

前期数据准备 pycharm操作数据库 搭建测试环境 ORM关键字 双下划线查询 ORM外键字段创建及操作 多表查询 跨表查询
day55
pycharm操作数据库
orm关键字
<1> all(): 查询所有结果
<2> get(**kwargs): 返回与所给筛选条件相匹配的对象,返回结果有且只有一个,如果符合筛选条件的对象超过一个或者没有都会抛出错误。
<3> filter(**kwargs): 它包含了与所给筛选条件相匹配的对象
<4> exclude(**kwargs): 它包含了与所给筛选条件不匹配的对象
<5> values(*field): 返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列model的实例化对象,而是一个可迭代的字典序列
values取具体的数据 是一个对象{},values没有指定参数,获取所有的字段数据,指定参数,获取指定字段数据
<6> values_list(*field): 它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列
values_list取具体的数据 是一个对象(),values_list没有指定参数,获取所有的字段数据,指定参数,获取指定字段数据
<7> order_by(*field): 对查询结果排序 ,默认是升序,如果在字段前面加-号就为降序 .示例:models.Person.objects.all().order_by('-id')
而且,order_by('-id','name')可以多个字段进行排序
<8> reverse(): 对查询结果反向排序,请注意reverse()通常只能在具有已定义顺序的QuerySet上调用(在model类的Meta中指定ordering或调用order_by()方法)。
<9> distinct(): 从返回结果中剔除重复纪录(如果你查询跨越多个表,可能在计算QuerySet时得到重复的结果。
此时可以使用distinct(),注意只有在PostgreSQL中支持按字段去重。)
<10> count(): 返回数据库中匹配查询(QuerySet)的对象数量。
<11> first(): 返回第一条记录 # 取不到返回None,不会像索引取不到会报错
<12> last(): 返回最后一条记录 # 同上
<13> exists(): 如果QuerySet包含数据,就返回True,否则返回False
# 注意get 没有这个方法,只有对象列表才能用这个方法<14> update(): 对字段的值进行更新获取数据
# res = models.User.objects.all() # 查询所有的数据 QuerySet 可以看成是列表套对象
# res = models.User.objects.filter() # 括号内填写筛选条件 不写相当于all() QuerySet 可以看成是列表套对象
# res = models.User.objects.filter(pk=1) # 想通过主键筛选数据 可以直接写pk 会自动定位到当前表的主键字段 无需你自己查看具体字段名称
# res = models.User.objects.filter(pk=1)[0] # 直接获取数据对象 QuerySet支持索引取值 但是django不推荐使用 因为索引不存在会直接报错
# res = models.User.objects.filter(pk=1).first() # 获取结果集中第一个对象 推荐使用封装的方法 不会出现索引超出范围报错的情况
# res = models.User.objects.filter(pk=1, name='kevin').first() # 括号内支持填写多个筛选条件 默认是and关系
# res = models.User.objects.filter().filter().filter().filter().filter() # 只要是QuerySet对象就可以继续点对象方法(类似于jQuery链式操作)
# res = models.User.objects.filter().last() # 获取结果集中最后一个对象
# res = models.User.objects.exclude(name='jason') # 取反操作 它包含了与所给筛选条件不匹配的对象
# res = models.User.objects.all().values('name','age') # QuerySet 可以看成是列表套字典
# res = models.User.objects.values('name','age') # QuerySet 可以看成是列表套字典 指定字段 all不写也表示从所有数据中操作
# res = models.User.objects.filter(pk=2).values('name') # 可以看成是对结果集进行字段的筛选
# res = models.User.objects.all().values_list('name', 'age') # QuerySet 可以看成是列表套元组数据去重
# res = models.User.objects.all().distinct() # 数据对象中如果包含主键 不可能去重
# res = models.User.objects.values('name').distinct()数据排序
# res = models.User.objects.order_by('age') # 默认是升序
# res = models.User.objects.order_by('-age') # 该为降序
# res = models.User.objects.order_by('age', 'pk') # 也支持多个字段依次排序
# res = models.User.objects.reverse() # 不起作用
# res1 = models.User.objects.order_by('age').reverse() # 只有在order_by排序之后才可以
# print(res1)
# res = models.User.objects.order_by('age')
数据取反
