论文阅读:《Multimodal Machine Learning:A Survey and Taxonomy》
来源:Arxiv[https://arxiv.org/abs/1705.09406]
一、模态的定义
Modality:模态,某事发生或经历的方式
Multimodal:多模态
natural language :which can be both written or spoken 自然语言
visual signals: which are often represented with images or videos 视觉图片以及视频
vocal signals: which encode sounds and para-verbal information such as prosody and vocal expressions 声音
二、多模态面临的挑战
1、表征(Representation:如何以利用多种模态的互补性和冗余性的方式表示和总结多模态数据(how to represent and summarize multimodal data in a way that exploits the complementarity and redundancy of multiple modalities)
多模态数据的异质性:语言通常是象征性的,而音频和视觉形式将被表示为信号
2、翻译(Translation):如何将数据从一种模态转换(映射)到另一种模态(how to translate (map) data from one modality to another)
模态之间的关系通常是开放式的或主观的:存在多种描述图像的正确方法,并且可能不存在一种完美的翻译
3、对齐(Alignment):从两个或多个不同的模态中识别(子)元素之间的直接关系(identify the direct relations between (sub)elements from two or more different modalities)
4、融合(Fusion):结合来自两种或多种模态的信息来执行预测(join information from two or more modalities to perform a prediction)
5、联合学习(Co-learning):在模态、它们的表示和它们的预测模型之间转移知识(transfer knowledge between modalities, their representation, and their predictive models)
协同训练co-training 零样本学习zero shot learning
三、任务
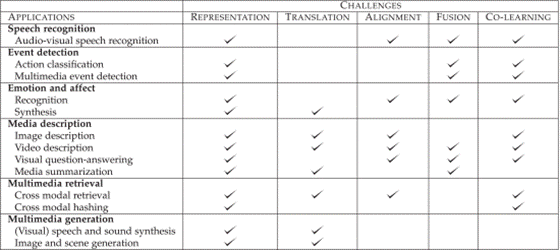
四、表征 Representation
解释:试图通过各模态的信息找到某种对多模态信息的统一表示
难题:如何组合来自异构来源的数据;如何处理不同级别的噪音;以及如何处理丢失的数据
好的表征的特点:
- 平滑度 smoothness
- 时间和空间连贯性 temporal and spatial coherence
- 稀疏性 sparsity
- 自然聚类 natural clustering
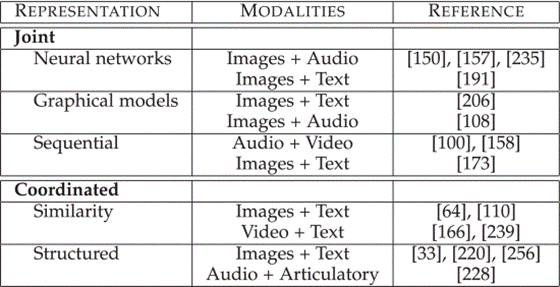
两种表征思路:
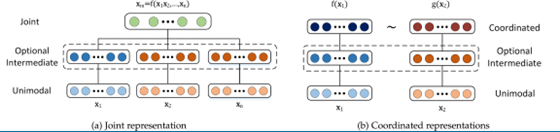
1、联合 joint
![]()
单模态的表示联合投影到多模态的联合表示
神经网络模型:通常使用最后或倒数第二个神经层作为单模态数据表示的一种形式,为了使用神经网络构建多模态表示,每个模态都从几个单独的神经层开始,然后是一个隐藏层,将模态投影到联合空间,然后联合多模态表示本身通过多个隐藏层或直接用于预测
概率图模型 Probabilistic graphical
RNN序列模型
tips:autoencoder models 自动编码器
2、协调 coordinated
![]()
每个模态学习单独的表示,并通过约束进行协调
基于相似度的模型:最小化协调空间中模态之间的距离
结构化协调模型:用于跨模态散列——将高维数据压缩成具有相似对象的相似二进制代码的紧凑二进制代码
代表:
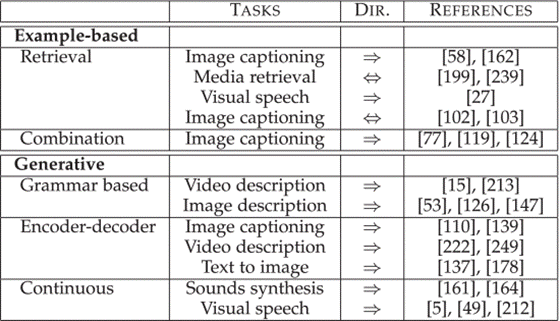
五、翻译 Translation
解释:将一种模态数据映射为另一种模态数据
两种思路:
1、example-based 基于示例的
- 翻译 跨模式检索 图像描述......
