[知识点] 2.4 排序十讲
总目录 > 2 算法基础 > 2.4 排序十讲
前言
好好地总结一下排序算法啦,虽然在大多数情况下意义不大,毕竟 C++ 自带 sort,但巩固下基础总没有错。
子目录列表
1、时间复杂度
2、选择排序
3、冒泡排序
4、插入排序
5、计数排序
6、基数排序
7、桶排序
8、归并排序
9、快速排序
10、堆排序
11、希尔排序(施工中)
12、归纳总结
2.4 排序十讲
1、时间复杂度
排序,顾名思义,将数组中的元素按照一定次序进行排列,其算法多种多样,性质也大多不同,各有优劣。但是,不管如何,我们对排序算法的需求最高的就是低时间复杂度。
时间复杂度是一个用来衡量某种算法的运行时间和其输入规模之间关系的函数,同理还有空间复杂度,表示方式为 O(复杂度值)。在说时间复杂度前,先说另一个概念:基本操作执行次数 T。
家里有 10 颗桃子,小明一天吃 1 颗,那么小明吃桃子的执行次数为 10;
家里有 n 颗桃子,小明一天吃 1 颗,那么小明吃桃子的执行次数为 T(n) = n;
家里有 n 颗桃子,小明一天吃 m 颗,那么小明吃桃子的执行次数为 T(n, m) = n / m;
家里有 n 箱桃子,一箱有 n 颗,小明一天吃 m 颗,那么小明吃桃子的执行次数为 T(n, m) = O(n ^ 2 / m)。
所以这两者有什么关系?下面是定义:
如果存在一个函数 f(n),使得当 n 趋近于 ∞ 时,T(n) / f(n) 极限值为不等于 0 的常数,则 f(n) 是 T(n) 的同数量级函数。记作 T(n) = O(f(n)),称 O(f(n)) 为算法的渐进时间复杂度,简称时间复杂度。
看起来很深奥的感觉,说简单点,时间复杂度是在基本操作执行次数的基础上省去了系数项和较低阶。比如某个算法的执行次数为 T(n) = 5 * n,则时间复杂度为 O(n);另一个算法执行次数为 T(n) = 2 * n ^ 3 + 2 * n ^ 2 + n,则时间复杂度为 O(n ^ 3)。
回归到算法。一般情况下,计算时间复杂度可以通过递推 / 递归的层数粗略估计,比如:
for (int i = 1; i <= n; i++) a[i] = a[i - 1] + b[i];
这个求前缀和的循环的时间复杂度为 O(n)。再比如:
for (int i = 1; i <= 2 * n; i++) for (int j = 1; j <= n; j++) a[i][j] = a[i - 1][j] + a[i][j - 1];
这个不知何意义的过程的时间复杂度为 O(n ^ 2)。
但并非都是这么简单的循环,还有各种其他的情形,一般可能出现如下时间复杂度:
O(1), O(log n), O(n), O(n log n), O(n * m), O(n ^ 2), O(n!), ...
