 方式处理,很好的解决了上面的问题。

同义词现在可以支持词组了,也就是说同义词如果是由多个词组成的,不会在分词的时候被傻傻的拆开,而是正确的处理。
还一个就是字段折叠( Field collapsing),这个特性比较有意思,你可以在搜索的时候,按某个字段作为维度进行去重,我这里写过一篇详细的博客,有兴趣的可以去看看:
http://elasticsearch.cn/article/132
Cancellable searches
ES 的搜索,对于一些耗时较长的查询,以前是没有办法取消的,除了干掉节点重来或者等待结束,没有办法,现在可以通过 ES 的任务管理机制来进行取消了, 5.3 已经提供。感兴趣的可以查看文档:
https://www.elastic.co/guide/en/Elasticsearch/reference/5.3/search.html#global-search-cancellation
Partitioned term aggs
ES 的聚合功能很强大吧, term aggs 相信也是大家常用的一种,如果遇到字段里面 term 很多的场景,聚合起来不只是慢,可能还没法正常运行。
现在 term aggs 提供了一种分区的概念,你可以对一个字段,分 n 次进行聚合,分而治之,有兴趣的可以看看文档:
https://www.elastic.co/guide/en/Elasticsearch/reference/5.3/search-aggregations-bucket-terms-aggregation.html#_filtering_values_with_partitions
另外,当你的集群变红的时候,你是不是手忙脚乱过,检查一大堆配置,访问一大堆接口来查看到底是哪里出了问题。

现在方便了,新增的 /_cluster/allocation/explain 接口能够直接告诉你哪里出了问题:


Java REST Client 也有了更新, ES 之前提供了一个偏底层的 Java HTTP REST client,但是用起来太费劲,需要手动拼 JSON,现在, Java REST Client 分成了 Java High Level REST Client 和 Java Low Level REST Client, High Level 基于 Low Level 来实现,顾名思义,提供更多用户方便的接口调用, High Level REST Client 将提供和 Transport Client 类似的接口,不用手动去拼接 QueryDSL 的 JSON 了,目测在 5.5 版本提供。
听说你们有很多集群在跑?那你有没有用过 tribe node 来访问多个集群呢?, tribe-node 的工作方式是合并多个集群的元数据到一起,负责请求的转发。
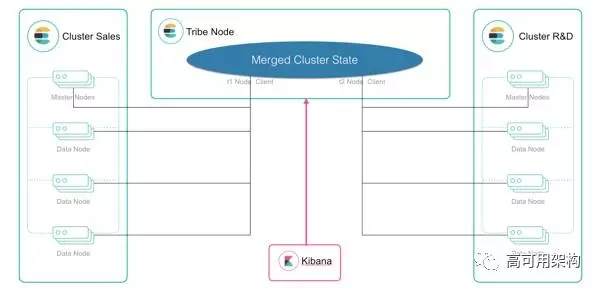
大概就是这个图。
不过 tribe-node 有几个问题,首先,他需要和各个集群的每个节点建立连接,另外 tribe-node 的 配置的静态的,修改之后需要重启 tribe-node,每个集群的元数据变化之后都需要进行合并,频繁的操作十分影响性能,并且集群的索引名称必须保证不能相同,同时,通过 tribe-node 只能只读,无法创建索引,再者,跨集群查询,会将所有的分片的数据都放到 tribe-node 上进行 reduce,如果分片很多,可能出现 OOM 等问题。
新引入的 cross-cluster 跨集群功能就是为了方便以一种更优雅的方式来替换掉 tribe-node。
先来上一张图,里面可以看到如何创建一个 cross-cluster。
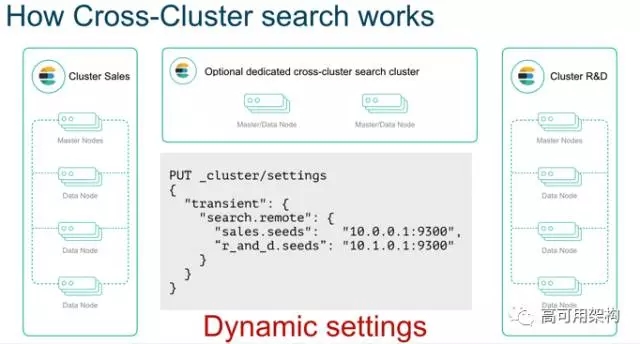
可以看到,集群的任何节点都能执行跨集群操作,节点的元数据不需要频繁更新,集群间索引基于命名空间进行了隔离。
什么是命名空间?
