
java IO、NIO
IO
- 流 相当目标与程序之间数据交互的通道
- 输入流 目标到程序
- 输出流 程序到目标
- bit 在计算机中,数据都是以二进制存储的,即每个bit位为0或1。
- 字节 计算机存储单位,一个字节即8个bit位。
- 字符 人们能识别的文字符号等;通过不同的编码,将字节解码成我们能够识别的字符,多数情况下,在64位的系统中(比如win64)1字(word)= 8字节(byte)=64(bit)。
根据输入输出单位大小不同分为字节流和字符流
- 字节流 以8个字节为单位进行读写,以InputStream和OutputStream为基础类,以byte数组作为操作对象。
- 字符流 以字符char(char类型是一个单一的 16 位 Unicode 字符)为单位进行读写,以Reader和Writer为基础类,以char数组作为操作对象。
- Console 此类包含多个方法,可访问与当前 Java 虚拟机关联的基于字符的控制台设备(如果有)。
- File 文件和目录路径名的抽象表示形式。
InputStream 和 OutputStream

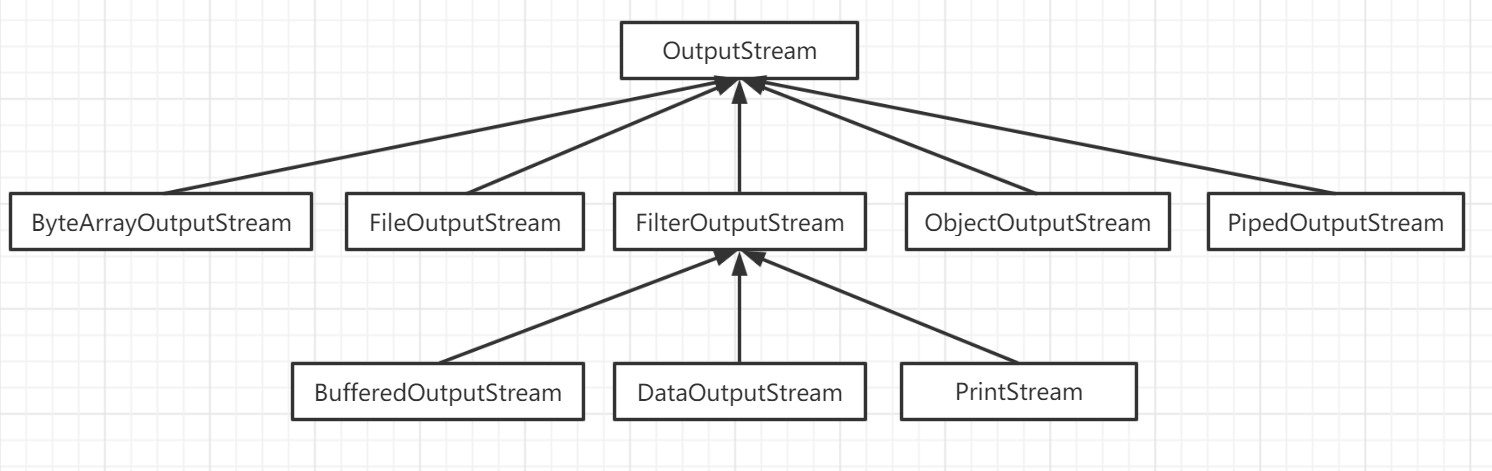
- InputStream 此抽象类是表示字节输入流的所有类的超类。其子类必须实现read()方法
int available() 返回可以从此输入流中无阻塞地读取(或跳过)的字节数的估计值,可以是0,或者在检测到流结束时为0。
void close() 关闭此输入流并释放与该流关联的所有系统资源。
void mark(int readlimit) 标记此输入流中的当前位置。
boolean markSupported() 测试此输入流是否支持 mark和 reset方法。
static InputStream nullInputStream() 返回一个不读取任何字节的新 InputStream 。
abstract int read() 从输入流中读取下一个数据字节。
int read(byte[] b) 从输入流中读取一些字节数并将它们存储到缓冲区数组 b 。
int read(byte[] b, int off, int len) 从输入流 len最多 len字节的数据读入一个字节数组。
byte[] readAllBytes() 从输入流中读取所有剩余字节。
int readNBytes(byte[] b, int off, int len) 从输入流中读取请求的字节数到给定的字节数组中。
byte[] readNBytes(int len) 从输入流中读取指定的字节数。
void reset() 将此流重新定位到上次在此输入流上调用 mark方法时的位置。
long skip(long n) 跳过并丢弃此输入流中的 n字节数据。
long transferTo(OutputStream out) 从该输入流中读取所有字节,并按读取顺序将字节写入给定的输出流。
- OutputStream 此抽象类是表示输出字节流的所有类的超类。 输出流接受输出字节并将它们发送到某个接收器。其子类必须实现write(int var1)方法。
void close() 关闭此输出流并释放与此流关联的所有系统资源。
void flush() 刷新此输出流并强制写出任何缓冲的输出字节。
static OutputStream nullOutputStream() 返回一个新的 OutputStream ,它丢弃所有字节。
void write(byte[] b) 将 b.length字节从指定的字节数组写入此输出流。
void write(byte[] b, int off, int len) 将从偏移量 off开始的指定字节数组中的 len字节写入此输出流。
abstract void write(int b) 将指定的字节写入此输出流。
- ByteArrayInputStream 包含一个内部缓冲区,该缓冲区包含从流中读取的字节。内部计数器跟踪 read 方法要提供的下一个字节。主要针对一个内存中byte数组的操作。对该对象实例的操作是线程安全的,方法上的synchronized关键字避免不同线程同一时刻对同一实例操作,改变实例的pos,pos等字段的值。
- ByteArrayOutputStream 包含一个内部缓冲区数组,此类实现一个输出流,其中数据被写入字节数组。 缓冲区会在数据写入时自动增长。 可以使用toByteArray()和toString()检索数据。对该对象实例的操作是线程安全的,方法上的synchronized关键字避免不同线程同一时刻对同一实例操作,改变实例的buf,count等字段的值。用于将字节写入该输出流。
/***
* ByteArrayInputStream
* 字段:
* buf 由该流的创建者提供的 byte 数组。
* count 比输入流缓冲区中最后一个有效字符的索引大一的索引。
* mark 流中当前的标记位置。
* pos 要从输入流缓冲区中读取的下一个字符的索引。
* 构造方法:
* ByteArrayInputStream(byte[] buf)
* ByteArrayInputStream(byte[] buf, int offset, int length)
* 主要方法:
* available() 返回可从此输入流读取(或跳过)的剩余字节数。count-pos
* mark(int readAheadLimit) 设置流中的当前标记位置。
* reset() 将缓冲区的位置重置为标记位置。 pos->mark
* skip(long n) 从此输入流中跳过 n 个输入字节。pos+n
* close() 关闭 ByteArrayInputStream 无效。
* @throws IOException
*/
@Test
public void ByteArrayInputStreamIO() throws IOException {
//使用utf-8编码转化为字节数组
byte[] e = "hello world".getBytes("utf-8");
byte[] c = "你好 世界".getBytes("utf-8");
ByteArrayInputStream byteArrayInputStreamE = new ByteArrayInputStream(e);
ByteArrayInputStream byteArrayInputStreamC = new ByteArrayInputStream(c);
try {
byte[] bytes = new byte[6];
byteArrayInputStreamE.read(bytes, 0, 4);
//使用utf-8解码得到abcd,解码英文字符串 'hell',英文一个字节一个字符
System.out.println(new String(bytes, "utf-8"));
for (int i = 0; i < byteArrayInputStreamE.available(); i++) {
//读取下一个字节输出
System.out.println(byteArrayInputStreamE.read());
}
//使用utf-8解码得到abcd,解码中文字符串 '你好',中文三个字节一个字符
byteArrayInputStreamC.read(bytes, 0, 6);
System.out.println(new String(bytes, "utf-8"));
for (int i = 0; i < byteArrayInputStreamE.available(); i++) {
//输出每个字节
System.out.println(byteArrayInputStreamC.read());
}
} finally {
byteArrayInputStreamE.close();
byteArrayInputStreamC.close();
}
}
/**
* 方法:
* void reset() 将此 ByteArrayOutputStream的 count字段重置为零,以便丢弃输出流中当前累积的所有输出。
* int size() 返回缓冲区的当前大小。
* byte[] toByteArray() 创建一个新分配的字节数组。
* String toString() 使用平台的默认字符集将缓冲区的内容转换为字符串解码字节。
* String toString(String charsetName) 通过使用名为charset的字节解码将缓冲区的内容转换为字符串。
* String toString(Charset charset) 通过使用指定的charset解码字节,将缓冲区的内容转换为字符串。
* void write(byte[] b, int off, int len) 从偏移量为 off的指定字节数组写入 len字节到此 ByteArrayOutputStream 。
* void write(int b) 将指定的字节写入此 ByteArrayOutputStream 。
* void writeBytes(byte[] b) 将指定字节数组的完整内容写入此 ByteArrayOutputStream 。
* void writeTo(OutputStream out) 将此 ByteArrayOutputStream的完整内容写入指定的输出流参数,就像通过使用 out.write(buf, 0, count)调用输出流的write方法 out.write(buf, 0, count) 。
* <p>
* 构造方法:
* ByteArrayOutputStream() 创建一个新的 ByteArrayOutputStream 。
* ByteArrayOutputStream(int size) 创建一个新的 ByteArrayOutputStream ,具有指定大小的缓冲区容量(以字节为单位)。
*
* @throws IOException
*/
@Test
public void ByteArrayOutputStreamIO() throws IOException {
//使用utf-8编码转化为字节数组
byte[] e = "hello world".getBytes("utf-8");
try (
ByteArrayOutputStream baos = new ByteArrayOutputStream();
) {
//将上述字节数组写入输出流
baos.write(e, 0, e.length);
byte[] bytes = baos.toByteArray();
//新建一个ByteArrayInputStream输入流以输出流中的字节数组为参数
try (ByteArrayInputStream bais = new ByteArrayInputStream(bytes);
) {
//hello world
System.out.println(new String(bais.readAllBytes(),"utf-8"));
}
} catch (Exception ex) {
ex.printStackTrace();
}
}
- FileInputStream 从文件系统中的某个文件中获得输入字节。哪些文件可用取决于主机环境。用于读取诸如图像数据之类的原始字节流。要读取字符流,请考虑使用 FileReader。FileInputStream除了是针对文件的操作外,方法与ByteArrayInputStream类似,此外还能获得FileChannel(NIO包下的类)。
- FileOutputStream 文件输出流是用于将数据写入File或FileDescriptor的输出流,用于写入诸如图像数据的原始字节流。 要编写字符流,请考虑使用FileWriter 。 文件是否可用或是否可以创建取决于底层平台。 特别是某些平台允许一次仅打开一个文件以供写入FileOutputStream (或其他文件写入对象)。 在这种情况下,如果涉及的文件已经打开,则此类中的构造函数将失败。
/***
* FileInputStream
*构造函数:
* FileInputStream fis = new FileInputStream("p1.jpg") 文件位于根路径下
* FileInputStream fis = new FileInputStream("C:\\Users\\tyjin\\IdeaProjects\\IOandNIO\\p1.jpg") 文件绝对路径
* FileInputStream fis = new FileInputStream(FileDescriptor.in) FileDescriptor文件描述符类的实例充当底层机器特定结构的不透明句柄,表示打开文件,打开套接字或其他字节源或接收器。 文件描述符的主要实际用途是创建FileInputStream或FileOutputStream来包含它。
