基于Transformer的ViT、DETR、Deformable DETR原理详解
自从Transformer出来以后,Transformer便开始在NLP领域一统江湖。而Transformer在CV领域反响平平,一度认为不适合CV领域,直到最近计算机视觉领域出来几篇Transformer文章,性能直逼CNN的SOTA,给予了计算机视觉领域新的想象空间。
本文不拘泥于Transformer原理和细节实现(知乎有很多优质的Transformer解析文章,感兴趣的可以看看),着重于Transformer对计算机视觉领域的革新。
首先简略回顾一下Transformer,然后介绍最近几篇计算机视觉领域的Transformer文章,其中ViT用于图像分类,DETR和Deformable DETR用于目标检测。从这几篇可以看出,Transformer在计算机视觉领域的范式已经初具雏形,可以大致概括为:Embedding -> Transformer -> Head
一些有趣的点写在最后~~
Transformer
Transformer详解
下面以机器翻译为例子,简略介绍Transformer结构。
1. Encoder-Decoder
Transformer结构可以表示为Encoder和Decoder两个部分
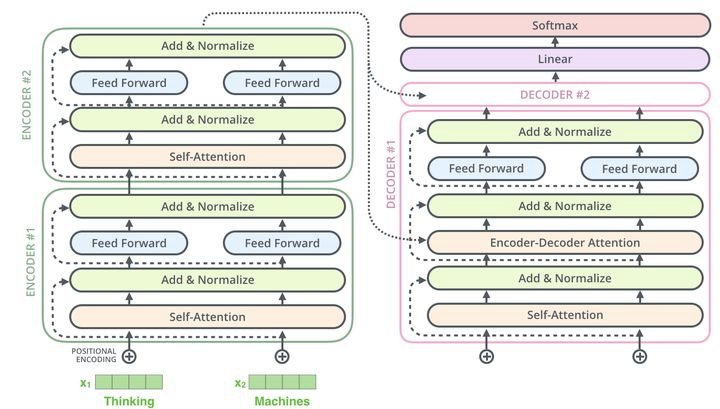
Encoder和Decoder主要由Self-Attention和Feed-Forward Network两个组件构成,Self-Attention由Scaled Dot-Product Attention和Multi-Head Attention两个组件构成。
Scaled Dot-Product Attention公式:
![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233620859-1549016853.png)
Multi-Head Attention公式:
![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233621133-1677296150.png)
Feed-Forward Network公式:
![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233621374-839997282.png)
2. Positional Encoding

如图所示,由于机器翻译任务跟输入单词的顺序有关,Transformer在编码输入单词的嵌入向量时引入了positional encoding,这样Transformer就能够区分出输入单词的位置了。
引入positional encoding的公式为:
![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233621903-1796783631.png)
![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233622124-1115104338.png) 是位置,
是位置, ![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233622323-54657127.png) 是维数,
是维数, ![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233622532-1603385475.png) 是输入单词的嵌入向量维度。
是输入单词的嵌入向量维度。
3. Self-Attention
3.1 Scaled Dot-Product Attention
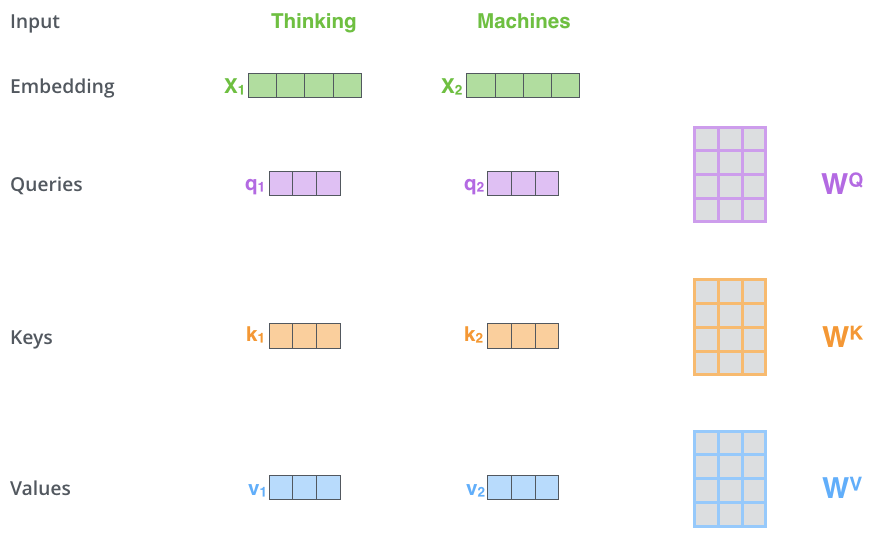
在Scaled Dot-Product Attention中,每个输入单词的嵌入向量分别通过3个矩阵![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233623000-2014884106.png) ,
,![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233623309-1912795152.png) 和 来分别得到Query向量(
和 来分别得到Query向量(![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233623502-1912346340.png) ),Key向量(
),Key向量(![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233623708-76572784.png) )和Value向量(
)和Value向量(![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233623916-338508000.png) )。
)。
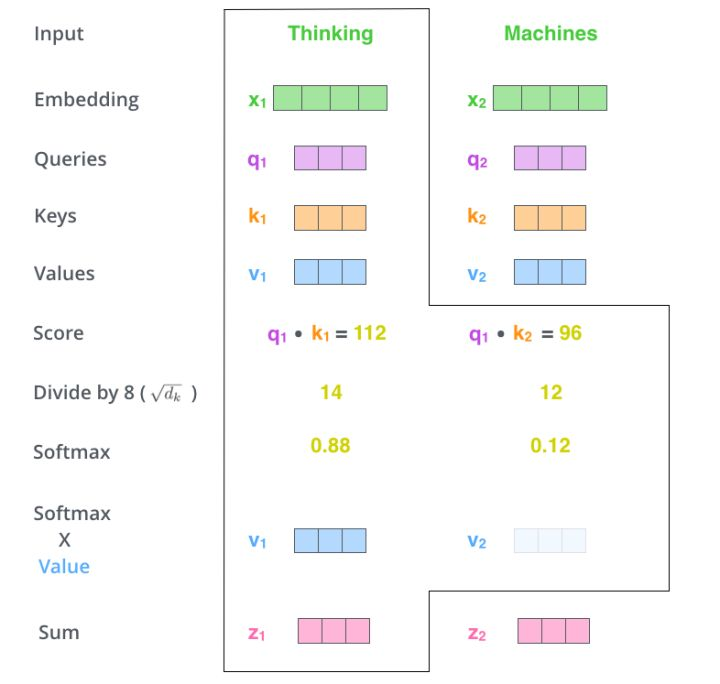
如图所示,Scaled Dot-Product Attention的计算过程可以分成7个步骤:
- 每个输入单词转化成嵌入向量。
- 根据嵌入向量得到
![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233624689-1411281685.png) ,
,![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233624877-1285388866.png) ,
,![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233625106-210286618.png) 三个向量。
三个向量。 - 通过向量计算 : 。
- 对
![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233625322-861855284.png) ,
,![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233625521-1229729129.png) 进行归一化,即除以
进行归一化,即除以![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233625734-1646869932.png) 。
。 - 通过
![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233625937-41711149.png) 激活函数计算
激活函数计算![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233626276-1007339858.png) 。
。 - 点乘Value值
![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233626493-1422534571.png) ,得到每个输入向量的评分
,得到每个输入向量的评分![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233626681-567843903.png) 。
。 - 所有输入向量的评分
![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233626875-169226651.png) 之和为
之和为![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233627073-1651378622.png) :
:![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233627311-611277080.png) 。
。
上述步骤的矩阵形式可以表示成:
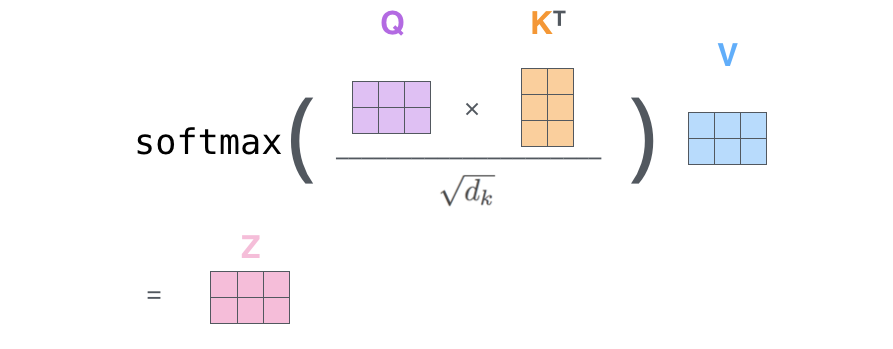
与Scaled Dot-Product Attention公式一致。
3.2 Multi-Head Attention
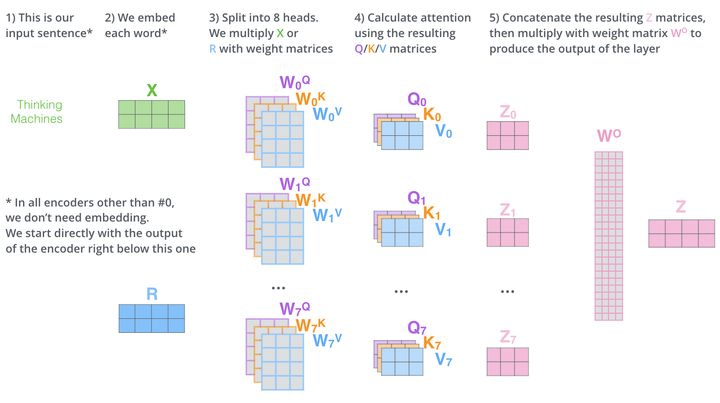
如图所示,Multi-Head Attention相当于h个不同Scaled Dot-Product Attention的集成,以h=8为例子,Multi-Head Attention步骤如下:
- 将数据
![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233628261-203126449.png) 分别输入到8个不同的Scaled Dot-Product Attention中,得到8个加权后的特征矩阵
分别输入到8个不同的Scaled Dot-Product Attention中,得到8个加权后的特征矩阵 ![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233628453-1195710304.png) 。
。 - 将8个
![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233628664-812741729.png) 按列拼成一个大的特征矩阵。
按列拼成一个大的特征矩阵。 - 特征矩阵经过一层全连接得到输出
![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233628862-1041300745.png) 。
。
Scaled Dot-Product Attention和Multi-Head Attention都加入了short-cut机制。
ViT
ViT将Transformer巧妙的应用于图像分类任务,更少计算量下性能跟SOTA相当。
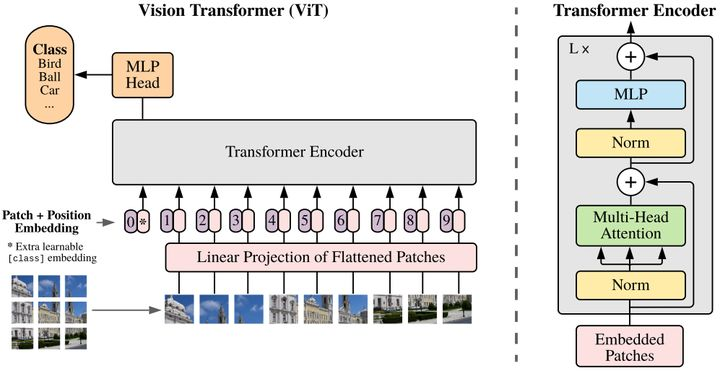
Vision Transformer(ViT)将输入图片拆分成16x16个patches,每个patch做一次线性变换降维同时嵌入位置信息,然后送入Transformer,避免了像素级attention的运算。类似BERT[class]标记位的设置,ViT在Transformer输入序列前增加了一个额外可学习的[class]标记位,并且该位置的Transformer Encoder输出作为图像特征。
![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233629558-851103460.png)
其中![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233629903-1615892945.png) 为原图像分辨率,
为原图像分辨率,![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233630181-2106823203.png) 为每个图像patch的分辨率。
为每个图像patch的分辨率。![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233630386-1650142893.png) 为Transformer输入序列的长度。
为Transformer输入序列的长度。
ViT舍弃了CNN的归纳偏好问题,更加有利于在超大规模数据上学习知识,即大规模训练优归纳偏好,在众多图像分类任务上直逼SOTA。
DETR
DETR使用set loss function作为监督信号来进行端到端训练,然后同时预测所有目标,其中set loss function使用bipartite matching算法将pred目标和gt目标匹配起来。直接将目标检测任务看成set prediction问题,使训练过程变的简洁,并且避免了anchor、NMS等复杂处理。
DETR主要有两个部分:architecture和set prediction loss。
1. Architecture
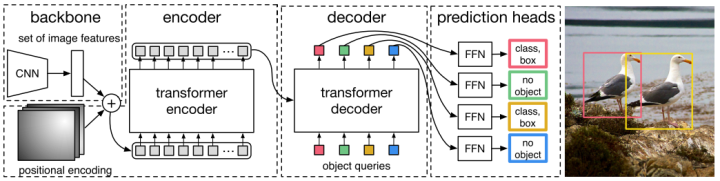
DETR先用CNN将输入图像embedding成一个二维表征,然后将二维表征转换成一维表征并结合positional encoding一起送入encoder,decoder将少量固定数量的已学习的object queries(可以理解为positional embeddings)和encoder的输出作为输入。最后将decoder得到的每个output embdding传递到一个共享的前馈网络(FFN),该网络可以预测一个检测结果(包括类和边框)或着“没有目标”的类。
1.1 Transformer
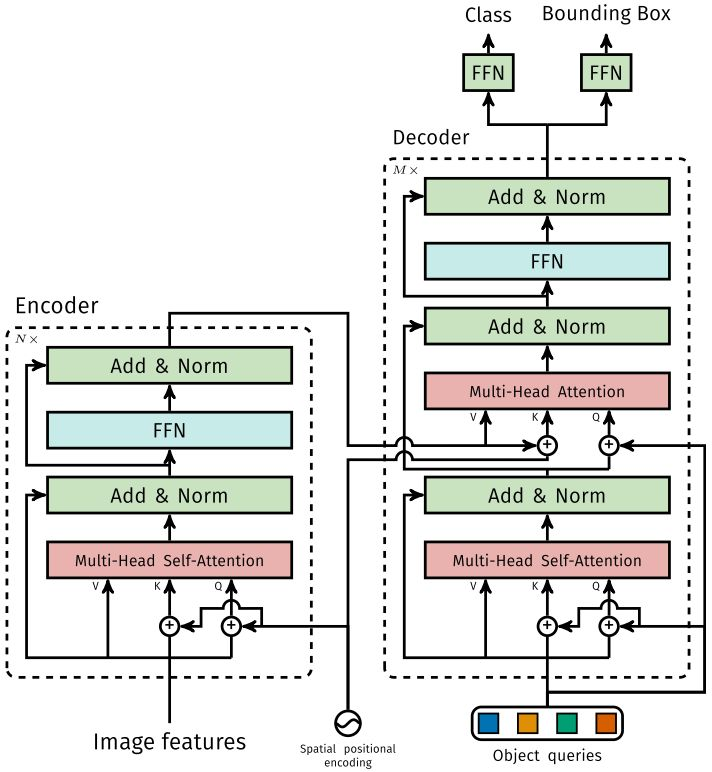
1.1.1 Encoder
将Backbone输出的feature map转换成一维表征,得到 特征图,然后结合positional encoding作为Encoder的输入。每个Encoder都由Multi-Head Self-Attention和FFN组成。
和Transformer Encoder不同的是,因为Encoder具有位置不变性,DETR将positional encoding添加到每一个Multi-Head Self-Attention中,来保证目标检测的位置敏感性。
1.1.2 Decoder
因为Decoder也具有位置不变性,Decoder的![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233631835-48179455.png) 个object query(可以理解为学习不同object的positional embedding)必须是不同,以便产生不同的结果,并且同时把它们添加到每一个Multi-Head Attention中。
个object query(可以理解为学习不同object的positional embedding)必须是不同,以便产生不同的结果,并且同时把它们添加到每一个Multi-Head Attention中。![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233632022-241546072.png) 个object queries通过Decoder转换成一个output embedding,然后output embedding通过FFN独立解码出
个object queries通过Decoder转换成一个output embedding,然后output embedding通过FFN独立解码出![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233632222-1037618260.png) 个预测结果,包含box和class。对输入embedding同时使用Self-Attention和Encoder-Decoder Attention,模型可以利用目标的相互关系来进行全局推理。
个预测结果,包含box和class。对输入embedding同时使用Self-Attention和Encoder-Decoder Attention,模型可以利用目标的相互关系来进行全局推理。
和Transformer Decoder不同的是,DETR的每个Decoder并行输出![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233632419-377744343.png) 个对象,Transformer Decoder使用的是自回归模型,串行输出
个对象,Transformer Decoder使用的是自回归模型,串行输出![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233632624-280829328.png) 个对象,每次只能预测一个输出序列的一个元素。
个对象,每次只能预测一个输出序列的一个元素。
1.1.3 FFN