最后,我们回到排序的问题上来。各类排序算法的时间复杂度是不一致的,那么在所有排序方法说完后,会统一进行归纳总结。
注意,所有算法都按从小到大排序。
2、选择排序
① 基本思想
每次从第 i 个数到第 n 个数中找到最小的元素,将这个元素和第 i 个位置上的元素交换。时间复杂度显然为 O(n ^ 2)。
② 代码
1 void selectionSort() { 2 for (int i = 1; i <= n; i++) { 3 int mi = 0; 4 for (int j = i + 1; j <= n; j++) 5 if (a[j] < a[mi]) mi = j; 6 swap(a[i], a[mi]); 7 } 8 }
③ 稳定性
假设排序前,序列为a[] = {3, 3, 2},根据选择排序的思想,将 a[1] = 3, a[2] = 2 交换,变成 {2, 3, 3};而 a[2] = a[3] = 3,不用交换,排序完成。我们注意到,排序前有两个相等的元素 3,排序后这两个元素的相对顺序发生改变了,这样的排序方法我们称之为不稳定排序。反之,如果使用某种排序算法排序后,任何相等元素的相对顺序没有改变,则称之为稳定排序。
由此可见,选择排序是不稳定排序。
3、冒泡排序
① 基本思想
从第 1 位开始扫描,检查相邻的两个元素,如果前一个元素大于后一个元素,则交换两个元素的位置,一直扫描到第 n 位。扫描完后,能且仅能确定第 n 个元素为整个序列的最大值,则下一轮扫描为从第 1 位到第 n - 1 位,并确定第 n - 1 位为倒数第二大元素,以此类推,扫描 n - 1 次后,完成排序。
② 代码
1 void bubbleSort() { 2 for (int i = 1; i <= n - 1; i++) 3 for (int j = 1; j <= n - i; j++) 4 if (a[j] > a[j + 1]) swap(a[j], a[j + 1]); 5 }
③ 最好与最坏时间复杂度
从代码来看,时间复杂度显然为 O(n ^ 2),但其实这种说法并不严谨。具体而言,时间复杂度分为平均时间复杂度,最坏时间复杂度,最好时间复杂度。本题的平均时间复杂度和最坏时间复杂度(考虑倒序的情况)确实为 O(n ^ 2),但最好呢?
如果序列为正序的话,其实只需要遍历一遍数组而不用执行任何交换操作,但是上面的代码似乎并看不出这一点,因为不管如何都执行了两重 n 循环,所以原代码还有可以优化的地方:如果在本轮扫描中没有出现前面的元素大于后面的元素的情况,则意味着已经满足条件,可以直接退出循环,这样,最好时间复杂度即为 O(n)。
不过,在一般情况中,最坏时间复杂度才有意义,它是算法的下限,只要下限不会超时,不论如何都不会有问题了;在不知道数据是什么样的情况下,最好时间复杂度参考意义不大,这样的优化也只是锦上添花。
④ 最终代码
1 void bubbleSort() { 2 int f = 1; 3 for (int i = 1; i <= n - 1; i++) { 4 f = 1; 5 for (int j = 1; j <= n - i; j++) 6 if (a[j] > a[j + 1]) f = 0, swap(a[j], a[j + 1]); 7 if (f) break; 8 } 9 }
4、插入排序
① 基本思想
从第 i 位开始,每次循环将前 1 到 i - 1 位视作已排序部分,i 到 n 位为未排序部分,在已排序部分中将第 i 位的元素插入到合适的位置,以此类推,共需要循环 n - 1 次。
插入过程最坏时间复杂度为 O(n),故最终时间复杂度也为 O(n ^ 2)。
② 代码
1 void insertSort() { 2 for (int i = 2; i <= n; i++) { 3 int o = a[i]; 4 for (int j = 1; j <= i - 1; j++) 5 if (a[j] >= o) { 6 for (int k = i; k >= j + 1; k--) 7 a[k] = a[k - 1]; 8 a[j] = o; 9 break; 10 } 11 } 12 }
5、计数排序
① 基本思想
统计出每个数出现的次数,再求得该次数的前缀和 sum,则排序前的数组的第 i 位 a[i] 应该在排序后的数组的第 sum[a[i]] 位。如果有相等元素,假设 a[i] = a[i - 1],则将 sum[a[i]]--,即 a[i - 1] 应该在排序后数组的第 sum[a[i]] - 1 位。
看起来有点绕,看代码然后测试几组数据会更好理解。
注意到,既然要统计每个数出现次数且还要计算前缀和,说明时间和空间上都与序列中数的大小挂钩,假设值域为 [1, w],则时间复杂度为 O(n + w),所以不难明白,计数排序非常适用于 n 较大而 w 较小,即元素很多但比较密集的情况,其时间复杂度会远优于 O(n ^ 2) 甚至 O(n log n) 的排序算法。
特别地,如果值域不从 1 开始且较为密集,比如 {92, 94, 91, 95, ...},则在统计次数和前缀和的时候可以采用偏移数据,比如 sum[1..r - l + 1] 来表示 [l, r] 的次数前缀和。