* 我们无法创建一个有效的该对象,以及使用它的方法,通常只能使用其内部三个常量:
* static FileDescriptor.err 标准错误流的句柄。
* static FileDescriptor.in 标准输入流的句柄。键盘输入
* static FileDescriptor.out 标准输出流的句柄。输出到屏幕
*
* 特有方法:
* FileChannel getChannel() 返回与此文件输出流关联的唯一FileChannel对象。
* FileDescriptor getFD() 返回与此流关联的文件描述符FileDescriptor。
*
* FileOutputStream
* 构造函数:
* FileOutputStream(File file) 输出流内容写入file文件
* FileOutputStream(FileDescriptor fdObj) 创建要写入指定文件描述符的文件输出流,该文件描述符表示与文件系统中实际文件的现有连接。
* FileOutputStream(File file, boolean append) 创建文件输出流以写入由指定的 File对象表示的文件,append=true则以追加的方式,而不覆盖。
* FileOutputStream(String name) 创建name文件,件位于根路径下
* FileOutputStream(String name, boolean append) 创建文件输出流以写入具有指定名称的文件。
*
* 特有方法:
* FileChannel getChannel() 返回与此文件输出流关联的唯一FileChannel对象。
* FileDescriptor getFD() 返回与此流关联的文件描述符FileDescriptor。
* @throws IOException
*/
@Test
public void FileStreamIO() throws IOException {
//使用try-with-resources语法糖结构
try (FileInputStream fis = new FileInputStream("C:\\Users\\tyjin\\Pictures\\视频项目\\p1.jpg");
FileOutputStream fos = new FileOutputStream(new File("C:\\Users\\tyjin\\Pictures\\视频项目\\p2.jpg"))){
byte[] pic;
if (fis.available() > 0) {
//读取图片以字节数组保存
pic = fis.readAllBytes();
for (byte b :
pic) {
//内容写入到p2.jpg
fos.write(b);
}
}
System.out.println();
//获得FileChannel,该类后面再说
FileChannel fc=fis.getChannel();
} catch (Exception e){
e.printStackTrace();
}
}
//使用Junit 无法执行,只能在main方法中执行。
public static void main(String[] args) throws IOException {
//使用try-with-resources语法糖结构
try (FileInputStream fis = new FileInputStream(FileDescriptor.in);){
System.out.println("输入:");
int a=fis.read();//标准输入a
System.out.println(a);
} catch (Exception e){
e.printStackTrace();
}
}
-
FilterInputStream 类FilterInputStream本身只是简单地重写的所有方法InputStream与传递给所包含输入流的所有请求的版本。 FilterInputStream子类可以进一步覆盖这些方法中的一些,并且还可以提供另外的方法和字段。即该类只是对闯入的输入流的方法今昔重写。该类无法直接使用,通常使用其子类。
-
FilterOutputStream 此类是过滤输出流的所有类的超类。 类FilterOutputStream本身只是简单地重写的所有方法OutputStream与传递到底层输出流的所有请求的版本。 FilterOutputStream子类可以进一步覆盖这些方法中的一些以及提供附加的方法和字段。
-
BufferedInputStream 向另一个输入流添加功能 - 即缓冲输入并支持mark和reset方法的功能。创建默认最小8192的内部缓冲区buf,通过fill()将read方法的读取的内容的输入流中读取到BufferedInputStream缓冲区字节数组buf中,BufferedInputStream.read方法再从缓冲数组中读取。对该对象实例的操作是线程安全的,方法上的synchronized关键字避免不同线程同一时刻对同一实例操作,改变实例的pos,marklimit等字段的值。
-
BufferedOutputStream 该类实现缓冲输出流。 通过设置这样的输出流,应用程序可以将字节写入基础输出流,而不必为写入的每个字节调用底层系统。该输出流的write方法将数据写入到缓冲区,调用flush()方法后写入目标输出流(构造方法参数)。
/**
* BufferedInputStream
* 字段:
* byte[] buf 存储数据的内部缓冲区数组。
* count 索引1大于缓冲区中最后一个有效字节的索引。
* marklimit 在后续调用 reset方法失败之前调用 mark方法后允许的最大 mark读。
* markpos 调用最后一个 mark方法时 pos字段的值。
* pos 缓冲区中的当前位置。
*
* 构造方法:
* BufferedInputStream(InputStream in) 创建一个 BufferedInputStream并保存其参数,即输入流 in ,供以后使用。
* BufferedInputStream(InputStream in, int size) 创建具有指定缓冲区大小的 BufferedInputStream ,并保存其参数(输入流 in )供以后使用。
*
* BufferedOutputStream
* 字段:
* buf[] 存储数据的内部缓冲区。
* count 缓冲区中的有效字节数。
*
* 特有方法:
* void flush() 刷新此缓冲的输出流,将内容同步到目标输出流。
* void write(byte[] b, int off, int len) 将从偏移量 off开始的指定字节数组中的 len字节写入此缓冲输出流。
* void write(int b) 将指定的字节写入此缓冲的输出流。
*
* @throws IOException
*/
@Test
public void BufferedStreamIO() throws IOException {
byte[] bs = null;
try (ByteArrayOutputStream baos = new ByteArrayOutputStream();
BufferedOutputStream bos = new BufferedOutputStream(baos);) {
byte[] b0 = "hello world".getBytes("utf-8");
for (byte b :
b0) {
bos.write(b);
}
bos.flush();
//获取写入的字节数组
bs = baos.toByteArray();
} catch (Exception ex) {
ex.printStackTrace();
}
try (
//以输出流中的字节数组作为参数
ByteArrayInputStream bais = new ByteArrayInputStream(bs);
BufferedInputStream bis = new BufferedInputStream(bais);) {
byte[] bytes = new byte[6];
bis.read(bytes, 0, 4);
//使用utf-8解码得到abcd,解码英文字符串 'hell',英文一个字节一个字符
System.out.println(new String(bytes, "utf-8"));
} catch (Exception ex) {
ex.printStackTrace();
}
}
- DataInputStream 数据输入流允许应用程序以与机器无关的方式从底层输入流中读取原始Java数据类型。 应用程序使用数据输出流来写入稍后可由数据输入流读取的数据。DataInputStream对于多线程访问不一定安全。除了提供除read(byte[] b)、read(byte[] b, int off, int len)读取字节数组的方法外,还提供了其它将流内容读取为基本类型的方法,原理是根据基本数据类型的字节数从字节数组中读取出多个字节,然后进行位运算后类型转换为相应的基本类型;
- DataOutputStream 数据输出流允许应用程序以可移植的方式将原始Java数据类型写入输出流。 然后,应用程序可以使用数据输入流来重新读取数据。提供write(byte[] b, int off, int len)、write(int b)基本字节写入方法外,还提供了writeXXX(obj)来写入基本数据类型,保证基本数据类型的字节数,DataInputStream.readXXX()来读取基本数据类型。
/**
* boolean 1 bit,不到一个字节
* byte 8 bit,1字节
* short 16 bit,2字节
* char 16 bit,2字节
* int 32 bit,4字节
* float 32 bit,4字节
* long 64 bit,8字节
* double 64 bit,8字节
*/
public final char readChar() throws IOException {
//char类型为两个字节
int ch1 = this.in.read();
int ch2 = this.in.read();
if ((ch1 | ch2) < 0) {
throw new EOFException();
} else {
//进行位运算 ch1 << 8 左移8位,相当于解析DataOutputStream.writeChar()写入的内容
return (char) ((ch1 << 8) + (ch2 << 0));
}
}
/**
* DataInputStream
* 直接定义的字符串转字节数组无法使用 readXXX()方法,只有DataOutputStream.writexxx()写入的才可以使用,
* 原因是在DataOutputStream写入时规定了各种基本类型的字节数,而String.getBytes()获得的字节数组根据编码的不同字每种字符节数也不同
* 而DataInputStream.readxxx()(通过<<位运算符)是DataOutputStream.writexxx()的逆过程,只能解析DataOutputStream.writexxx()写入的字节数组(通过>>>位运算符)
* 而通过直接定义字节数组的方式则不会对字节进行位运算对高位低位补0补1以满足不同数据类型的字节数。
* <<表示左移移,不分正负数,低位补0;
* >>表示右移,如果该数为正,则高位补0,若为负数,则高位补1;
* >>>表示无符号右移,也叫逻辑右移,即若该数为正,则高位补0,而若该数为负数,则右移后高位同样补0
* 特有方法:
* readXXX() 读取固定个数输入字节并返回 XXX类型值。
* readUTF() 读取使用 modified UTF-8格式编码的字符串。
*
* DataOutputStream
* writeXXX(Object v) 将 XXX类型数据写入基础输出流,为四个字节,高字节优先。
*writeUTF(String str) 使用 modified UTF-8编码以与机器无关的方式将字符串写入基础输出流。
* @throws IOException
*/
@Test
public void DataStreamIO() throws IOException {
/*test 1*/
byte[] e = new byte[]{(byte) '我'};
//模拟DataOutputStream.writexxx(),将字符转化为两个字节,可以使用readxxx()方法
