JAVA学习笔记
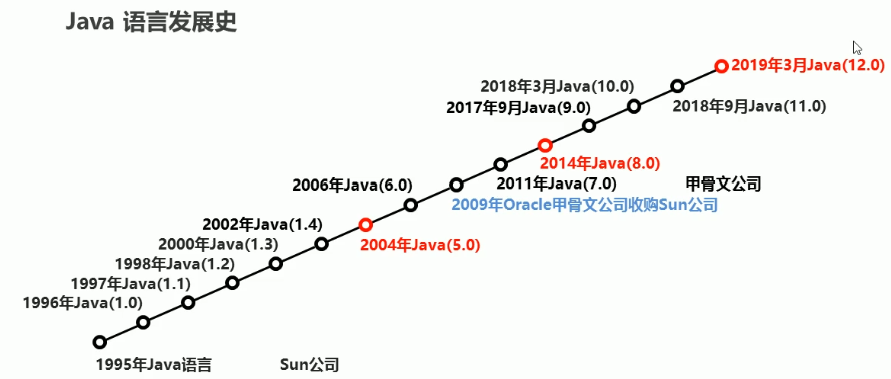
1. JAVA



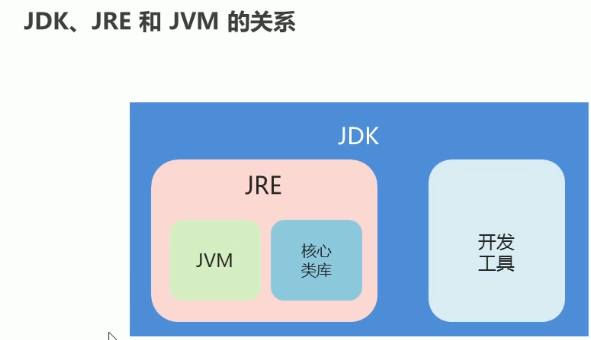
跨平台原理:在不同的操作系统中,都安装一个与操作系统对应的Java虚拟机(JVMJava Virtual Machine)即可。
2. 常用dos命令


3. 配置path环境变量
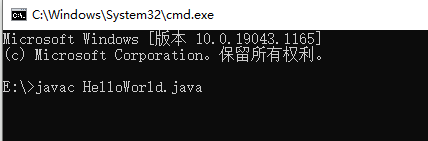
为了能够在任何文件夹下都能访问到JDK提供的javac(编译工具)和java工具(运行工具)
4. HelloWorld案例编写
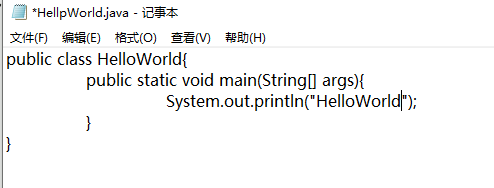


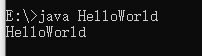
public class A { //public限制类名称和文件名保持一致,如果类名称是ABC,文件名是A,报错
public static void main(String[] args){
System.out.println("R.I.P");
}
}
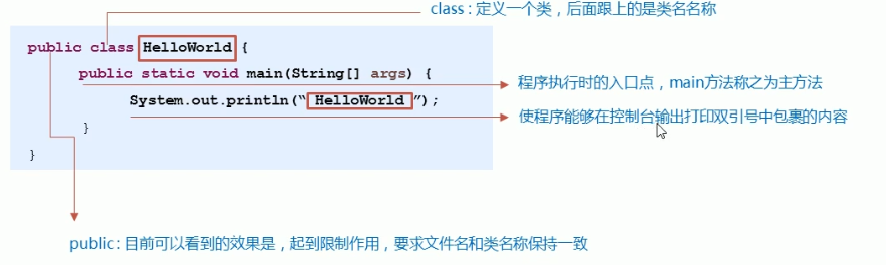
5. 数据类型
小数建议double 整数建议int,如果报错就用long
5.1 注意
5.1.1

5.1.2 定义float和long变量的注意事项
定义float类型变量的时候:需要在数值后面加入F的标识,F可以大写也可以小写.
定义1ong类型变量的时候:需要在数值后面加入L的标识,L可以大写也可以小写.(建议大写,因为小写的l和数字1太像)
float a = 12.3F;
long b = 1000L;
5.1.3 变量的作用域范围
变量的作用域:只在它所在的大括中有效
当这个大括中的代码执行完毕后,内部所[定义]的变量就会从内存中消失
6. 键盘录入
https://www.cnblogs.com/zhrb/p/6347738.html
步骤1:导包,需要写在class的上面
import java.util. scanner;
步骤2:创建对象
Scanner sC = new Scanner (System.in);
只有sc可以改变,其他属于固定格式
步骤3:使用变量接收数据
int i = ac.nextInt() ;
只有i变量可以改变,其他属于固定格式
import java.util.Scanner;
public class Demo1Scanner{
public static void main(String[] args){
Scanner sc =new Scanner(System.in);
int a = sc.nextInt();
System.out.println(a);
}
}
7. 标识符
标识符:就是给类,方法,变量等起名字的符号(就是自己起的名)
由数字、字母、下划线( )和美元符($)组成
不能以数字开头
不能是关键字
区分大小写
7.1 标识符的常见命名约定
7.1.1 小驼峰命名法:方法、变量
●约定1 :标识符是一个单词的时候,首字母小写
●范例1 : name
●约定2 :标识符由多个单词组成的时候,第一个单词首字母小写,其他单词首字母大写
●范例2 : firstName
7.1.2 大驼峰命名法:类
●约定1 :标识符是一个单词的时候,首字母大写
范例1 : Student
●约定2 :标识符由多个单词组成的时候,每个单词的首字母大写
范例2 : GoodStudent
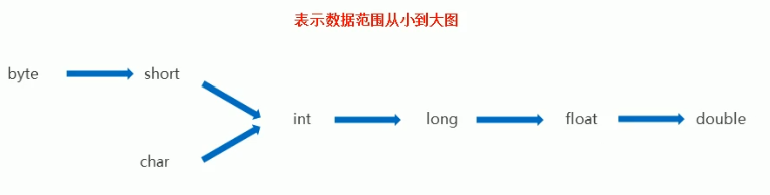
8. 类型转换
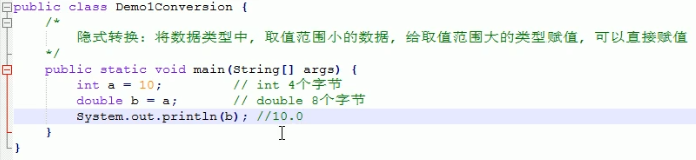
8.1 隐式转换
将数据类型中,取值范围小的数据,给取值范围大的类型赋值,可以直接赋值(小的给大的,可以直接给)
int 4个字节
double 8个字节
4升的油,倒入8升的桶,可以直接倒入
8.1.2 隐式转换的细节
小的数据类型,和大的数据类型运算,小的会提升为大的之后,再进行运算

