
数据库调优-03 (索引)
四、索引
1、索引数据结构
1.1 B-Tree 索引
B-Tree
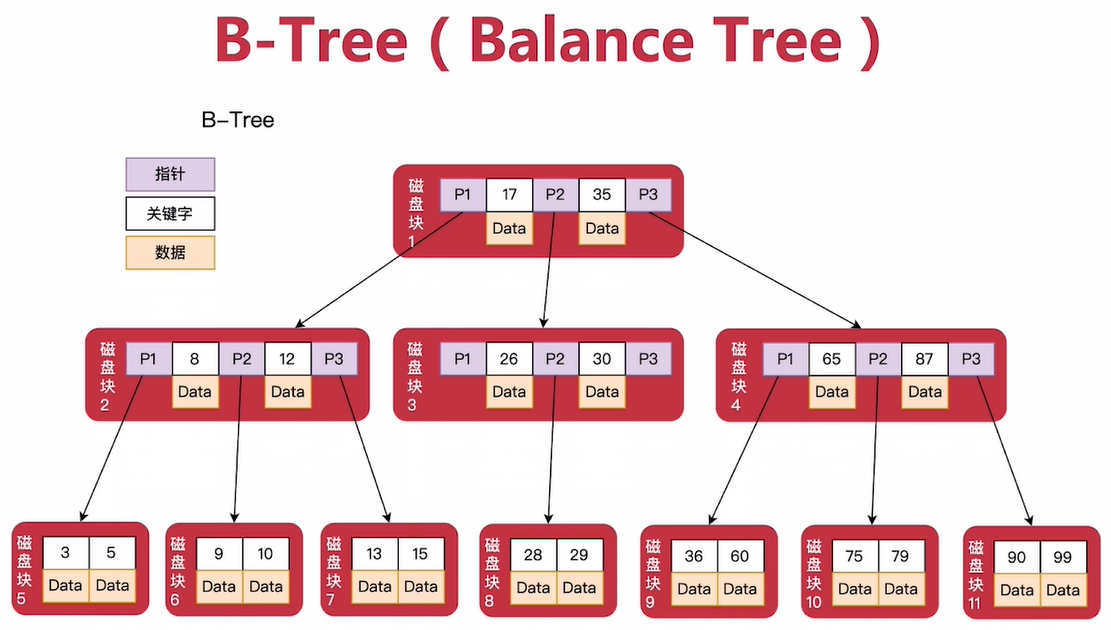
特点:
-
根节点的子节点个数2 <=x<=m ,m是树的阶
- 假设m =3,则根节点可以有2-3个孩子
-
中间节点的子节点个数m/2 <=y <=m
- 假设m=3,中间节点至少有2个孩子,最多3个孩子
-
每个中间节点包含n个关键字,n=子节点个数-1,且按升序排序
- 如果中间节点有3个子节点,则里面会有2个关键字,且按升序排序(磁盘块3是有三个子节点的,另外两个没有画出来)
-
Pi(i-1..n+1)为指向子树根节点的指针。其中P[1]指向关键字小于Key[1]的子树, P[i]指向关键字属于(Key[i-1], Key[i])的子树, P[n+1]指向关键字大于Key[n]的子树
- P1,P2,P3为指向子树根节点的指针,P1指向关键字小于Key1的树; P2指向key1-key2之间的子树; P3指向大于Rey2的树
B+Tree
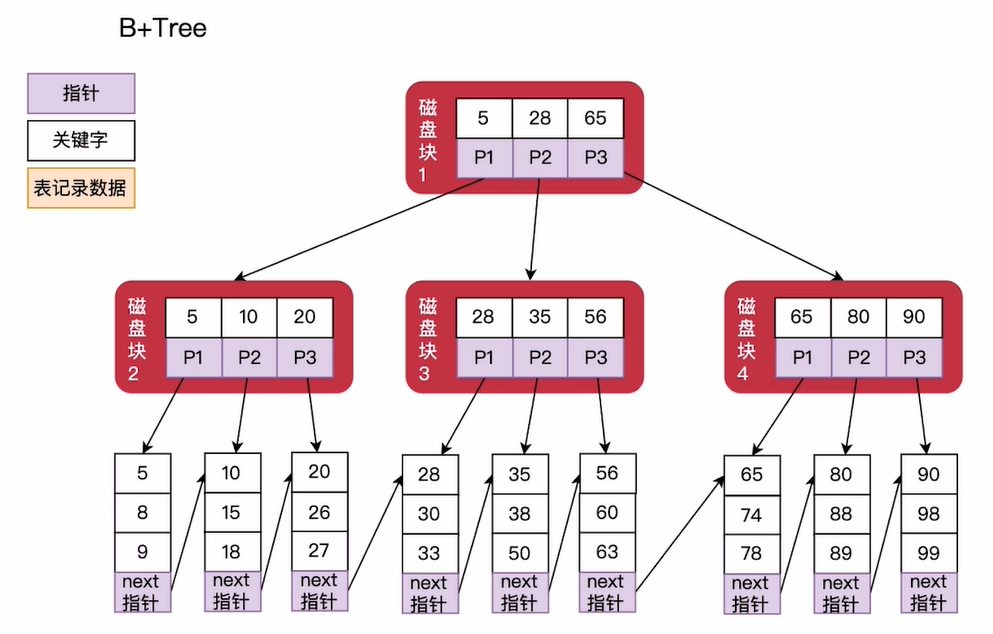
B+Tree 是在 B-Tree 基础上的一种优化
InnoDB 存储引擎使用 B+Tree 实现其索引结构
B+Tree 和 B-Tree 的差异
-
B+Tree有n个子节点的节点中含有n个关键字
- B-Tree是n个子节点的节点有n-1个关键字
-
B+ Tree中,所有的叶子节点中包含了全部关键字的信息,且叶子节点按照关键字的大小自小而大顺序链接,构成一个有序链表
- B-Tree的叶子节点不包括全部关键字
-
B+ Tree中,非叶子节点仅用于索引,不保存数据记录,记录存放在叶子节点中
- B-Tree中,非叶子节点既保存索引,也保存数据记录
1.2 MYSQL各存储引擎存储方式
InnoDB
- B+Tree
- 主键索引:叶子节点存储主键及数据;
- 非主键索引(二级索引、辅助索引) :叶子节点存储索引以及主键,因此非主键索引查询数据会先找到对应的主键,再通过主键找到数据。
MyISAM
- B+Tree
- 主键/非主键索引的叶子节点都是存储指向数据块的指针,即它的数据和索引是分开存储的。
InnoDB的索引又称为聚簇索引,MyISAM的索引又称为非聚簇索引。
Memory
Memor引擎显示支持Hash索引
create table test_hash_table(
name varchar(45) not nult,
age tinyint(4) not nulL,
key using hash(name)
)engine = memory;
InnoDB引擎虽然不支持手动创建Hash索引,但它有一个"自适应Hash索引"的功能。当InnoDB发现某些索引值使用的非常频繁的话,它会在内存中基于B+Tree的索引之上在创建一个Hash索引,从而提升查询效率。这个"自适应Hash索引"我们没有办法直接介入,它只有一个开关,用show variables like innodb_adaptive_hash_index查看开关情况,set global innodb_adaptive_hash_index = 'OFF'可以关闭。
