SpringCloud学习之七:使用Spring Cloud Sleuth实现微服务跟踪
使用Spring Cloud Sleuth实现微服务跟踪
Spring Cloud版本:Hoxton.SR5
1. 简介
Spring Cloud Sleuth为Spring Cloud提供了分布式跟踪的解决方案,它大量借用了Google Dapper、Twitter Zipkin和Apache HTrace的设计。
Sleuth借用了Dapper的术语:
-
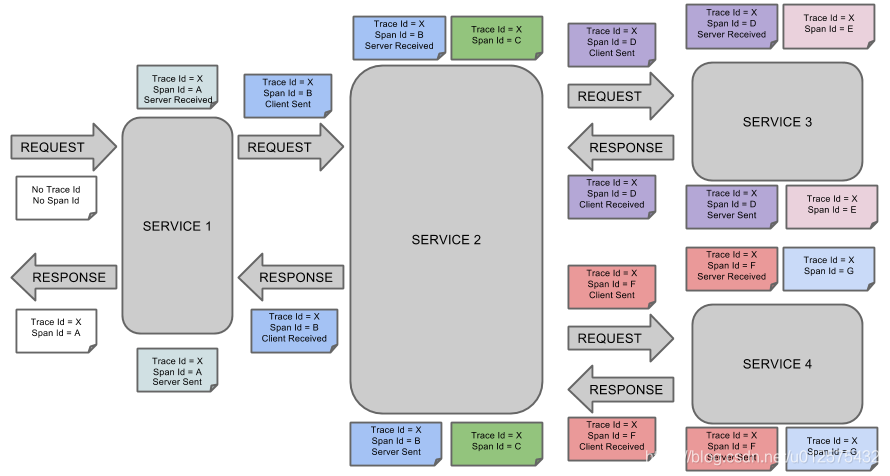
span(跨度):基本工作单元。span用一个64位的id唯一标识。除ID外,span还包含了其他数据,例如描述、时间戳事件、键值对的注解(标签),spanID、span父ID等。span被启动和停止时,记录了时间信息。初始化span被称为“root span”,该span的id和trace的ID相等。
-
trace(跟踪):一组共享“root span”的span组成的树状结构称为trace。trace也用一个64位的ID唯一标识,trace中的所有span都共享该trace的ID。
-
annotation(标注):annotaion用来记录事件的存在,其中,核心annotaion用来定义请求的开始和结束。
-
CS(Client Server客户端发送):客户端发起一个请求,该annotaion描述了span的开始
-
SR(Server Received服务器端接收):服务器端获得请求并准备处理它。如果用SR减去CS时间戳,就能得到网络延迟
-
SS(Server Sent服务器端发送):该annotation表明如果完成请求处理(当响应发挥客户端时)。如果用SS减去SR时间戳,就能得到服务器端处理请求所需的时间
-
CR(Client Received客户端接收):span结束的标识。客户端成功接收到服务器端的响应。如果CR减去CS时间戳,就能得到客户端发送请求到服务器响应所需的时间
-
2. 整合Spring Cloud Sleuth
-
在scl-eureka-client-consumer和scl-eureka-client-provider中添加如下依赖