// byte[] e = new byte[]{(byte) ('我'>>>8& 255),(byte) ('我'>>>0& 255)};
System.out.println("test 1:");
try (ByteArrayInputStream bais = new ByteArrayInputStream(e);
DataInputStream bis = new DataInputStream(bais);) {
while (bais.available() > 0) {
//打印每个字节观察和DataOutputStream写入的字节数组的区别-> 17
System.out.println(bais.read());
}
//重置pos
bis.reset();
//异常不满足两个字节
System.out.println(bis.readChar());
} catch (Exception ex) {
ex.printStackTrace();
}
/*test 2*/
byte[] e1 = "我".getBytes();
System.out.println("test 2:");
try (ByteArrayInputStream bais = new ByteArrayInputStream(e1);
DataInputStream bis = new DataInputStream(bais);) {
while (bais.available() > 0) {
//打印每个字节观察和DataOutputStream写入的字节数组的区别-> 230 136 145
System.out.println(bais.read());
}
//重置pos
bis.reset();
//乱码
//System.out.println(bis.readChar());
} catch (Exception ex) {
ex.printStackTrace();
}
/*test 3*/
System.out.println("test 3:");
try (
ByteArrayOutputStream baos = new ByteArrayOutputStream();
DataOutputStream bos = new DataOutputStream(baos);
) {
bos.writeChar('我');
try (ByteArrayInputStream bais = new ByteArrayInputStream(baos.toByteArray());
DataInputStream bis = new DataInputStream(bais);) {
while (bais.available() > 0) {
//打印每个字节观察和自定义的字符串得到的字节数组的区别 -> 98 17
System.out.println(bais.read());
}
//重置pos
bis.reset();
// 我
System.out.println(bis.readChar());
}
} catch (Exception ex) {
ex.printStackTrace();
}
}
-
LineNumberInputStream 行是以回车符( '\r' )结尾的字节序列,换行符( '\n' )或回车符后面紧跟换行符。 在所有三种情况下,行终止字符都作为单个换行符返回。
行号从0开始,当read返回换行符时,行号增加1 。(已过时),该类只是提供了额外的setLineNumber()、getLineNumber(); -
PushbackInputStream 向目标输入流添加通过将推回的字节存储在内部缓冲区中来“推回”或“未读”字节的能力。这在一个代码片段方便读取由特定字节值分隔的无限数量的数据字节的情况下很有用。 在读取终止字节之后,代码片段可以“解读”它,以便输入流上的下一个读取操作将重新读取被推回的字节。 例如,表示构成标识符的字符的字节可以由表示操作符的字节终止; 一个方法,其工作是只读取一个标识符,可以读取,直到它看到操作员,然后推回操作员重新读取。读取字节数组时将推回缓冲区的字节数组和目标输入流类的下一个读取位置的字节数组一起读取出。
/**
* 字段:
* byte[] buf 推回缓冲区。
* int pos 回推缓冲区中的位置,将从中读取下一个字节。该退回缓冲区从后往前填充,即pos初始位置为buf数组的大小(不指定为1),每次退回执行buf[--pos]=(byte)value
* 特有方法:
* void unread(byte[] b) 通过将字节数组复制到回送缓冲区的前面来推回字节数组,缓冲区大小必须>=b.length。
* void unread(byte[] b, int off, int len) 通过将其复制到回送缓冲区的前面来推回一部分字节数组,缓冲区大小必须>=len。
* void unread(int b) 通过将字节复制到回送缓冲区的前面来推回一个字节。
*
* @throws IOException
*/
@Test
public void PushbackInputStreamIO() throws IOException {
byte[] e = "1234:123412341234".getBytes("utf-8");
try (ByteArrayInputStream bais = new ByteArrayInputStream(e);
//退回一个字节
PushbackInputStream pis = new PushbackInputStream(bais);
//退回多个字节需指定缓冲区大小
// PushbackInputStream pis = new PushbackInputStream(bais,4);
) {
byte[] bytes = new byte[20];
/* while (pis.available() > 0) {
pis.read(bytes, 0, 4);
//如果包含':',则将本次读取4个字节回退到缓冲区
if (new String(bytes, "utf-8").contains(":")) {
// ->:123
System.out.println(new String(bytes, "utf-8"));
pis.unread(bytes, 0, 4);
//跳出循环
break;
}
// ->1234
System.out.println(new String(bytes, "utf-8"));
}*/
for(int i=0;i<pis.available()&&i<bytes.length;i++){
byte b=(byte)pis.read();
//如果该字节时':',则退回到缓冲区,下次再次读取出来
if(Objects.equals((byte)':',b)){
pis.unread(b);
break;
}else {
bytes[i]=b;
}
}
// ->1234
System.out.println(new String(bytes,"utf-8"));
byte[] bytes1 = new byte[20];
//:123412341234
bytes1 = pis.readAllBytes();
System.out.println(new String(bytes1, "utf-8"));
} catch (Exception ex) {
ex.printStackTrace();
}
}
- PrintStream 向另一个输出流添加功能,即能够方便地打印各种数据值的表示。 还提供了另外两个功能。 与其他输出流不同, PrintStream永远不会抛出IOException ; 相反,异常情况仅设置可通过checkError方法测试的内部标志。 可选地,可以创建PrintStream以便自动刷新; 这意味着flush字节数组写入方法后自动调用,所述一个println方法被调用时,或者一个新行字符或字节( '\n' )被写入。PrintStream打印的所有字符都使用给定的编码或字符集转换为字节,如果未指定,则使用平台的默认字符编码。 PrintWriter类应该在需要写入字符而不是字节的情况下使用。此类始终使用charset的默认替换字符串替换格式错误且不可映射的字符序列。 当需要更多地控制编码过程时,应使用CharsetEncoder类。
/**
* PrintStream
* 特有方法:
* append(char c) 将指定的字符追加到此输出流。
* PrintStream append(CharSequence csq) 将指定的字符序列追加到此输出流。
* PrintStream append(CharSequence csq, int start, int end) 将指定字符序列的子序列追加到此输出流。
* PrintStream format(String format, Object... args) 使用指定的格式字符串和参数将格式化字符串写入此输出流。
* PrintStream format(Locale l, String format, Object... args) 使用指定的格式字符串和参数将格式化字符串写入此输出流。
* print(xxx v) 将xxx类型的数据打印到原输入流的末尾
* println(xxx x) 同print(xxx v),再追加一个换行符
* PrintStream printf(String format, Object... args) 使用指定的格式字符串和参数将格式化字符串写入此输出流的便捷方法。
* PrintStream printf(Locale l, String format, Object... args) 使用指定的格式字符串和参数将格式化字符串写入此输出流的便捷方法。
* 构造方法:
* PrintStream(File file) 使用指定的文件创建没有自动行刷新的新打印流。
* PrintStream(File file, String csn) 使用指定的文件和字符集创建一个没有自动行刷新的新打印流。
* PrintStream(File file, Charset charset) 使用指定的文件和字符集创建一个没有自动行刷新的新打印流。
* PrintStream(OutputStream out) 创建新的打印流。
* PrintStream(OutputStream out, boolean autoFlush) 创建新的打印流。
* PrintStream(OutputStream out, boolean autoFlush, String encoding) 创建新的打印流。
* PrintStream(OutputStream out, boolean autoFlush, Charset charset) 创建一个新的打印流,具有指定的OutputStream,自动行刷新和字符集。
* PrintStream(String fileName) 使用指定的文件名创建没有自动行刷新的新打印流。
* PrintStream(String fileName, String csn) 使用指定的文件名和字符集创建一个没有自动行刷新的新打印流。
* PrintStream(String fileName, Charset charset) 使用指定的文件名和字符集创建一个没有自动行刷新的新打印流。
*/
@Test
public void PrintStreamIO() {
try (
ByteArrayOutputStream baos = new ByteArrayOutputStream();
//123\n,begin添加到目标输出流的开头
PrintStream ps = new PrintStream(baos,true).format("----%s\n", "123").append("begin")) {
ps.println(':');
byte[] bytes = "hello world".getBytes("utf-8");
//写入内容
ps.write(bytes);
ps.print('-');
//追加123后换行
ps.println("123");
//使用格式化打印方式,"f------>%d"会构建一个Formatter格式化器
ps.printf("f------>%d\n", 1);
ps.print(new String(":end"));
try (ByteArrayInputStream bais = new ByteArrayInputStream(baos.toByteArray());) {
/*
----123
begin:
hello world-123
f------>1
:end
*/
System.out.println(new String(bais.readAllBytes(), "utf-8"));
