一次galera cluster集群故障节点无法启动问题排查
现象
环境:
Server version: 10.0.25-MariaDB-wsrep MariaDB Server, wsrep_25.13.raf7f02e
配置文件:
[root@node-23 mariadb]# more /etc/my.cnf [mysqld] server_id=3 bind_address = node-23 port = 3306 datadir=/var/lib/mysql log-error=/var/log/mariadb/mariadb-error.log collation-server = utf8_general_ci init-connect = 'SET NAMES utf8' character-set-server = utf8 skip-name-resolve default-storage-engine = innodb innodb_autoinc_lock_mode=2 binlog_format = ROW # LOGGING # log-queries-not-using-indexes = 0 slow-query-log = 0 slow-query-log-file = /var/log/mariadb/mariadb-slow.log log_error = /var/log/mariadb/mariadb-error.log log-bin = /var/lib/mysql/mariadb-bin log-bin-index = /var/lib/mysql/mariadb-bin.index expire-logs-days = 7 log_slave_updates = 1 # SAFETY # max-allowed-packet = 16M max-connect-errors = 100 max_connections = 10000 wait_timeout = 3600 # CACHES AND LIMITS # tmp-table-size = 32M max-heap-table-size = 32M query-cache-type = 0 query-cache-size = 0M thread-cache-size = 50 open-files-limit = 65535 #table-definition-cache = 4096 table-open-cache = 1024 # INNODB # innodb-flush-method = O_DIRECT #innodb-log-file-size = 10240M innodb-flush-log-at-trx-commit = 2 innodb-file-per-table = 1 #innodb-buffer-pool-size = 4096M # Depending on number of cores and disk sub innodb-read-io-threads = 4 innodb-write-io-threads = 4 innodb-doublewrite = 0 #innodb-log-buffer-size = 128M innodb-buffer-pool-instances = 8 innodb-log-files-in-group = 2 innodb-thread-concurrency = 64 # avoid statistics update when doing e.g show tables innodb_stats_on_metadata = 0 wsrep_provider=/usr/lib64/galera/libgalera_smm.so # wsrep_provider_options="pc.ignore_quorum = true; pc.ignore_sb=false; gmcast.listen_addr=tcp://node-23:4567;gcs.fc_limit = 256; gcs.fc_factor = 0.99; gcs.fc_master_sl ave=yes" wsrep_cluster_address=gcomm://node-22,node-21,node-23 wsrep_cluster_name="openstack-controller" wsrep_node_address="node-23" wsrep_node_name="mysql-galera-node-23" #wsrep_sst_method=rsync wsrep_sst_method=xtrabackup-v2 wsrep_sst_auth=sst_user:XXXXXXXXXX wsrep_slave_threads=4 # to enable debug level logging, set this to 1 wsrep_debug = 0 # how many times to retry deadlocked autocommits wsrep_retry_autocommit = 3 [xtrabackup] compress compact parallel = 4 compress-threads = 4 rebuild-threads = 4 [mysqldump] quick quote-names max_allowed_packet = 16M
三节点的galera cluster集群,有两个节点down了,时间较长,重启后都不能加入集群了。
报错节点启动日志:

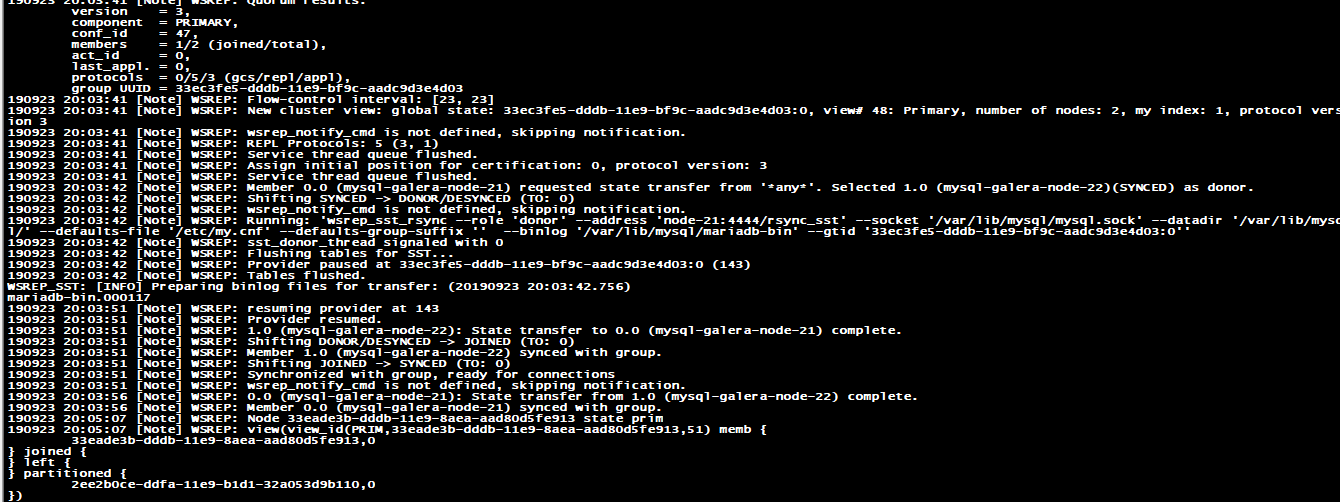
正常节点日志:
思路
1、日志没发现什么具体的报错信息
2、怀疑网络不通,发现没有
3、怀疑是不是日志不足所有导致初始化有问题,但是目前就是SSt全量的方式
4、查看主节点innobackup.backup.log日志也没有具体信息
解决
备份方式改为rsync模式,启动后改为xtrabackup-v2,重新启动容器
---当才华撑不起你的野心的时候,请努力!---