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-sleuth</artifactId> </dependency> -
在配置文件application.yml中添加如下配置
logging: level: root: INFO org.springframework.web.servlet.DispatcherServlet: DEBUG org.springframework.cloud.sleuth: DEBUG -
重启两个项目,访问http://localhost:8090/consumer/info,可发现两个项目的日志内容中已包含span和trace的一些信息

3. 整合ELK
ELK是一款非常流行的日志分析系统。搭建过程请参考:https://blog.csdn.net/u012575432/article/details/107252814
-
在scl-eureka-client-consumer和scl-eureka-client-provider中添加如下依赖
<dependency> <groupId>net.logstash.logback</groupId> <artifactId>logstash-logback-encoder</artifactId> <version>6.4</version> </dependency> -
因为日志需要输出给logstash进行分析,因此需要在
src/main/resources目录下新建文件logback-spring.xml,内容如下:<?xml version="1.0" encoding="UTF-8"?> <configuration> <include resource="org/springframework/boot/logging/logback/defaults.xml"/> <springProperty scope="context" name="springAppName" source="spring.application.name"/> <!-- Example for logging into the build folder of your project --> <property name="LOG_FILE" value="${BUILD_FOLDER:-log}/${springAppName}"/> <!-- You can override this to have a custom pattern --> <property name="CONSOLE_LOG_PATTERN" value="%clr(%d{yyyy-MM-dd HH:mm:ss.SSS}){faint} %clr(${LOG_LEVEL_PATTERN:-%5p}) %clr(${PID:- }){magenta} %clr(---){faint} %clr([%15.15t]){faint} %clr(%-40.40logger{39}){cyan} %clr(:){faint} %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}"/> <!-- Appender to log to console --> <appender name="console" class="ch.qos.logback.core.ConsoleAppender"> <filter class="ch.qos.logback.classic.filter.ThresholdFilter"> <!-- Minimum logging level to be presented in the console logs--> <level>DEBUG</level> </filter> <encoder> <pattern>${CONSOLE_LOG_PATTERN}</pattern> <charset>utf8</charset> </encoder> </appender> <!