}
} catch (IOException e) {
e.printStackTrace();
}
}
- ObjectOutputStream 将Java对象的原始数据类型和图形写入OutputStream。 可以使用ObjectInputStream读取(重构)对象。 可以通过使用流的文件来完成对象的持久存储。 如果流是网络套接字流,则可以在另一个主机或另一个进程中重新构建对象。只有支持java.io.Serializable接口的对象才能写入流。 每个可序列化对象的类都被编码,包括类的类名和签名,对象的字段和数组的值,以及从初始对象引用的任何其他对象的闭包。除writeObject(obj)外还有各种基本类型的写入,如writeInt(int v)等,
- ObjectInputStream 对先前使用ObjectOutputStream编写的原始数据和对象进行反序列化。方法readObject用于从流中读取对象。 应该使用Java的安全转换来获得所需的类型。 在Java中,字符串和数组是对象,在序列化期间被视为对象。 读取时,需要将它们转换为预期的类型。
/**
* ObjectOutputStream
* 特有方法:
* readXXX() XXX表示某一基本类型
* readObject() 读取一个对象
* readUnshared() 读取非共享对象
* ObjectOutputStream
* 特有方法:
* 只有支持java.io.Serializable接口的对象才能写入流
* writeXXX() XXX表示某一基本类型
* writeObject() 读取一个对象
* writeUnshared(Object obj) 将“非共享”对象写入ObjectOutputStream。 *
* 与Data输入输出流类似,支持Object类型,支持序列化与反序列化,内部使用DataOutputStream、DataInputStream实现
*/
@Test
public void ObjectStreamIO(){
try(ByteArrayOutputStream baos = new ByteArrayOutputStream();
ObjectOutputStream oos= new ObjectOutputStream(baos)){
//写入数据
oos.writeInt(12345);
oos.writeObject("Today");
oos.writeObject(new Date());
User user=new User("123","xiaoming");
oos.writeObject(user);
try (ByteArrayInputStream bais = new ByteArrayInputStream(baos.toByteArray());
ObjectInputStream ois=new ObjectInputStream(bais)) {
//读取数据
System.out.println(ois.readInt());
System.out.println((String)ois.readObject());
System.out.println((Date)ois.readObject());
System.out.println((User)ois.readObject());
}
}catch (IOException | ClassNotFoundException ex){
ex.printStackTrace();
}
}
- PipedInputStream 管道输入流应连接到管道输出流; 然后,管道输入流提供写入管道输出流的任何数据字节。 通常,一个线程从PipedInputStream对象读取数据,并且某些其他线程将数据写入相应的PipedOutputStream 。 建议不要尝试使用单个线程中的两个对象,因为它可能使线程死锁。 管道输入流包含缓冲区,在一定限度内将读操作与写操作解耦。 如果为连接的管道输出流提供数据字节的线程不再存在, 则称管道为broken 。
- PipedOutputStream 管道输出流可以连接到管道输入流以创建通信管道。 管道输出流是管道的发送端。 通常,数据由一个线程写入PipedOutputStream对象,并且由其他线程从连接的PipedInputStream读取数据。 建议不要尝试使用单个线程中的两个对象,因为它可能使线程死锁。 如果从连接的管道输入流读取数据字节的线程不再存在, 则称该管道为broken 。
PipedOutputStream的写入方法直接调用PipedOutputStream的receive()方法将数据写入到PipedOutputStream输入流中,相当于PipedOutputStream写入直接操作PipedOutputStream的缓冲区。
/**
* PipedInputStream
* 字段:
* protected byte[] buffer 传入数据的循环缓冲区。
* protected int in 循环缓冲区中位置的索引,当从连接的管道输出流接收时,将存储下一个数据字节。
* protected int out 循环缓冲区中位置的索引,此管道输入流将读取下一个数据字节。
* protected static int PIPE_SIZE 管道的循环输入缓冲区的默认大小。
* <p>
* 特有方法:
* int available()
* 返回可以在不阻塞的情况下从此输入流中读取的字节数。
* void connect(PipedOutputStream src)
* 使此管道输入流连接到管道输出流 src 。
* <p>
* PipedOutputStream
* 字段:
* PipedInputStream sink 连接输入流
* void connect(PipedInputStream snk)
* 将此管道输出流连接到接收器。
* void flush()
* 刷新此输出流并强制写出任何缓冲的输出字节。
* <p>
* 操作执行后必须关闭流
*/
@Test
public void PipedStreamIO() {
//定义输入流线程任务
class PipedInputStreamThread implements Runnable {
private PipedInputStream pis;
public PipedInputStreamThread() {
this.pis = new PipedInputStream();
}
public PipedInputStream getPipedInputStream() {
return this.pis;
}
@Override
public void run() {
try {
//不能使用该方法,若是该线程先于输出流线程执行,则会不满足条件往后执行,关闭输入流
//if(pis.available()>0)
System.out.println(new String(pis.readAllBytes(), "utf-8"));
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
pis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
//定义输入流线程任务
class PipedOutputStreamThread implements Runnable {
private PipedOutputStream pos;
public PipedOutputStreamThread() {
this.pos = new PipedOutputStream();
}
public PipedOutputStream getPipedOutputStream() {
return this.pos;
}
@Override
public void run() {
try {
byte[] bytes = "hello world".getBytes("utf-8");
pos.write(bytes);
//刷新缓冲区唤醒输入流线程
pos.flush();
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
pos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
try {
//创建任务
PipedOutputStreamThread outer = new PipedOutputStreamThread();
PipedInputStreamThread inner = new PipedInputStreamThread();
PipedOutputStream pos = outer.getPipedOutputStream();
PipedInputStream pis = inner.getPipedInputStream();
//连接管道
pos.connect(pis);
//创建线程
Thread putter = new Thread(outer);
Thread getter = new Thread(inner);
putter.start();
getter.start();
} catch (IOException ex) {
ex.printStackTrace();
}
}
- SequenceInputStream 表示其他输入流的逻辑串联。 它从一个有序的输入流集合开始,从第一个读取到文件结束,然后从第二个读取,依此类推,直到最后一个包含的输入流到达文件末尾。
用来读取多个流的组合,两个流使用SequenceInputStream(InputStream s1, InputStream s2),两个以上使用SequenceInputStream(Enumeration<? extends InputStream> e),Enumeration(枚举)接口的作用和Iterator类似,只提供了遍历Vector和HashTable类型集合元素的功能,不支持元素的移除操作。
/**
* 该输入流仅提供
* available()、close()、read()、read(byte[] b, int off, int len)方法。
* @throws IOException
*/
@Test
public void SequenceInputStreamIO() throws IOException{
//创建三个字节输入流
byte[] b1="hello".getBytes("utf-8");
byte[] b2=" java".getBytes("utf-8");
byte[] b3=" world".getBytes("utf-8");
try(ByteArrayInputStream bais1=new ByteArrayInputStream(b1);
ByteArrayInputStream bais2=new ByteArrayInputStream(b2);
ByteArrayInputStream bais3=new ByteArrayInputStream(b3);
){
//创建一个动态数组,elements()可返回Enumeration对象
Vector<InputStream> v = new Vector(3);
v.add(bais1);
v.add(bais2);
v.add(bais3);
try( SequenceInputStream sis=new SequenceInputStream(v.elements());){
byte[] bytes = sis.readAllBytes();
//hello java world
System.out.println(new String(bytes,"utf-8"));
}
}catch (IOException ex){
ex.printStackTrace();
}
}
- StringBufferInputStream 此类允许应用程序创建一个输入流,其中读取的字节由字符串的内容提供。 应用程序还可以使用ByteArrayInputStream从字节数组中读取字节。
此类仅使用字符串中每个字符的低八位(即一个字节(8位)表示的字符能正确写入和读出,)。(已过时),使用String对象作为构造参数,内部使用一个String字段接收,
/**构造方法:
* StringBufferInputStream(String s) 创建字符串输入流以从指定的字符串中读取数据。
*
* 方法:
* int available() 返回可以在不阻塞的情况下从输入流中读取的字节数。
* int read() 从此输入流中读取下一个数据字节。