② 代码
1 void countingSort() { 2 for (int i = 1; i <= n; i++) sum[a[i]]++; 3 for (int i = 1; i <= w; i++) sum[i] += sum[i - 1]; 4 for (int i = n; i >= 1; i--) b[sum[a[i]]--] = a[i]; 5 }
(w 表示值域,此处未定义)
6、基数排序
① 基本思想
将每一个数拆分成若干个数位(个位十位等),从最低(高)位起对各个数位依据 0 - 9 来分成 10 组一直到最高(低)位,最终得到排序结果。
两种实现方法:最高位优先法 MSD,从最高位开始;最低位优先法 LSD,从最低位开始。
注意,这里的数位是以十进制举例,则基数为 10,但并不局限于十进制,同样地,你也可以按照二进制,十六进制等等来拆分,则基数均为进制数;极端情况下,甚至可以直接以最大数作为基数,这个在后面会提到。
② 详细过程
假设排序前序列为 a[] = {73, 22, 93, 43, 35, 14, 28, 65, 39, 21}。
以 LSD 举例。首先为个位数,它们被分类为:

将分好类的 10 个数再次串起来,即:
{21, 22, 73, 93, 43, 14, 35, 65, 28, 39}
接下来为十位数,它们被分类为:
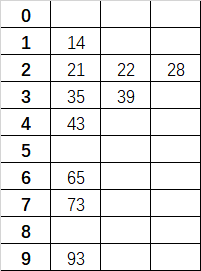
因为最高只到了十位数,所以将 10 个数串起来即为最后结果:
{14, 21, 22, 28, 35, 39, 43, 65, 73, 93}
③ 代码
1 void radixSort() { 2 int o = 1, x; 3 for (int i = 1; i <= d; i++) { 4 x = 1, memset(tot, 0, sizeof(tot)), memset(cnt, 0, sizeof(cnt)); 5 for (int j = 1; j <= n; j++) { 6 int tmp = a[j] / o % 10; 7 tot[tmp]++, cnt[tmp][tot[tmp]] = a[j]; 8 } 9 for (int j = 0; j <= 9; j++) 10 for (int k = 1; k <= tot[j]; k++) 11 a[x] = cnt[j][k], x++; 12 o *= 10; 13 } 14 }
(d 表示数位位数,此处未定义)
④ 基数?计数?
但是,上述代码并非最好的办法——每一轮都需要将每一组的所有数都存储下来,空间需求很高;当然,这一点可以用动态分配内存或者使用 vector 来解决,但其实我们根本不需要存它们。
回顾一下计数排序,我们是通过求得前缀和得到的各个数的排位,相当方便,其实基数排序同样可以这样排位,甚至可以直接使用计数排序的算法,只不过需要对于每一个数位都要进行一次,具体见下方代码。
⑤ 最终代码
1 void countingSort_r(int o) { 2 for (int i = 1; i <= n; i++) sum[a[i] / o % 10]++; 3 for (int i = 1; i <= 9; i++) sum[i] += sum[i - 1]; 4 for (int i = n; i >= 1; i--) b[sum[a[i] / o % 10]--] = a[i]; 5 for (int i = 1; i <= n; i++) a[i] = b[i]; 6 } 7 8 void radixSort() { 9 int o = 1, x; 10 for (int i = 1; i <= d; i++) { 11 x = 1, memset(sum, 0, sizeof(sum)); 12 countingSort_r(o); 13 o *= 10; 14 } 15 }
7、桶排序
① 基本思想
将序列的所有数的值域拆分成若干个“桶”,每一个桶的容量是一致的,再依次将这些数根据大小分别放入这些桶,然后对于每个桶再分别进行排序,内层排序可以使用任意排序方法。也就是说,桶排序本身并没有自己的排序部分,只是提供一种将问题简化的思路,并且,能很好地体现分治的思想。
比如值域为 [0, w],分成 5 个桶,则每个桶所表示的值域分别为 [0, 1 / 5 * w], (1 / 5 * w, 2 / 5 * w], ..., (4 / 5 * w, 1]。
根据这个思路,不难发现桶排序适用于值域较大,但是分布较为均匀的情况,这样放入和内层排序都很轻松,其时间复杂度为 O(n + k),k 表示桶的个数,计算过程略。
看完这个桶排序觉得似曾相识——其实它和基数排序的关系很密切。
② 计数,基数与桶排序
上面先后介绍了这三种排序,这里单独捋一捋之间的关系与区别。
> 计数排序是一种特殊的桶排序。即将整个值域视作一个桶,然后进行一轮排序即可(这里有一个疑问:既然计数排序是只有一个桶的桶排序,而桶排序实质上就是分桶再套用排序算法,那其他排序算法不应该都可以视作桶排序的一种?或者这种所谓特殊的桶排序本身就没有意义,因为桶排序本身就不是一种独立的排序算法?)