-- Appender to log to file --> <appender name="flatfile" class="ch.qos.logback.core.rolling.RollingFileAppender"> <file>${LOG_FILE}.log</file> <rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"> <fileNamePattern>${LOG_FILE}.%d{yyyy-MM-dd}.gz</fileNamePattern> <maxHistory>7</maxHistory> </rollingPolicy> <encoder> <pattern>${CONSOLE_LOG_PATTERN}</pattern> <charset>utf8</charset> </encoder> </appender> <!-- Appender to log to file in a JSON format --> <appender name="logstash" class="ch.qos.logback.core.rolling.RollingFileAppender"> <file>${LOG_FILE}.json</file> <rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"> <fileNamePattern>${LOG_FILE}.json.%d{yyyy-MM-dd}.gz</fileNamePattern> <maxHistory>7</maxHistory> </rollingPolicy> <encoder class="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder"> <providers> <timestamp> <timeZone>UTC</timeZone> </timestamp> <pattern> <pattern> { "severity": "%level", "service": "${springAppName:-}", "trace": "%X{traceId:-}", "span": "%X{spanId:-}", "baggage": "%X{key:-}", "pid": "${PID:-}", "thread": "%thread", "class": "%logger{40}", "rest": "%message" } </pattern> </pattern> </providers> </encoder> </appender> <root