* int read(byte[] b, int off, int len) 从此输入流 len最多 len字节的数据读入一个字节数组。
* void reset() 重置输入流以开始从此输入流的底层缓冲区的第一个字符读取。
* long skip(long n) 从此输入流中跳过 n字节的输入。
* @throws IOException
*/
@Test
public void StringBufferInputStreamIO() throws IOException {
try ( //“你好 世界”不能正确写入和读出
StringBufferInputStream sis = new StringBufferInputStream("hello world");) {
byte[] bytes = sis.readAllBytes();
//hello world
System.out.println(new String(bytes, "utf-8"));
}
}
Reader和Writer
Writer、Reader与OutputStream、InputStream类似,不过其操作的对象是字符(即char类型)。


- Writer 用于写入字符流的抽象类。 子类必须实现的唯一方法是write(char [],int,int),flush()和close()。 但是,大多数子类将覆盖此处定义的一些方法,以提供更高的效率,附加功能或两者兼而有之。
Writer append(char c) 将指定的字符追加到此writer。
Writer append(CharSequence csq) 将指定的字符序列追加到此writer。
Writer append(CharSequence csq, int start, int end) 将指定字符序列的子序列追加到此writer。
abstract void close() 关闭流,先冲洗它。
abstract void flush() 刷新流。
static Writer nullWriter() 返回一个新的 Writer ,它丢弃所有字符。
void write(char[] cbuf) 写一个字符数组。
abstract void write(char[] cbuf, int off, int len) 写一个字符数组的一部分。
void write(int c) 写一个字符。
void write(String str) 写一个字符串。
void write(String str, int off, int len) 写一个字符串的一部分。
- Reader 用于读取字符流的抽象类。 子类必须实现的唯一方法是read(char [],int,int)和close()。 但是,大多数子类将覆盖此处定义的一些方法,以提供更高的效率,附加功能或两者兼而有之。
abstract void close() 关闭流并释放与其关联的所有系统资源。
void mark(int readAheadLimit) 标记流中的当前位置。
boolean markSupported() 判断此流是否支持mark()操作。
static Reader nullReader() 返回不读取任何字符的新 Reader 。
int read() 读一个字符。
int read(char[] cbuf) 将字符读入数组。
abstract int read(char[] cbuf, int off, int len) 将字符读入数组的一部分。
int read(CharBuffer target) 尝试将字符读入指定的字符缓冲区。
boolean ready() 判断此流是否可以读取。
void reset() 重置流。
long skip(long n) 跳过字符。
long transferTo(Writer out) 读取此阅读器中的所有字符,并按照读取的顺序将字符写入给定的编写器。
- CharArrayReader 该类实现了一个可用作字符输入流的字符缓冲区。用来对一个字符数组进行读操作。类似于ByteArrayInputStream。
- CharArrayWriter 该类实现了一个可用作Writer的字符缓冲区。 将数据写入流时,缓冲区会自动增长。 可以使用toCharArray()和toString()来检索数据。在此类上调用close()无效,并且可以在流关闭后调用此类的方法而不生成IOException。向该输出流写入字符用来生成一个字符数组。类似于ByteArrayOutputStream。
/**
* CharArrayWriter
* 构造方法:
* CharArrayWriter() 创建一个新的CharArrayWriter。
* CharArrayWriter(int initialSize) 创建具有指定初始大小的新CharArrayWriter。
*
* 特有方法:
* CharArrayWriter append(char c) 将指定的字符追加到此writer。
* CharArrayWriter append(CharSequence csq) 将指定的字符序列追加到此writer。
* CharArrayWriter append(CharSequence csq, int start, int end) 将指定字符序列的子序列追加到此writer。
* int size() 返回缓冲区的当前大小。
* char[] toCharArray() 返回输入数据的副本。
* String toString() 将输入数据转换为字符串。
*
* CharArrayReader
* 构造方法:
* CharArrayReader(char[] buf) 从指定的字符数组创建CharArrayReader。
* CharArrayReader(char[] buf, int offset, int length) 从指定的字符数组创建CharArrayReader。
*
* int read() 读一个字符。
* int read(char[] b, int off, int len) 将字符读入数组的一部分。
* boolean ready() 判断此流是否可以读取。
* @throws IOException
*/
@Test
public void CharArrayIO() throws IOException {
try (
CharArrayWriter out = new CharArrayWriter(20);) {
char[] chars = "Hello world".toCharArray();
//写入内容
out.write(chars, 0, chars.length);
//输出流中的内容转化为字符串
System.out.println(out.toString());
try ( //使用输出流中写入的字符数组创建一个输入流
CharArrayReader in = new CharArrayReader(out.toCharArray())) {
if (in.ready()) {
char[] tar = new char[20];
//读取输出流中的目标数组
in.read(tar);
System.out.println(new String(tar));
}
}
}
}
- InputStreamReader 是从字节流到字符流的桥接器:它使用指定的charset读取字节并将其解码为字符。 它使用的字符集可以通过名称指定,也可以明确指定,或者可以接受平台的默认字符集。每次调用一个InputStreamReader的read()方法都可能导致从底层字节输入流中读取一个或多个字节。 为了实现字节到字符的有效转换,可以从基础流中提取比满足当前读取操作所需的更多字节。为了获得最高效率,请考虑在BufferedReader中包装InputStreamReader。内部使用StreamDecoder将将数据从字节输入流InputStream中读取
- OutputStreamWriter OutputStreamWriter是从字符流到字节流的桥接器:使用指定的charset将写入其中的字符编码为字节。 它使用的字符集可以通过名称指定,也可以明确指定,或者可以接受平台的默认字符集。每次调用write()方法都会导致在给定字符上调用编码转换器。 生成的字节在写入底层输出流之前在缓冲区中累积。 请注意,传递给write()方法的字符不会被缓冲。为了获得最高效率,请考虑在BufferedWriter中包装OutputStreamWriter,以避免频繁的转换器调用。内部使用StreamEncoder将字符输出流中的内容写入的字节输出流OutputStream。
/**
* 构造方法:
* OutputStreamWriter(OutputStream out) 创建使用默认字符编码的OutputStreamWriter。
* OutputStreamWriter(OutputStream out, String charsetName) 创建使用指定charset的OutputStreamWriter。
* OutputStreamWriter(OutputStream out, Charset cs) 创建使用给定charset的OutputStreamWriter。
* OutputStreamWriter(OutputStream out, CharsetEncoder enc) 创建使用给定charset编码器的OutputStreamWriter。
* <p>
* 特有方法:
* void flush() 刷新流。
* String getEncoding() 返回此流使用的字符编码的名称。
* void write(char[] cbuf, int off, int len) 写一个字符数组的一部分。
* void write(int c) 写一个字符。
* void write(String str, int off, int len) 写一个字符串的一部分。
* Writer append(CharSequence csq, int start, int end) 将csq字符串序列追加到输出流,起始位置
* Writer append(CharSequence csq) 将csq字符串序列追加到输出流,起始位置
* String getEncoding() 获取编码
* 构造方法:
* InputStreamReader(InputStream in) 创建一个使用默认字符集的InputStreamReader。
* InputStreamReader(InputStream in, String charsetName) 创建一个使用指定charset的InputStreamReader。
* InputStreamReader(InputStream in, Charset cs) 创建一个使用给定charset的InputStreamReader。
* InputStreamReader(InputStream in, CharsetDecoder dec) 创建一个使用给定charset解码器的InputStreamReader。
* 特有方法:
* String getEncoding() 返回此流使用的字符编码的名称。
* int read() 读一个字符。
* int read(char[] cbuf, int offset, int length) 将字符读入数组的一部分。
* boolean ready() 判断此流是否可以读取。
*/
@Test
public void InputStreamWriterAndReaderIO() {
try (
//创建一个字节数组输出流
//ByteArrayOutputStream baos = new ByteArrayOutputStream();
FileOutputStream baos=new FileOutputStream("t2.text",true);
//以uft-8编码将字符数组写入字节数组输出流
OutputStreamWriter out = new OutputStreamWriter(baos, "utf-8");) {
char[] chars = "Hello world".toCharArray();
//写入内容,此时并没有将数据写入ByteArrayOutputStream
out.write(chars, 0, chars.length);
//刷新缓冲区,将数据写入ByteArrayOutputStream,否则内容不会被写入到字节输出流
//不手动刷新的话,只有缓冲区被占满才会自动写入字节输出流。
out.flush();
//查看编码
System.out.println(out.getEncoding());
try (
//以字节数组输出流中字节数组创建一个字节数组输入流