> 基数排序是一种特殊的桶排序。桶排序根据值域区间来划分,而计数排序根据数位,且需要进行多轮桶排序;
> 基数排序是一种特殊的计数排序。这个在介绍基数排序时就有提过了,基数排序相当于逐位进行多轮计数排序;而当用最大值作为基数时,则相当于只需要一轮计数排序,基数排序也就退化成了计数排序。
③ 代码
1 void bucketSort() { 2 int size = w / k + 1, tot = 0; 3 for (int i = 1; i <= n; i++) 4 b[a[i] / size].push_back(a[i]); 5 for (int i = 1; i <= k; i++) { 6 anySort(b[i]); 7 for (int j = 1; j <= b[i].size(); j++) 8 tot++, a[tot] = b[i][j]; 9 }
(w 表示值域,k 表示桶的数量,b 为 vector 类,此处均未定义;同时,代码中的 "anySort(b[i])" 为伪代码,表示使用任何排序算法对第 i 个桶内的元素进行排序)
8、归并排序
① 基本思想
将数列平均划分为两个子序列,分别递归,再次划分为两个子序列,并进行排序,最后逐层回溯将划分的两个子序列合并。
由于合并前的两个子序列本身就是有序的,其实合并并不难操作。
② 详细过程
假设排序前序列为 a[] = {73, 22, 93, 35, 14, 21, 65, 39}。
> 划分 {73, 22, 93, 35} 和 {14, 21, 65, 39}
> 划分 {73, 22} 和 {93, 35}
> 划分 {73} 和 {22},只剩一个元素,回溯;{93} 和 {35} 同理
> 合并 {73} 和 {22},22 < 73,先加入 22,再加入 73,即 {22, 73},合并完成;{35, 93} 略
> 合并 {22, 73} 和 {35, 93},22 < 35,加入 22;35 < 73,加入 35;73 < 93,加入 73, 93,即 {22, 35, 73, 93},合并完成;
> 划分 {14, 21, 65, 39},略,得到 {14, 21, 39, 65}
> 合并 {22, 35, 73, 93} 和 {14, 21, 39, 65},14 < 22,加入 14;21 < 22,加入 21;后续略,得到 {14, 21, 22, 35, 39, 65, 73, 93},合并完成。
再看个图。
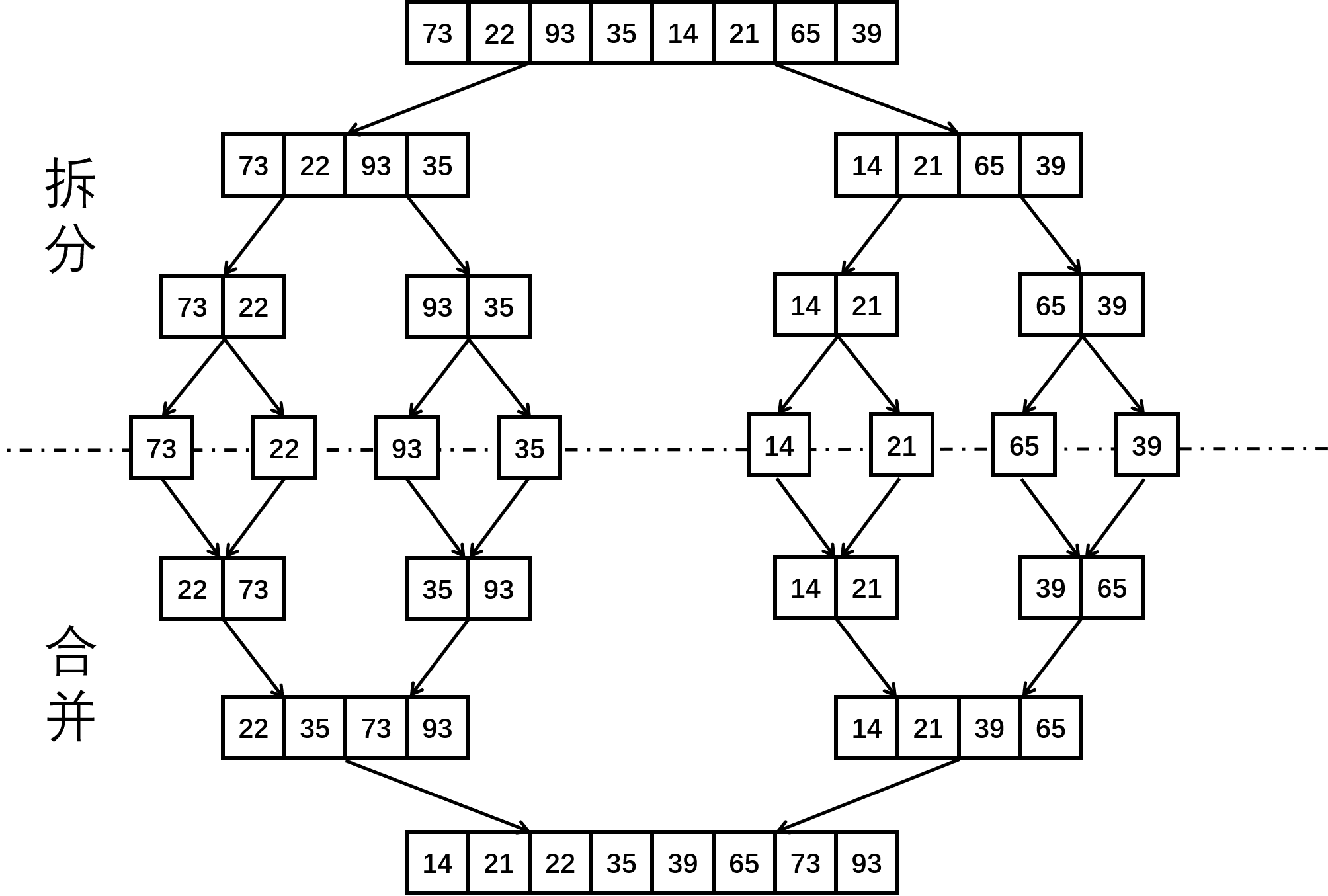
合并的方式其实很简单——维护两个首指针,每次从两个有序序列中的两个最小值中选择较小值即可。