FFN由3层perceptron和一层linear projection组成。FFN预测出box的归一化中心坐标、长、宽和class。
DETR预测的是固定数量的![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233632841-276369450.png) 个box的集合,并且
个box的集合,并且![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233633070-1299755920.png) 通常比实际目标数要大的多,所以使用一个额外的空类来表示预测得到的box不存在目标。
通常比实际目标数要大的多,所以使用一个额外的空类来表示预测得到的box不存在目标。
2. Set prediction loss
DETR模型训练的主要困难是如何根据gt衡量预测结果(类别、位置、数量)。DETR提出的loss函数可以产生pred和gt的最优双边匹配(确定pred和gt的一对一关系),然后优化loss。
将 ![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233633279-674294411.png) 表示为gt的集合, 表示为
表示为gt的集合, 表示为![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233633533-1265703232.png) 个预测结果的集合。假设
个预测结果的集合。假设![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233633779-861595872.png) 大于图片目标数,
大于图片目标数, ![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233634155-1758507086.png) 可以认为是用空类(无目标)填充的大小为
可以认为是用空类(无目标)填充的大小为![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233634372-2109941439.png) 的集合。搜索两个集合
的集合。搜索两个集合![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233634569-1661538451.png) 个元素
个元素![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233634761-824527495.png) 的不同排列顺序,使得loss尽可能的小的排列顺序即为二分图最大匹配(Bipartite Matching),公式如下:
的不同排列顺序,使得loss尽可能的小的排列顺序即为二分图最大匹配(Bipartite Matching),公式如下:
![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233634996-1443717876.png)
其中![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233635240-207683593.png) 表示pred和gt关于
表示pred和gt关于![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233635498-11353033.png) 元素
元素![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233635694-30776858.png) 的匹配loss。其中二分图匹配通过匈牙利算法(Hungarian algorithm)得到。
的匹配loss。其中二分图匹配通过匈牙利算法(Hungarian algorithm)得到。
匹配loss同时考虑了pred class和pred box的准确性。每个gt的元素![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233635880-1386803414.png) 可以看成
可以看成![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233636085-2135394873.png) ,
,![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233636447-1614639791.png) 表示class label(可能是空类)
表示class label(可能是空类) ![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233636678-1133713487.png) 表示gt box,将元素
表示gt box,将元素![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233636904-1091987055.png) 二分图匹配指定的pred class表示为
二分图匹配指定的pred class表示为 ![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233637114-1075010136.png) ,pred box表示为
,pred box表示为![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233637474-1774218953.png) 。
。
第一步先找到一对一匹配的pred和gt,第二步再计算hungarian loss。
hungarian loss公式如下:
![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233637692-1200559202.png)
其中 结合了L1 loss和generalized IoU loss,公式如下:
![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233637920-1869535005.png)
ViT和DETR两篇文章的实验和可视化分析很有启发性,感兴趣的可以仔细看看~~
Deformable DETR
从DETR看,还不足以赶上CNN,因为训练时间太久了,Deformable DETR的出现,让我对Transformer有了新的期待。
Deformable DETR将DETR中的attention替换成Deformable Attention,使DETR范式的检测器更加高效,收敛速度加快10倍。
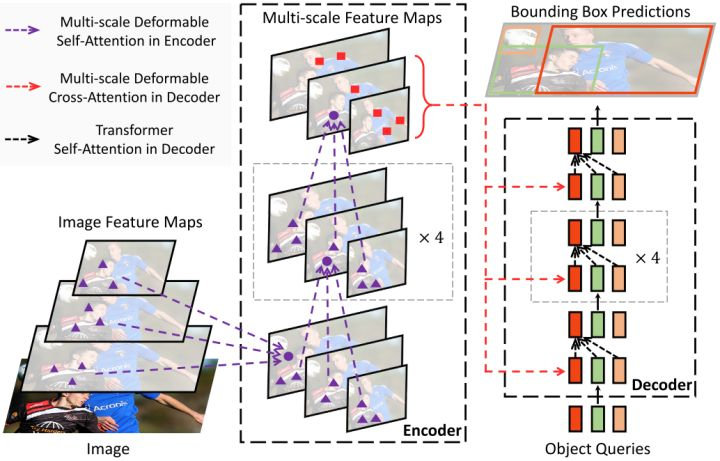
Deformable DETR提出的Deformable Attention可以可以缓解DETR的收敛速度慢和复杂度高的问题。同时结合了deformable convolution的稀疏空间采样能力和transformer的关系建模能力。Deformable Attention可以考虑小的采样位置集作为一个pre-filter突出所有feature map的关键特征,并且可以自然地扩展到融合多尺度特征,并且Multi-scale Deformable Attention本身就可以在多尺度特征图之间进行交换信息,不需要FPN操作。
1. Deformable Attention Module
给定一个query元素(如输出句子中的目标词)和一组key元素(如输入句子的源词),Multi-Head Attention能够根据query-key pairs的相关性自适应的聚合key的信息。为了让模型关注来自不同表示子空间和不同位置的信息,对multi-head的信息进行加权聚合。其中![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233640278-334399971.png) 表示query元素(特征表示为
