介绍
- Elasticsearch是一个实时的分布式搜索分析引擎, 它被用作全文检索、结构化搜索、分析以及这三个功能的组合;
- Index 对应 DB,Type 对应表,Document 对应记录
其他
知识点
- 集群: 多台物理机,通过配置一个相同的cluster name,组织成一个集群
- 节点: 同一个集群中的一个 Elasticearch主机
- 主分片: 索引的一个物理子集。同一个索引在物理上可以切多个分片,分布到不同的节点上。分片的实现是Lucene 中的索引, 个数是建立索引时就要指定的,建立后不可再改变
- 副本分片: 每个主分片可以有一个或者多个副本,个数是用户自己配置的
- 索引:(database) 索引数据的存储位置, 数据会被索引成一个index
- 类型: (table)索引中的分类
- 由于索引几乎有固定的开销,所以建议使用较少的索引和较多的类型
- 文档: (row)ES中一个可以被检索的基本单位
- 字段: (column)
- 映射: (schema)
查询
get /_index/_type/_id
//例子
http://localhost:9200/library/article/57508457556e30622882ba58
//返回
//未找到
{
_index: "library", //索引
_type: "article", //类型
_id: "57508457556e3043434", //文档ID
found: false
}
//查找到
{
_index: "library",
_type: "article",
_id: "57508457556e30622882ba58",
_version: 1, //版本号,每次改动会+1
found: true,
_source: { //文档全部内容
........
}
}
get /_index/_type/_search?q=
//例子
http://localhost:9200/library/article/_search?q=title:pariatur
//未找到
{
took: 1, //查询花费的时间,单位毫秒
timed_out: false, //是否超时
_shards: { //描述分片的信息
total: 5, //查询了多少个分片
successful: 5, //成功的分片数量
skipped: 0, //跳过的分片数量
failed: 0 //失败的分片数量
},
hits: { //搜索的结果
total: 0, //全部的满足条件的文档数目
max_score: null, //文档最大得分
hits: [ ]
}
}
//正则, 以空格分开等于OR, 注意括号区分优先级
name.raw:/.*jinks.*/ OR username.raw:(/.*jinks.*/ OR "jinks")
get http://localhost:9200/library/article/_search
参数:
{
"query": {
"match": {
"title": "pariatur"
}
},
"from": 0, //表示从第几行开始(默认0)
"size": 10 //表示查询多少条文档(默认10)
}
//注意:如果搜索size大于10000,需要设置index.max_result_window参数,size的大小不能超过index.max_result_window这个参数的设置,默认为10,000。
//相当于
{
"query": {
"bool": {
"must": [{
"match": {
"title": "pariatur"
}
}]
}
},
"size": 10
}
- 多条件查询 bool:must、filter、should
{
"query": {
"bool" : { //成为query的过滤器,还有其它的,如:and,or,not,limit
"must" : { //must,filter,should为过滤条件,如果有多个子条件,使用[]
"term" : { "user" : "kimchy" }
},
"filter": {
"term" : { "tag" : "tech" }
},
"must_not" : {
"range" : {
"age" : { "gte" : 10, "lte" : 20 }
}
},
"should" : [
{ "term" : { "tag" : "wow" } },
{ "term" : { "tag" : "elasticsearch" } }
],
"minimum_should_match" : 1, //用于现在should的子条件匹配个数。
"boost" : 1.0 //表示此过滤器的权重,默认1.0
}
}
}
//filter 对于数字: gt, lt, ge, le
//6.x
{
"query" : {
"match_phrase" : {
"title": "xxxx1 xxxx2" //非短语搜索为或
}
}
}
//5.x
{
"query": {
"match" : {
"title": {
"query": "xxxx1 xxxx2",
"type": "phrase"
}
}
}
}
{
"query": {...},
"highlight": {
"fields" : {
"name": {}
}
}
}
//返回
{
items: [{
....,
hightlight: [{name: ...<em>..<em>..}]
}],
counts: {...}
}
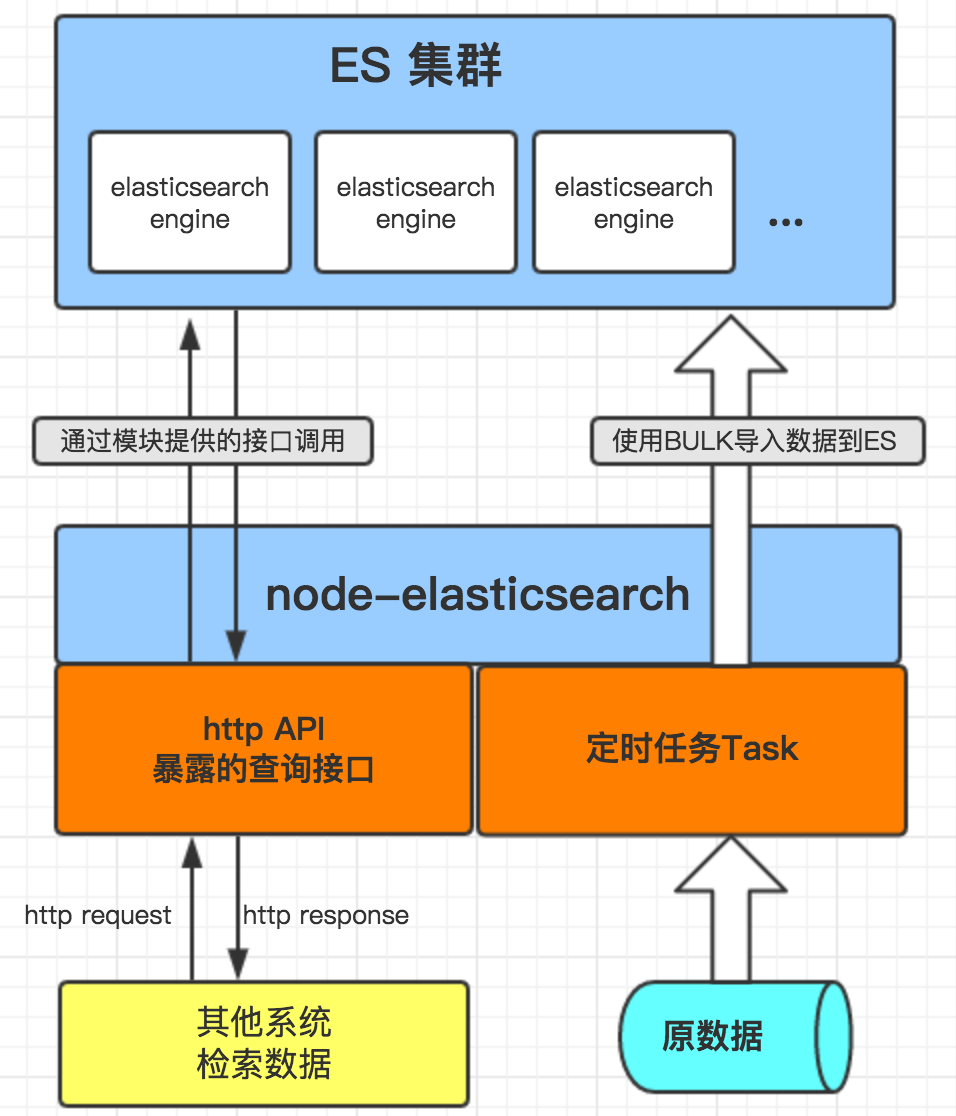
开发思路

 浙公网安备 33010602011771号
浙公网安备 33010602011771号