最后分析一下时间复杂度:对于 n 个数的数列,其长度为 k 的子序列合并时间复杂度为 O(k);而拆分层数,即每个数被合并的次数为 log n(这一点由二叉树的性质可得,请参见:7.3 树与二叉树),则其平均时间复杂度为 O(n log n),也是目前所有比较型排序算法中最快的,这个在归纳时会详细比较。
③ 代码
1 void merge(int l, int r) { 2 if (l == r) return; 3 int mid = (l + r) >> 1; 4 merge(l, mid), merge(mid + 1, r); 5 int fl = l, fr = mid + 1, o = l; 6 while (o <= r) { 7 if (a[fl] < a[fr] || fr > r) { 8 tmp[o] = a[fl]; 9 o++, fl++; 10 } 11 else { 12 tmp[o] = a[fr]; 13 o++, fr++; 14 } 15 } 16 for (int i = l; i <= r; i++) a[i] = tmp[i]; 17 } 18 19 void mergeSort() { 20 merge(1, n); 21 }
9、快速排序
① 基本思路
将数列非均等地划分为两个子序列,分别递归,再次划分为两个子序列,并进行排序,最后逐层回溯将划分的两个子序列直接拼接。
看起来和归并排序是孪生的,区别就在于,每次的划分并非平均划分,而是在分的过程中保证相对大小关系,以使回溯时不再需要合并而直接拼接即可。
快速排序的定义并没有对划分的方式有明确规定,这里只介绍一种:
对于每个序列,以其第一个数作为基准数,从第二个数到最后一个数进行分类,比基准数小的为一部分,大的为一部分,再分别对这两部分递归。
② 详细过程
假设排序前序列为 a[] = {73, 22, 93, 35, 14, 21, 65, 39}。
> 起始区间基准数为 73。{22, 35, 14, 21, 65, 39} 小于 73,为一部分,移动到 a[1..6];{93} 大于 73,为一部分,移动到 a[8];73 移动到 a[7];
> 对于 {22, 35, 14, 21, 65, 39},基准数为 22。{14, 21} 小于 22,为一部分,移动到 a[1..2];{35, 65, 39} 大于 22,为一部分,移动到 a[4..6];22 移动到 a[3];
> 对于 {14, 21},基准数为 14,{21} 大于 14,为一部分,在 a[2] 不变,14 在 a[1] 不变;对于 {35, 65, 39},基准数为 35,{65, 39} 大于 35,为一部分,移动到 a[5..6],35 在 a[4] 不变;
> 对于 {21},直接回溯;对于 {65, 39}, 基准数为 65,{39} 小于 65,为一部分,移动到 a[5],65 移动到 a[6];
更多步骤省略。
