

为什么要学习这个?
分布式技术必会,得益于redis的设计理念,内存数据库,epoll(多路复用)模型,单线程模型除去了锁和上下文切换,提高了性能.单线程保证执行顺序(轮询),在分布式环境下对于数据的一致性和唯一性应该是经常需要考虑到的.
简单入门:
1.数据结构:(特性对比java 集合)
- 字符类型(string)
- 散列类型(hash)
- 列表类型(list 双向链表)
- 集合类型(set)
- 有序集合(zset)
2.功能:
- 可以为每个key设置超时时间;
- 可以通过列表类型来实现分布式队列的操作
- 支持发布订阅的消息模式
3.存储
默认支持16个数据库;可以理解为一个命名空间
跟关系型数据库不一样的点
- redis不支持自定义数据库名词
- 每个数据库不能单独设置授权
- 每个数据库之间并不是完全隔离的。 可以通过flushall命令清空redis实例面的所有数据库中的数据
通过 select dbid 去选择不同的数据库命名空间 。 dbid的取值范围默认是0 -15
4.key 最大521M
===================================================================
实战 使用: 环境 centos7.0 redis4.0.10
安装
1.下载https://redis.io/download
2.解压 tar -zxvf 安装包
3.cd redis-4.0.10
4.执行make
(如果出现 *** [adlist.o] Error 127 ,先安装gcc 命令是:yum install gcc)
(如果出现zmalloc.h:50:31: 致命错误:jemalloc/jemalloc.h:没有那个文件或目录 执行命令:make MALLOC=libc)
4.1 make test (建议预先编译查看有没有问题)
(如果出现错误You need tcl 8.5 or newer in order to run the Redis test ,
参考:https://blog.csdn.net/luyee2010/article/details/18766911 )
4.2 make install [PREFIX=/path]完成安装(指定安装到什么目录)
5(bin).启动 /redis-server ../redis.conf 后台运行
以后台进程的方式启动,修改redis.conf daemonize =yes
6客户端连接 (修改配置 redis.conf bind 0.0.0.0)
./redis-cli -h 127.0.0.1 -p 6379
7.bin 目录下的其他命令
Redis-server 启动服务
Redis-cli 访问到redis的控制台
redis-benchmark 性能测试的工具
redis-check-aof aof文件进行检测的工具
redis-check-dump rdb文件检查工具
redis-sentinel sentinel 服务器配置
==================================================================
通用命令,根据key 做相关增删改查以及设置key的失效时间 (http://www.redis.net.cn/order/3531.html)
各种数据结构的使用
字符类型
赋值和取值
SET key value
setnx (用来做分布式锁)
GET key
递增数字(原子递增,默认为加1)
incr key
incrby key increment 递增指定的整数 eg: incrby shuaige 10
decr key 原子递减
append key value 向指定的key追加字符串
strlen key 获得key对应的value的长度
mget key key.. 同时获得多个key的value
mset key value key value key value …
setnx
列表类型
list, 可以存储一个有序的字符串列表
LPUSH/RPUSH: 从左边或者右边push数据
LPUSH/RPUSH key value value …
llen num 获得列表的长度
lrange key start stop ; 索引可以是负数, -1表示最右边的第一个元素
lrem key count value
lset key index value
LPOP/RPOP : 取数据
应用场景:可以用来做分布式消息队列
散列类型
不支持数据类型的嵌套(valu 是其他数据类型,比如list )
hset key field value
hget key filed
hmset key filed value [filed value …] 一次性设置多个值
hmget key field field … 一次性获得多个值
hgetall key 获得hash的所有信息,包括key和value
hexists key field 判断字段是否存在。 存在返回1. 不存在返回0
hincryby
hsetnx
hdel key field [field …] 删除一个或者多个字段
集合类型
set 跟list 不一样的点。 集合类型不能存在重复的数据。而且是无序的
sadd key member [member ...] 增加数据; 如果value已经存在,则会忽略存在的值,并且返回成功加入的元素的数量
srem key member 删除元素
smembers key 获得所有数据
sdiff key key … 对多个集合执行差集运算
sunion 对多个集合执行并集操作, 同时存在在两个集合里的所有值
有序集合
zadd key score member
zrange key start stop [withscores] 去获得元素。 withscores是可以获得元素的分数
如果两个元素的score是相同的话,那么根据(0<9<A<Z<a<z) 方式从小到大
redis的事务处理
MULTI 去开启事务
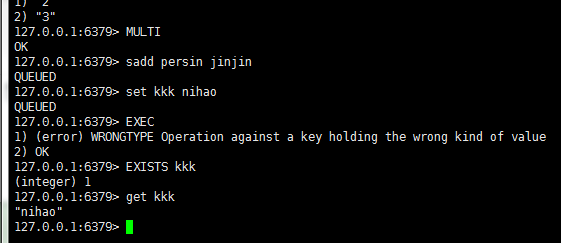
EXEC 去执行事务(注意,虽然开启了事务,但是如果执行的过程有问题的话,不会回滚!) 图中,先hset persin name tom (persin是hash类型,开启事务 用zadd persin jinjian 肯定报错,但是查询 get kkk 依然可以得到值)
过期时间
expire key seconds
ttl 获得key的过期时间
发布订阅
publish channel message
subscribe channel [ …]
数据淘汰策略
redis 内存数据集大小上升到一定大小的时候,就会施行数据淘汰策略。redis 提供 6种数据淘汰策略:
volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰
allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
no-enviction(驱逐):禁止驱逐数据
数据储存方式格式
AOF和RDB
RDB 表示实时存储,AOF只记录执行的语句,启动的时候执行语句
默认RDB
#补充相关linux命令:
检测后台进程是否存在 ps -ef |grep redis
检测6379端口是否在监听 netstat -lntp | grep 6379
# redis 监控工具
redis-stat