1.3 B-Tree(B+Tree)索引特性
- 完全匹配:index(name) => where name='刘德华',可以用到索引;
- 范围匹配: index(age) => where age > 5,可以用到索引;
- 前缀匹配: index(name) => where name like '刘%',可以用到索引,注意右模糊是可以使用索引,但左模糊却不行,即
like '%刘'无法使用索引。
对于组合索引:以index(name,age,sex)为例
-
查询条件不包含最左列(name字段),无法使用索引
- where age=5 and sex=1 是无法使用索引的
-
跳过了索引中的列,则无法完全使用索引
- where name='jim' and sex=1 就只能用name这一列
-
查询中有某个列的范围(模糊)查询,则其右边所有列都无法使用索引
- where name='jim' and age>18 and sex=1 就只能用name、age两列
以上3点限制就是最左前缀原则。
2、索引的创建原则
2.1 建议创建索引的场景
- select语句,频繁作为where条件的字段
select * from employees where first_name = 'Georgi';
-- 可以创建索引 index(first_name)
select * from employees where first_name = 'Georgi' and last_name = 'Cools';
-- 可以创建组合索引 index(first_name, last_name),注意最左前缀原则
-
update/delete语句的where条件的字段
update/delete语句会先根据where条件查询出对应的数据再做处理,添加索引可以提升查询时的效率。 -
需要分组、排序的字段
select dept_no, count(*) from dept_emp group by dept_no;
-- 可以创建索引 index(dept_no)
- distinct所使用的字段
select distinct(first_name) from employees;
-- 可以创建索引 index(first_name)
-
字段的值有唯一性约束
比用用户表中的用户名是不能重复的,用户名字段具有唯一性约束,可以创建索引。 -
对于多表查询,联接字段应创建索引,且类型务必保持一致(否则会导致隐式转换,导致索引无法使用)
2.2 不建议创建索引的场景
- where子句中用不到的字段
- 表的记录非常少
- 有大量重复数据的字段,选择性低(例如用户表里的性别字段)
- 索引的选择性越高,查询效率越好,因为可以过滤更多的行
- 频繁更新的字段,如果创建索引要考虑其索引维护开销
以上只是一般情况下的原则,实际工作中还是要根据实际情况合理的变通。
3、可能导致索引失效的场景
- 索引列不独立。独立是指:列不能是表达式的一部分,也不能是函数的参数