还是看个图。

感觉应该画的比较清楚了(
当然,基准数有很多选择方法,可以是最后一位,最中间一位,随机一位。
和归并排序一样,快速排序平均时间复杂度也是 O(n log n)。以后会经常发现一点,采用分治思想的算法,往往能够把原本的 n 的时间复杂度降为 log n,还有二分思想(请参见:2.5 二分思想)。
③ STL 中的 sort 函数
sort 是作为 <algorithm> 中最常用的算法,也是平常在遇到排序问题时相当通用的一种方法。
其实在 C 的标准库里已经有了排序函数 qsort,定义在了 <stdlib.h>,就是快速排序的模板函数;而 sort 并非完全是快速排序,它并未被严格要求实现方式,一般取决于编译器,只要求最坏时间复杂度为 O(n log n) 即可(C++11 之前要求平均为 O(n log n) )。
其使用方法:
sort(a + x, a + y, cmp),其中 a 为需要排序的数组(结构体/类同样可以,但需要重载运算符,请参见:https://www.cnblogs.com/jinkun113/p/12744678.html),x 为排序范围的首位,y 为末位的后一位,cmp 为自定义状态函数,可不写。
举一个例子,现在需要对 Student 类的第 2 至 10 名的语文成绩排序,则代码为:
1 class Student { 2 public: 3 int chn, mat, eng; 4 bool operator < (const Student &x) const { 5 return chn < x.chn; 6 } 7 } s[20]; 8 9 void stlSort() { 10 sort(s + 2, s + 11); 11 }
状态函数的使用方法:
> 从大到小
sort(a + 1, a + n + 1, greater <int>());
> 自定义
可以在结构体/类外额外定义一个比较函数,可以使其在不同情况下使用不同的排序方法,比如:
1 class Student { 2 public: 3 int chn, mat, eng; 4 bool operator < (const Student &x) const { 5 return chn < x.chn; 6 } 7 } s[20]; 8 9 bool cmpEng (const Student a, const Student b) { 10 return a.eng < b.eng; 11 } 12 void stlSort() { 13 sort(s + 1, s + 10); 14 sort(s + 1, s + 10, cmpEng); 15 }
L13 为比较语文成绩,L14 为比较英语成绩。