GET sales:*,r_and_d:logs*/_search
{
"query": { … }
}
可以看到上面的 QueryDSL,正常的索引前面有 namespace:这样的前缀,这就是命名空间,也就是选择不同的集群。
不仅可以动态设置多个集群的访问,也不需要重启节点。集群间互相不受影响,更没有频繁的元数据的同步。
Kibana 能够完全访问多个集群,且能创建索引和进行修改,具备完整访问权限。
跨集群访问只需要很轻量级的几个连接,不需要和每个节点都建立连接,这个功能在 5.3 已经支持。
Batched Search Reduce Phases
另外,以前的搜索的 reduce 操作都是要等到把每个分片的结果都拿到本地之后再做合并,所以为了避免海量分片造成的资源大量占用的问题,之前是有一个最多 1000 个分片的软限制,也就是一个搜索最多只能检索 1000 个分片,现在新增的 batched search reduce phases 提供了分批进行 reduce 的行为,也就是不用全部拿到之后再做 reduce,而是拿到足够的分片(默认 512)之后就开始 做 reduce,然后拿到合并结果,释放相关的资源,继续获取其他的分片数据继续进行 reduce,这样就能处理海量的数据了,这个功能在 5.4 发布。
ES 6.0 展望
上面的这些功能基本会在 5.x 提供,而 es6.0 早已在路上了,有很多特性值得期待:
稀疏性 Doc Values 的支持,大家知道 es 的 doc values 是列式存储,文档的原始值都是存放在 doc values 里面的,而稀疏性是指,一个索引里面,文档的结构其实是多样性的,但是郁闷的是只要一个文档有这个字段,其他所有的文档尽管没有这个字段,可也都要承担这个字段的开销,所以会存在磁盘空间的浪费,而这块的改进就是这个问题。
Index sorting,即在索引阶段的排序,即我们查询的时候有时候会根据某个字段的值进行排序,比如时间、编号等等,如果在索引的时候提取排好序,那么搜索或聚合的时候就会非常快,相应的直接走预先排序好的索引就行了。当然索引的时候会要增加额外开销,适合不怎么变化的索引的场景。
顺序号的支持,每个 es 的操作都有一个顺序编号,这个属于 es 内部的一个功能,可以提供:快速的分片副本恢复或同步;跨数据中心的节点恢复;甚至提供一个 Changes API 等等;
无缝滚动升级,使之能够从 5 的最后一个版本滚动升级到 6 的最后一个版本,不需要集群的完整重启。无缝滚动升级,也就是不用停服务,在线升级,补充一下。
什么是最后一个版本?