表示query元素(特征表示为![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233640495-1914382022.png) ),
),![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233640715-1085331426.png) 表示key元素(特征表示为
表示key元素(特征表示为![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233640933-1771938469.png) ),
),![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233641151-727058140.png) 是特征维度,
是特征维度,![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233641343-1324398491.png) 和
和 ![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233641544-373739565.png) 分别为
分别为![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233641741-71997853.png) 和
和![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233641953-301394582.png) 的集合。
的集合。
那么Transformer 的 Multi-Head Attention公式表示为:
![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233642187-308322039.png)
其中![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233642404-1037258079.png) 指定attention head,
指定attention head,![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233642636-886507628.png) 和
和![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233643008-1734609220.png) 是可学习参数,注意力权重
是可学习参数,注意力权重![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233643248-1663891341.png) 并且归一化
并且归一化![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233643478-1322702767.png) ,其中
,其中![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233643739-565568376.png) 是可学习参数。为了能够分辨不同空间位置,
是可学习参数。为了能够分辨不同空间位置,![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233643944-368557254.png) 和
和![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233644147-398371095.png) 通常会引入positional embedding。
通常会引入positional embedding。
对于DETR中的Transformer Encoder,query和key元素都是feature map中的像素。
DETR 的 Multi-Head Attention 公式表示为:
![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233644367-2007198886.png)
其中![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233644607-1138234452.png) 。
。
DETR主要有两个问题:需要更多的训练时间来收敛,对小目标的检测性能相对较差。本质上是因为Transfomer的Multi-Head Attention会对输入图片的所有空间位置进行计算。而Deformable DETR的Deformable Attention只关注参考点周围的一小部分关键采样点,为每个query分配少量固定数量的key,可以缓解收敛性和输入分辨率受限制的问题。
给定一个输入feature map ,![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233644840-502959905.png) 表示为query元素(特征表示为),二维参考点表示为
表示为query元素(特征表示为),二维参考点表示为![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233645034-2044770335.png) ,Deformable DETR 的 Deformable Attention公式表示为:
,Deformable DETR 的 Deformable Attention公式表示为:
![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233645236-358636615.png)
其中![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233645469-677104733.png) 指定attention head,
指定attention head,![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233645661-417413721.png) 指定采样的key,
指定采样的key,![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233645876-723260868.png) 表示采样key的总数(
表示采样key的总数(![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233646079-335132094.png) )。
)。![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233646325-1325559811.png) ,
, ![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233646525-353447817.png) 分别表示第
分别表示第![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233646735-720677290.png) 个采样点在第
个采样点在第![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233646933-324795729.png) 个attention head的采样偏移量和注意力权重。注意力权重
个attention head的采样偏移量和注意力权重。注意力权重![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233647128-93250509.png) 在[0,1]的范围内,归一化
在[0,1]的范围内,归一化![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233647323-588692317.png) 。