8.1.3 特殊关注
byte short char三种数据在运算的时候,不管是否有更高的数据类型,都会提升为int ,然后再进行运算

8.2 强制转换
把一个表示数据范围大的数值或者变量赋值给另一个表示数据范围小的变量
简答理解:大的给小的,不能直接给,需要强转
格式:目标数据类型变量名= (目标数据类型)值或者变量;
public class Demo2Conversion{
public static void main(String[] args){
int a = 10;
byte b = (byte)a;
System.out.println(b);
}
}
范例:int k = (int)88.88;
注意:
强制类型转换,有可能会发生精度损失
精度损失:简单理解,将容积为8升的容器中的水,倒入容积为4升的容器中,如果水超出了4升,就洒了。
8.3 类型转换案例
请判断下列代码是否存在问题,如果有,请指出并修正。

前置知识点铺垫:
隐式转换:当小的数据类型和大的数据类型在-起运算的时候,小的会先提升为大的之后,再进行运算
特殊关注: byte short char 在运算的时候,都会直接提升为int,然后再进行运算. .
错误原因:
byte c= a + b;
这里的a和b是两个byte类型,它们在运算之前会将自己提升为int类型,然后再进行运算
两个int相加,结果还是int,想要把一-个int类型的结果,赋值给byte类型的变量
大的给小的,不能直接给
非要给的话,就需要强制类型转换
解决方案:
首先让a和b进行相加,使用()提升算数优先级
再对相加的结果整体进行强转
byte c= (byte)(a + b);
注意:
byte c= (byte)a + (byte)b;//错误方案,强制转换后还是byte,运算时又会提升为int
担心的问题:
3和4是两个常量,整数常量默认的数据类型是int
这里两个int相加,结果还是int, int给byte赋值.
enmm...应该需要强转吧
Java存在常量优化机制:
byted=3+4;
这里的3和4是两个常量,Java存在常量优化机制,会在编译的时候就会让3和4进行相加,然后会自动判断7是否在byte的取值范围内
不在范围内:编译出错
在范围内:通过编译
补充
long num = 123;
一般来说,123后面是要加个L的,但是此时编译不出错,说明不加L是可以的
为什么呢?
123是整数常量,默认为int类型,把int类型赋给long类型,即小的给大的,
这是不是意味着long以后不用加L了?
long num = 123456789123456789;
此时编译错误
long num = 123456789123456789L;
此时不出错
123456789123456789这么大的数值,默认的int是装不下的
9. 运算符
9.1 运算符和表达式
运算符:对常量或者变量进行操作的符号
表达式:用运算符把常量或者变量连接起来符合java语法的式子就可以称为表达式。
不同运算符连接的表达式体现的是不同类型的表达式。
举例说明
int a = 10;
int b = 20;
int c = a + b;
- :是运算符,并且是算术运算符
a +b:是表达式, 由于+是算术运算符,所以这个表达式叫算术表达式
简单说,符号就是运算符,整体就是表达式
9.2 算术运算符
运算符:
对[常量]或[变量]进行操作的符号
算数运算符
-
-
- :跟小学数学的运算方式一样
/ :整数相除,结果只能得到整数,如果想要得到带有小数的结果,必须加入小数(浮点类型)的运算
% (取模) :取余数.
- :跟小学数学的运算方式一样
-
9.2.1 字符的"+"操作
阅读下列代码,思考运行结果