# res = models.User.objects.exclude(name='jason') # 取反操作统计
# res = models.User.objects.count() # 统计结果集的个数判断
# res = models.User.objects.exists()
# res = models.User.objects.filter(name='jasonNB').exists() # 判断结果集中是否有数据 有返回True 没有返回False
# 1.查询年龄大于20的用户
# res = models.User.objects.filter(age__gt=20)
# print(res)
"""
__gt 大于
__lt 小于
__gte 大于等于
__lte 小于等于
"""
# 2.查询年龄是18、22、25的用户
# res = models.User.objects.filter(age__in=[18, 22, 25])
# print(res)
"""
__in 成员运算
"""
# 3.查询年龄在18到26之间的用户
# res = models.User.objects.filter(age__range=[18, 26]) # 包含18和26
# print(res)
"""
__range 范围查询
"""
# 4.查询姓名中包含字母j的用户
# res = models.User.objects.filter(name__contains='j')
# res = models.User.objects.filter(name__icontains='j')
# print(res)
"""
__contains 区分大小写
__icontains 忽略大小写
"""
# 5.其他方法补充
"""
__startswith
__endswith
__regex
"""
# 6.查询月份是5月的数据
# res = models.User.objects.filter(op_time__month=5)
# print(res)
# 查询年份是22年的数据
res = models.User.objects.filter(op_time__year=2022)
print(res)
"""
__year 按照年份筛选数据
__month 按照月份筛选数据
...
"""
MYSQL回顾
关系的种类
一对多关系
多对多关系
一对一关系
关系的判断
换位思考
字段的位置
一对多关系 外键字段建在多的一方
多对多关系 外键字段建在第三张关系表中
一对一关系 外键字段建在任意一方都可以 但是推荐建在查询频率较高的表中
前期相关配置
settings.py
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': '库名称',
'HOST':'127.0.0.1',
'PORT': '3306',
'USER': 'root',
'PASSWORD': '123456'
}
}__init__.py
import pymysql
pymysql.install_as_MySQLdb()models.py
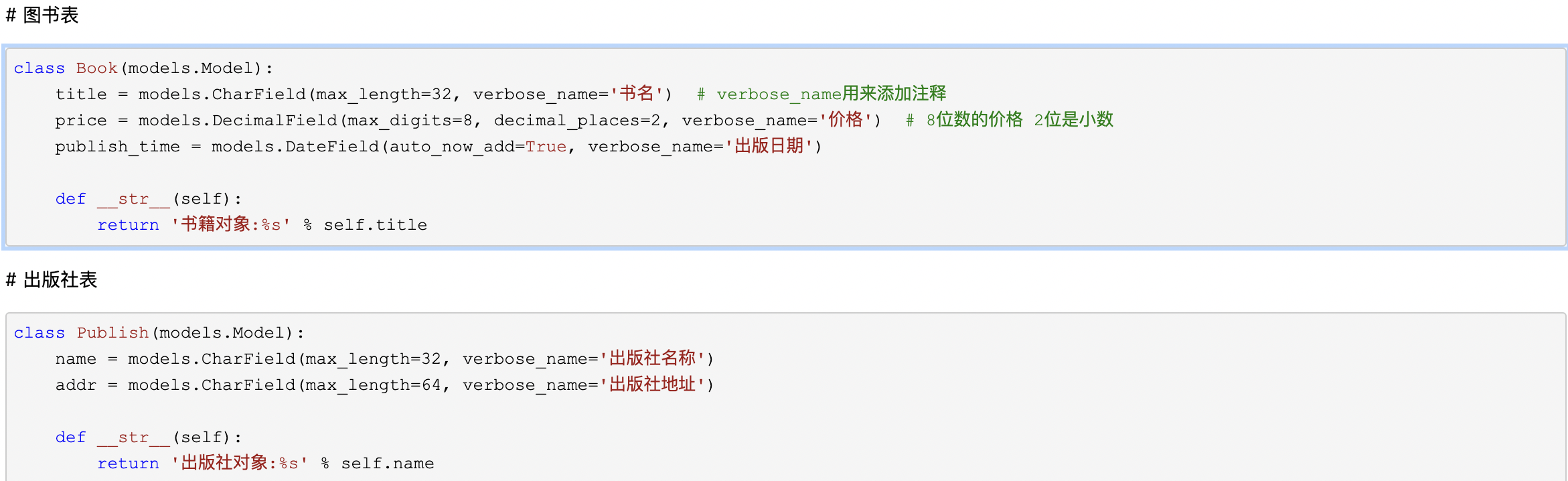
# 图书表
class Book(models.Model):
title = models.CharField(max_length=32, verbose_name='书名') # verbose_name用来添加注释
price = models.DecimalField(max_digits=8, decimal_places=2, verbose_name='价格') # 8位数的价格 2位是小数
publish_time = models.DateField(auto_now_add=True, verbose_name='出版日期')
def __str__(self):
return '书籍对象:%s' % self.title# 出版社表
class Publish(models.Model):
name = models.CharField(max_length=32, verbose_name='出版社名称')
addr = models.CharField(max_length=64, verbose_name='出版社地址')
def __str__(self):
return '出版社对象:%s' % self.name
class Author(models.Model):
name = models.CharField(max_length=32, verbose_name='姓名')
age = models.IntegerField(verbose_name='年龄')# 作者详情表
class AuthorDetail(models.Model):
phone = models.BigIntegerField(verbose_name='手机号')
addr = models.CharField(max_length==64, verbose_name='家庭地址')
django orm创建表关系
图书表
出版社表
作者表
作者详情表
