
显存充足,但是却出现CUDA error:out of memory错误
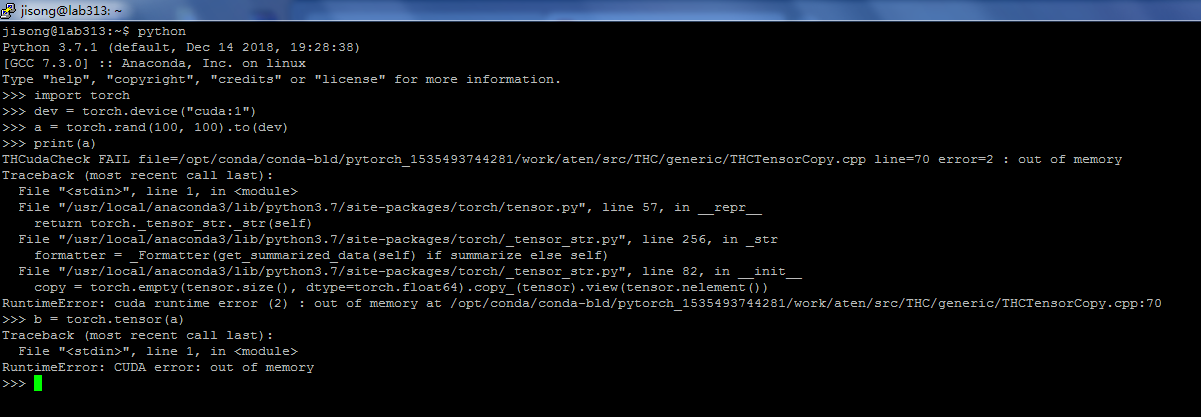
之前一开始以为是cuda和cudnn安装错误导致的,所以重装了,但是后来发现重装也出错了。
后来重装后的用了一会也出现了问题。确定其实是Tensorflow和pytorch冲突导致的,因为我发现当我同学在0号GPU上运行程序我就会出问题。
详见pytorch官方论坛:
https://discuss.pytorch.org/t/gpu-is-not-utilized-while-occur-runtimeerror-cuda-runtime-error-out-of-memory-at/34780
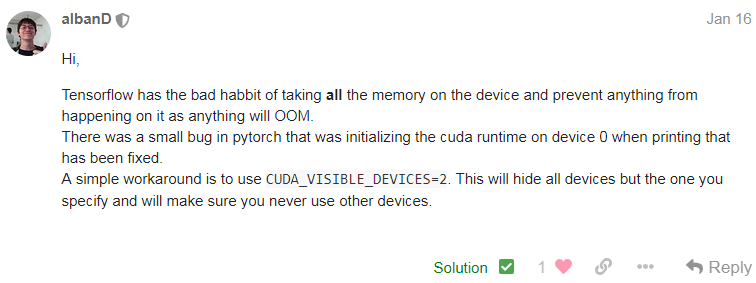
因此最好的方法就是运行的时候使用CUDA_VISIBLE_DEVICES限制一下使用的GPU。
比如有0,1,2,3号GPU,CUDA_VISIBLE_DEVICES=2,3,则当前进程的可见GPU只有物理上的2、3号GPU,此时它们的编号也对应变成了0、1,即cuda:0对应2号GPU,cuda:1对应3号GPU。
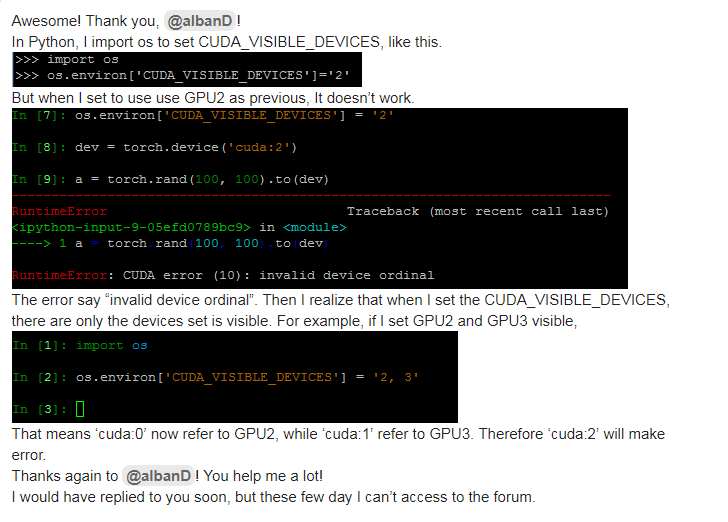
如何设置CUDA_VISIBLE_DEVICES:
① 使用python的os模块
import os
os.environ['CUDA_VISIBLE_DEVICES']='2, 3'
②直接设置环境变量(linux系统)
export CUDA_VISIBLE_DEVICES=2,3
分割线~~~~~
猜测有可能是cuda和cudnn安装错误导致的,决定重装。
卸载CUDA
https://blog.csdn.net/huang_owen/article/details/80811738
https://blog.csdn.net/u014561933/article/details/79968580
由于之前使用的是deb安装,
sudo apt-get autoremove --purge cuda
卸载后,进入/usr/local,发现还残留有cuda的文件夹,据说是cudnn,但是我好像没发现??

