[神经网络与深度学习笔记]LDA降维
LDA降维
LinearDiscriminant Analysis 线性判别分析,是一种有监督的线性降维算法。与PCA保持数据信息不同,LDA的目标是将原始数据投影到低维空间,尽量使同一类的数据聚集,不同类的数据尽可能分散
步骤:
- 计算类内散度矩阵\(S_b\)
- 计算类间散度矩阵\(S_w\)
- 计算矩阵\(S_w^{-1}S_b\)
- 对矩阵\(S_w^{-1}S_b\)进行特征分解,计算最大的\(d\)个最大的特征值对应的特征向量组成\(W\)
- 计算投影后的数据点\(Y = W^TX\)
其中的内散度矩阵\(S_b\)、类间散度矩阵\(S_w\),概念复杂,是一种距离度量方法,我们通过计算机帮助计算即可。
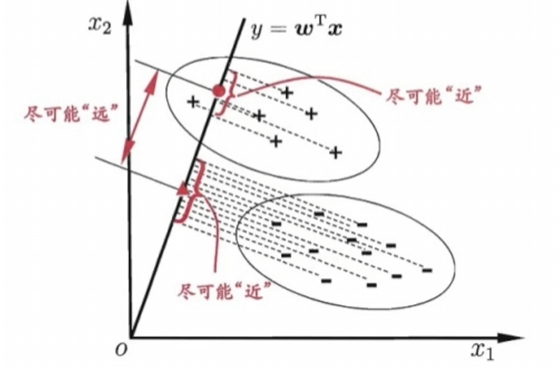
导入iris数据
import numpy as np
import pandas as pd
df=pd.read_csv(r'iris.data')
print(df.shape)
#查看类别
print(set(df['Iris-setosa']))
df.columns=['sepal length','sepal width',
'petal length','petal width','class label']
df.head(6)
转换标签数据,然后将四维数据特征进行降维
from sklearn.preprocessing import LabelEncoder
X=df[['sepal length','sepal width',
'petal length','petal width']].values
y=df['class label'].values
#映射标签(使用sklearn包快速完成标签转换)
enc=LabelEncoder()
y=enc.fit_transform(y)+1
print(set(y))

import numpy as np
np.set_printoptions(precision=4)
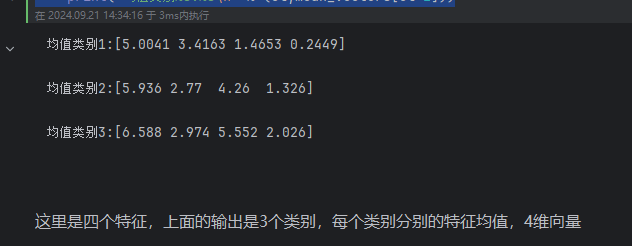
#保存均值
mean_vectors=[]
#计算类别
for cl in range(1,4):
mean_vectors.append(np.mean(X[y==cl],axis=0))
print('均值类别%s:%s\n' % (cl,mean_vectors[cl-1]))
不使用sklearn
计算类内散步矩阵
\(S_W=\sum_{i=1}^cS_i\)
\(S_i=\sum_{z\in D_i}^n\left(x-m_i\right)\left(x-m_i\right)^\mathrm{T}\)
\(m_i=\frac{1}{n_i}\sum_{x\in D_i}^nx_k\)
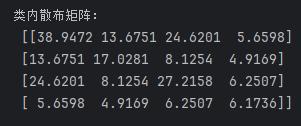
s_w=np.zeros((4,4)) #4个特征
for cl,mv in zip(range(1,4),mean_vectors):
class_sc_mat=np.zeros((4,4))
for row in X[y==cl]:
#对每个特征进行计算
row,mv=row.reshape(4,1),mv.reshape(4,1)
#上面的计算公式
class_sc_mat+=(row-mv).dot((row-mv).T)
s_w+=class_sc_mat