运行结果

运算过程

a + b的运算中,为int类型, b为char类型
当( byte short char int )在一起运算的时候,都会提升为int之后,再进行运算
但是, char属于字符,字符是怎样提升为int数值的呢?
ASCII码表
ASCII (American Standard Code for Information Interchange) :美国信息交换标准代码
是计算机中字节到字符的一套对应关系。
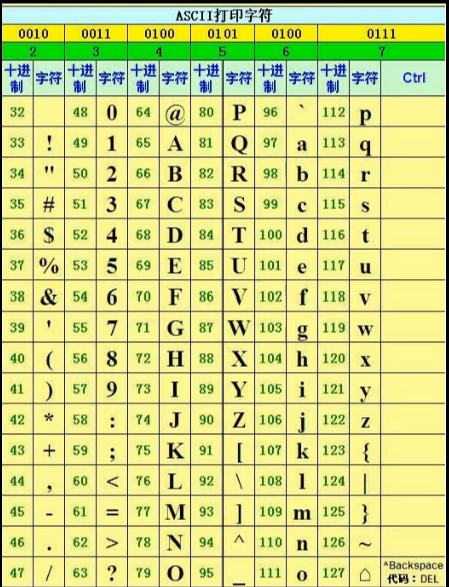
为什么要有这样的码表?
计算机中数据的存储,都是以字节的形式在进行存储,我们不会直接操作繁琐的、不便于记忆的字节。
例如:我们想要使用字符a ,但a字符真正存储的字节表示是数值97 ,如果直接面向字节,那现在要表示字符j
难道还要现去查找吗?不现实,太麻烦
可以记住一些常用的

回到运算过程

a + b的运算中, a为int类型, b为char类型
当( byte short char int )在一起运算的时候,都会提升为int之后, 再进行运算
char提升为int的过程,就是查找码表中,字符所对应的数值表示形式
字符'a' 查找到数值的97之后,在跟数值1进行运算,结果就是98
所以,最终输出在控制台的结果就是98
9.2.2 字符串的"+"操作
public class A {
public static void main(String[] args){
System.out.println("jimei"+666);
System.out.println("jimei"+true);
System.out.println(1+99+"年集美");//运算是从左到右进行的
System.out.println("5+5="+5+5);
System.out.println("5+5="+(5+5));//括号提升算数优先级
}
}

当+操作中出现字符串时,这个 + 是[字符串连接符],而不是算术运算。
字符串可以使用+号,跟[任意数据类型]拼接
在+操作中,如果出现了字符串,就是连接运算符,则就是算术运算。当连续进行+操作时,从左到右逐个执行。
字符串相等性判断
String a = new String("java");
String b = new String("java");
if(a == b)
System.out.println("相等");
else
System.out.println("不相等");
为什么不相等?
== 用于比较两个变量存放的引用值(可暂且理解为地址)是否相等
代码中使用了new 相等于:创建一个新的对线
于是 a和b 分别指向了两个新创建的字符串对象,对象的内容相同,但引用不同,所以a与b不相等
怎么改?
if(a.equals(b))
9.2.3 自增自减运算符
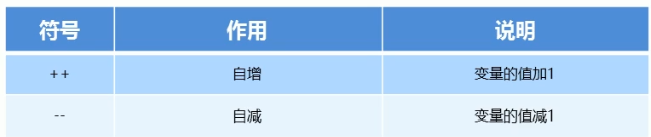
注意:只能对变量进行操作
9.2.4 赋值运算符
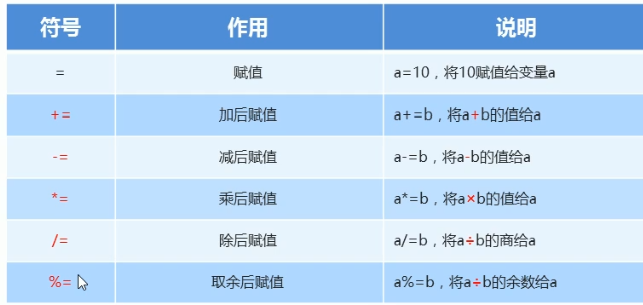
short s = 1;
s = (short)(s+ 1);//必须强制转换,否则编译错误
short ss = 1;
ss += 1;//注意:扩展赋值运算符底层会自带强转功能,此时不报错
注意事项:扩展的赋值运算符隐含了强制类型转换
9.2.4 关系运算符(比较运算符)

注意事项:关系运算符的结果都是boolean类型,要么是true ,要么是false。千万不要把“==” 误写成“=”
9.2.5 逻辑运算符
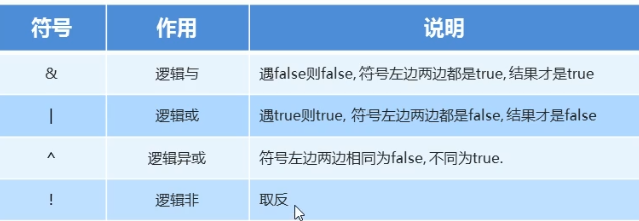
我们可以这样说,逻辑运算符,是用来连接关系表达式的运算符。当然,逻辑运算符也可以直接连接布尔类型的常量或者变量
短路逻辑运算符
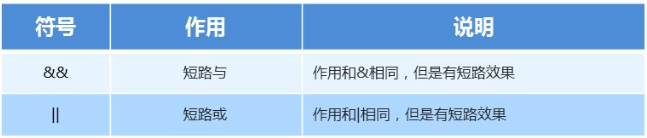
&和 && 的区别:
& :无论符号左边是true还是false,右边都要继续执行
&&具有短路效果,符号左边为false的时候,右边就不执行了
注意事项:
逻辑与& ,无论左边真假,右边都要执行。
短路与&& ,如果左边为真,右边执行;如果左边为假,右边不执行。
逻辑或| ,无论左边真假,右边都要执行。
短路或||,如果左边为假,右边执行;如果左边为真,右边不执行。
9.2.6 三元运算符
格式:关系表达式 ? 表达式1 : 表达式2;
执行流程:
首先计算关系表达式的值
如果值为true ,取表达式1的值
如果值为false ,取表达式2的值
public static void main (String[] arga) {
int a = 10;
int b = 20;
int max=a > b ? a : b;
system.out.println (max) ;
}
10.流程控制
流程控制语句:通过一些语句,来控制程序的[执行流程]
顺序结构
顺序结构是程序中最简单最基本的流程控制,没有特定的语法结构,按照代码的先后顺序,依次执行,
程序中大多数的代码都是这样执行的。
10.1 if语句
格式1:
if(关系表达式)
{
语句体;
}
格式2:
if(关系表达式)
{
语句体1;
}
else
{
语句体2;
}
格式3:
if(判断条件1)
{
语句体1;
}
else if(判断条件2)
{
语句体2;
}
···
else//备胎
{
语句体n+1;
}
注意事项:
①if语句所控制的语句体如果是-条语句,大括号可以省略不写
②if语句的小括号后面,没有分号
if(age>=18)
int a = 10;