//ByteArrayInputStream bais = new ByteArrayInputStream(baos.toByteArray());
FileInputStream bais = new FileInputStream("t2.text");
//以utf-8编码从字节数组输入流读取字符
InputStreamReader in = new InputStreamReader(bais, "utf-8")) {
if (in.ready()) {
char[] chars1 = new char[20];
//读取内容
in.read(chars1);
//Hello world
System.out.println(new String(chars1));
}
}
} catch (IOException ex) {
ex.printStackTrace();
}
- FileWriter 使用默认缓冲区大小将文本写入字符文件。 从字符到字节的编码使用指定的charset或平台的default charset 。FileWriter用于编写字符流。 要写入原始字节流,请考虑使用FileOutputStream 。继承自OutputStreamWriter,内部创建一个FileOutputStream作为字节输出流,区别是OutputStreamWriter可以写入任意字节输出流,而FileWriter只能写入文件输出流。
- FileReader使用默认缓冲区大小从字符文件中读取文本。 从字节到字符的解码使用指定的charset或平台的default charset 。FileReader用于读取字符流。 要读取原始字节流,请考虑使用FileInputStream 。继承自InputStreamReader,内部使用传入的文件名或路径创建一个FileInputStream作为字节输入流。使用方式同BufferedInputStream,操作对象是文件。区别是InputStreamReader可以读取任意字节输入流,而FileReader只能读取文件输入流。
/**
* FileWriter
* FileWriter(File file) 给 File写一个 FileWriter ,使用平台的 default charset
* FileWriter(FileDescriptor fd) 构造一个 FileWriter给出的文件描述符,使用该平台的 default charset 。
* FileWriter(File file, boolean append) 在给出要写入的 FileWriter下构造 File ,并使用平台的 default charset构造一个布尔值,指示是否附加写入的数据。
* FileWriter(File file, Charset charset) 构造一个FileWriter给予File编写和charset 。
* FileWriter(File file, Charset charset, boolean append) 构造FileWriter给出File写入, charset和一个布尔值,指示是否附加写入的数据。
* FileWriter(String fileName) 构造一个 FileWriter给出文件名,使用平台的 default charset
* FileWriter(String fileName, boolean append) 使用平台的 default charset构造一个 FileWriter给定一个文件名和一个布尔值,指示是否附加写入的数据。
* FileWriter(String fileName, Charset charset) 构造一个FileWriter给出文件名和charset 。
* FileWriter(String fileName, Charset charset, boolean append) 构造一个FileWriter给定一个文件名, charset和一个布尔值,指示是否附加写入的数据。
* FileReader
* 构造方法:
* FileReader(File file) 使用平台 FileReader ,在 File读取时创建一个新的 FileReader 。
* FileReader(FileDescriptor fd) 使用平台 default charset创建一个新的 FileReader ,给定 FileDescriptor进行读取。
* FileReader(File file, Charset charset) 创建一个新的FileReader ,给出File读取和charset 。
* FileReader(String fileName) 使用平台 default charset创建一个新的 FileReader ,给定要读取的文件的 名称 。
* FileReader(String fileName, Charset charset) 给定要读取的文件的名称和FileReader ,创建一个新的FileReader 。
*/
@Test
public void FileWriterAndReaderIO() {
try (
//以追加方方式写入,编码方式为utf-8
FileWriter out = new FileWriter("t1.text", Charset.forName("utf-8") , true);) {
char[] chars = "Hello world".toCharArray();
//写入内容,此时并没有将数据写入ByteArrayOutputStream
out.write(chars, 0, chars.length);
//刷新缓冲区,将数据写入ByteArrayOutputStream,否则内容不会被写入到字节输出流
//不手动刷新的话,只有缓冲区被占满才会自动写入字节输出流。
// out.flush();
//查看编码
System.out.println(out.getEncoding());
try (
//以utf-8编码从字节数组输入流读取字符
FileReader in = new FileReader("t1.text",Charset.forName("utf-8"))) {
if (in.ready()) {
char[] chars1 = new char[20];
//读取内容
in.read(chars1);
//Hello world
System.out.println(new String(chars1));
}
}
} catch (IOException ex) {
ex.printStackTrace();
}
}
- BufferedReader 类似BufferedInputStream,可以指定缓冲区大小,默认为8192,通常,由Reader构成的每个读取请求都会导致相应的读取请求由基础字符或字节流构成。 因此,建议将BufferedReader包装在任何read()操作可能代价高昂的Reader上,例如FileReaders和InputStreamReaders。 例如,
BufferedReader in
= new BufferedReader(new FileReader("foo.in"));
如果没有缓冲,read()或readLine()的每次调用都可能导致从文件中读取字节,转换为字符,然后返回,这可能是非常低效的。
- BufferedWriter 将文本写入字符输出流,缓冲字符,以便有效地写入单个字符,数组和字符串,类似BufferedOutputStream,操作对象为字符。可以指定缓冲区大小,默认为8192。
提供了一个newLine()方法,它使用平台自己的行分隔符概念,由系统属性line.separator定义。 并非所有平台都使用换行符('\ n')来终止行。 因此,调用此方法终止每个输出行比直接编写换行符更为可取。建议将BufferedWriter包装在任何write()操作可能代价高昂的Writer周围,例如FileWriters和OutputStreamWriters。 例如,
PrintWriter out
= new PrintWriter(new BufferedWriter(new FileWriter("foo.out")));
将PrintWriter的输出缓冲到文件。 如果没有缓冲,每次调用print()方法都会导致字符转换为字节,然后立即写入文件,这可能效率很低。
-
LineNumberReader 缓冲的字符输入流,用于跟踪行号。 该类定义了方法setLineNumber(int)和getLineNumber() ,分别用于设置和获取当前行号。默认情况下,行号从0开始。此数字在读取数据时每line terminator递增一次,并且可以通过调用setLineNumber(int)进行更改。 但请注意, setLineNumber(int)实际上并未更改流中的当前位置; 它只会更改getLineNumber()返回的getLineNumber() 。通过换行符('\ n'),回车符('\ r')或回车符后面的任何一行,行被认为是terminated 。
-
FilterReader 抽象类,用于读取已过滤字符流的抽象类。 抽象类FilterReader本身提供了将所有请求传递给包含流的默认方法。 FilterReader子类应覆盖其中一些方法,还可能提供其他方法和字段。
-
FilterWriter 用于编写过滤字符流的抽象类。 抽象类FilterWriter本身提供了将所有请求传递给包含流的默认方法。 FilterWriter子类应覆盖其中一些方法,还可能提供其他方法和字段。
-
PushbackReader 字符流阅读器,相当于PushbackInputStream,允许将字符退回流中,操作的是字符。
-
PipedWriter 管道字符输出流。用法类似PipedOutputStream
-
PipedReader 管道字符输入流。用法类似PipedInputStream
-
StringWriter 在字符串缓冲区中收集其输出的字符流,然后可用于构造字符串。
-
StringReader 字符串,其源是字符串。对一个字符串进行读操作。
StringWriter() 使用默认的初始字符串缓冲区大小创建新的字符串编写器。
StringWriter(int initialSize) 使用指定的初始字符串缓冲区大小创建新的字符串writer。
StringWriter append(char c)
将指定的字符追加到此writer。
StringWriter append(CharSequence csq)
将指定的字符序列追加到此writer。
StringWriter append(CharSequence csq, int start, int end)
将指定字符序列的子序列追加到此writer。
void close() 关闭 StringWriter无效。
void flush() 冲洗流。
StringBuffer getBuffer() 返回字符串缓冲区本身。
String toString() 将缓冲区的当前值作为字符串返回。
void write(char[] cbuf, int off, int len) 写一个字符数组的一部分。
void write(int c) 写一个字符。
void write(String str) 写一个字符串。
void write(String str, int off, int len) 写一个字符串的一部分。
StringReader(String s) 创建一个新的字符串阅读器。
- PrintWriter 将对象的格式化表示打印到文本输出流。 这个类实现所有的print中发现的方法PrintStream 。 它不包含写入原始字节的方法,程序应使用未编码的字节流。不像PrintStream类,如果启用自动刷新,将只有当一个做println , printf ,或format被调用的方法,而不是当一个换行符恰好是输出。
RandomAccessFile
此类的实例支持读取和写入随机访问文件。 随机访问文件的行为类似于存储在文件系统中的大量字节。 有一种游标或索引到隐含数组中,称为文件指针 ; 输入操作从文件指针开始读取字节,并使文件指针超过读取的字节数。 如果在读/写模式下创建随机访问文件,则输出操作也可用; 输出操作从文件指针开始写入字节,并使文件指针超过写入的字节。 写入隐含数组当前末尾的输出操作会导致数组被扩展。 文件指针可以通过读取getFilePointer方法和由设置seek方法。
通常,对于此类中的所有读取例程,如果在读取了所需的字节数之前达到文件结尾,则抛出EOFException (这是一种IOException )。 如果由于文件结尾之外的任何原因无法读取任何字节,则抛出IOException以外的EOFException 。 特别是,如果流已经关闭, IOException可能抛出IOException 。
