

26. Remove Duplicates from Sorted Array
前言:继几个月前做了50题左右的Leetcode以来,没有再次接触过类似的训练。在学习了数据结构之后,为了增强算法的训练,乘着Leetcode.CN的上线(感觉没了discuss就没了精髓),想系统性的记录一下解题过程和思路,为日后的复习提供便利。
首先,在Leetcode.CN->探索->初级算法->数组中按顺序刷题(顺序看这里,实际还是到英文网站阅读题干与讨论与解法)。需要说明的是,之前刷过的50题全是数组名下的,当时的水品大概为勉强解出medium题,所以对数组相对比较熟悉。
本文记录的是第一题:从排序数组中删除重复项(具体描述见超链接)。题目大概可表述为给定一个有序的数组,删除其中重复的元素并返回修改后的数组长度。题目描述很简单,很符合数组easy题的难度,但是值得注意的是,出题人在示例里加上了一句“不需要理会新的数组长度后面的元素”。
对此题的第一反应(just for the beginner)就是从第二项开始,依次遍历数组的每一项与前面一项作对比,如果比前一项大则保留,继续遍历下一项;如果与前一项相同,则将这一项之后的每一项向前移动一个位置,遍历的指针保持不变(算法一)。刚学到一个词,叫做TSSN(来自浙江大学MOOC《数据结构》陈越老师的会心一击)。用来形容这个算法呢,再合适不过了。根据算法的逻辑不难得出,该算法的时间复杂度为O(N2)。以下是该算法的代码实现:
1 int removeDuplicates(int* nums, int numsSize) { 2 if(!numsSize){ 3 return 0; 4 } 5 for(int i = 1; i < numsSize; ){ 6 if(nums[i] == nums[i-1]){ 7 for(int j = i; j < numsSize; j++){ 8 nums[j] = nums[j+1]; 9 10 } 11 numsSize--; 12 }else{ 13 i++; 14 } 15 } 16 return numsSize; 17 }
从下面的提交记录可以看出,该算法慢于绝大多数的C语言用户(居然还有25%的人更慢。。)。

那么有什么好一点的算法可以提高效率呢?首先分析算法一,导致其速度慢的主要原因是每一次发现重复元素之后的删除过程需要移动在其之后的每一个元素。有一个很好的解决办法是开辟一块空间,在遍历原数组时,遇到不重复的数字将其存在新的数组,遍历完成之后,将新数组copy到原数组即完成相应需求(时间复杂度O(N),空间复杂度O(N))。但是题目要求的是不能使用额外的空间去开辟数组即要求在原地完成(in place)。
根据上述要求对第二个算法进行改进得到最后的结果,其实在题干部分“不需要理会新的数组长度后面的元素”已经给出提示,既然无法开辟新的空间,那就直接把需要的值堆在原来的数组上,因为访问到某值时,其之前的节点都已被访问,只要依次从头开始放置,其有效的长度不可能超过这个值。这个算法与算法一的区别在于,算法一的针对的对象是需要删除的值的节点,而本算法聚焦于需要保留的值。看起来保留需要保留的值的操作会比较复杂,直观上一般会选择直接处理需要删除的节点,所以本题最重要的思想是多角度思考。以下是实现算法三的代码以及提交记录:
1 int removeDuplicates(int* nums, int numsSize) { 2 if(numsSize==0){ 3 return 0; 4 } 5 int k=0; 6 int count=1; 7 for(int i=1;i<numsSize;i++){ 8 if(nums[i] > nums[k]){ 9 k++; 10 nums[k] = nums[i]; 11 count++; 12 } 13 } 14 return count; 15 }
提交记录显示算法的性能得到了极大的改善。
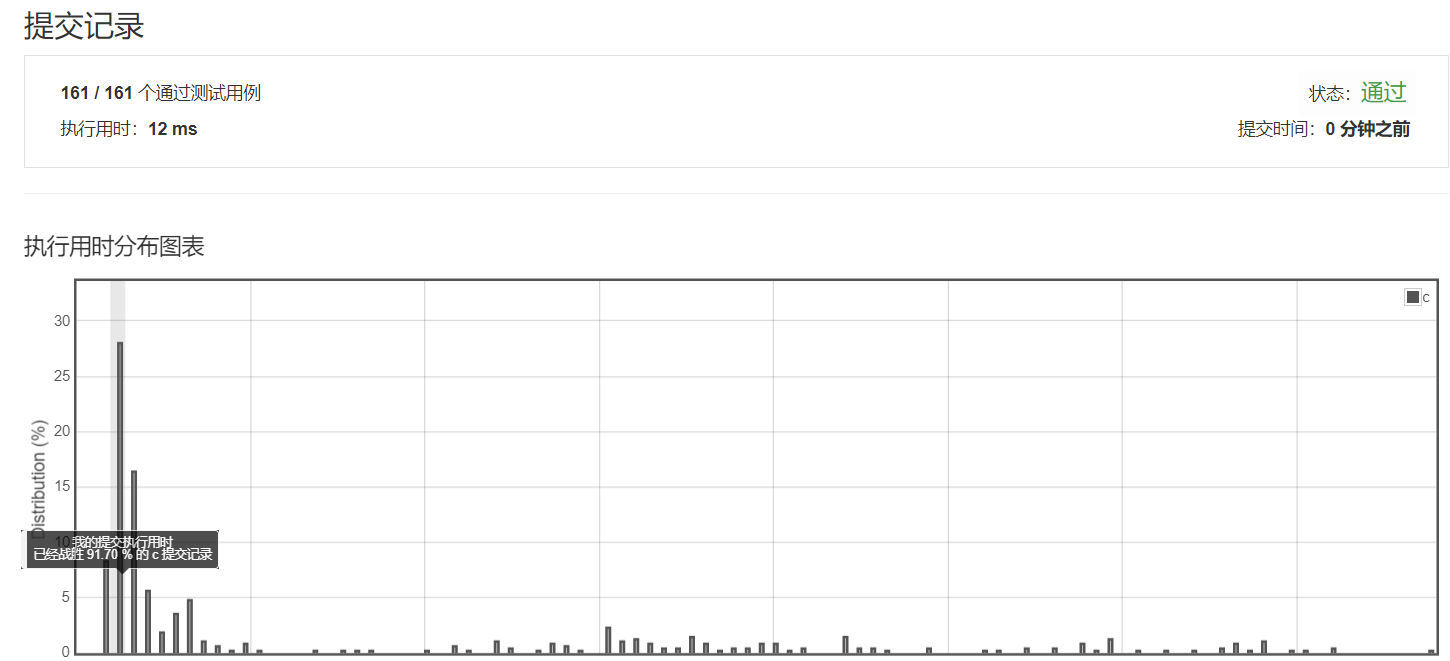
91.7%?是不是还存在更优的算法呢?在算法层面上来讲,有O(N)应该是达到最优了的。至于此处的排名,可能跟服务器的状态有关系(瞎蒙的)。同一个代码我在第一次提交的时候只战胜了43%(再次试了一下居然到了8ms,超越100%,服务器还真调皮╮(╯▽╰)╭)。但是不管怎么波动,其效率与算法一做对比还是有质的提升的(这不是废话, N2与N能一样嘛!)。那不管怎么说,本题就到此为止了,尽情期待下一篇 (●'◡'●)!