报错
此时给 int a = 10; 加上括号就不报错
这是因为
对于编译器来说,它认为
int a = 10;
这条算是两条语句,定义是一条,赋值又是一条
10.2 Switch语句
格式
switch(表达式)
{
case值1 :
语句体1;
break;
case值2 :
语句体2;
break;
default :
语句体n+1;
break;
}
表达式的取值:(将要被匹配的值)取值为byte、short 、int、 char , JDK5以后可以是枚举, JDK7以后可以是String。
注意事项:
case给出的值不允许重复
case后面的值只能是常量,不能是变量
如果switch语句中,case省略了break语句,就会开始case穿透。
现象:
当开始case穿透,后续的case就不会具有匹配效果,内部的语句都会执行直到看见break,或者将整体ewitch语句执行完毕,才会结束.
case值1 :
语句体1;
case值2 :
语句体2;
break;
结果是执行了语句1和语句2
这是不是意味着以后写代码的时候都要写break?
不是的 case穿透现象可以利用
case穿透现象的利用
switch (week)
case 1:
case 2:
case 3:
case 4:
case 5:
System.out.println("工作日") ;
break;
case 6:
case 7:
System. out .print1n("休息日");
break;
default:
System.out.print1n("您的输入有误");
break;
10.3 for循环语句
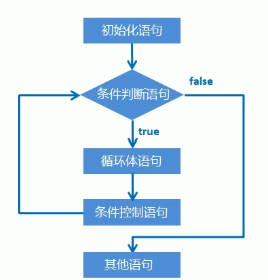
格式
for(初始化语句;条件判断语句;条件控制语句)
{
循环体语句;
}
注意:for循环内部定义的变量,在循环结束后,就会从内存中消失
10.4 while循环语句
格式
while(条件判断语句)
{
循环体语句;
(条件控制语句;)
}
10.5 do..while循环语句
do
{
循环体语句;
(条件控制语句;)
}while(条件判断语句)
10.5 三种循环的区别
三种循环的区别:
for循环和while循环先判断条件是否成立 ,然后决定是否执行循环体(先判断后执行)
do...while循环先执行一次循环体 ,然后判断条件是否成立,是否继续执行循环体(先执行后判断)
for和while的区别:
条件控制语 句所控制的自增变量,因为归属for循环的语法结构中,在for循环结束后,就不能再次被访问到了
条件控制语句所控制的自增变量,对于while循环来说不归属其语法结构中,在while循环结束后,该变量还可以继续使用
三种循环的场景:
明确循环次数,推荐使用for循环 例如;在控制台打印10次HelloWorld,求1-100之间的数据和
不明确循环次数,推荐使用while循环 例如 :珠穆朗玛峰案例
do..while循环,很少使用
命令提示符窗口中Ctrl+ C可以结束死循环
10.6 跳转控制语句
continue用在循环中,基于条件控制,跳过某次循环体内容的执行,继续下一次的执行
break用在循环中,基于条件控制,终止循环体内容的执行,也就是说结束当前的整个循环
注意:break和continue只能跳出、跳过自己所在的那一层关系,如果想要跳出、跳过指定的一层就可以加入标号。
示例
标号名: while (true)
{
switch (表达式)
{
case 1:
break 标号名;
}
}
11.Random
作用:用于产生一个随机数
使用步骤:
①导包
import java.util.Random;
导包的动作必须出现在类定义的上面
②创建对象
Random r = new Random();
r是变量名,可以边,其他的都不允许变
③获取随机数
int number = r.nextInt(10);//获取数据的范围:[0,10)包括0,不包括10
number是变量名,可以变,数字10可以变,其他的都不允许变
12.数组
数组(array)是一种容器,用来存储同种数据类型的多个值。
容器类型为int,存储int整数没有问题
容器类型为int ,存储byte类型,没有问题
总结:数组容器在存储数据的时候,需要结合数据类型考虑。
例如: int类型的数组容器( boolean byte short double )
建议:容器的类型,和存储的数据类型保持一致
12.1数组的定义格式
格式一
数据类型[] 变量名;
int[] array;
格式二
数据类型 变量名[];
int array[];
12.2数组的动态初始化
声明并开辟数组
数组类型[] 变量名 = new 数据类型[数组长度];
其中,数据类型可以是8种基本的数据类型,也可以是引用数据类型。
注意:
在给数组命名的时候,一般在数组名后加一个 s 表示这是一个包含多个元素的数组(与单个变量区分)。
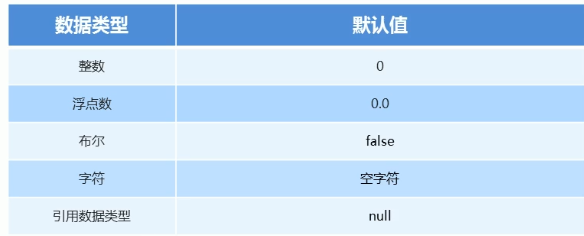
当数组采用动态初始化开辟空间之后,数组之中的每个元素都是该数据类型的默认值。
| 数据类型 | 默认初始化 |
| ---- | ---- | ---- |
| byte、short、int、long | 0 |
| foat、double | 0.0 |
| char | 一个空字符,即 ‘\u0000’ |
| boolean | false | 1 |
| 引用数据类型 | null,表示变量不引用任何对象 |
引用数据类型:引用、记录了地址值的变量,所对应的数据类型,就是引用数据类型
数组名称.length:取得数组长度(数组长度可以由属性length获得)。
12.3数组元素访问
访问数组容器中的空间位置
12.4 java内存分配
栈内存:方法运行时,进入的内存,局部变量都存放于这块内存当中
堆内存: new出来的内容都会进入堆内存,并且会存在地址值
方法区:字节码文件(.class文件)加载时进入的内存
本地方法栈:调用操作系统相关资源
寄存器:交给CPU去使用
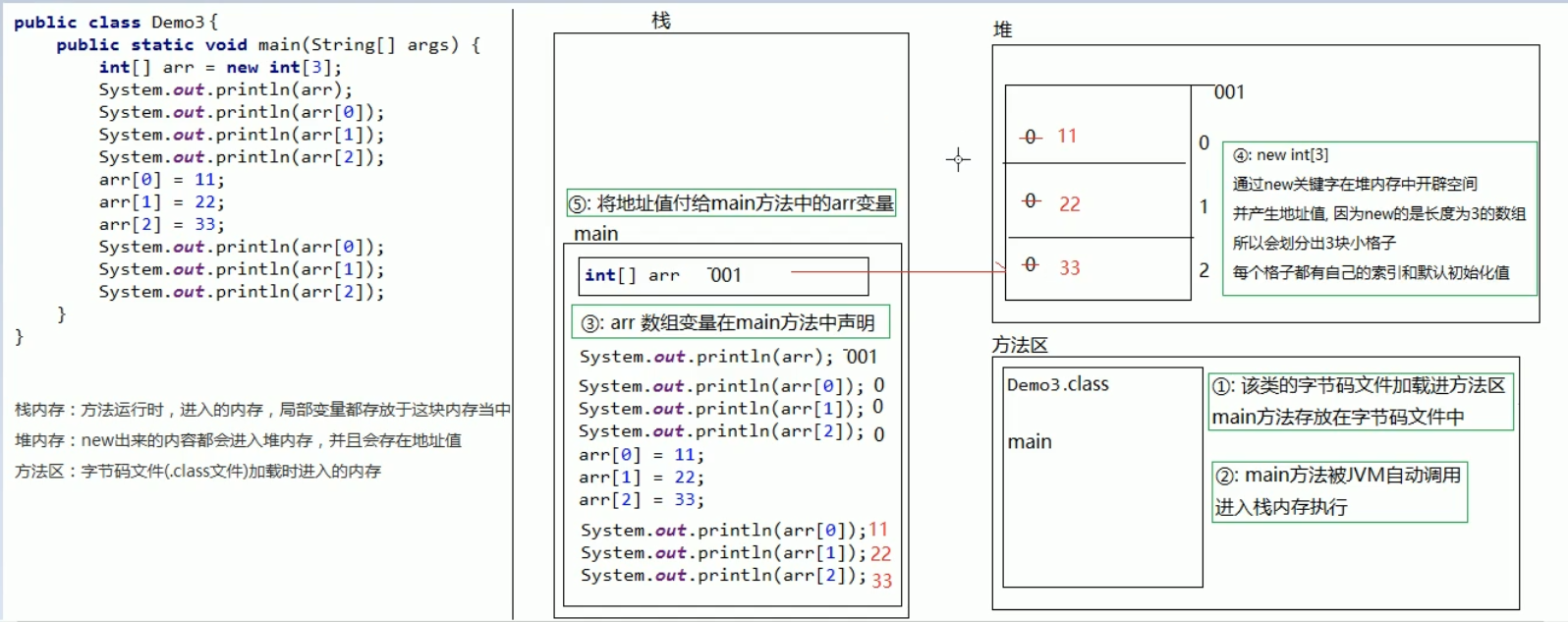
引用数据类型:引用、记录了地址值的变量,所对应的数据类型,就是引用数据类型
例如: int[] arr = new int[3];
12.5多个数组内存图