-- 示例1:索引字段不独立(索引字段进行了表达式计算)
select * from employees where id + 1 = 10003;
-- 解决方案:事先计算好表达式的值,再传过来,避免在SQLwhere条件 = 的左侧做计算
select * from employees where id = 10002;
-- 示例2:索引字段不独立(索引字段是函数的参数)
select * from employees where SUBSTRING(first_name, 1, 3) = 'Geo';
-- 解决方案:预先计算好结果,再传过来,在where条件的左侧,不要使用函数;或者使用等价的SQL去实现
select * from employees where first_name like 'Geo%';
- 使用了左模糊
select * from employees where first_name like '%Geo%';
-- 解决方案:尽量避免使用左模糊,如果避免不了,可以考虑使用搜索引擎去解决
- 使用OR查询的部分字段没有索引
select * from employees where first_name = 'Georgi' or last_name = 'Georgi';
-- 解决方案:分别为first_name以及last_name字段创建索引
- 字符串条件未使用''引起来
select * from dept_emp where dept_no = 3;
-- 解决方案:规范地编写SQL
select * from dept_emp where dept_no = '3';
- 不符合最左前缀原则的查询
-- 存在index(last_name, first_name)
select * from employees where first_name = 'Facello';
-- 解决方案:调整索引的顺序,变成index(first_name,last_name)或index(first_name)
- 索引字段建议添加NOT NULL约束
select * from users where mobile is null;
-- 解决方案:
把索引字段设置成NOT NULL,甚至可以把所有字段都设置成NOT NULL并为字段设置默认值
-- 单列索引无法储null值,复合索引无法储全为null的值
-- 查询时,采用is null条件时,不能利用到索引,只能全表扫描
-- MySQL官方建议尽量把字段定义为NOT NULL:https://dev.mysql.com/doc/refman/8.0/en/data-size.html
- 隐式转换导致索引失效
select a.*,b.id from test1 a
left join test2 b on a.id=b.a_id
-- 这其中a.id和b.a_id字段类型必须一样,否则会触发隐式转换导致索引失效
4、索引调优技巧
4.1 长字段的索引调优
实际项目中有时可能会索引一个很长的字符串字段,这个时候会导致索引占用的空间比较大,此时查询效率也不会很高。那么这种情况下该怎么样优化呢?