。![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233647526-1328328794.png) 表示为无约束范围的二维实数。因为
表示为无约束范围的二维实数。因为![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233647733-1908446766.png) 为分数,需要采用双线性插值方法计算
为分数,需要采用双线性插值方法计算![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233648018-46043600.png) 。
。
2. Multi-scale Deformable Attention Module
Deformable Attention可以很自然地扩展到多尺度的feature maps。![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233648252-2089528388.png) 表示为输入的多尺度feature maps,
表示为输入的多尺度feature maps,![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233648461-768770092.png) 。
。 ![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233648779-2016988054.png) 表示为每个query元素
表示为每个query元素![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233649046-1632936058.png) 的参考点
的参考点 ![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233649235-1806450833.png) 的归一化坐标。Deformable DETR 的Multi-scale Deformable Attention公式表示为:
的归一化坐标。Deformable DETR 的Multi-scale Deformable Attention公式表示为:
![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233649447-1652815167.png)
其中![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233649710-2130091767.png) 指定attention head,
指定attention head,![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233649902-329923727.png) 指定输入特征层,
指定输入特征层,![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233650111-458044598.png) 指定采样的key,
指定采样的key,![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233650328-1295657417.png) 表示采样key的总数(
表示采样key的总数( ![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233650552-1713728263.png) )。
)。![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233650782-1462319212.png) ,
, ![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233651021-1301433669.png) 分别表示第
分别表示第![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233651205-1333398193.png) 个采样点在第
个采样点在第![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233651426-692278967.png) 特征层的第
特征层的第![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233651626-148727886.png) 个attention head的采样偏移量和注意力权重。注意力权重
个attention head的采样偏移量和注意力权重。注意力权重![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233651824-1935527676.png) 在[0,1]的范围内,归一化
在[0,1]的范围内,归一化![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233652087-1077780904.png) 。
。
3. Deformable Transformer Encoder
将DETR中所有的attention替换成multi-scale deformable attention。encoder的输入和输出都是具有相同分辨率的多尺度feature maps。Encoder从ResNet的![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233652336-2001376231.png) 中抽取多尺度feature maps
中抽取多尺度feature maps![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233652619-2103511728.png) , (
, ( ![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233652840-619558455.png) 由
由![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233653051-1627037394.png) 进行3×3 stride 2卷积得到)。
进行3×3 stride 2卷积得到)。
在Encoder中使用multi-scale deformable attention,输出是和输入具有相同分辨率的多尺度feature maps。query和key都来自多尺度feature maps的像素。对于每个query像素,参考点是它本身。为了判断query像素源自哪个特征层,除了positional embedding外,还添加了一个scale-level embedding![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233653241-1246646913.png) ,不同于positional embedding的固定编码, scale-level embedding随机初始化并且通过训练得到。
,不同于positional embedding的固定编码, scale-level embedding随机初始化并且通过训练得到。
4. Deformable Transformer Decoder
Decoder中有cross-attention和self-attention两种注意力。这两种注意力的query元素都是object queries。在cross-attention中,object queries从feature maps中提取特征,而key元素是encoder输出的feature maps。在self-attention中,object queries之间相互作用,key元素也是object queries。因为Deformable Attention是用于key元素的feature maps特征提取的,所以decoder部分,deformable attention只替换cross-attention。