/**
* RandomAccessFile
* 构造方法:
* RandomAccessFile(File file, String mode) 创建随机访问文件流,以便从File参数指定的文件中读取,也可以选择写入。
* RandomAccessFile(String name, String mode) 创建随机访问文件流,以便从具有指定名称的文件进行读取,并可选择写入该文件。
*
* 特有方法:
* void close() 关闭此随机访问文件流并释放与该流关联的所有系统资源。
* FileChannel getChannel() 返回与此文件关联的唯一FileChannel对象。
* FileDescriptor getFD() 返回与此流关联的opaque文件描述符对象。
* long getFilePointer() 返回此文件中的当前偏移量。
* long length() 返回此文件的长度。
* int read() 从该文件中读取一个字节的数据。
* int read(byte[] b) 从此文件读取最多 b.length字节的数据到一个字节数组。
* int read(byte[] b, int off, int len) 从此文件读取最多 len字节的数据到一个字节数组。
* boolean readBoolean() 从此文件中读取 boolean 。
* byte readByte() 从该文件中读取带符号的8位值。
* char readChar() 从此文件中读取字符。
* double readDouble() 从此文件中读取 double 。
* float readFloat() 从此文件中读取 float 。
* void readFully(byte[] b) 从当前文件指针开始,将此文件中的 b.length字节读入字节数组。
* void readFully(byte[] b, int off, int len) 从当前文件指针开始,将此文件中的 len字节精确读入字节数组。
* int readInt() 从此文件中读取带符号的32位整数。
* String readLine() 从此文件中读取下一行文本。
* long readLong() 从此文件中读取带符号的64位整数。
* short readShort() 从该文件中读取带符号的16位数字。
* int readUnsignedByte() 从该文件中读取无符号的8位数。
* int readUnsignedShort() 从此文件中读取无符号的16位数字。
* String readUTF() 从此文件中读取字符串。
* void seek(long pos) 设置从此文件的开头开始测量的文件指针偏移量,在该位置进行下一次读取或写入操作。
* void setLength(long newLength) 设置此文件的长度。
* int skipBytes(int n) 尝试跳过 n字节的输入,丢弃跳过的字节。
* void write(byte[] b) 从当前文件指针开始,将指定字节数组中的 b.length字节写入此文件。
* void write(byte[] b, int off, int len) 将从偏移量 off开始的指定字节数组中的 len个字节写入此文件。
* void write(int b) 将指定的字节写入此文件。
* void writeBoolean(boolean v) 将 boolean写入文件作为单字节值。
* void writeByte(int v) 将 byte写入文件作为单字节值。
* void writeBytes(String s) 将字符串作为字节序列写入文件。
* void writeChar(int v) 将 char作为双字节值写入文件,高字节优先。
* void writeChars(String s) 将字符串作为字符序列写入文件。
* void writeDouble(double v) 双参数传递给转换 long使用 doubleToLongBits方法在类 Double ,然后写入该 long值到该文件作为一个八字节的数量,高字节。
* void writeFloat(float v) 浮子参数的转换 int使用 floatToIntBits方法在类 Float ,然后写入该 int值到该文件作为一个四字节数量,高字节。
* void writeInt(int v) 将 int写入文件为四个字节,高字节优先。
* void writeLong(long v) 将 long写入文件为8个字节,高字节优先。
* void writeShort(int v) 将 short写入文件为两个字节,高字节优先。
* void writeUTF(String str) 使用 modified UTF-8编码以与机器无关的方式将字符串写入文件。
*/
@Test
public void RandomAccessFileIO() {
try (
//以读写方式打开t1.text文件
RandomAccessFile rw = new RandomAccessFile("t1.text", "rw");) {
byte[] bytes1 = new byte[20];
//先执行写操作后无法读取数据
rw.read(bytes1);
System.out.println(new String(bytes1, "utf-8"));
//跳过文件原有内容,在文件尾操作,否则会覆盖原来的内容
rw.seek(rw.length());
byte[] bytes = "Hello worlds".getBytes("utf-8");
rw.write(bytes);
rw.writeChar('s');
rw.seek(12);
System.out.println(rw.readChar());
} catch (IOException ex) {
ex.printStackTrace();
}
}
IO总结
-
IO流根据传输单位大小区分为字节流和字符流
字节流 InputStream、OutPutStream;字符流Reader、Writer -
根据直接操作目标还是通过其它流操作目标可分为基础流和包装流(需传入一个基础流,对基础流进行沿途转换数据或提供其他功能)。
基础流:ByteArrayInputStream、ByteArrayOutputStream、FileInputStream、FileOutputStream、PipedInputStream、PipedOutputStream、StringBufferInputStream(过时)、CharArrayReader、CharArrayWriter、StringReader、StringWriter、PipedReader、PipedWriter
包装流:BufferedInputStream(添加缓冲区)、BufferedOutputStream(添加缓冲区)、DataInputStream(以基础数据类型读取)、DataOutputStream(以基础数据类型写入)、LineNumberInputStream(过时)、PushbackInputStream(支持对读取内容退回)、ObjectInputStream(能以基本数据类型读取,支持反序列化)、ObjectOutputStream(能以基本数据类型读取,支持序列化)、SequenceInputStream(组合多个输入流)、PrintStream(支持输出格式)、InputStreamReader(支持字节到字符的转换)、OutputStreamWriter(支持字符到字节的转换)、FileReader(同InputStreamReader)、FileWriter(同OutputStreamWriter)、BufferedReader(添加缓冲区)、LineNumberReader(BufferedReader,可设置合伙的lineNumber)、PrintWriter(PrintStream,支持输出格式)、PushbackReader(支持对读取内容退回) -
通过对文件操作或对内存操作区分
文件流:FileInputStream、FileOutputStream、FileWriter、FileReader
内存流:ByteArrayInputStream、ByteArrayOutputStream、PipedInputStream、PipedOutputStream、CharArrayReader、CharArrayWriter、StringReader、StringWriter、PipedReader、PipedWriter、StringBufferInputStream
NIO
传统IO操作磁盘时会有一个从JVM复制到磁盘的操作。NIO则可是使用Channel直接连接程序和磁盘,使用Buffer(直接缓冲区)进行直接读写。
NIO和传统IO的区别:
传统IO面向流,是阻塞的。
NIO面向缓冲区,非阻塞(针对网络Socket),可使用多路复用器对通道进行复用(非阻塞的实现)
概念:
- Channel 通道表示与实体的开放连接,例如硬件设备,文件,网络套接字或能够执行一个或多个不同I / O操作(例如读取或写入)的程序组件。渠道是开放的还是封闭的。 通道在创建时打开,一旦关闭,它将保持关闭状态。 一旦某个通道关闭,任何在其上调用I / O操作的尝试都将导致抛出ClosedChannelException 。 可以通过调用其isOpen方法来测试通道是否打开。
- FileChannel 用于读取,写入,映射和操作文件的通道。 获取该通道的方式有,文件io:FileInputStream.getChannel() , FileOutputStream.getChannel() , RandomAccessFile.getChannel(),FileChannel.open(),Files.newByteChannel();网络io:Socket.getChannel(),ServerSocket.getChannel(),DatagramSocket.getChannel()等。
abstract void force(boolean metaData) 强制将此通道文件的任何更新写入包含它的存储设备。
FileLock lock() 获取此频道文件的独占锁定。
abstract FileLock lock(long position, long size, boolean shared) 获取此通道文件的给定区域的锁定。
abstract MappedByteBuffer map(FileChannel.MapMode mode, long position, long size) 将此频道文件的某个区域直接映射到内存中。
static FileChannel open(Path path, OpenOption... options) 打开或创建文件,返回文件通道以访问该文件。
static FileChannel open(Path path, Set<? extends OpenOption> options, FileAttribute<?>... attrs) 打开或创建文件,返回文件通道以访问该文件。
abstract long position() 返回此通道的文件位置。
abstract FileChannel position(long newPosition) 设置此通道的文件位置。
abstract int read(ByteBuffer dst) 从该通道读取一个字节序列到给定的缓冲区。
long read(ByteBuffer[] dsts) 从该通道读取一系列字节到给定的缓冲区。
abstract long read(ByteBuffer[] dsts, int offset, int length) 从该通道读取一系列字节到给定缓冲区的子序列。
abstract int read(ByteBuffer dst, long position) 从给定文件位置开始,从该通道读取一个字节序列到给定缓冲区。
abstract long size() 返回此通道文件的当前大小。
abstract long transferFrom(ReadableByteChannel src, long position, long count) 从给定的可读字节通道将字节传输到此通道的文件中。
abstract long transferTo(long position, long count, WritableByteChannel target) 将字节从此通道的文件传输到给定的可写字节通道。
abstract FileChannel truncate(long size) 将此频道的文件截断为给定大小。
FileLock tryLock() 尝试获取此频道文件的独占锁定。