关系判断
书与出版社
一本书不能对应多个出版社
一个出版社可以对应多本书
# 一对多关系 书是多 出版社是一 ForeignKey
'''django orm外键字段针对一对多关系也是建在多的一方 '''
书与作者
一本书可以对应多个作者
一个作者可以对应多本书
# 多对多关系 ManyToManyField
'''django orm外键字段针对多对多关系 可以不用自己创建第三张表'''
作者与作者详情
一个作者不能对应多个作者详情
一个作者详情不能对个多个作者
# 一对一关系 OneToOneField
'''django orm外键字段针对一对一关系 建在查询频率较高的表中'''
ManyToManyField不会在表中创建实际的字段
而是告诉django orm自动创建第三张关系表
ForeignKey、OneToOneField会在字段的后面自动添加_id后缀
如果你在定义模型类的时候自己添加了该后缀那么迁移的时候还会再次添加_id_id 所以不要自己加_id后缀
ps:三个关键字里面的参数
to用于指定跟哪张表有关系 自动关联主键
to_field\to_fields 也可以自己指定关联字段一对多、一对一
添加外键字段 create
# 第一种 直接写外键字段对应的值
models.Book.objects.create(title='聊斋志异', price=16987.22, publish_id=1) # 直接填写关联数据的主键值
# 第二种 先获取一个数据对象 通过数据对象添加
publish_obj = models.Publish.objects.filter(pk=2).first()
models.Book.objects.create(title='资本论', price=56777.98, publish=publish_obj)
修改外键字段 update
第一种
models.Book.objects.filter(pk=1).update(publish_id=3) # 修改外键对应的值
第二种
publish_obj = models.Publish.objects.filter(pk=2).first()
models.Book.objects.filter(pk=1).update(publish=publish_obj) # 通过获取的对象修改
多对多
添加关系 add
第一种
book_obj = models.Book.objects.filter(pk=1).first() # 先获取一本书的对象
book_obj.authors.add(1) # 用这本书的对象点第三张关系表(书与作者的虚拟表)进行添加数据 这里的1是指添加了数据主键值
book_obj.authors.add(1, 2) # 可以直接填写多个数据主键值
第二种
author_obj1 = models.Author.objects.filter(pk=1).first() # 获取对象
author_obj2 = models.Author.objects.filter(pk=2).first() # 获取对象
book_obj.authors.add(author_obj1) # 通过点的方式添加对对象
book_obj.authors.add(author_obj1,author_obj2) # 支持添加多个
修改关系 set
第一种
book_obj = models.Book.objects.filter(pk=1).first() # 同样是先获取一本书对象
book_obj.authors.set([3, ]) # 通过对象点第三张表的方式修改 括号内必须是一个迭代的对象 不然会报错 所以是括号套列表 元素可以单个也可多个
book_obj.authors.set([1, 2])
第二种
author_obj1 = models.Author.objects.filter(pk=3).first()
author_obj2 = models.Author.objects.filter(pk=4).first()
book_obj.authors.set([author_obj1, ]) # 括号内套列表里面放获取到的对象 可以单个也可多个
book_obj.authors.set([author_obj1, author_obj2])
删除关系 remove
第一种
book_obj = models.Book.objects.filter(pk=1).first()
book_obj.authors.remove(3) # 括号放主键值
book_obj.authors.remove(3,4) # 也可以移除多个
第二种
author_obj1 = models.Author.objects.filter(pk=1).first()
author_obj2 = models.Author.objects.filter(pk=2).first()
book_obj.authors.remove(author_obj1) # 括号内可以放对象
book_obj.authors.remove(author_obj1,author_obj2)
清空关系 clear
book_obj = models.Book.objects.filter(pk=1).first()
book_obj.authors.clear()
回顾MySQL多表查询思路
子查询
将SQL语句用括号括起来当做条件使用
子查询>>>:基于对象的跨表查询
连表操作
inner join\left join\right join\union
django orm本质还是使用的上述两种方法
连表操作>>>:基于双下划线的跨表查询
正反向的概念
核心在于当前数据对象是否含有外键字段 有则是正向 没有则是反向
