
100W数据,测试复合索引
复合索引不是那么容易被catch到的。
两个查询条件都是等于的时候,才会被catch到。
mysql> select count(*) from tf_user_index where sex = 2 and score > 80;
+----------+
| count(*) |
+----------+
| 1261904 |
+----------+
1 row in set (10.65 sec)
mysql> select count(*) from tf_user where sex = 2 and score > 80;
+----------+
| count(*) |
+----------+
| 1261904 |
+----------+
1 row in set (4.38 sec)
mysql> explain select count(*) from tf_user_index where sex = 2 and score > 80;
+----+-------------+---------------+------+---------------+------+---------+-------+---------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+---------------+------+---------------+------+---------+-------+---------+-------------+
| 1 | SIMPLE | tf_user_index | ref | score,sex | sex | 1 | const | 4481227 | Using where |
+----+-------------+---------------+------+---------------+------+---------+-------+---------+-------------+
1 row in set (0.08 sec)
查询条件中,如果有大于号。那么优先抓取等于号对应的索引,也就是sex对应的索引。经过索引的一番折腾,查询时间反而更长了。
即便是把score放到前面,一样的效果。
mysql> explain select count(*) from tf_user_index where score> 80 and sex = 2;
+----+-------------+---------------+------+---------------+------+---------+-------+---------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+---------------+------+---------------+------+---------+-------+---------+-------------+
| 1 | SIMPLE | tf_user_index | ref | score,sex | sex | 1 | const | 4481227 | Using where |
+----+-------------+---------------+------+---------------+------+---------+-------+---------+-------------+
两个条件都为等于的时候,索引的效果就有点明显了。
mysql> select count(*) from tf_user_index where sex = 2 and score = 80;
+----------+
| count(*) |
+----------+
| 63230 |
+----------+
1 row in set (1.09 sec)
mysql> select count(*) from tf_user where sex = 2 and score = 80;
+----------+
| count(*) |
+----------+
| 63230 |
+----------+
1 row in set (2.61 sec)
mysql> explain select count(*) from tf_user_index where sex = 2 and score = 80;
+----+-------------+---------------+-------------+---------------+-----------+---------+------+--------+------------------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+---------------+-------------+---------------+-----------+---------+------+--------+------------------------------------------------------+
| 1 | SIMPLE | tf_user_index | index_merge | score,sex | score,sex | 4,1 | NULL | 124004 | Using intersect(score,sex); Using where; Using index |
+----+-------------+---------------+-------------+---------------+-----------+---------+------+--------+------------------------------------------------------+
1 row in set (0.00 sec)
这个时候,并没有添加复合索引。
加了复合索引,如果查询条件是大于号,一样catch不到。
mysql> explain select count(*) from tf_user_index where sex = 2 and score > 80;
+----+-------------+---------------+------+---------------------+------+---------+-------+---------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+---------------+------+---------------------+------+---------+-------+---------+-------------+
| 1 | SIMPLE | tf_user_index | ref | score,sex,score_sex | sex | 1 | const | 4481227 | Using where |
+----+-------------+---------------+------+---------------------+------+---------+-------+---------+-------------+
1 row in set (0.01 sec)
mysql> select count(*) from tf_user_index where score > 80 and sex =2;
+----------+
| count(*) |
+----------+
| 1261904 |
+----------+
1 row in set (15.32 sec)
竟然执行了15秒之久。
这条sql语句可以优化一下,将sex也改为大于号。
mysql> select count(*) from tf_user_index where score > 80 and sex >1;
+----------+
| count(*) |
+----------+
| 1261904 |
+----------+
1 row in set (0.66 sec)
mysql> explain select count(*) from tf_user_index where score > 80 and sex >1;
+----+-------------+---------------+-------+---------------------+-----------+---------+------+---------+--------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+---------------+-------+---------------------+-----------+---------+------+---------+--------------------------+
| 1 | SIMPLE | tf_user_index | range | score,sex,score_sex | score_sex | 4 | NULL | 4481227 | Using where; Using index |
+----+-------------+---------------+-------+---------------------+-----------+---------+------+---------+--------------------------+
1 row in set (0.00 sec)
这样就捕捉到了索引。
mysql> select count(*) from tf_user_index where score = 80 and sex = 1;
+----------+
| count(*) |
+----------+
| 62866 |
+----------+
1 row in set (0.01 sec)
mysql> explain select count(*) from tf_user_index where score = 80 and sex = 1;
+----+-------------+---------------+------+---------------------+-----------+---------+-------------+--------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+---------------+------+---------------------+-----------+---------+-------------+--------+-------------+
| 1 | SIMPLE | tf_user_index | ref | score,sex,score_sex | score_sex | 5 | const,const | 124794 | Using index |
+----+-------------+---------------+------+---------------------+-----------+---------+-------------+--------+-------------+
1 row in set (0.00 sec)
mysql> select count(*) from tf_user_index where sex = 1 and score=80;
+----------+
| count(*) |
+----------+
| 62866 |
+----------+
1 row in set (0.01 sec)
mysql> explain select count(*) from tf_user_index where sex = 1 and score=80;
+----+-------------+---------------+------+---------------------+-----------+---------+-------------+--------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+---------------+------+---------------------+-----------+---------+-------------+--------+-------------+
| 1 | SIMPLE | tf_user_index | ref | score,sex,score_sex | score_sex | 5 | const,const | 124794 | Using index |
+----+-------------+---------------+------+---------------------+-----------+---------+-------------+--------+-------------+
1 row in set (0.00 sec)
顺序并不重要。
索引,复合索引,确实可以提供查询的速度。关键是,要能够捕捉到。要能够找寻它们捕捉的规律。理解它们执行的过程。
合理的分析查询的规律,合理的给表添加索引。分析常用的查询,分析常用的查询字段。通过explain字段来进行sql语句的分析,优化sql语句。
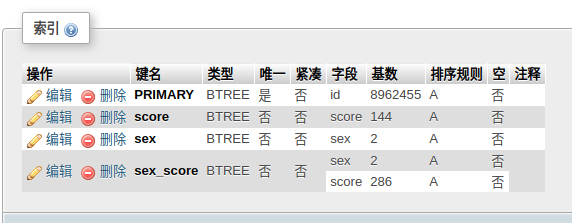
实践发现sex_score,score_sex查询的效果是一样的,关键是能否捕捉到。
mysql> explain select count(*) from tf_user_index where sex = 2 and score>80;
+----+-------------+---------------+-------+---------------------+-----------+---------+------+---------+--------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+---------------+-------+---------------------+-----------+---------+------+---------+--------------------------+
| 1 | SIMPLE | tf_user_index | range | score,sex,sex_score | sex_score | 5 | NULL | 2446346 | Using where; Using index |
+----+-------------+---------------+-------+---------------------+-----------+---------+------+---------+--------------------------+
1 row in set (0.00 sec)
mysql> select count(*) from tf_user_index where sex = 2 and score>80;
+----------+
| count(*) |
+----------+
| 1261904 |
+----------+
1 row in set (0.31 sec)
我屮艸芔茻,sex_score竟然捕捉到了索引。看来顺序还是有所区别的。这个建索引还是多多的实验吧。孰能生巧。