注意:每new一次,在堆内存中, 都是一块新的空间 ,堆内存中的空间地址不会出现重复的现象
12.6多个数组指向相同内存图
数组类型的变量应该记录什么?
地址值
int[] arr1 = new int[2];
int[] arr2 = arr1;
12.7 数组的静态初始化
静态初始化:初始化时,就可以指定数组要存储的元素,系统还会自动计算出该数组长度
格式
数据类型[] 变量名 = new 数据类型[]{数据1,数据2,数据3,……};
int[] arr = new int[]{1,2,3};
简化格式:数据类型[]变量名={数据1,数据2,数据.......};
注意:简化格式只是简化了书写,对内存来说new依旧是存在的
两种初始化的区别对比
动态初始化:手动指定数组长度,由系统给出默认初始化值。
静态初始化:手动指定数组元素,系统会根据元素个数,计算出数组的长度
使用场景
动态初始化:只明确元素个数,不明确具体数值,推荐使用动态初始化
例:使用数组容器来存储键盘录入的5个整数
int[]arr= {? ? ? ? ?};
静态初始化:需求中已经明确了要操作的具体数据,直接静态初始化即可
例:将一班的学生成绩存入数组中11,22,33
int[]arr= {11,22, 33};
12.8 数组常见操作
数组遍历:将数组中所有的数据取出来
动态获取数组元素个数:数组名.length