2、generative 生成
- 基于语法(grammar-based), 编码器-解码器模型(encoder-decoder), 连续生成(continuous generation)【基于源模态输入流连续生成目标模态,最适合在时间序列之间进行转换】
代表:
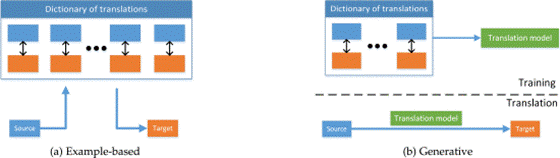
六、对齐 Alignment
解释:从两个甚至多个模态中寻找事物子成份之间的关系和联系。比如给定一张图片和图片的描述,找到图中的某个区域以及这个区域在描述中对应的表述。又比如给定一个美食制作视频和对应的菜谱,实现菜谱中的步骤描述与视频分段的对应。
两种思路:
1、显式对齐 explicit
- 重点是相似性度量。两种方法:无监督(动态时间扭曲 DTW) 、弱监督
2、隐式对齐 implicit
- 学习如何在模型训练期间潜在地对齐数据。两种方法:图模型、神经网络模型(使用attention机制)
- 图像字幕中,注意力机制将允许解码器(通常是 RNN)在生成每个连续单词时专注于图像的特定部分;
- 问答任务,允许将问题中的单词与信息源的子组件(例如一段文本[236]、图像[65]或视频序列)对齐。
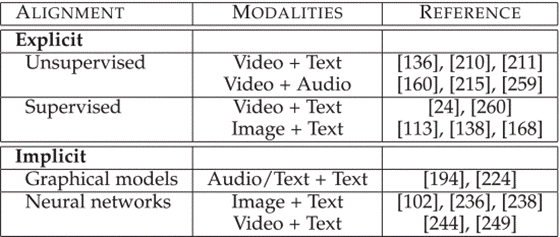
七、融合 Fusion
解释:从多个模态信息中整合信息来完成分类或回归任务
融合的价值:
- 在观察同一个现象时引入多个模态,可能带来更健壮(robust)的预测
- 接触多个模态的信息,可能让我们捕捉到互补的信息(complementary information),尤其是这些信息在单模态下并不"可见"时
- 一个多模态系统在缺失某一个模态时依旧能工作
两种思路:
1、无模型 model-agnostic
- 早期(基于特征,在特征被提取后立即集成(通常通过简单地连接它们的表示),比较简单)
- 晚期(基于决策,在每种模态做出决定(例如分类或回归)后执行整合,方法包括:平均、投票方案、基于信道噪声的加权、信号方差、学习模型,允许为每个模态使用不同的模型,因为不同的预测器可以更好地对每个单独的模态进行建模,从而提供更大的灵活性;当缺少一种或多种模态时,它可以更轻松地进行预测,甚至可以在没有并行数据时进行训练,然而忽略了模态之间的低级交互)
- 混合融合(早期融合和单个单峰预测器的输出)
2、基于模型 model-based
- Multiple Kernel learning(MKL),多核学习(将不同的核用于不同的数据模态/视图)
- Graphical models,图模型 后续可以看看
- Neural Networks,神经网络 循环神经网路,进行端到端的训练
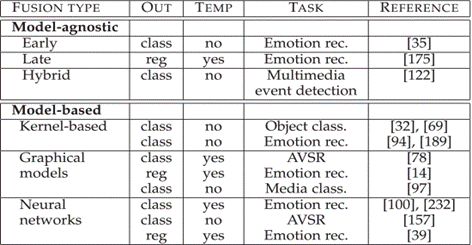
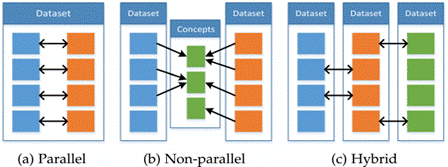
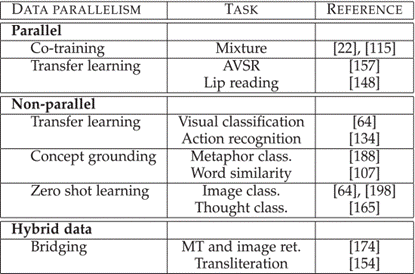
八、共同学习 Co-learning
解释:通过利用来自另一种(资源丰富)模态的知识来帮助(资源贫乏)模态建模;辅助模态(helper modality)通常只参与模型的训练过程,并不参与模型的测试使用过程
三种方法:
1、并行
- 需要训练数据集,其中来自一种模态的观察结果与来自其他模态的观察结果直接相关;协同训练、表示学习、迁移学习
2、非并行
- 不需要来自不同模式的观察之间的直接联系,通常通过使用类别重叠来实现共同学习;零样本学习ZSL
3、混合
- 通过共享模式或数据集桥接


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律