也就是 6 发布第一个版本,比如 6.0 的时候, 5 的对应的那个最后的发布的版本,比如 5.5,那么 5.5 可以直接滚动升级到 6.0。并且这两个版本我们称为主要版本,他们还支持跨大版本的搜索。就是前面提到的 cross-cluster 特性,不同的版本也能支持跨集群访问,如下:
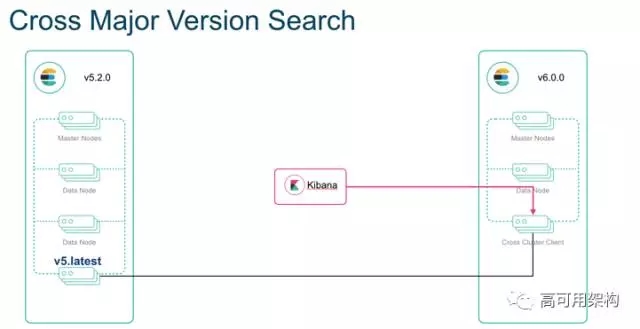
下面还有一些:
Removal of types,在 6.0 里面,开始不支持一个 index 里面存在多个 type 了,所有的新的 index 都将只有一个虚拟的固定的 type: doc 来代替,基于 type 的 parent-child 关系将通过单独的 join 字段来实现, type 会在 7.0 彻底移除。
Index-template inheritance,索引版本的继承,目前索引模板是所有匹配的都会合并,这样会造成索引模板有一些冲突问题, 6.0 将会只匹配一个,索引创建时也会进行验证。
Load aware shard routing, 基于负载的请求路由,目前的搜索请求是全节点轮询,那么性能最慢的节点往往会造成整体的延迟增加,新的实现方式将基于队列的耗费时间自动调节队列长度,负载高的节点的队列长度将减少,让其他节点分摊更多的压力,搜索和索引都将基于这种机制。
已经关闭的索引将也支持 replica 的自动处理,确保数据可靠。
X-Pack 的部分特性:
6.0 的部分特性预告就上面这些,我猜下面的特性你也同样感兴趣:
Elasticsearch-SQL
Elasticsearch 官方也要支持的 SQL 特性了。
默认提供了一个 CLI 工具,可以很方便的执行 SQL 查询,主要面向管理人员,提高常见操作的使用效率。
Kibana 里面也可以直接执行。
另外也兼容 JDBC 协议,现存的很多基于 JDBC 协议的各种 SQL 工具及 BI 工具都能直接把 es 当数据库来连接和进行数据分析。

支持在 Java 里面通过 Java.sql 和 javax.sql API 接口访问 ES 数据。
使用 ES 变得更加轻量级,使用起来无依赖。
去年 Elastic 收购了业界领先的行为数据分析厂商 Prelert,现在相关产品已经集成进入了 X-Pack 的机器学习模块,可以快速的实现基于 ES 数据的行为分析,借助 ES 的海量实时处理能力,采用非监督机器学习来识别异常行为。
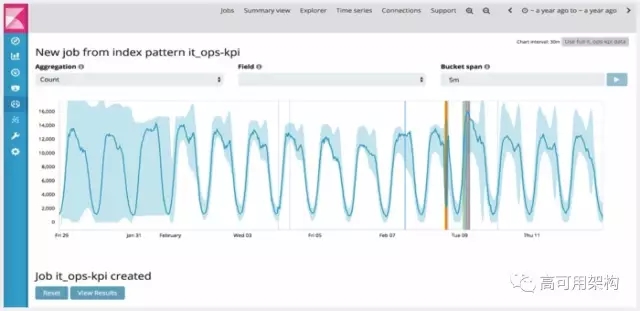
上图是机器学习自动识别出来的异常数据点。
本文只是 ES 最近的众多改进的一部分,有关更详细的更新内容还以具体的版本发布记录为准。
ElasticStack 的其他开源项目也有很多有意思的改进和 feature,愿意了解更多的,可以关注我们官方及社区的活动:
http://elasticsearch.cn/article/141
Q&A
提问:能否说说 ES 是如何在 lucene 上实现分布式的?
这个不是一句话能够说清楚点,可以参考我们的权威指南:
http://elasticsearch.cn/book/elasticsearch_definitive_guide_2.x/distributed-docs.html
提问:可否组织一些 ES 常见的复杂模型构建思路探讨这样的论题。主要是探讨如何实现与优化。我想这是在座的同学都会有遇到的问题。
曾勇:复杂模型需要具体分析,可以参看我们的权威指南:
http://elasticsearch.cn/book/elasticsearch_definitive_guide_2.x/modeling-your-data.html
提问:ES 与 solr 对比有什么优势?技术选型时如何考虑?
曾勇:网上的对比有很多,我就不一一赘述了,如果没有用过 solr,那建议直接使用 ES 吧,上手更快更简单。另外网上的优劣比较其实也要结合自己的实际场景,实践出真知。
问:请问下,如果我有 9G 的数据导入,如何导最快?之前 curl @xxx.txt 方式,但是数据文件一大 curl 标准格式导入就不行了。
曾勇:走 bulk 方式肯定是最快的,txt 内容是什么格式呢,利用一些现存的工具,可以试试,比如 logstash,记得选择 bulk 模式。导入的时候,有很多参数也对速度有帮助,这个就要去看看索引的优化这块的内容了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号