

从python 单机版爬虫 scrapy 到 分布式scrapy-redis 爬虫用最简单的步骤创建实例
scrapy 是很强大的模块化爬虫框架,具有很高的灵活性,使用频率很高,使用该框架能大大提高开发效率,scrapy-redis是在scrapy框架开发了组件,替换队列部分,实现多台服务器并行运行爬虫,提高爬取速度。下面是用最简单的例子从建立普通scrapy爬虫,然后数据保存mysql ,最后简单替换几行就能使用scrapy-redis改造为分布式爬虫。
一 创建最简单的爬取cnblogs 首页标题的爬虫
1 使用命令行安装 scrapy
pip install scrapy
2 使用命令行运行scrapy命令创建 scrapy项目
scrapy startproject cnblogprojct
进入 新创建的scrapyproject 目录并创建爬虫
cd cnblogprojct
scrapy genspider cnblogs cnblogs.com
然后基本的框架就创建好了

打开cnblogs.py
增加:
print(response.css('title'))
如下图

然后用命令行运行爬虫
scrapy crawl cnblogs
可以看到已经抓取并打印cnblogs的标题
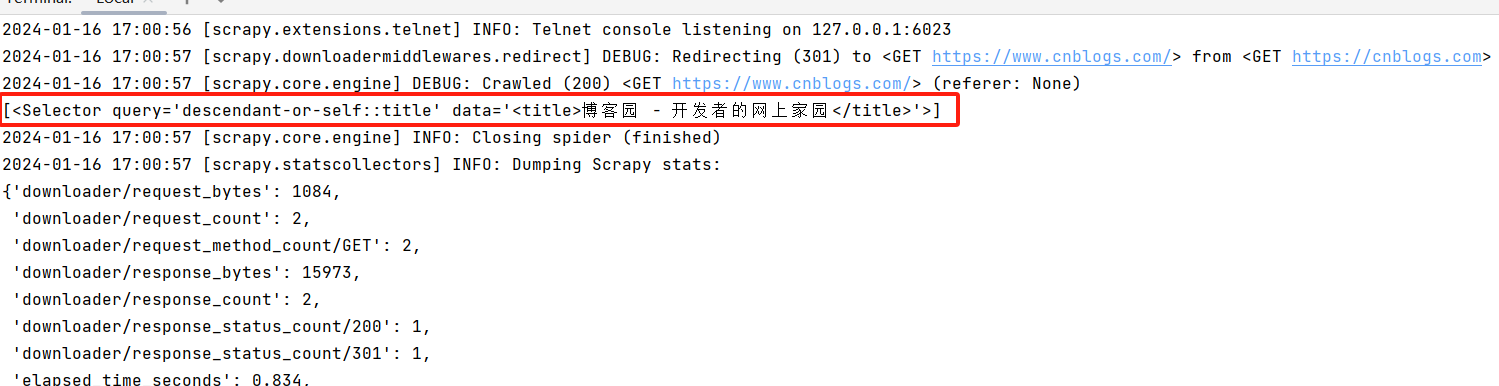
到这里一个简单的scrapy就完成了。下面我们尝试把抓取的标题写入csv文件
cnblogs.py 爬虫类的 parse 方法改为以下代码
def parse(self, response):
item = {}
item['title'] = response.css('title')
item['description'] = response.css('description')
return item
然后 用命令行运行
scrapy crawl cnblogs -o cnblogshome.csv
就会把网页标题和描述保存到csv文件


到这里,已经可以写爬取网页并保存到文件了,下面继续进化,保存到mysql数据库
安装mysql和异步处理twisted(提高并发能力)
pip install pymysql pip install twisted
打开pipelines.py 编辑 CnblogprojctPipeline 类
class CnblogprojctPipeline:
def __init__(self, dbpool):
# logging.debug("=======5555555==========")
self.dbpool = dbpool
@classmethod
def from_settings(cls, settings):
# 获取settings文件中的配置
dbparms = dict(
host='127.0.0.1',
db='test',
user='root',
passwd='123456',
charset='utf8',
cp_reconnect=True,
cursorclass=pymysql.cursors.DictCursor,
use_unicode=True,
)
# 使用Twisted中的adbapi获取数据库连接池对象
dbpool = adbapi.ConnectionPool("pymysql", **dbparms)
return cls(dbpool)
def process_item(self, item, spider):
logging.debug("=======23223==========")
# 使用teisted使mysql插入变成异步执行
# 使用数据库连接池对象进行数据库操作,自动传递cursor对象到第一个参数
query = self.dbpool.runInteraction(self.do_insert, item)
# 设置出错时的回调方法,自动传递出错消息对象failure到第一个参数
logging.debug(query)
query.addErrback(self.handle_error, item, spider) # 处理异常
def handle_error(self, failure, item, spider):
# 处理异步插入的异常
logging.error(str(failure))
def do_insert(self, cursor, item):
now = datetime.datetime.now()
now_format = (now + datetime.timedelta(hours=13)).strftime("%Y-%m-%d %H:%M:%S")
insert_sql = """
insert into web(title,addtime)
values (%s,%s)
"""
cursor.execute(insert_sql, (
str(item["title"]),now_format
))
打开setting.py 把里面将ITEM_PIPELINES给解注释了,这样爬虫 parse(self, response) 返回的item就会进入pipelines.py 的 CnblogprojctPipeline 里面
然后命令行运行
scrapy crawl cnblogs
数据就写到数据库里了
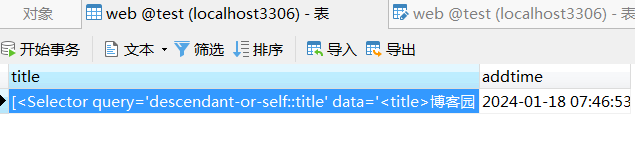
二 使用scrapy-redis 改为分布式爬虫,这样可以部署多台服务器爬取,并且因为使用同一来源:redis,所以不会重复爬
1 命令行安装模块
pip install scrapy_redis
2 在cnblogs.py 引入
from scrapy_redis.spiders import RedisSpider
并把 CnblogsSpider 继承改为RedisSpider, 并增加 redis_key = "cnblogs:start_urls" (redis爬虫会从这个redis 队列获取需要爬取url)并把 allowed_domains ,start_urls 变量注释掉
class CnblogsSpider(RedisSpider): name = "cnblogs" redis_key = "cnblogs:start_urls" # allowed_domains = ["www.cnblogs.com"] # start_urls = ["https://www.cnblogs.com"]
然后在给redis写入需要爬取的url
I:\pythonproject\cnblogprojct> redis-cli 127.0.0.1:6379> lpush cnblogs:start_urls https://www.cnblogs.com/
运行爬虫
scrapy crawl cnblogs
有些网站禁止了爬虫,可以试一下在setting.py里 的USER-AGENT 开启并写入真实的UA
USER_AGENT = "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36"
至此,使用 scrapy爬虫框架完成分布式爬虫完成,后面写下如何部署。

