知识蒸馏(Distillation)
蒸馏神经网络取名为蒸馏(Distill),其实是一个非常形象的过程。
我们把数据结构信息和数据本身当作一个混合物,分布信息通过概率分布被分离出来。首先,T值很大,相当于用很高的温度将关键的分布信息从原有的数据中分离,之后在同样的温度下用新模型融合蒸馏出来的数据分布,最后恢复温度,让两者充分融合。这也可以看成Prof. Hinton将这一个迁移学习过程命名为蒸馏的原因。
蒸馏神经网络想做的事情,本质上更接近于迁移学习(Transfer Learning),当然也可从模型压缩(Model Compression)的角度取理解蒸馏神经网络。
Hinton的这篇论文严谨的数学思想推导并不复杂,但是主要是通过巧妙的实验设计来验证了蒸馏神经网络的可行性,所以本专题主要从蒸馏的思想以及实验的设计来介绍蒸馏神经网络。
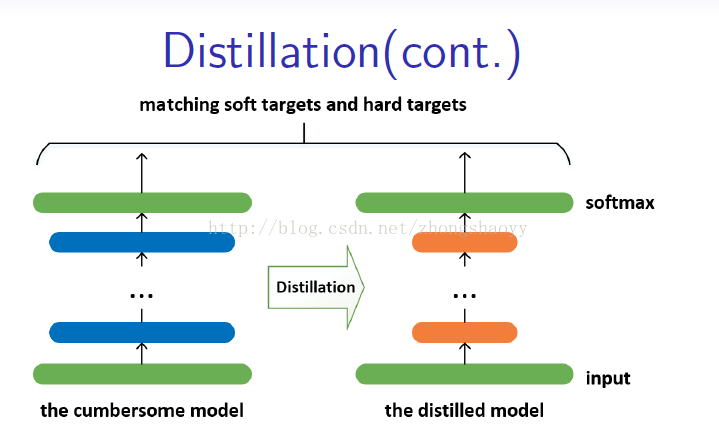
Distillation:
修改后的softmax公式为:
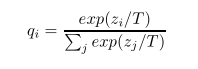
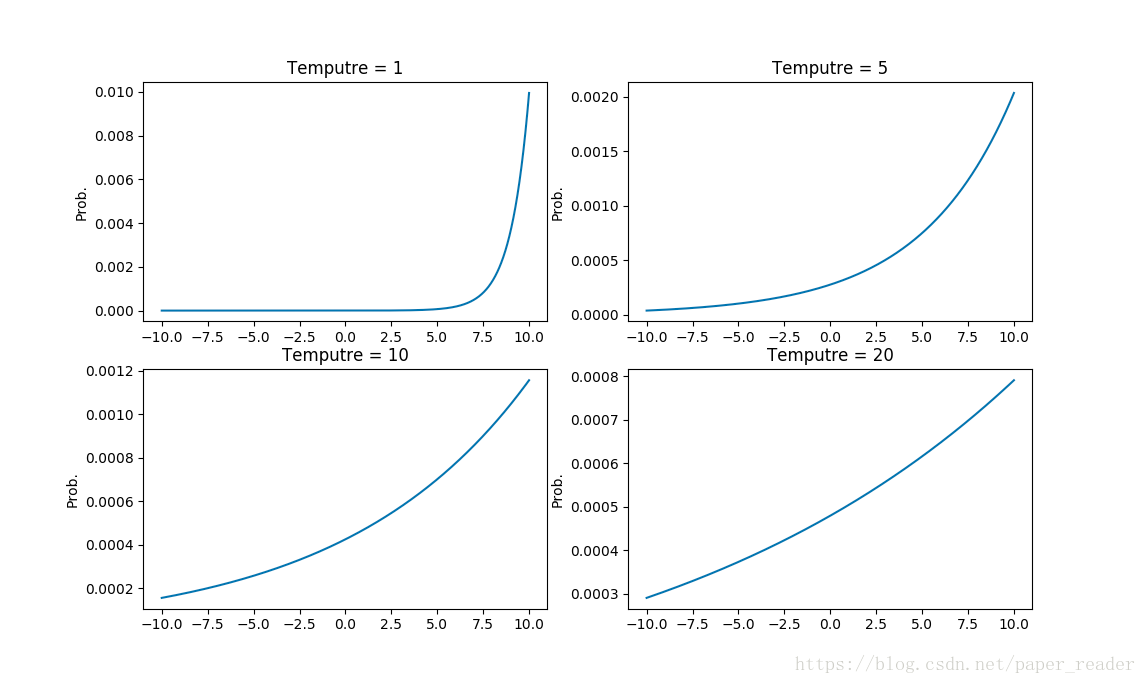
T就是一个调节参数,通常为1;T的数值越大则所有类的分布越‘软’(平缓)。
公式中,T参数是一个温度超参数,按照softmax的分布来看,随着T参数的增大,这个软目标的分布更加均匀。
一个简单的知识蒸馏的形式是:用复杂模型得到的“软目标”为目标(在softmax中T较大),用“转化”训练集训练小模型。训练小模型时T不变仍然较大,训练完之后T改为1。
当正确的标签是所有的或部分的传输集时,这个方法可以通过训练被蒸馏的模型产生正确的标签。一种方法是使用正确的标签来修改软目标,但是我们发现更好的方法是简单地使用两个不同目标函数的加权平均值。第一个目标函数是带有软目标的交叉熵,这种交叉熵是在蒸馏模型的softmax中使用相同的T计算的,用于从繁琐的模型中生成软目标。第二个目标函数是带有正确标签的交叉熵。这是在蒸馏模型的softmax中使用完全相同的逻辑,但在T=1下计算。我们发现,在第二个目标函数中,使用一个较低权重的条件,得到了最好的结果。由于软目标尺度所产生的梯度的大小为1/T^2,所以在使用硬的和软的目标时将它们乘以T^2是很重要的。这确保了在使用T时,硬和软目标的相对贡献基本保持不变。