方式一:
创建一个冗余字段存储长字段对应的hash值,将索引加在这个hash字段上,这样当where条件匹配时使用hash值进行匹配。
-- 这里假设first_name字段是个长字段,first_name_hash是冗余的hash字段
insert into employees (emp_no, birth_date, first_name, last_name, gender, hire_date, first_name_hash)
value (
1001, now(),
'大目......................',
'大', 'M', now(),
CRC32('大目......................')
);
first_name_hash的值应该具备以下要求:
- 字段的长度应该比较的小,SHA1/MD5两种算法是不合适的
- 应当尽量避免hash冲突,就目前来说,流行使用CRC32()或者FNV64()
查询语句示例:
select * from employees where first_name_hash = CRC32('Facello') and first_name = 'Facello';
方式二:
上面方式一是对长字段值的完整匹配的优化方案,那如果需要模糊匹配又该怎么办呢?我们需要使用前缀索引。
创建前缀索引语句示例:
alter table employees add key (first_name(n));
这里的n代表以first_name字段前那个字符创建索引,那么这个n取多大合适呢?我们肯定希望这个n尽可能小,这样即节省空间也提升性能,并且n长度字符串的选择性也要足够的高。
我们可以通过索引的选择性公式来计算:
索引的选择性 = 不重复的索引值 / 数据表的总记录数
首先我们算出完整的一列它的选择性,这里仍以first_name字段为例:
-- 完整列的选择性:结果是0.0042 [这个字段的最大选择性了]
select count(distinct first_name)/count(*) from employees;
接着我们通过改变n值大小来接近这个最大选择性:
select count(distinct left(first_name, 8))/count(*) from employees;
-- 5: 0.0038 6:0.0041 7:0.0042 8:0.0042
我们可以得出结论,当n=7时就已经可以达到最大选择性了,所以n值设为7是最好的:
alter table employees add key (first_name(7));
前缀索引的局限性:无法做order by、group by;无法使用覆盖索引。
4.2 使用组合索引
在SQL存在多个条件,且存在多个单列索引时。MySQL会使用索引合并(type=index_merge)。出现索引合并往往说明索引不够合理,可以改为组合索引。
当然上面的建议不是必须的,如果SQL暂时没有性能问题,那么就可以不用管,反之SQL如果达不到性能要求,这是就可以考虑改成组合索引。而且组合索引必须要要注意索引顺序,即最左前缀原则。
4.3 覆盖索引
对于索引X,SELECT的字段只需从索引就能获得,而无需到表数据里获取,这样的索引就叫覆盖索引。覆盖索引是可以有效提升性能的。
例如:
-- 这里创建了组合索引index(first_name, last_name),那么下面的语句就会使用到覆盖索引
select first_name, last_name from employees where first_name = 'Georgi' and last_name = 'Georgi';
4.5 冗余、重复、未使用索引优化
重复索引:在相同的列上按照相同的顺序创建的索引。
示例:
create table test_table (
id int not null primary key auto_increment,
a int not null,
b int not null,
UNIQUE (id),
INDEX (id)
) ENGINE = InnoDB;
上面的语句中对于id字段同时使用了主键、唯一索引和普通索引。其实唯一索引就是在普通索引的基础上加上了唯一性约束,而主键又在唯一索引基础上加上了非空约束。所以说这是相当于在ID这个字段上创建了三个重复索引。
我们只要把唯一索引和普通索引删掉就行了。