因为multi-scale deformable attention提取参考点周围的图像特征,让检测头预测box相对参考点的偏移量,进一步降低了优化难度。
复杂度分析
假设query和key的数量分别为![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233653427-1646227478.png) 、
、![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233653657-691562516.png) (
(![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233653872-1514822018.png) ),维度为
),维度为![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233654082-700796065.png) ,key采样点数为
,key采样点数为![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233654296-1201160065.png) ,图像的feature map大小为
,图像的feature map大小为![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233654496-87581897.png) ,卷积核尺寸为
,卷积核尺寸为![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233654737-372249286.png) 。
。
Convolution复杂度
- 为了保证输入和输出在第一个维度都相同,故需要对输入进行padding操作,因为这里kernel size为
![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233654945-1404094016.png) (实际kernel的形状为
(实际kernel的形状为![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233655167-831646412.png) )。
)。 - 大小为
![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233655378-1496498041.png) 的卷积核一次运算复杂度为
的卷积核一次运算复杂度为![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233655598-677203677.png) ,一共做了
,一共做了![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233655844-358694249.png) 次,故复杂度为
次,故复杂度为![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233656056-995464664.png) 。
。 - 为了保证第三个维度相等,故需要
![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233656355-1266998476.png) 个卷积核,所以卷积操作的时间复杂度为
个卷积核,所以卷积操作的时间复杂度为![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233656552-221567310.png) 。
。
Self-Attention复杂度
![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233656779-1210150015.png)
![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233657066-1258824138.png) 的计算复杂度为
的计算复杂度为![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233657319-1629087535.png) 。
。- 相似度计算
![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233657500-1380046563.png) :
:![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233657700-934835616.png) 与
与![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233657903-435989595.png) 运算,得到
运算,得到![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233658101-42054316.png) 矩阵,复杂度为
矩阵,复杂度为![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233658341-77995867.png) 。
。 ![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233658619-1415999544.png) 计算:对每行做
计算:对每行做 ![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233658887-734167308.png) ,复杂度为
,复杂度为![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233659120-1371460566.png) ,则n行的复杂度为
,则n行的复杂度为![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233659329-1354947084.png) 。
。- 加权和:
![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233659555-748240424.png) 与
与![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233659764-1262613410.png) 运算,得到
运算,得到![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233700096-1784312548.png) 矩阵,复杂度为
矩阵,复杂度为![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233700313-1326920096.png) 。
。 - 故最后self-attention的时间复杂度为
![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233700576-945973288.png) 。
。
Transformer
Self-Attention的复杂度为![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233700815-1324864828.png) 。
。
ViT
![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233701020-39265921.png)
Self-Attention的复杂度为![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233701224-1026225070.png) 。
