


grep 详解
grep
是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。(global search regular expression(RE) and print out the line,全面搜索正则表达式并把行打印出来)
常见用法
1. ps -ef | grep **** 配合 ps 命令 用的比较多。
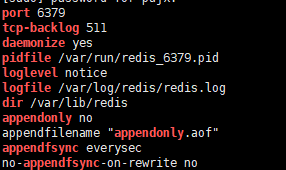
2. grep -Ev "^#|^$" /etc/redis.conf 查看redis配置文件的不以#开头 或者是空行 的内容
以下就是输出的内容


protected-mode no port 6379 tcp-backlog 511 timeout 0 tcp-keepalive 300 daemonize yes supervised no pidfile /var/run/redis_6379.pid loglevel notice logfile /var/log/redis/redis.log databases 16 save 900 1 save 300 10 save 60 10000 stop-writes-on-bgsave-error no rdbcompression yes rdbchecksum yes dbfilename dump.rdb dir /var/lib/redis slave-serve-stale-data yes slave-read-only yes repl-diskless-sync no repl-diskless-sync-delay 5 repl-disable-tcp-nodelay no slave-priority 100 appendonly no appendfilename "appendonly.aof" appendfsync everysec no-appendfsync-on-rewrite no auto-aof-rewrite-percentage 100 auto-aof-rewrite-min-size 64mb aof-load-truncated yes lua-time-limit 5000 slowlog-log-slower-than 10000 slowlog-max-len 128 latency-monitor-threshold 0 notify-keyspace-events "" hash-max-ziplist-entries 512 hash-max-ziplist-value 64 list-max-ziplist-size -2 list-compress-depth 0 set-max-intset-entries 512 zset-max-ziplist-entries 128 zset-max-ziplist-value 64 hll-sparse-max-bytes 3000 activerehashing yes client-output-buffer-limit normal 0 0 0 client-output-buffer-limit slave 256mb 64mb 60 client-output-buffer-limit pubsub 32mb 8mb 60 hz 10 aof-rewrite-incremental-fsync yes
如果先嫌显示的太多,可以在后面再加 | grep -E "bind|port|tcp-backlog|daemonize|pidfile|loglevel|logfile|dir|requirepass|appendonly|appendfsync" 就会显示你要的含有关键词的内容
3. 其他方法我不常用,就先不写。
参数
- -a 或 --text : 不要忽略二进制的数据。
- -A<显示行数> 或 --after-context=<显示行数> : 除了显示符合范本样式的那一列之外,并显示该行之后的内容。
- -b 或 --byte-offset : 在显示符合样式的那一行之前,标示出该行第一个字符的编号。
- -B<显示行数> 或 --before-context=<显示行数> : 除了显示符合样式的那一行之外,并显示该行之前的内容。
- -c 或 --count : 计算符合样式的列数。
- -C<显示行数> 或 --context=<显示行数>或-<显示行数> : 除了显示符合样式的那一行之外,并显示该行之前后的内容。
- -d <动作> 或 --directories=<动作> : 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep指令将回报信息并停止动作。
- -e<范本样式> 或 --regexp=<范本样式> : 指定字符串做为查找文件内容的样式。
- -E 或 --extended-regexp : 将样式为延伸的普通表示法来使用。【就是可以匹配多个,匹配多个用 | 符号】
- -f<规则文件> 或 --file=<规则文件> : 指定规则文件,其内容含有一个或多个规则样式,让grep查找符合规则条件的文件内容,格式为每行一个规则样式。
- -F 或 --fixed-regexp : 将样式视为固定字符串的列表。
- -G 或 --basic-regexp : 将样式视为普通的表示法来使用。
- -h 或 --no-filename : 在显示符合样式的那一行之前,不标示该行所属的文件名称。
- -H 或 --with-filename : 在显示符合样式的那一行之前,表示该行所属的文件名称。
- -i 或 --ignore-case : 忽略字符大小写的差别。
- -l 或 --file-with-matches : 列出文件内容符合指定的样式的文件名称。
- -L 或 --files-without-match : 列出文件内容不符合指定的样式的文件名称。
- -n 或 --line-number : 在显示符合样式的那一行之前,标示出该行的列数编号。
- -q 或 --quiet或--silent : 不显示任何信息。
- -r 或 --recursive : 此参数的效果和指定"-d recurse"参数相同。
- -s 或 --no-messages : 不显示错误信息。
- -v 或 --revert-match : 显示不包含匹配文本的所有行。【取相反的意思】
- -V 或 --version : 显示版本信息。
- -w 或 --word-regexp : 只显示全字符合的列。
- -x --line-regexp : 只显示全列符合的列。
- -y : 此参数的效果和指定"-i"参数相同。
欢迎博友指出错误,我将改进,共同提高技术。