level="INFO"> <appender-ref ref="console"/> <appender-ref ref="logstash"/> <!-- <appender-ref ref="flatfile"/> --> </root> </configuration> -
因为
logback-spring.xml中使用了spring.application.name属性,所以需要将spring.application.name移动到bootstrap.yml下。因为logback-spring.xml配置先于
application.yml加载,所以若仍将spring.application.name放在application.yml里,将无法正确读取属性 -
编写Logstash配置文件,命名为logstash.conf,放在
config目录下,然后重启Logstash。内容如下input { file { codec => json path => "/home/sc/eureka-client/log/*.json" # logback输出的json格式日志文件 } } filter { grok { match => { "message" => "%{TIMESTAMP_ISO8601:timestamp}\s+%{LOGLEVEL:severity}\s+\[%{DATA:service},%{DATA:trace},%{DATA:span},%{DATA:exportable}\]\s+%{DATA:pid}\s+---\s+\[%{DATA:thread}\]\s+%{DATA:class}\s+:\s+%{GREEDYDATA:rest}" } } date { match => ["timestamp", "ISO8601"] } mutate { remove_field => ["timestamp"] } } output { elasticsearch { hosts => ["http://127.0.0.1:9000"] # ES地址 } } -
重启两个项目,多次访问http://localhost:8090/consumer/info,产生日志
-
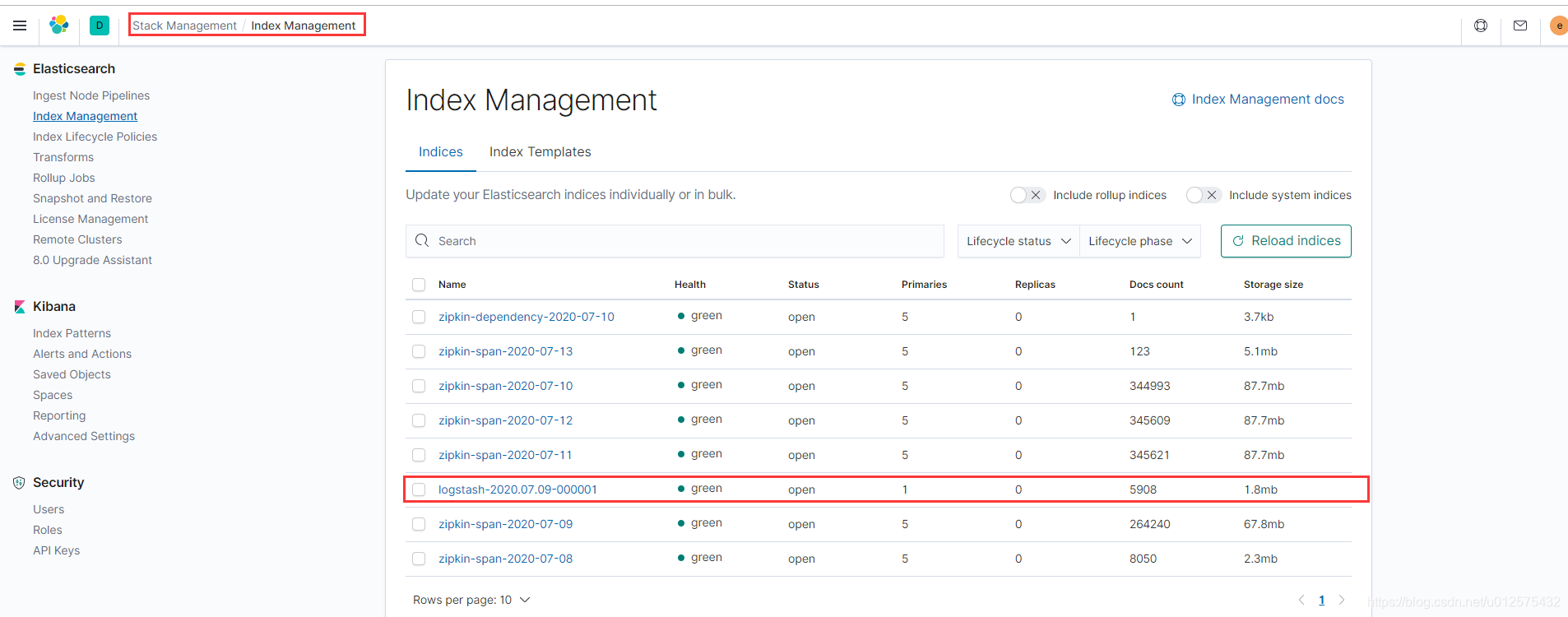
然后访问Kibana首页http://localhost:5601,找到Elasticsearch下的Index Management,发现列表中已存在logstash开头的index
-
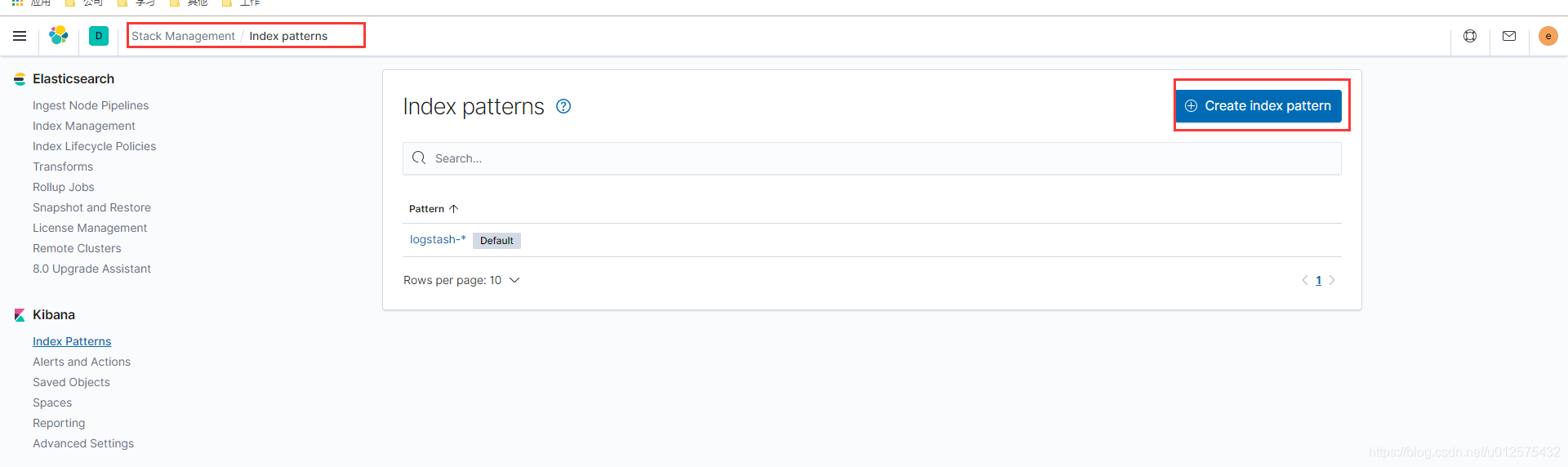
然后找到Kibana下的Index Patterns,并按照如下步骤创建Index Pattern
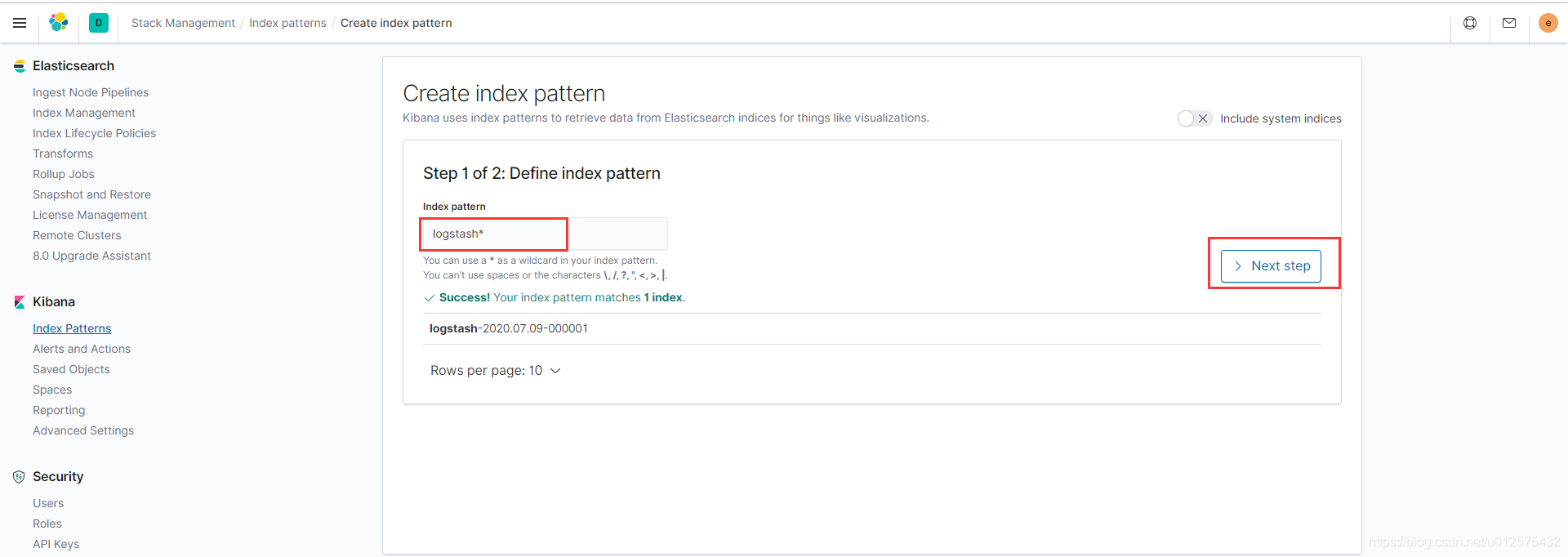
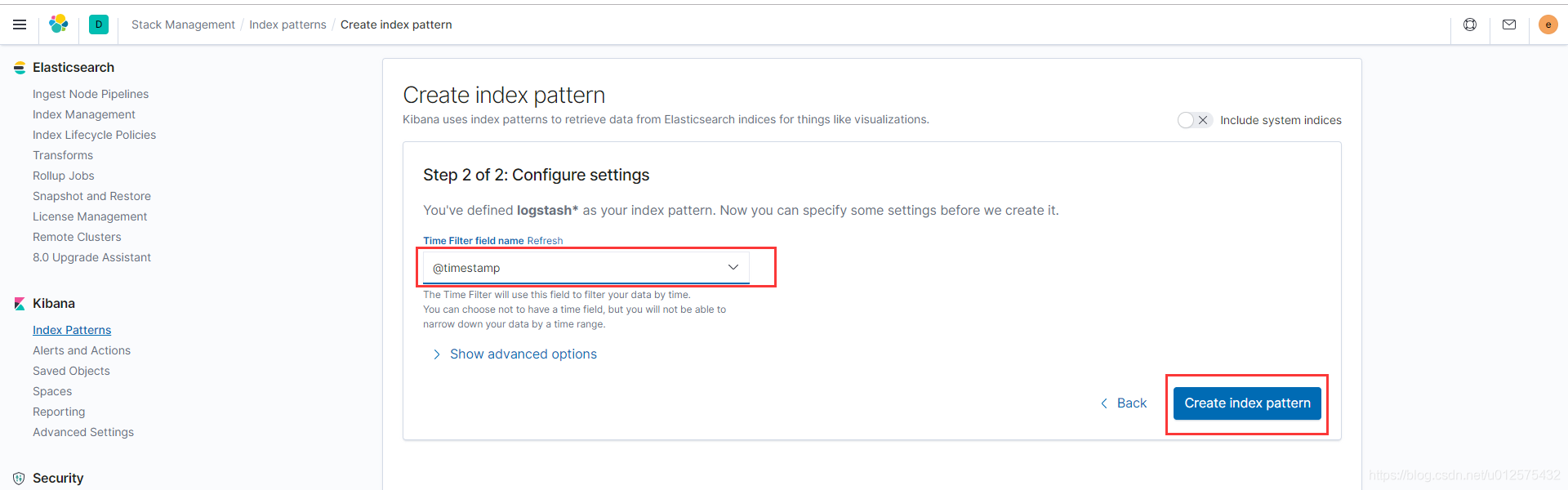
-
创建完成后,点击Kibana下的Discover,即可看见如下日志。一个完整的http请求过程,展开可发现traceID都是一致的
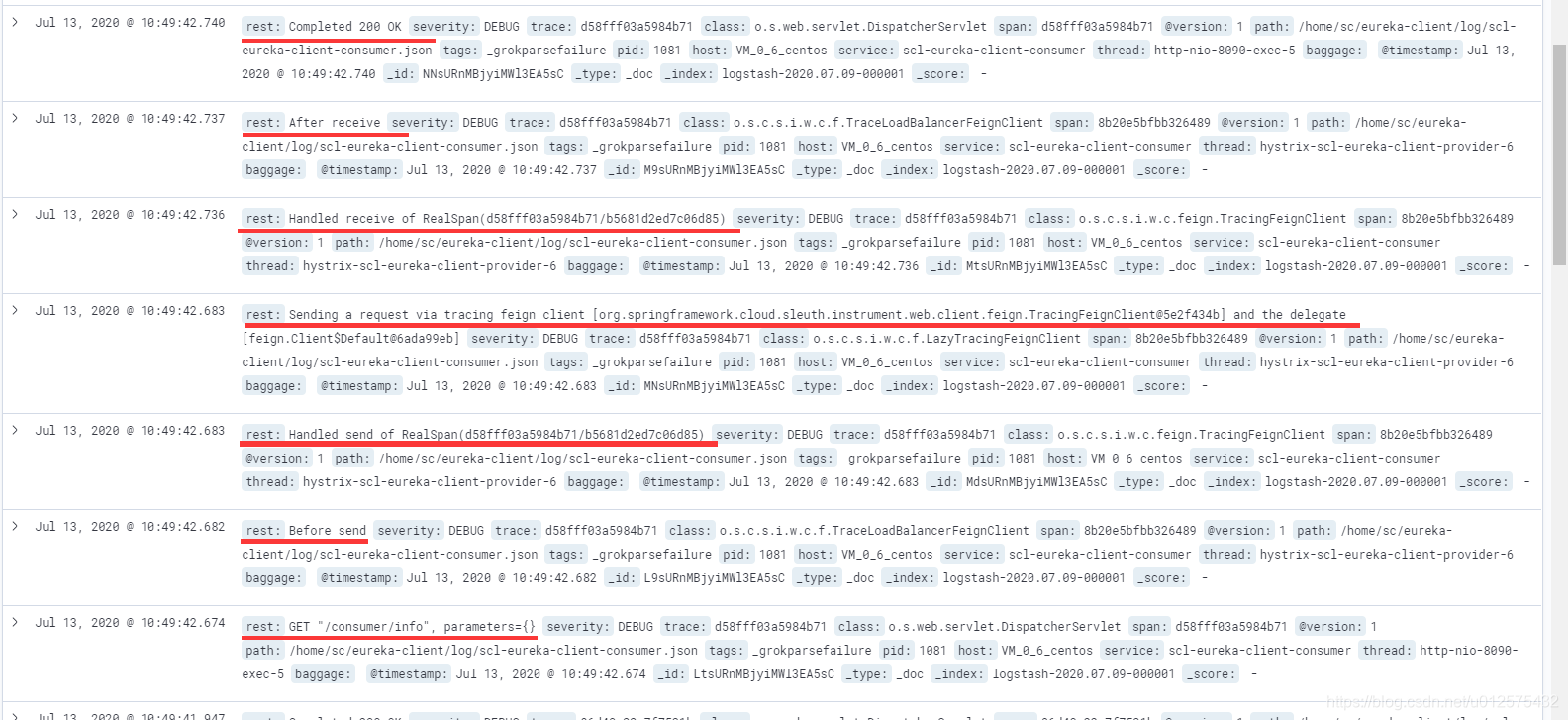
4. 整合Zipkin
ELK实现了业务日志的跟踪,Zipkin可实现服务链路日志跟踪
Spring官网已不推荐自己实现Zipkin Server端,建议使用原生的Zipkin Server
zipkin-server:https://search.maven.org/remote_content?g=io.zipkin&a=zipkin-server&v=LATEST&c=exec
zipkin-dependencies:https://search.maven.org/remote_content?g=io.zipkin.dependencies&a=zipkin-dependencies&v=LATEST
4.1 微服务整合Zipkin
-
启动zipkin服务端
