CNN结构和语音识别应用
一、基本结构
参考deep learning. Ian Goodfellow的chapter9
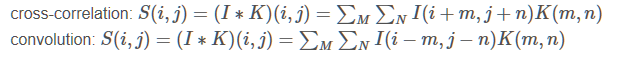
两种操作的区别在于是否做翻转,使用的时候将这两种操作都叫做了convolution
三个优势[1]:
- sparse interactions
- parameter sharing
- equivariant representations
三个阶段:
convolution:
nonlinearity:
pooling: 对于input的小的扰动保持invariant
二、kaldi代码实现
参考kaldi中net2实现,nnet2/nnet-component.h
- CNN的输入:36*33
假设特征维度为36*1
两阶差分:36*3
左右5帧:36*33 (两维的图像作为CNN的输入)
- 使用的filter:7*33*128
第一维:frequency axis size of the patch
第二维:time axis size of the patch
第三维:number of output feature_map
步长设置:patch_step_=1
form patches which span over several frequency bands and whole time axis
- 输出的feature_map:30*1*128
第一维:(36-7)/1+1=30
第二维:33 - 33 + 1 = 1
第三维:number of output feature_map
- max-pooling输出:10*1*128
pool_size=3, no overlaps
三、网络变形
(一)network in network
Lin, M., Chen, Q., and Yan, S. Network in network. In Proc. ICLR, 2014.
两点创新:
- global average pooling: 不需要全连接层,减少参数量;全连接层容易过拟合。
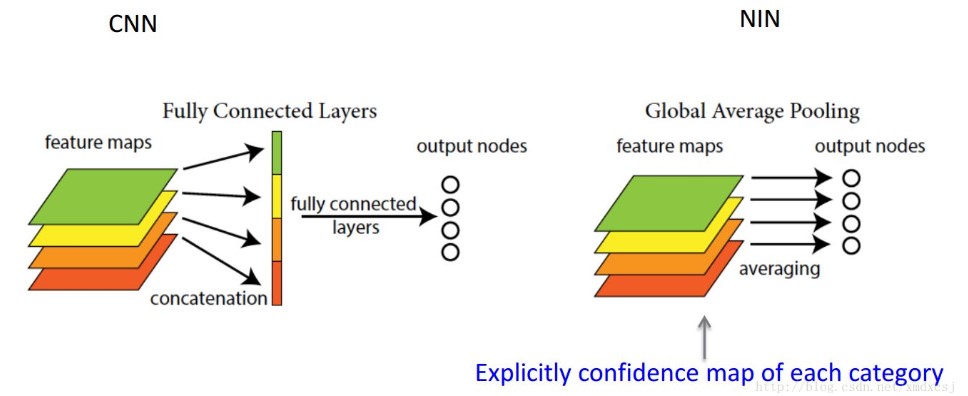
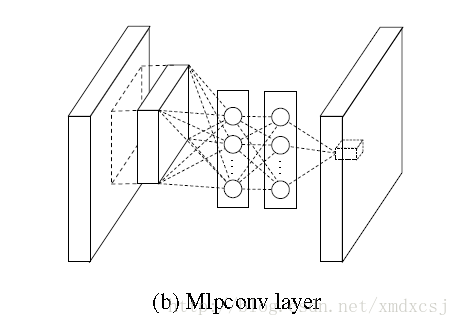
- mlpconv
(二)VGGNet
K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. In ICLR, 2015. Oxford The runner-up in ILSVRC 2014
网络层数增加到16-19层,同时使用更小的filter(3*3)
(三)ResNet
K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. arXiv:1512.03385, 2015. winner of ILSVRC 2015
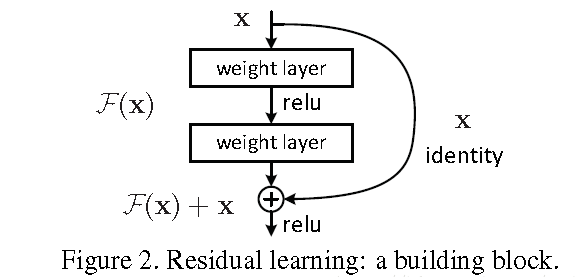
解决问题:网络层数增大,可以提升网络能力,但是当层数增加到一定值以后,性能就会发生饱和,继续过大,会出现degradation问题,比如56-layer的误差要比20-layer的高。原因在于have exponentially low convergence rates, which impact the reducing of the training error。
使用方法:引入shortcut,加快收敛,解决degradation问题,同时没有引入新的参数。
最后结果:从之前的30层增加到152层,性能一直提升,但是增加到1000层以后,training error比较小,但是测试误差变化,原因在于overfitting。
四、语音应用
(一)deep-cnn
D. Yu, W. Xiong, J. Droppo, A. Stolcke, G. Ye, J. Li, and G. Zweig, “Deep convolutional neural networks with layer-wise context expansion and attention”, in Proc.Interspeech, 2016.
