使用Pytorch在多GPU下保存和加载训练模型参数遇到的问题
最近使用Pytorch在学习一个深度学习项目,在模型保存和加载过程中遇到了问题,最终通过在网卡查找资料得已解决,故以此记之,以备忘却。
首先,是在使用多GPU进行模型训练的过程中,在保存模型参数时,应该使用类似如下代码进行保存:
对应的在加载模型参数时,使用如下代码进行加载是没有问题的:

请注意红圈的地方缺了“module”关键字,导致在保存模型参数时,参数保存成了这样(模型参数是以key-value的形式保存的),即stat_dict(key),对应的value每个值都多了一个module:
接下来在加载模型参数时,如果直接使用代码 model.load_state_dict(torch.load('模型参数文件存放路径')['state_dict'])就会出现问题。报错如下:
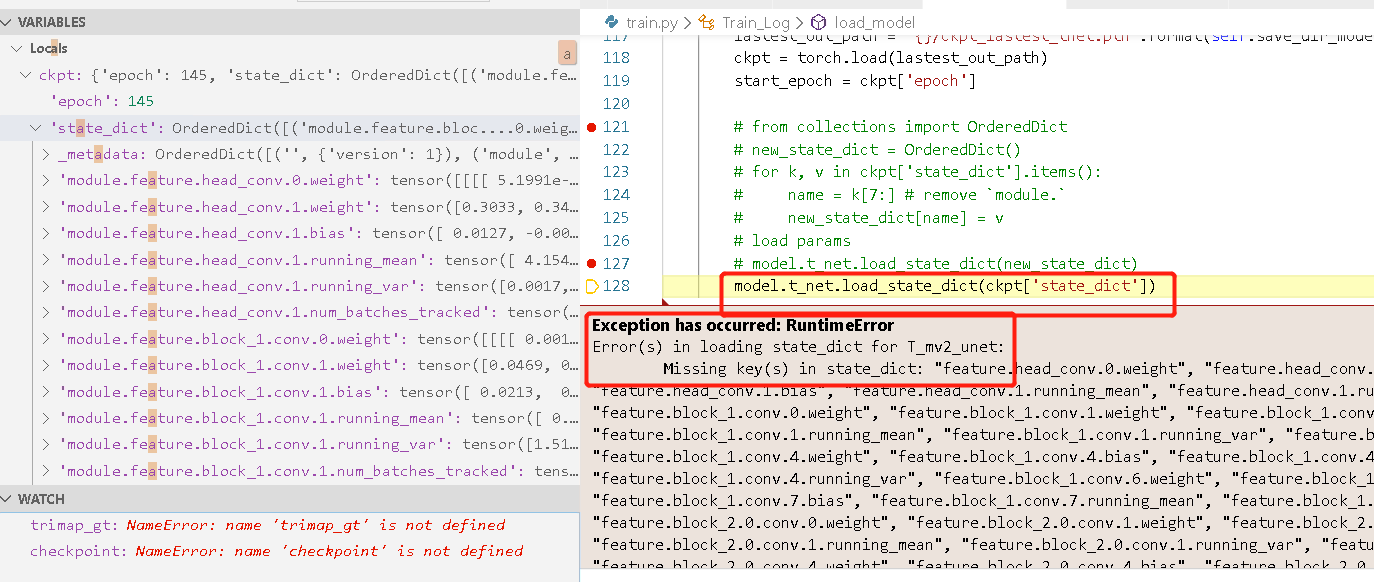
好了,既然知道了出问题的原因在哪里,那就来考虑下如何处理了,两种方案:
第一,修改保存模型的代码(加上"module")后,把模型重新训练一次,重新加载即可。但我们大家都知道,这样的深度模型训练,时间一般都是以小时或者天计的,我们等不了那么久。(如果时间允许,可以这么干。哈哈!)
第二,在加载模型参数之前,写代码将模型参数里的"module"关键字给去掉。比如可以这么写:

实话实说,这个代码并不是我的原创,网上给出这个解决方案的地方很多。但我这里有一点不同的时,我加了个“[state_dict]”,我看到的很多地方是没有这个的,直接就是ckpt.items()。因为我并不知道他们保存模型参数的代码是怎么写的,所以也并不好评论对错。但总之一句话,我们是要通过这段代码,去掉状态字典里的"module"关键字的所以大家可以通过debug,查看这里的k取到的是什么值,应该要是取到下图所示红色框里的值,然后通过“name=k[7:]”去掉前面的"module",然后再加载就可以了。

文中提到一个词“[state_dict]”,大家不用太在意,有的人在保存模型参数时,用的是“model”,只要在保存和读取的时候,保持一致就可以了。
欢迎大家对描述不清楚或者不准确的地方提出批评意见和建议!
posted on 2020-04-10 11:03 jinjunweina 阅读(3941) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号