所以有了 sort,理论上就不用对这些排序算法尤其快速排序有太过深入的了解,因为 sort 已经能满足大多数情况下的要求,也是大多数情况下时间复杂度最低的,所以这么多年来我都没去学快排(
但是并不是所有语言都会内置,所以了解总没坏处。
④ 代码
1 void work(int l, int r) { 2 if (l == r) return; 3 int tl = 0, tr = 0; 4 for (int i = l + 1; i <= r; i++) 5 if (a[i] < a[l]) tl++, ls[tl] = a[i]; 6 else tr++, rs[tr] = a[i]; 7 a[l + tl] = a[l]; 8 for (int i = 1; i <= tl; i++) a[l + i - 1] = ls[i]; 9 for (int i = 1; i <= tr; i++) a[l + tl + i] = rs[i]; 10 if (tl) work(l, l + tl - 1); 11 if (tr) work(l + tl + 1, r); 12 } 13 14 void quickSort() { 15 work(1, n); 16 }
10、堆排序
请参见:7.4 堆与优先队列
11、希尔排序
属于插入排序的一类,暂略。
12、归纳总结
先列出各大排序的类型,平均时间复杂度,稳定性,适用情景。
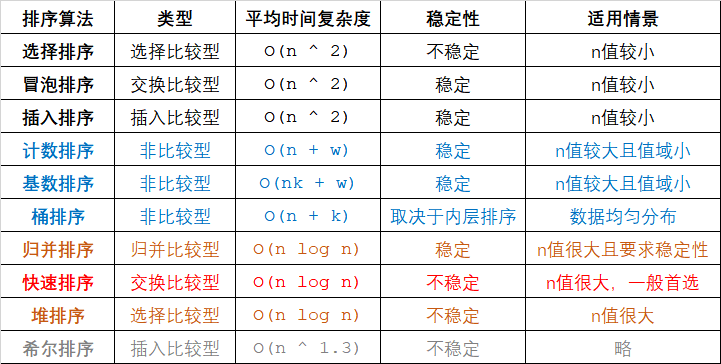
最开始介绍的三种排序——选择排序,冒泡排序,插入排序,是最为基础最好理解的,同时也是效率最低的,在确定数据不太大的情况下可以使用,因为代码量小;
而后介绍的三种排序——计数排序,基数排序,桶排序,其实是一家人,它们和其他所有排序的思路都不同,并非通过数与数之间的比较来进行排列,时间复杂度看起来也是那么另类,看似是 O(n) 级别,但还受到了值域 w 和分类个数 k 的限制,所以适用于 n 很大而值域小,也就是数据变化量小的情况。桶排序较为特殊,在数据足够均匀的情况下,桶排序的期望时间复杂度是可以达到 O(n) 的,而如果很密集,则完全取决于其内层排序的效率了。
再后来的三种排序——归并排序,快速排序,堆排序,是一般情况下效率最高的,也是相对最难写的。相比之下,归并排序保证稳定性,但空间需求较大,因为用到了二叉树结构;而快速排序不用考虑空间问题,所以一般可以首选;堆排序在使用 STL 中的 priority_queue(请参见:7.4 堆与优先队列)则也非常方便。
希尔排序暂时不介绍。
当然,说了这么多,如果使用的是 C 或 C++,在遇到排序问题时基本可以无脑使用 sort 函数,也就不用去考虑太多在什么情况使用什么排序算法了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号