如果对应的索引不存在,我们一般都是返回一个负数,而且经常用-1来表示。
13. 方法
方法( method )就是一段具有独立功能的代码块,不调用就不执行
13.1 为什么要有方法
代码的重复度太高,复用性太差
方法的出现,可以提高代码的复用性
方法使用前提须知
方法必须先创建才可以使用 ,该过程称为方法定义
方法创建后并不是 直接运行的,需要手动使用后才执行,该过程称为方法调用
13.2 方法的定义和调用
13.2.1方法定义
格式
public static void 方法名()
{
//方法体
}
范例
public static void eat()
{
//方法体
}
13.2.2方法调用
格式
方法名();
范例
eat();
注意:方法必须先定义后调用,否则程序将报错
方法与方法之间是平级关系, 不能嵌套定义
方法没有被调用的时候,都在方法区中的字节码文件(.class)中存储
方法被调用的时候,需要进入到栈(先进后出)内存中运行
执行完毕就从栈出去了
13.3 带参数方法的定义和调用
13.3.1定义格式
public static void 方法名(参数){ ....}
单个参数
public static void 方法名(数据类型 变量名) {.....}
public static void method( int number){..... }
多个参数
public static void 方法名(数据类型变量名1, 数据类型变量名2,.....){......}
public static void getMax( int number1 ,int number2 ){ .....}
注意:
方法定义时,参数中的数据类型与变量名都不能缺少,缺少任意一个程序将报错
方法定义时,多个参数之间使用逗号( , )分隔
调用格式
方法名(参数);
单个参数
方法名(变星名/常量值);
method( 5 ) ;
多个参数
方法名(变量名1/常量值1 , 变量名2/常量值2 );
getMax ( 5,6 ) ;
13.3.2 形参和实参
形参:全称形式参数,是指方法定义中的参数
实参:全称实际参数,方法调用中的参数
13.4 带返回值方法的定义和调用
格式
public static 数据类型 方法名(参数)
{
return 数据;
}
范例1
public static boolean isEvenNumber( int number )
{
return true;
}
范例2
public static int getMax( int a, int b )
{
return 100 ;
}
注意:
方法定义时return后面的返回值与方法定义上的数据类型要匹配,否则程序将报错
定义方法时,要做到两个明确
明确参数:主要是明确参数的类型和数量
明确返回值类型:主要是明确方法操作完毕之后是否有数据返回,如果没有,写void ;如果有, 写对应的数据类型
13.5 方法重载
概述
在同一个类中,定义了多个同名的方法,但每个方法具有不同的参数类型或参数个數,这些同名的方法,就构成了重载关系
简单记:同一个类中,方法名相同,参数不同的方法
参数不同:个数不同、类型不同、顺序不同
顺序不同可以构成重载,但是不建议
方法重载的好处
在println中就有体现,java源代码中对println方法设置了大量重载关系,使你在打印的时候不用关心那么多繁琐的方法名,要是没有方法重载,可能会变成这样

示例
public static void main(String[] args)
{
short a = 10;
short b = 20;
System.out.println(compare(a,b));
}
public static boolean compare (int a, int b)
{
return a == b;
}
public static boolean compare (byte a, byte b)
{
return a == b;
}
public static boolean compare (short a, short b)
{
return a == b;
}
兼容了全整数类型
13.6 方法的参数传递
方法参数传递为基本数据类型:
传入方法中的,只是具体的数值
方法参数传递为引用数据类型:
传入方法中的,是内存地址
14. 二维数组
14.1 二维数组概述
二维数组也是一种容器,不同于一维数组 ,该容器存储的都是一维数组容器
14.2 二维数组 动态初始化
定义格式1
数据类型[][] 变量名;
int [][] arr;
定义格式2
数据类型 变量名[][];
int arr[][];
定义格式3
数据类型[]变量名[];
int[] arr[];
动态初始化
数据类型[][] 变量名 = new 数据类型[m][n];
int[][] arr =new int [3][3];
m表示这个二维数组,可以存放多少个一维数组
n表示每一个维数组,可以存放多少个元素
如果打印一下arr
System.out.println(arr);
会得到:[[I@10f87f48
@:分膈符
10f87f48 :十大进制内存地址
I :数组中存储的数据类型(int)
[[ : 几个中括号就代表的是几维数组
System.out.println(arr[0]);
System.out.println(arr[1]);
System.out.println(arr[2]);
会得到:
[ I@b4c966a
[ I@2f4d3709
[ I@4e50df2e
通过这个现象,我们可以得知:
二维数组存储一维数组的时候,存储的是一维数组的内存地址
14.3 二维数组 元素访问的细节问题
二维数组中存储的是一维数组,郡能不能存入[提前创建好的一维数组]呢?
int[] arr1 = {11,22,33};
int[] arr2 = {44,55,66};
int[] arr3 = {77,88,99};
int[][] arr = new int[3][3];
arr[0] = arr1;
arr[1] = arr2;
arr[2] = arr3;
Syt.out.println(arr[1][2]);
是可以的
如果改为这样
int[] arr3 = {77,88,99,100};
Syt.out.println(arr[2][3]);
是否会报错呢?
得到结果如下
100
为什么呢?
int[][] arr = new int[3][3] 不好使吗?
我们再使用传统的存储方式
int[][] arr = new int[3][3];
arr[2][3] = 100;
这时就会报错
为什么呢?
int[][] arr = new int[3][3];
new 进堆开辟空间,由于长度为3,划分出3个格子有各自的索引值,默认初始化值是null(二维数组存储的是一维数组,数组是引用类型,引用数据类型默认值都是null)
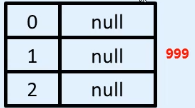
接下来再创建3个一维数组,长度都为3,都有各自的地址