abstract FileLock tryLock(long position, long size, boolean shared) 尝试获取此频道文件的给定区域的锁定。
abstract int write(ByteBuffer src) 从给定缓冲区向该通道写入一个字节序列。
long write(ByteBuffer[] srcs) 从给定的缓冲区向该通道写入一个字节序列。
abstract long write(ByteBuffer[] srcs, int offset, int length) 从给定缓冲区的子序列向该通道写入一个字节序列。
abstract int write(ByteBuffer src, long position) 从给定的缓冲区向该通道写入一个字节序列,从给定的文件位置开始。
- SelectableChannel 可通过Selector多路复用的通道 。
- SocketChannel 用于面向流的连接套接字的可选通道。
- ServerSocketChannel 面向流的侦听套接字的可选通道。
- SelectionKey 表示SelectableChannel与Selector注册的令牌。
- SelectorSelectableChannel对象的多路复用器。
- Pipe 一对实现单向管道的通道。
- Pipe.SinkChannel 表示Pipe的可写端的通道 。
- Pipe.SourceChannel 表示Pipe可读端的通道 。
- Buffer 用于特定基元类型的数据的容器。缓冲区是特定基元类型的线性有限元素序列。多个并发线程使用缓冲区是不安全的。 如果要由多个线程使用缓冲区,则应通过适当的同步来控制对缓冲区的访问。
#属性:
capacity 缓冲区的容量是它包含的元素数。缓冲区的容量永远不会消极,永远不会改变。
limit 缓冲区的限制是不应读取或写入的第一个元素的索引。缓冲区的限制永远不会为负,并且永远不会超过其容量。
position 缓冲区的位置是要读取或写入的下一个元素的索引。缓冲区的位置永远不会为负,并且永远不会超过其限制。
mark 缓冲区标记是调用reset方法时其位置(position)将重置的索引 。
0 <= mark <= position <= limit <= capacity
#方法:
abstract Object array() 返回支持此缓冲区的数组 (可选操作) 。
abstract int arrayOffset() 返回此缓冲区缓冲区第一个元素的后备数组中的偏移量 (可选操作) 。
int capacity() 返回此缓冲区的容量。
Buffer clear() 清除此缓冲区。
abstract Buffer duplicate() 创建一个共享此缓冲区内容的新缓冲区。
Buffer flip() 翻转此缓冲区。
abstract boolean hasArray() 判断此缓冲区是否由可访问的数组支持。
boolean hasRemaining() 告知当前位置和限制之间是否存在任何元素。
abstract boolean isDirect() 判断此缓冲区是否为 direct 。
abstract boolean isReadOnly() 判断此缓冲区是否为只读。
int limit() 返回此缓冲区的限制。
Buffer limit(int newLimit) 设置此缓冲区的限制。
Buffer mark() 在此位置设置此缓冲区的标记。
int position() 返回此缓冲区的位置。
Buffer position(int newPosition) 设置此缓冲区的位置。
int remaining() 返回当前位置和限制之间的元素数。
Buffer reset() 将此缓冲区的位置重置为先前标记的位置。
Buffer rewind() 倒回这个缓冲区。
abstract Buffer slice() 创建一个新缓冲区,其内容是此缓冲区内容的共享子序列。
- 每个非布尔基元类型都有一个缓冲类。 每个类定义了一系列get和put方法,用于将数据移出和移入缓冲区,用于压缩 , 复制和切片缓冲区的方法,以及用于分配新缓冲区以及将现有数组包装到缓冲。
字节缓冲区的区别在于它们可以用作I / O操作的源和目标。 它们还支持其他缓冲区类中没有的几个功能:
(1)、可以将字节缓冲区分配为direct缓冲区,在这种情况下,Java虚拟机将尽最大努力直接在其上执行本机I / O操作。
(2)、一个字节缓冲区可以由mapping直接创建一个文件区域到内存中,在这种情况下,可以使用MappedByteBuffer类中定义的一些额外的文件相关操作。
(3)、字节缓冲区提供对其内容的访问,作为任何非布尔基元类型的异构或同构序列binary data ,在big-endian或little-endian byte order中 。
ByteBuffer alignedSlice(int unitSize) 创建一个新的字节缓冲区,其内容是此缓冲区内容的共享和对齐的子序列。
int alignmentOffset(int index, int unitSize) 返回内存地址,指向给定索引处的字节,给定单位大小的模数。
static ByteBuffer allocate(int capacity) 分配一个新的字节缓冲区。
static ByteBuffer allocateDirect(int capacity) 分配新的直接字节缓冲区。
byte[] array() 返回支持此缓冲区的字节数组 (可选操作) 。
int arrayOffset() 返回此缓冲区缓冲区第一个元素的后备数组中的偏移量 (可选操作) 。
abstract CharBuffer asXXXBuffer() 将此字节缓冲区的视图创建为XXX缓冲区。
abstract ByteBuffer compact() 压缩此缓冲区 (可选操作) 。
int compareTo(ByteBuffer that) 比较此缓冲区与另一个缓冲区。
duplicate() 创建一个共享此缓冲区内容的新字节缓冲区。
abstract byte get() 获取自缓冲区数据
abstract byte get(int index) 绝对 获取方法。
getXXX() 用于读取XXX基本类型值的相对 get方法。
getXXX(int index) 用于读取XXX基本类型值的绝对 get方法。
hasArray() 判断此缓冲区是否由可访问的字节数组支持。
hashCode() 返回此缓冲区的当前哈希码。
isDirect() 判断此字节缓冲区是否是直接的。
mismatch(ByteBuffer that) 查找并返回此缓冲区与给定缓冲区之间第一个不匹配的相对索引。
order() 检索此缓冲区的字节顺序。
order(ByteOrder bo) 修改此缓冲区的字节顺序。
put() 将一个或多个字节放入缓冲区。
putXXX() 用于写入XXX基本类型值的put方法 。
slice() 创建一个新的字节缓冲区,其内容是此缓冲区内容的共享子序列。
wrap() 将字节数组包装到缓冲区中。
- 直接缓冲区和非直接缓冲区,给定直接缓冲区Java虚拟机将尽最大努力直接执行本机I / O操作,而非直接缓冲区则需要执行copy操作将jvm中的内容写入磁盘;(1)、直接缓冲区将缓冲区建立在物理内存中,可以提高效率,可通过Buffer.allocateDirect()创建,此方法返回的缓冲区通常具有更高的分配和解除分配成本,或由FileChannel的mapping直接创建到存储器中的文件区域FileChannel.map()方法获得(MappedByteBuffer)。 直接缓冲区的内容可能位于正常的垃圾收集堆之外,因此它们对应用程序的内存占用量的影响可能并不明显。 因此,建议直接缓冲区主要分配给受基础系统本机I / O操作影响的大型长期缓冲区。 通常,最好只在它们在程序性能上产生可测量的增益时才分配直接缓冲区;(2)、非直接缓冲区将缓冲区建立在 JVM 的内存中,字节缓冲区可以由allocation创建,它为缓冲区的内容分配空间,或者通过wrapping将现有的字节数组创建到缓冲区中。
@Test
public void FileChannelNIO() {
//test 1:写入、读取字符串
try (FileOutputStream fos = new FileOutputStream("t1.text");
FileChannel outChannel = fos.getChannel();) {
ByteBuffer buf = ByteBuffer.allocate(1024);
buf.put("hello world".getBytes());
//切换到读模式
buf.flip();
//若有剩余字节则向文件中写入
while (buf.hasRemaining()) {
outChannel.write(buf);
}
buf.clear();
} catch (IOException ex) {
ex.printStackTrace();
}
//对同一文件可通过同一通道操作,此处为验证输入流的文件通道
try (FileInputStream fis = new FileInputStream("t1.text");
FileChannel inChannel = fis.getChannel()) {
ByteBuffer buf = ByteBuffer.allocate(1024);
inChannel.read(buf);
byte[] bytes = new byte[1024];
//切换到读
buf.flip();
//读取数据
buf.get(bytes, 0, buf.remaining());
System.out.println(new String(bytes));
} catch (IOException ex) {
ex.printStackTrace();
}
//test 2: 文件复制,直接缓冲区
try (FileInputStream fis = new FileInputStream("p1.jpg");
FileChannel inC = fis.getChannel();
FileOutputStream fos = new FileOutputStream("p2.jpg");
FileChannel outC = fos.getChannel()) {
//获取直接缓冲区
ByteBuffer buf = ByteBuffer.allocateDirect(1024);
//数据读入缓冲区
while (inC.read(buf) != -1) {
//切换到读
buf.flip();
//向p2.jpg写入
outC.write(buf);
//清空缓冲区
buf.clear();
}
//or
//inC.transferTo(0, inC.size(),outC);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
//test 3: 文件复制,直接缓冲区,此时在缓冲区上的操作相当于直接操作磁盘
try (
FileChannel inC = FileChannel.open(Path.of("p1.jpg"), StandardOpenOption.READ);
//文件操作枚举常量StandardOpenOption
FileChannel outC = FileChannel.open(Path.of("p3.jpg"), StandardOpenOption.WRITE, StandardOpenOption.CREATE, StandardOpenOption.READ)) {
//获取映射文件
//FileChannel.MapMode文件映射模式的类型安全枚举。
ByteBuffer inBuf = inC.map(FileChannel.MapMode.READ_ONLY, 0, inC.size());
ByteBuffer outBuf = outC.map(FileChannel.MapMode.READ_WRITE, 0, inC.size());
outBuf.put(inBuf);
/* byte[] bytes = new byte[inBuf.limit()];
//获取缓冲区内容
inBuf.get(bytes);
//写入直接输出缓冲流
outBuf.put(bytes);*/
//or
//inC.transferTo(0, inC.size(),outC);
} catch (IOException e) {
e.printStackTrace();
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号