冗余索引:如果已经存在索引 index(A, B),又创建了 index(A),那么index(A)就是index(A, B)的冗余索引。
冗余索引一般情况下是需要避免的,但也不是绝对的看下面的示例:
explain
select *
from salaries
where from_date = '1986-06-26'
order by emp_no;
其中emp_no是主键,此时我们加一个索引 index(from_date),explain的结果是 type=ref | extra=null,表明使用了索引,这某种意义上来说是相当于一个组合索引 index(from_date, emp_no)的。
然后我们删除index(from_date)索引,新增一个index(from_date, to_date)索引,explain的结果是 type=ref | extra=Using filesort,这表明order by子句无法使用索引,这是为什么呢?应为这个索引相当于index(from_date, to_date, emp_no),不符合最左前缀原则,所以想做性能优化的话可以添加个冗余索引index(from_date)。
未使用的索引即使故名思意的,应该要把它删掉就行了。
5、索引类型
MySQL有多种索引类型,使用不同的角度,分类也有所不同。
先说结论:
从数据结构角度,可分为:
- B+树索引
- hash索引
- 空间数据索引(R-Tree索引)
- 全文索引
从功能逻辑角度,可分为:
- 普通索引
- 唯一索引
- 主键索引
- 组合索引
- 全文索引
从物理存储角度,可分为:
- 聚簇索引
- 非聚簇索引
5.1 从功能逻辑角度
5.1.1 普通索引
普通索引是基础的索引,没有任何约束,主要用于提高查询效率。示例:
CREATE INDEX index_name ON table(column(length))
5.1.2 唯一索引
唯一索引就是在普通索引的基础上增加了数据唯一性的约束,索引列的值必须唯一,允许有NULL值。如果一个唯一索引同时还是个组合索引,那么表示列值的组合必须唯一。在一张数据表里可以有多个唯一索引。示例:
CREATE UNIQUE INDEX indexName ON table(column(length))
5.1.3 主键索引
主键索引是一种特殊的唯一索引,不允许有NULL值,并且一张表最多只有一个主键索引。
5.1.4 组合索引
指多个字段上创建的索引,使用组合索引时遵循最左前缀原则。示例:
CREATE index index_name CREATE table (column1, column2);
5.1.5 全文索引
全文索引,用来检索文本中的关键字,用得很少,一般应对这种需求用Elasticsearch或者Solr之类的全文搜索引擎。
5.2 从物理存储角度(聚簇索引、非聚簇索引)
聚簇索引的叶子节点就是数据节点,而非聚簇索引的叶子节点不存储数据,而是指向对应数据块的指针。
InnoDB的主键索引使用的是聚簇索引,而MyISAM使用了非聚簇索引。
-
表数据和主键一起存储的,聚簇索引的数据的物理存放顺序与索引顺序是一致的,即:只要索引是相邻的,那么对应的数据一定也是相邻地存放在磁盘上的。而由于无法同时把数据行同时存放在两个不同的地方,所以一张表只有一个聚簇索引。
- 聚簇索引的二级索引:叶子节点不会保存引用的行的物理位置,而是保存行的主键值。
-
非聚簇索引:叶子节点存储的是数据块的指针。表数据和索引分开存储。查询时,先找到索引,再根据索引找到对应的数据行
聚簇索引 vs 非聚簇索引
聚簇索引优点:
- 查找效率理论上比非聚簇索引要高,但是插入、修改、删除操作的性能比非聚簇索引要低
- 范围查询方便
聚簇索引缺点:
- 插入速度严重依赖于插入顺序,因此,对于InnoDB表,我们一般都会定义一个自增的ID列为主键
- 更新主键的代价很高,因为将会导致被更新的行移动。(当然一般不会更新主键)
- 聚簇索引增删改操作性能比非聚簇索引性能低
对于InnoDB:
- 主键使用聚簇索引,并且一张表有且只有1个聚簇索引。如果创建的表没有主键,则InnoDB会隐式定义一个主键来作为聚簇索引。
- 二级索引(非主键索引)叶子节点存储的是行的主键值,因此使用二级索引命中数据需要查询两次,先用二级索引搜索到主键,再用主键查找数据。
参考文档:
聚集索引与非聚集索引的总结
说一下聚簇索引 & 非聚簇索引
Mysql聚簇索引和非聚簇索引原理(数据库)
MySQL中MyISAM和InnoDB对B-Tree索引不同的实现方式