nohup java -jar zipkin-server-2.21.5-exec.jar >> /home/sc/zipkin-server/zipkin.log 2>&1 & -
在scl-eureka-client-consumer和scl-eureka-client-provider中添加如下依赖
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-zipkin</artifactId> </dependency> -
在application.yml里添加zipkin相关配置
spring: zipkin: base-url: http://127.0.0.1:9411 sleuth: sampler: probability: 1.0 -
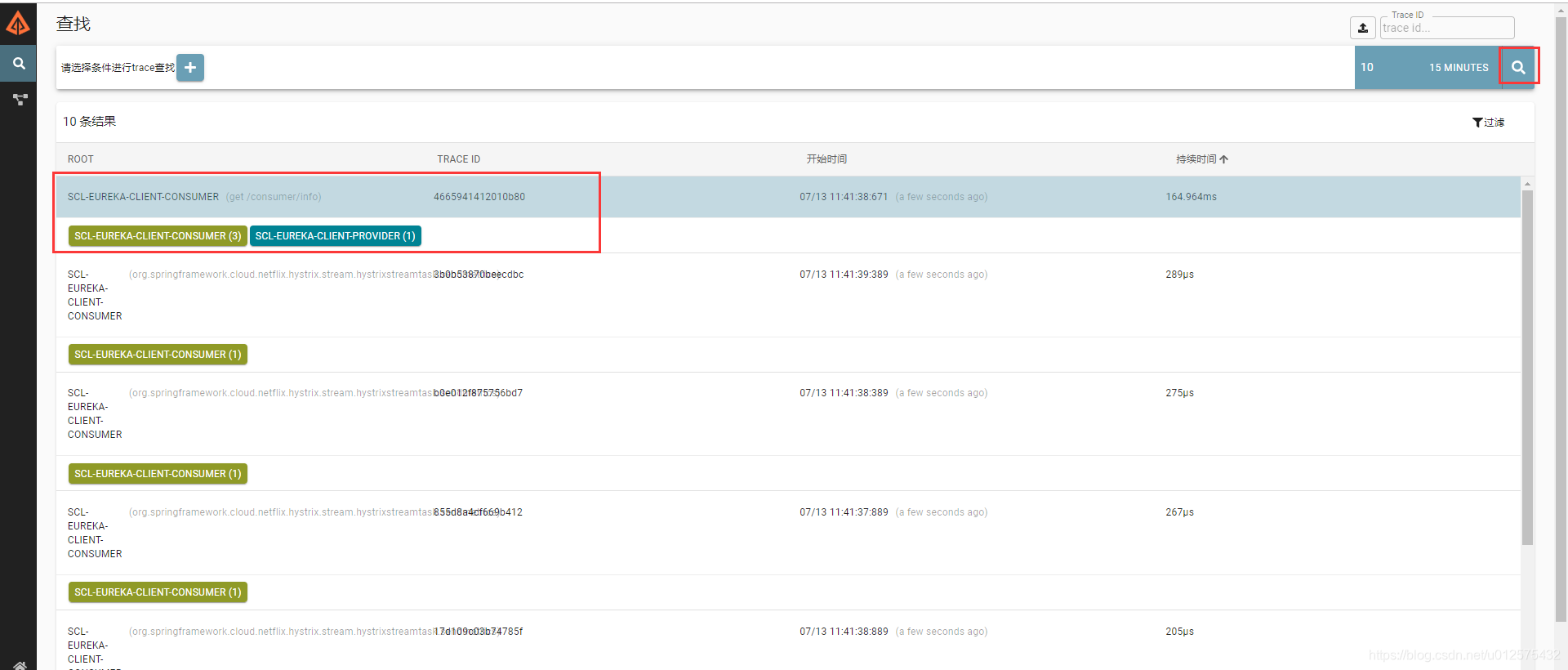
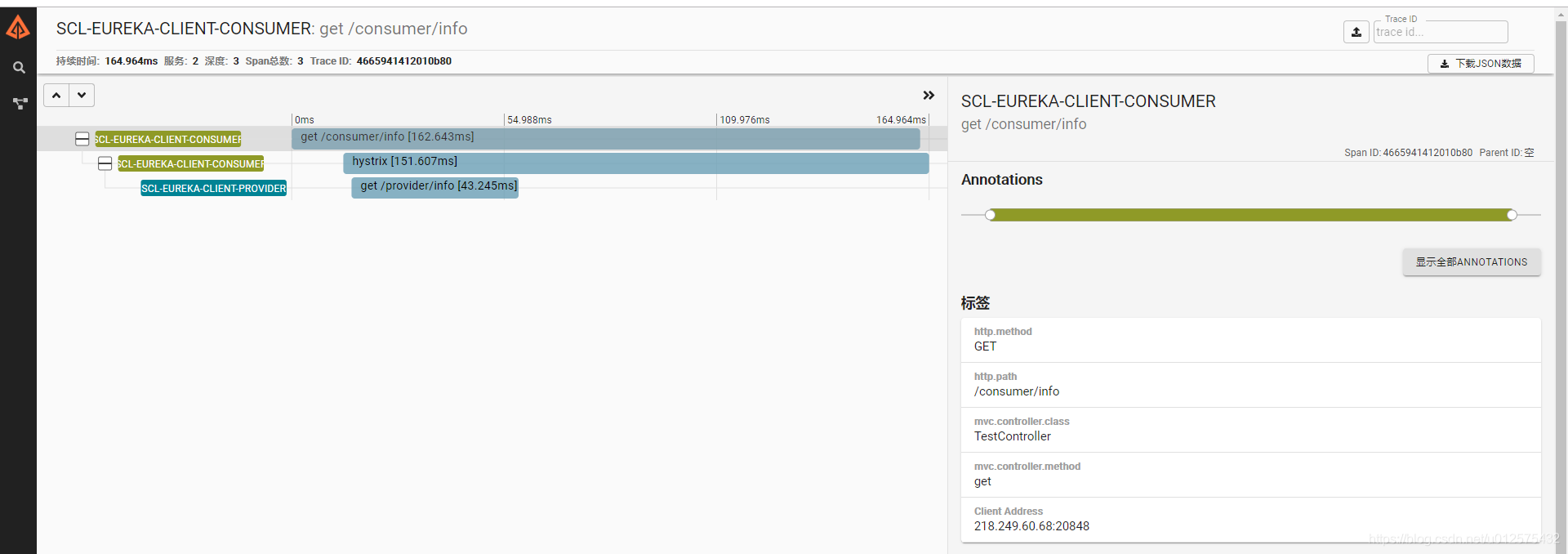
重启两个项目,多次访问http://localhost:8090/consumer/info,产生日志,然后访问http://localhost:9411,可看到请求日志,点击其中某一条即可看见调用过程。
4.2 使用RabbitMQ收集数据
-
使用如下命令启动Zipkin服务端
nohup java -jar zipkin-server-2.21.5-exec.jar --RABBIT_ADDRESSES=127.0.0.1:5672 >> /home/sc/zipkin-server/zipkin.log 2>&1 & -
在scl-eureka-client-consumer和scl-eureka-client-provider中添加如下依赖
<dependency> <groupId>org.springframework.amqp</groupId> <artifactId>spring-rabbit</artifactId> </dependency><dependency> <groupId>org.springframework.amqp</groupId> <artifactId>spring-rabbit</artifactId> </dependency> -
