

数据结构之快速排序
- 快速排序
是一种非常高效的排序方法,采用“分而治之”的思想,把大的拆分为小的,小的再拆分为更小的。
- 基本原理
对于一组给定的记录,通过一趟排序后,将原序列分为两部分,其中前一部分的所有记录都比后一部分的所有记录小,然后再依次对前后两部分的记录进行快速排序,递归该过程,直至序列中的所有记录均有序为止。
- 程序如下
public class Test{ public static void quickSort(int[] a, int low, int high){ int i, j, index; if(low>=high) return; i = low; j = high; index = a[i]; where(i<j){ while(i<j && a[j]>=index) j--; if(i<j) a[i++] = a[j]; while(i<j && a[i]<index) i++; if(i<j) a[j--] = a[i]; } a[i] = index; quickSort(a, low, i-1); quickSort(a, i+1, high); } public static void main(String[] args){ int[] a = {7,6,4,8,9,3,2}; quickSort(a,0,a.length-1); for(int i=0;i<a.length;i++){ System.out.print(a[i]+" "); } } }
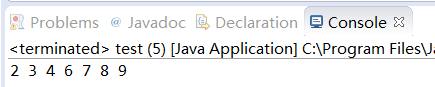
程序结果
- 快排特点
当初始的序列整体或局部有序时,快速排序的性能会下降,此时,快速排序将退化为冒泡排序。
1) 最坏时间复杂度。 选择的基准关键字是待排序的所有记录中最小或者最大的。这时记录与基准关键字的比较次数会增多。在这种情况下,需要进行(n-1)次区间划分。对于第k(0<k<n)次区间划分,划分前的序列长度为(n-k+1),需要进行(n-k)次记录的比较。因此,当k从1到(n-1)时,进行的比较次数总共为n(n-1)/2,所以,在最坏情况下时间复杂度为O(n2).
2) 最好时间复杂度。指每次区间划分的结果都是基准关键字左右两边的序列长度相等或者相差为1,即选择的基准关键字为待排序的记录中的中间值。此时,进行的比较次数为nlogn,所以,最好情况下时间复杂度为O(nlogn)。
3) 平均时间复杂度为O(nlogn)。虽然在最坏情况下时间复杂度为O(n2),但是在所有平均时间复杂度为O(nlogn)的算法中,快排的平均性能是最好的。
4) 空间复杂度。快排需要一个栈空间来实现递归。当最好情况时,递归树的最大深度为[logn]+1(logn为向上取整);当最坏情况时,递归树的最大深度为n。在每轮排序结束后比较基准关键字左右的记录个数,对多的一边进行排序,此时,栈的最大深度可降为logn。因此,快排的平均空间复杂度为O(logn)。
5) 基准关键字的选取。(基准关键字的选取是决定快排算法性能的关键)
(1) 三者取中。三者是指当前序列中,将其首、尾和中间位置上的记录进行比较,选择三者的中值作为基准关键字,在划分开始前交换序列中的第一个记录与基准关键字的位置。
(2) 取随机数。取左边left和右边right之间的一个随机数m(left<=m<=right),用n[m]作为基准关键字。这种方法使得n[left]和n[right]之间的记录时随机分布的,采用方法得到的快排一般称为随机的快速排序。
posted on 2017-03-27 22:01 一个不会coding的girl 阅读(314) 评论(0) 编辑 收藏 举报