正向
eg:
由书籍查询出版社 外键字段在书籍表中 那么书查出版社就是'正向'
由书籍查询作者 外键字段在书籍表中 那么书查作者就是'正向'
由作者查询作者详情 外键字段在作者表中 那么也是'正向'
反向
eg:
由出版社查询书籍 外键字段不在出版社表 那么出版社查书就是'反向'
...
查询口诀
正向查询按外键字段名
反向查询按表名小写

"""基于对象的跨表查询本质就是子查询即分步操作即可"""
# 1.查询数据分析书籍对应的出版社
# 先获取书籍对象
# book_obj = models.Book.objects.filter(title='数据分析').first()
# 再使用跨表查询
# res = book_obj.publish
# print(res) # 出版社对象:北方出版社
# 2.查询python全栈开发对应的作者
# 先获取书籍对象
# book_obj = models.Book.objects.filter(title='python全栈开发').first()
# 再使用跨表查询
# res = book_obj.authors # app01.Author.None
# res = book_obj.authors.all()
# print(res) # <QuerySet [<Author: 作者对象:jason>, <Author: 作者对象:jerry>]>
# 3.查询作者jason的详情信息
# 先获取jason作者对象
# author_obj = models.Author.objects.filter(name='jason').first()
# 再使用跨表查询
# res = author_obj.author_detail
# print(res) # 作者详情对象:芜湖
# 4.查询东方出版社出版的书籍
# publish_obj = models.Publish.objects.filter(name='东方出版社').first()
# res = publish_obj.book_set # app01.Book.None
# res = publish_obj.book_set.all()
# print(res) # <QuerySet [<Book: 书籍对象:linux云计算>, <Book: 书籍对象:聊斋志异>]>
# 5.查询jason编写的书籍
# author_obj = models.Author.objects.filter(name='jason').first()
# res = author_obj.book_set # app01.Book.None
# res = author_obj.book_set.all()
# print(res) # <QuerySet [<Book: 书籍对象:golang高并发>, <Book: 书籍对象:python全栈开发>]>
# 6.查询电话是110的作者
author_detail_obj = models.AuthorDetail.objects.filter(phone=110).first()
res = author_detail_obj.author
print(res) # 作者对象:jason"""基于双下划线的跨表查询本质就是连表操作"""
# 基于双下划线的跨表查询
"""
查询数据分析书籍对应的价格和出版日期
models.Book.objects.filter(title='数据分析').values('price','publish_time')
"""
'''手上有什么条件就先拿models点该条件对应的表名'''
# 1.查询数据分析书籍对应的出版社名称
# res = models.Book.objects.filter(title='数据分析').values('publish__name', 'publish__addr')
# print(res) # <QuerySet [{'publish__name': '北方出版社', 'publish__addr': '北京'}]>
# 2.查询python全栈开发对应的作者姓名和年龄
# res = models.Book.objects.filter(title='python全栈开发').values('authors__name','authors__age')
# print(res) # <QuerySet [{'authors__name': 'jason', 'authors__age': 18}, {'authors__name': 'jerry', 'authors__age': 29}]>
# 3.查询作者jason的手机号和地址
# res = models.Author.objects.filter(name='jason').values('author_detail__phone','author_detail__addr')
# print(res) # <QuerySet [{'author_detail__phone': 110, 'author_detail__addr': '芜湖'}]>
# 4.查询东方出版社出版的书籍名称和价格
# res = models.Publish.objects.filter(name='东方出版社').values('book__title','book__price')
# print(res) # <QuerySet [{'book__title': 'linux云计算', 'book__price': Decimal('24888.44')}, {'book__title': '聊斋志异', 'book__price': Decimal('16987.22')}]>
# 5.