修改application.yml配置文件,删除
spring.zipkin.base-url,添加RabbitMQ相关配置spring: zipkin: sender: type: rabbit sleuth: sampler: probability: 1.0 rabbitmq: host: 127.0.0.1 port: 5672 -
按上一步的测试方法进行测试。依然可以正常显示跟踪日志
4.3 使用Elasticsearch存储跟踪数据
Zipkin默认使用将数据存储在内存中。若Zipkin Server重启或崩溃都会导致数据丢失,不适合生产环境。zipkin Server支持多种后端存储,MySQL、Elasticsearch、Cassandra等。本文使用Elasticsearch存储跟踪数据
-
使用如下命令启动Zipkin服务端
* nohup java -jar zipkin-server-2.21.5-exec.jar --RABBIT_ADDRESSES=127.0.0.1:5672 --STORAGE_TYPE=elasticsearch --ES_HOSTS=http://127.0.0.1:9000 >> /home/sc/zipkin-server/zipkin.log 2>&1 & -
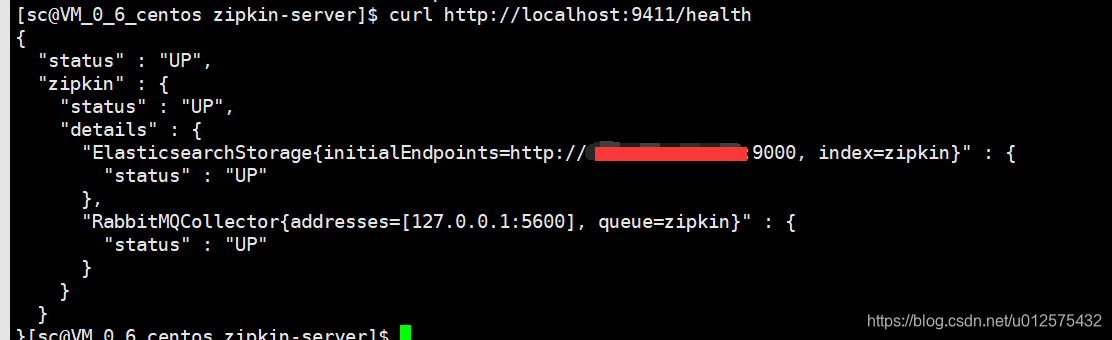
使用
curl http://localhost:9411/health即可查看
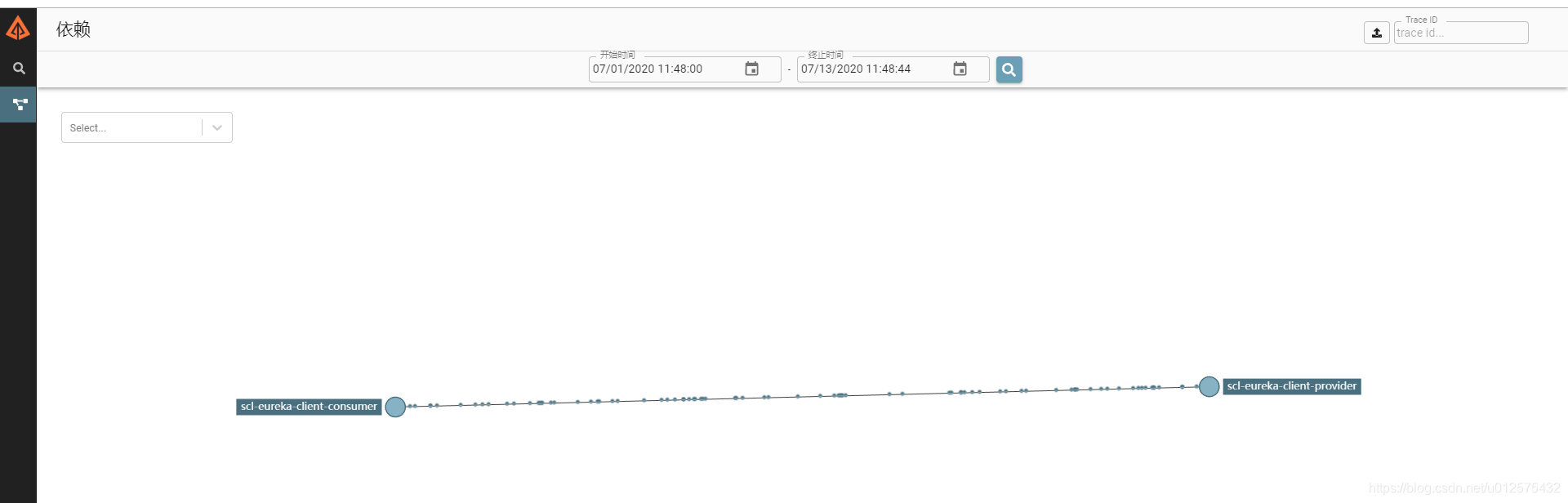
4.4 依赖界面无法显示依赖关系
-
使用如下命令启动zipkin dependencies即可
STORAGE_TYPE=elasticsearch ES_HOSTS=http://127.0.0.1:9000 java -Xms64m -Xmx512m -jar zipkin-dependencies-2.4.2.jar -
该jar包启动后仅允许一次,分析当前依赖关系。若想定时分析,可配置定时任务
-
重新访问http://localhost:9411,点击依赖即可查看