。
DETR
![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233701513-1412153979.png)
Self-Attention的复杂度为![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233701788-1544033844.png) 。
。
Deformable DETR
Self-Attention的复杂度为![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233702036-858163291.png) 。
。
分析细节看原论文
几个问题
![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233702428-1072410868.png) 如何理解? 为什么不使用相同的
如何理解? 为什么不使用相同的![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233702691-598175257.png) 和
和![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233702913-2103929450.png) ?
?
1. 从点乘的物理意义上讲,两个向量的点乘表示两个向量的相似度。
2. ![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233703130-2006697642.png) 的物理意义是一样的,都表示同一个句子中不同token组成的矩阵。矩阵中的每一行,是表示一个token的word embedding向量。假设一个句子“Hello, how are you?”长度是6,embedding维度是300,那么
的物理意义是一样的,都表示同一个句子中不同token组成的矩阵。矩阵中的每一行,是表示一个token的word embedding向量。假设一个句子“Hello, how are you?”长度是6,embedding维度是300,那么![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233703469-906895358.png) 都是(6,300)的矩阵。
都是(6,300)的矩阵。
所以![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233703686-2041778937.png) 和
和![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233703862-190538436.png) 的点乘可以理解为计算一个句子中每个token相对于句子中其他token的相似度,这个相似度可以理解为attetnion score,关注度得分。虽然有了attention score矩阵,但是这个矩阵是经过各种计算后得到的,已经很难表示原来的句子了,而
的点乘可以理解为计算一个句子中每个token相对于句子中其他token的相似度,这个相似度可以理解为attetnion score,关注度得分。虽然有了attention score矩阵,但是这个矩阵是经过各种计算后得到的,已经很难表示原来的句子了,而![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233704040-1972924979.png) 还代表着原来的句子,所以可以将attention score矩阵与
还代表着原来的句子,所以可以将attention score矩阵与![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233704311-622001105.png) 相乘,得到的是一个加权后的结果。
相乘,得到的是一个加权后的结果。
经过上面的解释,我们知道![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233704498-1596548615.png) 和
和![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233704741-360505877.png) 的点乘是为了得到一个attention score 矩阵,用来对
的点乘是为了得到一个attention score 矩阵,用来对![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233704943-416401789.png) 进行提炼。
进行提炼。![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233705136-463642989.png) 和
和![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233705325-1047521274.png) 使用不同的
使用不同的![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233705552-1509127883.png) ,
, ![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233705760-1764729307.png) 来计算,可以理解为是在不同空间上的投影。正因为有了这种不同空间的投影,增加了表达能力,这样计算得到的attention score矩阵的泛化能力更高。这里解释下我理解的泛化能力,因为
来计算,可以理解为是在不同空间上的投影。正因为有了这种不同空间的投影,增加了表达能力,这样计算得到的attention score矩阵的泛化能力更高。这里解释下我理解的泛化能力,因为![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233705952-250112578.png) 和
和![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233706151-1447677884.png) 使用了不同的
使用了不同的![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233706358-818181966.png) ,
, ![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233706592-243584195.png) 来计算,得到的也是两个完全不同的矩阵,所以表达能力更强。但是如果不用
来计算,得到的也是两个完全不同的矩阵,所以表达能力更强。但是如果不用![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233706787-1582684019.png) ,直接拿
,直接拿![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233706990-1964045763.png) 和
和![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233707263-978709730.png) 点乘的话,attention score 矩阵是一个对称矩阵,所以泛化能力很差,这个矩阵对
点乘的话,attention score 矩阵是一个对称矩阵,所以泛化能力很差,这个矩阵对![[公式]](https://img2020.cnblogs.com/blog/1470684/202105/1470684-20210526233707457-1672503133.png) 进行提炼,效果会变差。
进行提炼,效果会变差。
如何Position Embedding更好?
