

C++ 统计地铁中站名出现的字的个数
最近网上看到一个话题,也很有意思的,就写到这里来了。
- 上海地铁的站名中,出现频率最高的字是什么?
正好,练习自己的C++代码能力,给定一些站名,计算一下。
首先是一个文件,记录了所有的站名,这个文件内容比较长,摘录一部分下来。这个文件可以作为我们的输入文件来用。
注意,这个文件内容上只是把所有线路的名称罗列了一遍,可能有重复。因此,在我们计算的一开始,要把这些内容去重。
最前面的部分如下:
#include<iostream>
#include<string>
#include<stdio.h>
#include<string.h>
#include<algorithm>
using namespace std;
string name[15000];
int nPos=0;
int main(){
freopen("Name.txt","r",stdin);
freopen("Calc.txt","w",stdout);
//1.排重
string s;
while(cin>>s){
int flag=0;
for(int i=1;i<=nPos;i++){
if(name[i]==s)flag=1;
}
if(flag==0)name[++nPos]=s;
}
nPos这个变量用于记录目前的name数组总共有多少个元素。大体逻辑就是这样。
接下来,我们要统计出现的字符的数量。我们使用一个结构体来记录:
struct Count{
char T[4];//出现的中文汉字
int times;
Count(){
T[0]=T[1]=T[2]=T[3]=0;
}
}strCount[15000];
int sPos=0;
由于是中文汉字,我们考虑使用字符串来存储,大小放大一点,就写成4个字节吧。
我们从1开始,顺次遍历name数组的每个元素,然后把name中每个中文字符拿出来和strCount中比对。出现过就+1,没出现过就新建一个。
for(int i=1;i<=nPos;i++){
for(int j=0;j+1<name[i].size();j+=2){
char c[3];c[0]=name[i].at(j);c[1]=name[i].at(j+1);c[3]='\0'; //提取成中文
int flag=0;
for(int k=1;k<=sPos;k++){
if(check(strCount[k].T,c)){//这个字已经出现过
strCount[k].times++;
flag=1;
}
}
if(flag==0){
strncpy(strCount[++sPos].T,c,2);
strCount[sPos].times=1;
}
}
}
这里用到了一个check函数判断字符串的相等,由于只有2个元素所以直接写就可以了,不用循环来比对了。
bool check(char *A,char *B){
if(A[0]==B[0] && A[1]==B[1] )return true;
return false;
}
然后最后的部分,进行排序和输出。
bool comp(Count A,Count B){
return A.times>B.times;
}
int main(){
//中略
//3.输出信息
sort(strCount+1,strCount+sPos+1,comp);
for(int i=1;i<=50;i++){
cout<<strCount[i].T<<" "<<strCount[i].times<<endl;
}
return 0;
}
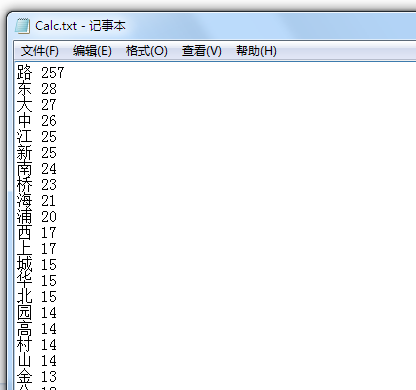
最终的输出结果,这里我们只输出前50名,摘取一些贴在下面:
本文所有内容下载见:https://files.cnblogs.com/files/blogs/692473/Calc.zip?t=1643093477