print('类内散布矩阵:\n',s_w)
计算类间散步矩阵
$S_B=\sum_{i=1}cN_i(m_i-m)(m_i-m)\top $
#全局均值
overall_mean=np.mean(X,axis=0)
overall_mean

#类间散布矩阵
s_b=np.zeros((4,4))
#对各类别分别计算
for i,mean_vec in enumerate(mean_vectors):
#当前类别样本数
n=X[y==i+1,:].shape[0]
mean_vec=mean_vec.reshape(4,1)
overall_mean=overall_mean.reshape(4,1)
#上述公式
s_b+=n*(mean_vec-overall_mean).dot((mean_vec-overall_mean).T)
print('类间散布矩阵:\n',s_b)
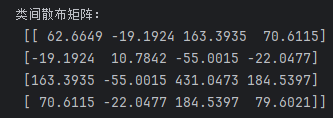
#求解特征值、特征向量
eig_vals,eig_vecs=np.linalg.eig(np.linalg.inv(s_w).dot(s_b)) #s_w求解逆矩阵
for i in range(len(eig_vals)):
eigvec_sc=eig_vecs[:,i].reshape(4,1)
print('\n特征向量{}:\n{}'.format(i+1,eigvec_sc.real))
print('特征值{:}: {:.2e}'.format(i+1,eig_vals[i].real))
特征向量1:
[[-0.2051]
[-0.3869]
[ 0.5463]
[ 0.714 ]]
特征值1: 3.19e+01
特征向量2:
[[-0.0084]
[-0.5891]
[ 0.2545]
[-0.7669]]
特征值2: 2.77e-01
特征向量3:
[[ 0.8205]
[-0.144 ]
[-0.0962]
[-0.5448]]
特征值3: -3.90e-15
特征向量4:
[[-0.5111]
[ 0.4445]
[ 0.4866]
[-0.5517]]
特征值4: -6.27e-16
得到4个特征向量和其对应的特征值。
特征值越大,所对应的特征向量越重要,所以接下来可进行排序。
#特征值和特征向量配对
eig_pairs=[(np.abs(eig_vals[i]),eig_vecs[:,i]) for i in range(len(eig_vals))]
#排序
eig_pairs=sorted(eig_pairs,key=lambda k:k[0],reverse=True)
print('特征排序结果:\n')
for i in eig_pairs:
print(i[0])
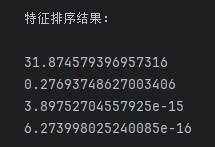
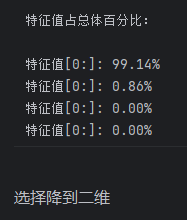
print('特征值占总体百分比:\n')
eigv_sum=sum(eig_vals)
for i,j in enumerate(eig_pairs):
print('特征值[0:]: {1:.2%}'.format(i+1,(j[0]/eigv_sum).real))
W=np.hstack((eig_pairs[0][1].reshape(4,1),
eig_pairs[1][1].reshape(4,1)))
print('矩阵W:\n',W.real)

#执行降维