查询jason编写的书籍名称和日期
# res = models.Author.objects.filter(name='jason').values('book__title', 'book__publish_time')
# print(res) # <QuerySet [{'book__title': 'golang高并发', 'book__publish_time': datetime.date(2022, 6, 7)}, {'book__title': 'python全栈开发', 'book__publish_time': datetime.date(2022, 2, 28)}]>
# 6.查询电话是110的作者的姓名和年龄
# res = models.AuthorDetail.objects.filter(phone=110).values('author__name','author__age')
# print(res) # <QuerySet [{'author__name': 'jason', 'author__age': 18}]>"""基于双下划线的跨表查询的结果也可以是完整的数据对象"""
'''手上有条件所在的表可以不被models点 直接点最终的目标数据对应的表'''
# 1.查询数据分析书籍对应的出版社名称
# res = models.Publish.objects.filter(book__title='数据分析')
# print(res) # <QuerySet [<Publish: 出版社对象:北方出版社>]>
# res = models.Publish.objects.filter(book__title='数据分析').values('name')
# print(res) # <QuerySet [{'name': '北方出版社'}]>
# 2.查询python全栈开发对应的作者姓名和年龄
# res = models.Author.objects.filter(book__title='python全栈开发').values('name','age')
# print(res) # <QuerySet [{'name': 'jason', 'age': 18}, {'name': 'jerry', 'age': 29}]>
# 3.查询作者jason的手机号和地址
# res = models.AuthorDetail.objects.filter(author__name='jason').values('phone','addr')
# print(res) # <QuerySet [{'phone': 110, 'addr': '芜湖'}]>
# 4.查询东方出版社出版的书籍名称和价格
# res = models.Book.objects.filter(publish__name='东方出版社').values('title','price')
# print(res) # <QuerySet [{'title': 'linux云计算', 'price': Decimal('24888.44')}, {'title': '聊斋志异', 'price': Decimal('16987.22')}]>
# 5.查询jason编写的书籍名称和日期
# res = models.Book.objects.filter(authors__name='jason').values('title','publish_time')
# print(res) # <QuerySet [{'title': 'golang高并发', 'publish_time': datetime.date(2022, 6, 7)}, {'title': 'python全栈开发', 'publish_time': datetime.date(2022, 2, 28)}]>
# 6.查询电话是110的作者的姓名和年龄
# res = models.Author.objects.filter(author_detail__phone=110).values('name','age')
# print(res) # <QuerySet [{'name': 'jason', 'age': 18}]>
# 连续跨表操作
# 查询python全栈开发对应的作者的手机号
# res = models.Book.objects.filter(title='python全栈开发').values('authors__author_detail__phone')
# print(res) # <QuerySet [{'authors__author_detail__phone': 110}, {'authors__author_detail__phone': 140}]>
res1 = models.AuthorDetail.objects.filter(author__book__title='python全栈开发').values('phone')
print(res1) # <QuerySet [{'phone': 110}, {'phone': 140}]>
"""
可能出现的不是疑问的疑问:如何获取多张表里面的字段数据
res = models.Book.objects.filter(title='python全栈开发').values('authors__author_detail__phone','authors__name','title')
print(res)
"""方式1:如果结果集对象是queryset 那么可以直接点query查看
方式2:配置文件固定配置
适用面更广 只要执行了orm操作 都会打印内部SQL语句