再把3个一维数组的地址赋给二维数组当中去
这个二维数组当中记录的就是这3个一维数组的地址
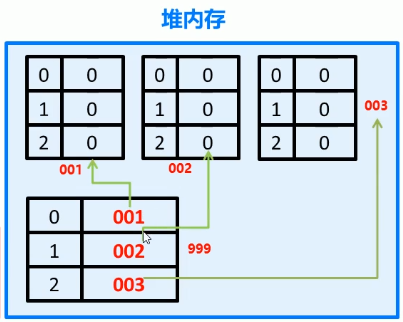
这时才把二维数组的地址赋给arr
找第1个一维数组数组的3号索引,但是根本没有3号索引
此时才出现错误(数组的索引越界异常)
那莫为什么提前创建一维数组再赋值的方式不会出现问题?
int[] smallArray = {111,222,333, 111};
arr[2] = smallArray;
System.out. println(arr[2][3]);
int[] smallArray = {111,222,333, 111};静态初始化在堆内存中开辟空间产生地址

此时它记录的是一份内存地址
arr[2] = smallArray;就是把2索引位置的地址替换为smallArray的地址
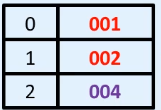
如果将来你再通过arr找2索引位置,找到的就是004所对应的空间
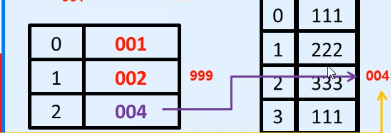
是地址的替换
System.out. println(arr[2][3]); arr先找2号索引 004, 004再找3号索引,即111
就把111取出并成功打印
内存地址的替换跟原来一维数组的长度没有关系了
14.4 二维数组 静态初始化
数据类型[][] 变量名= new 数据类型[][]{ {元素1,元素2}..., {元素1,元素2...} ...};
int[][] arr = new int[][]{{11,22},{33,44}};
简化格式:数据类型[][] 变量名= { {元素1,元素2}..., {元素1,元素2...} ...};
int[][] arr = {{11,22},{33,44}};
15. 进制
15.1 不同进制的书写方式
十进制:Java中,数值默认都是10进制,不需要加任何修饰。
二进制:数值前面以0b开头, b大小写都可以。
八进制:数值前面以0开头。
十六进制:数值前面以0x开头。x大小写都可以。
注意:书写的时候, 虽然加入 了进制的标识,但打印在控制台 展示的都是十进制数据.
15.2 进制转换
十进制到任意进制的转换
公式:除基取余
使用源数据,不断的除以基数(几进制,基数就是几)得到余数,直到商为0 ,再将余数倒着拼起来即可。
快速进制转换法
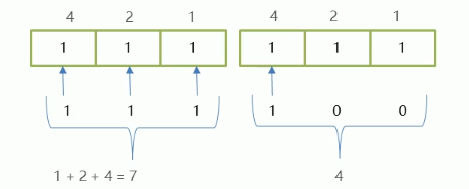
8421码:
8421码又称BCD码,是BCD代码中最常用的一种
BCD : (Binary-Coded Decimal)二进制码十进制数
在这种编码方式中,每一位二进制值的1都是代表一 个固定数值,把每一位的1代表的十进制数加起来
得到的结果就是它所代表的十进制数。
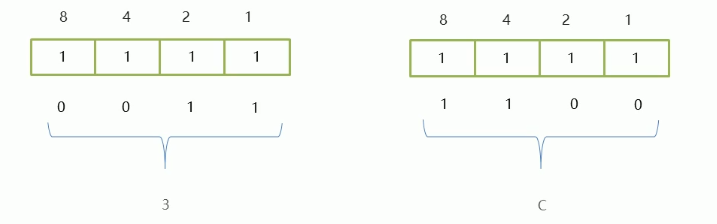
二进制快速转八进制
八进制:将三个二进制位看为-组,再进行转换
原因:八进制逢八进一,三个二进制位最多可以表示111 ,也就是数值7 ,如果出现第四位,就超范围了
例:将60的二进制0b111100转换为八进制
二进制快速转十六进制
十六进制:将四个二进制位看为一组,再进行转换
原因:十六进制逢十六进一,四个二进制位最多可以表示1111 , 也就是数值15 ,如果出现第五位,就超范围了
例:将60的二进制0b111100转换为十六进制
15.3 原码反码补码
计算机中的数据,都是以二进制补码的形式在运算,而补码则是通过反码和原码推算出来的。
原码(可直观看出数据大小)
就是二进制定点表示法,即最高位为符号位,[0] 示正,[1]示负,其余位表示数值的大小。
通过一个字节表示+7和-7 ,代码: byte b1= 7; byte b2= -7;
一个字节等于8个比特位,也就是8个二进制位
反码
正数的反码与其原码相同;负数的反码是对其原码逐位取反,但符号位除外。
补码(数据以该状态进行运算)
正数的补码与其原码相同;负数的补码是在其反码的末位加1。
了解之后,请看下面的案例