进入cuda-9.0

删除文件夹

重新安装cuda
这次使用.run进行安装
https://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html
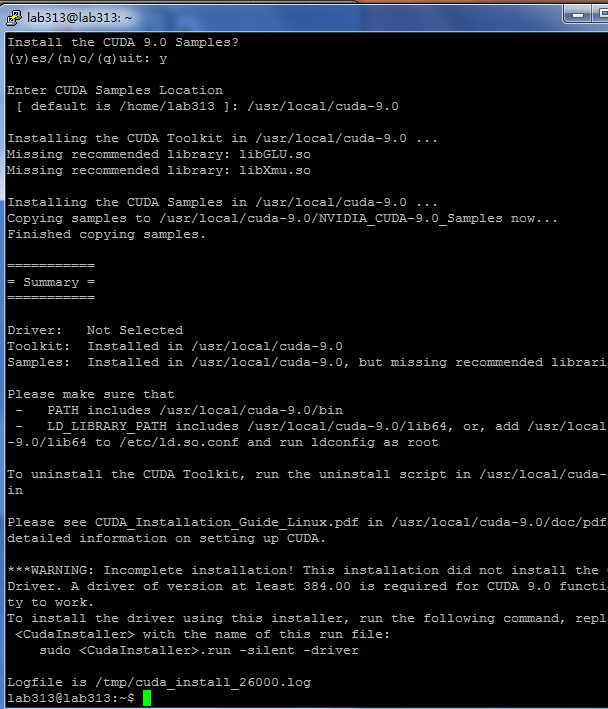
安装完成

之前已经在/etc/profile添加过环境变量了

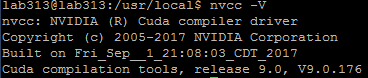
然后也安装补丁
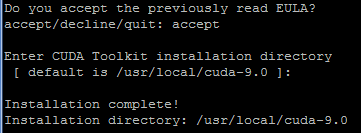
安装cudnn
https://docs.nvidia.com/deeplearning/sdk/cudnn-install/index.html#installlinux
使用deb方式安装
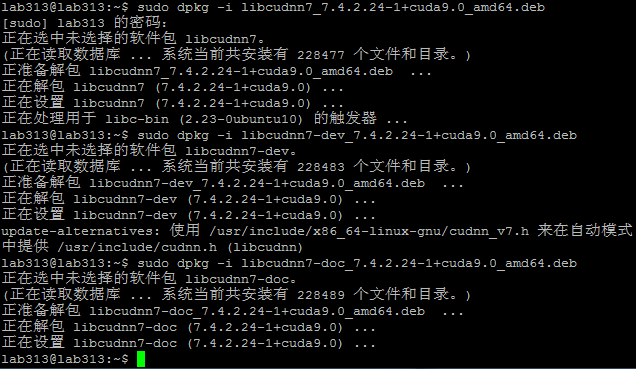
并验证cudnn的安装是否成功

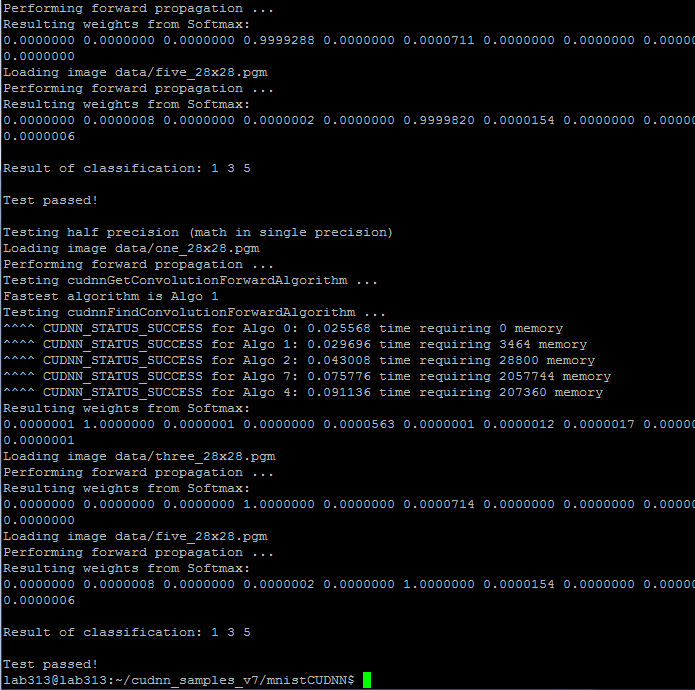
最后删掉该例程

最后解决了上述虚假报错的问题

