数据量与半监督与监督学习 Data amount and semi-supervised and supervised learning
机器学习工程师最熟悉的设置之一是访问大量数据,但需要适度的资源来注释它。处于困境的每个人最终都会经历逻辑步骤,当他们拥有有限的监督数据时会问自己该做什么,但很多未标记的数据,以及文献似乎都有一个现成的答案:半监督学习。
这通常是出现问题的时候。
从历史上看,半监督学习一直是每个工程师作为一种通过仪式进行的兔子洞之一,只是为了发现对普通旧数据标签的新发现。细节对于每个问题都是独一无二的,但从广义上讲,它们通常可以描述如下:
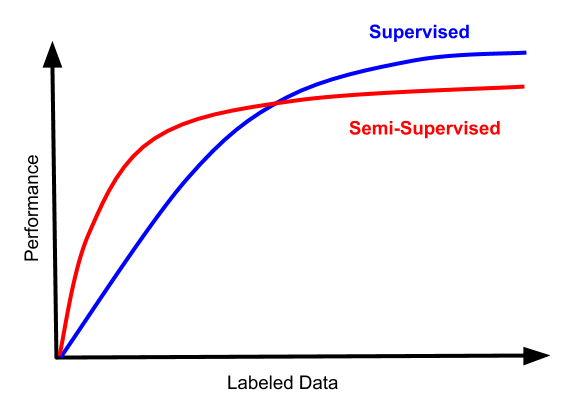
在低数据制度中,半监督培训确实倾向于提高绩效。但在实际环境中,你经常会从“可怕且不可用”的性能水平变为“不太可怕但仍然完全无法使用”。从本质上讲,当你处于半监督学习实际上有帮助的数据体系时,这意味着你也处于一种你的分类器非常糟糕且没有实际用途的制度中。
此外,半监督通常不是免费的,并且使用半监督学习的方法通常不能为您提供监督学习在高数据制度中所做的相同渐近性质 - 未标记的数据可能会引入偏差, 例如。参见例如第4节。在深度学习的早期,一种非常流行的半监督学习方法是首先在未标记数据上学习自动编码器,然后对标记数据进行微调。几乎没有人这样做,因为通过自动编码学习的表示倾向于凭经验限制微调的渐近性能。有趣的是,即使是大大改进的现代生成方法也没有多大改善这种情况,可能是因为什么使得良好的生成模型不一定是什么使得良好的分类器。因此,当您看到工程师今天对模型进行微调时,通常从在监督数据上学习的表示开始 - 是的,我认为文本是用于语言建模目的的自我监督数据。在任何可行的情况下,从其他预训练模型转移学习是一个更加强大的起点,半监督方法难以超越。
因此,典型的机器学习工程师在半监督学习的沼泽中的旅程如下:

1:一切都很糟糕,让我们尝试半监督学习!(毕竟,这是工程工作,比标记数据更有趣......)
2:看,数字上升!但是仍然很可怕。看起来我们毕竟必须标记数据......
3:更多的数据更好,但是你有没有尝试过丢弃半监督机器会发生什么?
4:嘿,你知道什么,它实际上更简单,更好。我们可以通过完全跳过2和3来节省时间和大量技术债务。
如果您非常幸运,您的问题也可能具有这样的性能特征:
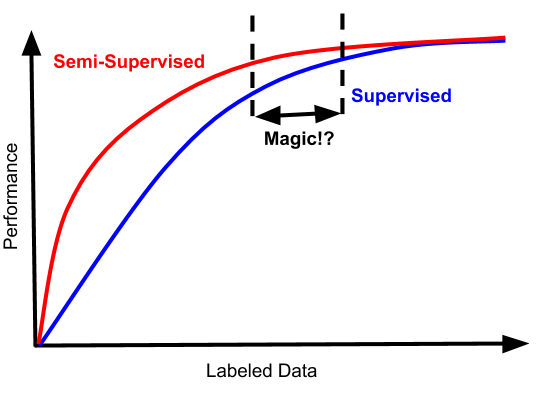
在这种情况下,存在一种狭窄的数据体系,其中半监督是不可怕的并且还提高了数据效率。根据我的经验,很难打到那个甜蜜点。考虑到额外复杂性的成本,标记数据量的差距通常不是更好的数量级,并且收益递减,这很少值得麻烦,除非你在学术基准上竞争。
但等等,这部题为“安静的半监督革命”的作品不是吗?
一个引人入胜的趋势是半监督学习的景观可能会变成看起来更像这样的东西
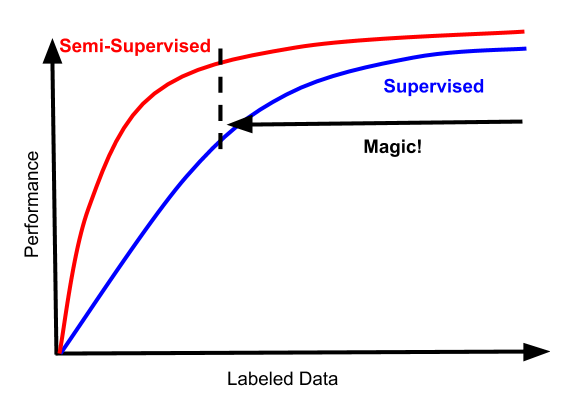
这会改变一切。首先,这些曲线与半监督方法应该做的心理模型相匹配:更多数据应该总是更好。即使对于监督学习表现良好的数据制度,半监督和监督之间的差距也应严格为正。并且越来越多地发生这种情况是免费的,而且额外的复杂性非常小。“魔术区”开始走低,同样重要的是,它不受高数据制度的束缚。
什么是新的?很多东西:许多聪明的方法来自我标记数据并以这样的方式表达损失,即它们与噪声和自我标记的潜在偏差兼容。最近的两部作品举例说明了最近的进展并指出了相关文献:MixMatch:半监督学习和无监督数据增强的整体方法。
半监督学习世界的另一个根本转变是认识到它可能在机器学习隐私中扮演非常重要的角色。例如,颈部的方法(半监督知识转移的深度学习从私人训练数据,可扩展的私学教育与PATE,)从而使监管数据被估计私人,并具有较强的私密性保证学生模型仅使用未标记的培训(假定公共)数据。用于提取知识的隐私敏感方法正在成为联邦学习的关键推动者之一,联合学习提供了有效的分布式学习的承诺,其不依赖于具有访问用户数据的模型,具有强大的数学隐私保证。
在实际环境中重新审视半监督学习的价值是一个激动人心的时刻。看到一个长期存在的假设受到挑战,这是该领域惊人进展的一个很好的指标。这种趋势都是最新的,我们必须看看这些方法是否经得起时间的考验,但是这些进步可能导致机器学习工具架构发生根本转变的可能性非常大。
欢迎转载,转载请保留页面地址。帮助到你的请点个推荐。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号