运行结果

为什么?
①整数130 :默认为int , int占用4个字节,也就是4组8个二进制位
00000000 00000000 00000000 10000010
②强转到byte : 4个字节, 强制转换为1个字节,就是砍掉前3组8位
10000010(当前以补码的形式存在,因为强制转换属于运算过程当中,所以强转后的数据是一个补码)
③根据运算后的补码,反向推原码
-126
16. 接口
interface关键字
- 接口是特殊的引用类型
- 可包含abstract方法签名
- 无方法体,无代码定义
- 接口必须被实现才能使用
定义:类似于定义抽象类

实现:使用implements实现接口,类似子类覆盖其父类所有抽象方法。

场景:飞行展览会,只要会进行飞行演示的飞行物均可参加。具体的,只要包含f1yShow方法,就可在飞行展览上进行飞行演示

接口体现has-a关系
相较于继承的is-a,接口体现的是has-a关系
所有实现Showable接口的对象均has-a flyShow方法
Plane与Bird虽无继承关系,但都has-a flyShow方法,这让实现相同接口的类可以有共同表现(但实现不同),这类似于继承
体现多态:拥有相同方法
(flyshow),但各有不同实现(Bird与Plane的实现不同)
接口抽象出来的是共同的行为
Comparable接口
public interface comparable{
int compareTo(object other);
}
该接口代表当前对象与传入对象other进行比较,比较的结果以int值返回:
==0,与other相等;>0,比other大;<0,比other小。
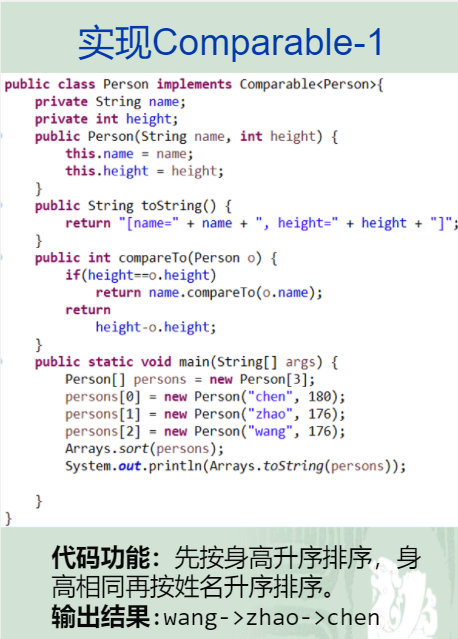
1.Arrays.sort()可对所有实现了Comparable接口的对象进行排序。
2.在排序过程中,必然涉及到两个对象之间的比较!怎么比较?

比较时调用该方法
https://blog.csdn.net/xiangyuenacha/article/details/84255353
17. 嵌套类与Lambda:局部类、匿名类与Lambda
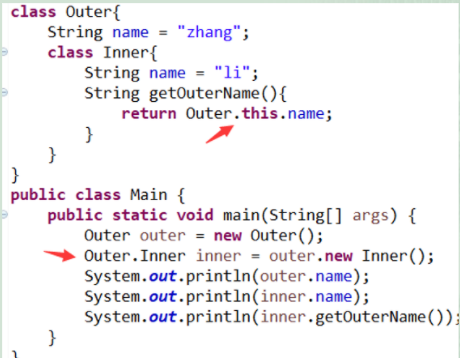
嵌套类定义
在类内部定义的类

非静态嵌套类(内部类)可访问外部类的所有属性和方法,包括private修饰的。
- Inner类可访问外部类outer的name
- 先有外部类才有内部类
如果嵌套类是static的,则不能访问外部非静态的属性和方法。

如果外部类和内部类的属性或方法同名怎么办?
OuterClassName.this.属性或OuterClassName.this.方法来访问;
局部类
语句块中定义的类

局部类是内部类
匿名类
没有类名的类
是内部类

常用于:图形界面编程中处理事件,如鼠标事件、按钮事件和键盘事件等。
匿名类一定会继承一个父类或者实现某个接口。上面创建的匿名类就是Test接口的实现类。
匿名类还有什么用?
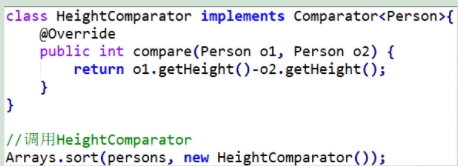
前面为了实现两个Person对象的比较,必须先定义一个HeightComparator类,太麻烦了!如下例所示:
如何使用匿名类简化?

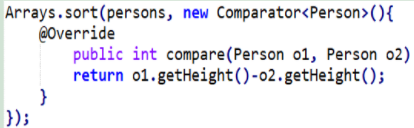
特点:
- 无需额外创建类,仅使用一次简化代码
- 隐藏操作、体现了封装性
Lam表达式


------------------------------------------------------------------------------------------------------分割线------------------------------------------------------------------------------------------------------------
http://c.biancheng.net/view/890.html