1. T参数是什么?有什么作用?
T参数为了对应蒸馏的概念,在论文中叫的是Temperature,也就是蒸馏的温度。T越高对应的分布概率越平缓,为什么要使得分布概率变平缓?举一个例子,假设你是每次都是进行负重登山,虽然过程很辛苦,但是当有一天你取下负重,正常的登山的时候,你就会变得非常轻松,可以比别人登得高登得远。
同样的,在这篇文章里面的T就是这个负重包,我们知道对于一个复杂网络来说往往能够得到很好的分类效果,错误的概率比正确的概率会小很多很多,但是对于一个小网络来说它是无法学成这个效果的。我们为了去帮助小网络进行学习,就在小网络的softmax加一个T参数,加上这个T参数以后错误分类再经过softmax以后输出会变大(softmax中指数函数的单增特性,这里不做具体解释),同样的正确分类会变小。这就人为的加大了训练的难度,一旦将T重新设置为1,分类结果会非常的接近于大网络的分类效果。
2. soft target(“软目标”)是什么?
soft就是对应的带有T的目标,是要尽量的接近于大网络加入T后的分布概率。
3. hard target(“硬目标”)是什么?
hard就是正常网络训练的目标,是要尽量的完成正确的分类。
4. 两个目标函数究竟是什么?
两个目标函数也就是对应的上面的soft target和hard target。这个体现在Student Network会有两个loss,分别对应上面两个问题求得的交叉熵,作为小网络训练的loss function。
5. 具体蒸馏是如何训练的?
Teacher: 对softmax(T=20)的输出与原始label求loss。
Student: (1)对softmax(T=20)的输出与Teacher的softmax(T=20)的输出求loss1。
(2)对softmax(T=1)的输出与原始label求loss2。
(3)loss = loss1+loss2
欢迎转载,转载请保留页面地址。帮助到你的请点个推荐。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号