两点创新:
- context expansion是指将n-1层的context作为第n层的输入
- attention机制,对于卷积层的频谱输入,不同的时间和频率对应点的重要性可能不同(当前时刻对应的帧的重要性要比前后几帧高一些),引入importance weight matrix(权重的初始化值为1),对每一层做卷积操作之前首先和这个矩阵进行element-wise相乘,相当于根据重要性进行加权。

参数:
- jump blocks: 4
- each block: (20; 31; 128), (10; 16; 256), (5; 8; 512), (3; 4; 1024)
最后的结果相比DNN和LSTM要好。
T. Sercu and V. Goel, “Advances in Very Deep Convolutional Neural Networks for LVCSR,” in INTERSPEECH, 2016.
对比了时间维度上的time pooling和time padding的效果,pool比no pool效果好
但是使用pooling或者padding在进行整句区分性训练的时候会带来问题,pooling会导致输出帧数变少,padding会导致edge处的输出结果改变
提出了使用更大的context window来解决上面的问题,no pooling,no padding,带来一些额外的计算量
Batch Normalization
The idea of BN is to standardize the internal representations inside the network (i.e. the layer outputs), which helps the network to converge faster and generalize better, inspired by the way whitening the network input improves performance. BN is implemented by standardizing the output of a layer before applying the nonlinearity, using the local mean and variance computed over the minibatch, then correcting with a learned variance and bias term
BN(x)=γx−E(x)(Var(x)+ϵ) 1/2 +β BN(x)=γx−E(x)(Var(x)+ϵ)1/2+βBN(x)=\gamma\frac{x-E(x)}{(Var(x)+\epsilon)^{1/2}}+\beta
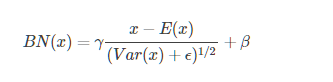
(二)ctc-cnn
Zhang, Y., Pezeshki, M., Brakel, P., Zhang, S., Laurent, C., Bengio, Y., Courville, A. (2016) Towards End-to-End Speech Recognition with Deep Convolutional Neural Networks. Proc. Interspeech 2016, 410-414.
性能和LSTM差不多,在同样参数量的情况下加速2.5X
将之前的LSTM网络结构替换为CNN,然后跟着全连接层,顶层使用CTC准则进行训练
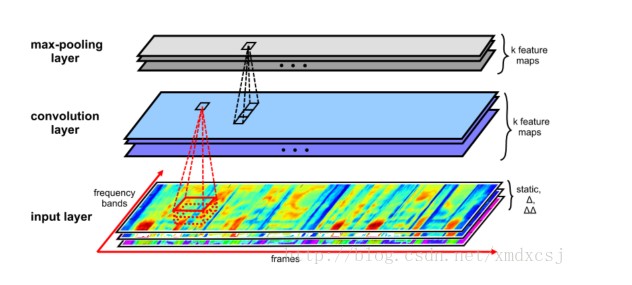
W. Song and J. Cai, “End-to-End Deep Neural Network for Automatic Speech Recognition,” Technical Report. 2015 stanford
CNNs are exceptionally good at capturing high level features in spatial domain and have demonstrated unparalleled success in computer vision related tasks. One natural advantage of using CNN is that it’s invariant against translations of the variations in frequencies, which are common observed across speaker with different pitch due to their age or gender.
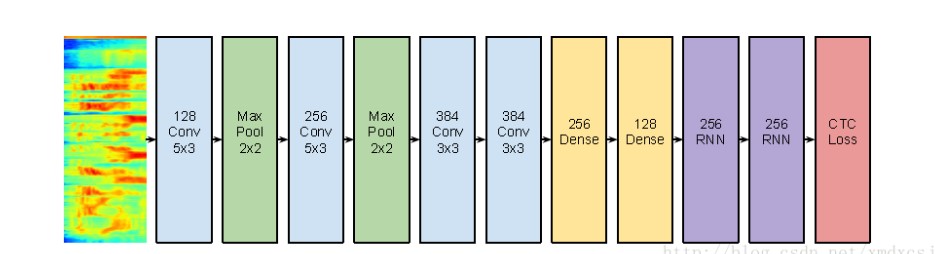
对数据帧使用时间窗获得一个单通道的图像,使用5X3的filter,考虑到频率维度的长度大于时间维度的长度。
首先使用CNN+softmax训练一个帧的分类器,然后固定CNN的参数,使用DNN+RNN+CTC替换softmax进行CTC训练,使用CNN预训练比直接训练CTC效果要好一些。
参考:https://blog.csdn.net/xmdxcsj/article/details/54695995
欢迎转载,转载请保留页面地址。帮助到你的请点个推荐。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号