目前还是一个开放问题,知乎上有一些优质的讨论,详细分析可以看链接文章
ViT为什么要增加一个[CLS]标志位? 为什么将[CLS]标志位对应的向量作为整个序列的语义表示?
和BERT相类似,ViT在序列前添加一个可学习的[CLS]标志位。以BERT为例,BERT在第一句前添加一个[CLS]标志位,最后一层该标志位对应的向量可以作为整句话的语义表示,从而用于下游的分类任务等。
将[CLS]标志位对应的向量作为整个文本的语义表示,是因为与文本中已有的其它词相比,这个无明显语义信息的符号会更“公平”地融合文本中各个词的语义信息,从而更好的表示整句话的语义。
归纳偏好是什么?
归纳偏置在机器学习中是一种很微妙的概念:在机器学习中,很多学习算法经常会对学习的问题做一些假设,这些假设就称为归纳偏好(Inductive Bias)。归纳偏置可以理解为,从现实生活中观察到的现象中归纳出一定的规则(heuristics),然后对模型做一定的约束,从而可以起到“模型选择”的作用,即从假设空间中选择出更符合现实规则的模型。可以把归纳偏好理解为贝叶斯学习中的“先验”。
在深度学习中,也使用了归纳偏好。在CNN中,假设特征具有局部性(Locality)的特点,即把相邻的一些特征融合到一起,会更容易得到“解”;在RNN中,假设每一时刻的计算依赖于历史计算结果;还有attention机制,也是从人的直觉、生活经验归纳得到的规则。
而Transformer可以避免CNN的局部性归纳偏好问题。举一个DETR中的例子。

训练集中没有超过13只长颈鹿的图像,DETR实验中创建了一个合成的图像来验证DETR的泛化能力,DERT可以完全找到合成的全部24只长颈鹿。这证实了DETR避免了CNN的归纳偏好问题。
二分图匹配? 匈牙利算法?
给定一个二分图G,在G的一个子图M中,M的边集{E}中的任意两条边都不依附于同一个顶点,则称M是一个匹配。求二分图最大匹配可以用匈牙利算法。
详细分析可以看链接文章
https://liam.page/2016/04/03/Hungarian-algorithm-in-the-maximum-matching-problem-of-bigraph/
ZihaoZhao:带你入门多目标跟踪(三)匈牙利算法&KM算法
BETR的positional embedding、object queries和slot三者之间有何关系?

DETR可视化decoder预测得到的20个slot。可以观察到每个slot学习到了特定区域的尺度大小。Object queries从这个角度看,其实有点像Faster-RCNN等目标检测器的anchor,结合encoder的positional embedding信息让每个slot往学习到的特定区域去寻找目标。
Transformer相比于CNN的优缺点?
优点:
Transformer关注全局信息,能建模更加长距离的依赖关系,而CNN关注局部信息,全局信息的捕捉能力弱。
Transformer避免了CNN中存在的归纳偏好问题。
缺点:
Transformer复杂度比CNN高,但是ViT和Deformable DETR给出了一些解决方法来降低Transformer的复杂度。
Deformable detr中值得注意的几个地方:
DeformableTransformer中在不使用two_stage的条件下提供的reference_points是由nn.Embedding经过线性变化得到的,值得注意的是这个·reference_points·直接参与了loss的计算,也就是说这个分支上对self.reference_points层进行了训练。DeformableTransformer中使用two_stage的条件下在每个位置上都生成了proposal,然后选择topk个proposal作为query的reference_point,但是可以发现这里的topk 进行了detach,并不会传递从decoder传来的梯度误差。DeformableTransformer中使用two_stage的条件会在encoder的输出层的每个位置提供一个anchor,对于多尺度而言,提供了不同尺度的anchor。这里有个注意的是此时的query数量非常大,这会导致两个问题:第一,正负样本会很不均衡;第二,使用matcher分配gt给proposal会导致分配较慢,且密集proposal上进行一一配对会导致训练不稳定,较难收敛。DeformableTransformerDecoder在 不用return_intermediate时的输出需要进行unsqueeze,否则在detector中调用时会有维度问题。- 在
deformable_detr中DeformableDETR的定义中, 在使用refine技术时,class_embed、bbox_embed是不共享参数的, 而不使用refine技术时,每层的class_embed, bbox_embed是参数共享的,使用nn.ModuleList主要是为了forward中推理代码的统一。
总结
Transformer给图像分类和目标检测方向带来了巨大革新,分割、跟踪、视频等方向也不远了吧
NLP和CV的关系变的越来越有趣了,虽然争议很大,但是试想一下,NLP和CV两个领域能用一种范式来表达,该有多可怕,未来图像和文字是不是可以随心所欲的转来转去?可感知可推理的强人工智能是不是不远了?(想想就好)
向着NLP和CV的统一前进
Reference
[1]Attention Is All You Need
[2]An Image is Worth 16*16 Words: Transformers for Image Recognition at Scale
[3]End-to-End Object Detection with Transformers
[4]Deformable DETR: Deformable Transformers for End-to-End Object Detection
欢迎转载,转载请保留页面地址。帮助到你的请点个推荐。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号