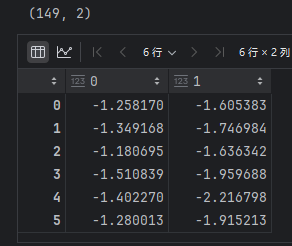
X_lda=X.dot(W)
print(X_lda.shape)
pd.DataFrame(X_lda).head(6)
import matplotlib.pyplot as plt
def plot_lda():
ax=plt.subplot(111)
for label,marker,color in zip(
range(1,4),('^','s','o'),('blue','red','green')):
plt.scatter(x=X[:,0].real[y==label],
y=X[:,1].real[y==label],
marker=marker,
color=color,
alpha=0.5,
label=y[label])
plt.xlabel('X[0]')
plt.ylabel('X[1]')
#plt.legend()
plot_lda()
源数据挑两个维度作图:
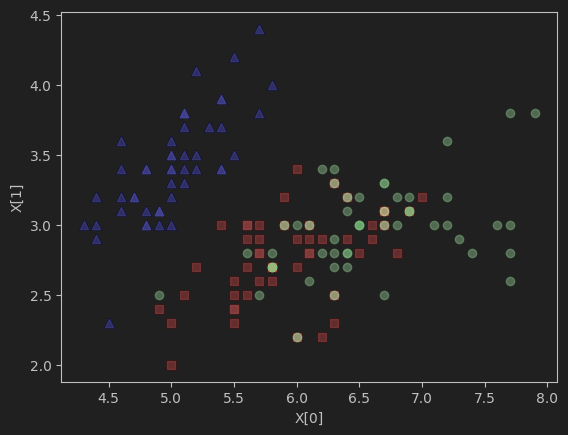
降维后用数据作图:
def plot_lda():
ax=plt.subplot(111)
for label,marker,color in zip(
range(1,4),('^','s','o'),('blue','red','green')):
plt.scatter(x=X_lda[:,0].real[y==label],
y=X_lda[:,1].real[y==label],
marker=marker,
color=color,
alpha=0.5,
label=y[label])
plt.xlabel('X[0]')
plt.ylabel('X[1]')
#plt.legend()
plot_lda()
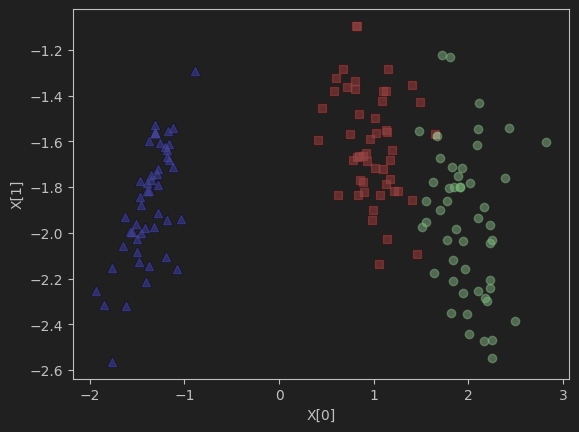
如果对原始数据集随机取两维数据,数据集并不能按类别划分开,但降维后的数据点,区分的较为明显
使用sklearn版本
#使用sklearn版本
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA
sklearn_LDA=LDA(n_components=2)
X_lda_sklearn=sklearn_LDA.fit_transform(X,y)
pd.DataFrame(X_lda_sklearn).head(6)
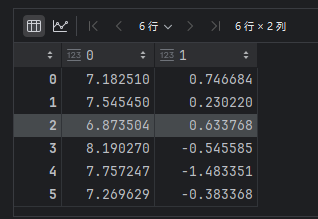
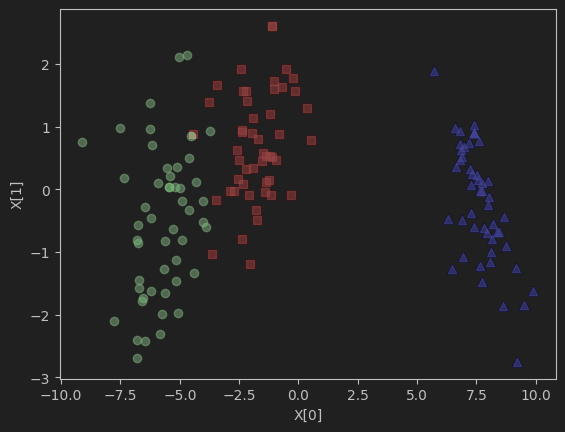
def plot_lda():
ax=plt.subplot(111)
for label,marker,color in zip(
range(1,4),('^','s','o'),('blue','red','green')):
plt.scatter(x=X_lda_sklearn[:,0].real[y==label],
y=X_lda_sklearn[:,1].real[y==label],
marker=marker,
color=color,
alpha=0.5,
label=y[label])
plt.xlabel('X[0]')
plt.ylabel('X[1]')
#plt.legend()
plot_lda()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号