
面试问题整理
1.kubernetes相关
1.使用ingress网关访问服务时报timeout
答:首先确保服务是否正常,不通过网关来访问服务做下测试。
如果我告诉你后端服务正常呢?
-
超时时间太短:您可以检查客户端的超时时间是否太短,并将其增加到合适的值。
-
网络问题:您可以检查网络连接是否正常,确保 Ingress 网关和要访问的服务都可以访问。
-
Ingress 规则不正确:您可以检查 Ingress 规则是否正确,确保请求的 URL 正确匹配 Ingress 规则。
-
后端服务响应慢:您可以检查后端服务是否响应较慢,并优化其性能。
-
中间件问题:如果您使用了中间件,请检查中间件是否出现问题,例如负载均衡器或代理。
答:这种情况下如果是使用的sc,那么每个pod都会去申请一个独立的pvc,这样下来其实每个pod内的数据并不是共享的那么就可能会导致数据不一致的问题。如果是使用的静态存储这种,多个pod都挂载同一个pvc上面那么就要考虑同时读写的问题,需要添加类似锁的机制来避免同时读写造成的问题。
3.helm
答:Helm是Kubernetes 应用的包管理工具,主要用来管理 Charts,类似Linux系统的yum。helm有三个概念,chart即helm包,helm仓库,release即运行在K8S集群中的实例。
helm如何安装一个服务
答:一般是先找到需要安装服务的仓库地址,将仓库地址add到本地helm中,然后使用helm install来安装对应服务。当然,helm一般只是提供一个比较标准化的服务模板,我们可以先把helm包pull下来解压修改里面的value文件来自定义安装,也可以通过show value来获取命令行自定义安装指令。
helm包怎么创建
答:helm create创建一个带有chart文件的目录,可以根据自己需求来添加templates和values,然后使用helm package 来打包。一般helm包里面包括charts(里面主要包括了包的一些介绍信息)、templates(这个目录下一般放值安装服务所需的一些Yaml文件)、values(这里面主要是一些关键参数的变量,在安装时templates里面的yaml文件会读取这些变量)。
4.集群外如何访问集群内的服务
答:一般访问会通过nodeport方式映射service端口,也可以通过ingress网络来做统一代理,有条件也可以使用loadbalancer负载均衡来把服务直接暴露到外部。
说一下外部访问服务的具体流程(流量走向)
答:首先要知道,service只是作为服务发现和负载均衡使用,真正pod的ip存在endpoints上面。拿到pod的地址以后无论通过集群的哪个节点进行访问该pod都是可以的(以集群使用BGP协议为例,bgp使用的是路由广播,即每个节点的路由表上都包含着集群所有的路由信息),节点会通过路由表上的信息来把请求转到对应节点上然后发送到pod内。
答:flannel插件下如果是在同一个节点内的pod他们共用一个docker网桥,相当于在同一个局域网中可以直接通过IP访问。跨节点访问则请求节点先发送请求到docker网桥,网桥把请求转到物理网卡,然后通过本地路由规则找到对应的节点。接受节点收到请求后转给docker网桥,网桥再将流量转到对应pod上。ji
bgp插件下,每个节点内都有全局路由表,在同一个节点内可以通过bgp为每个pod内置的 Veth Pair 直接进行转发,跨节点访问时 Veth Pair会把请求发到宿主机中。宿主机网络栈就会根据路由规则的下一跳 IP 地址,把它们转发给正确的网关。
(拓展问题, 常用的私有地址网段)
10.0.0.0/8:10.0.0.0-10.255.255.255 172.16.0.0/12:172.16.0.0-172.31.255.255 192.168.0.0/16:192.168.0.0-192.168.255.255
(二层网络和三层网络为了解决什么问题)
二层网络主要是避免广播风暴,三层网络主要实现跨多个域访问
二层网络寻址时通过mac地址寻址,三层网络寻址是通过路由寻址
5.pv和pvc
存储的管理是一个与计算实例的管理完全不同的问题。 PersistentVolume 子系统为用户和管理员提供了一组 API, 将存储如何制备的细节从其如何被使用中抽象出来。我们不需要关心底层的存储只需要通过API来实现对存储的操作。
静态存储:PV
动态存储:sc
PV卷的回收策略
保留
回收策略 Retain 使得用户可以手动回收资源。当 PersistentVolumeClaim 对象被删除时,PersistentVolume 卷仍然存在,对应的数据卷被视为"已释放(released)"。 由于卷上仍然存在这前一申领人的数据,该卷还不能用于其他申领。 管理员可以通过下面的步骤来手动回收该卷:
删除 PersistentVolume 对象。与之相关的、位于外部基础设施中的存储资产 (例如 AWS EBS、GCE PD、Azure Disk 或 Cinder 卷)在 PV 删除之后仍然存在。
根据情况,手动清除所关联的存储资产上的数据。
手动删除所关联的存储资产。
如果你希望重用该存储资产,可以基于存储资产的定义创建新的 PersistentVolume 卷对象
删除
对于支持 Delete 回收策略的卷插件,删除动作会将 PersistentVolume 对象从 Kubernetes 中移除,同时也会从外部基础设施(如 AWS EBS、GCE PD、Azure Disk 或 Cinder 卷)中移除所关联的存储资产。动态制备的卷会继承其 StorageClass 中设置的回收策略, 该策略默认为 Delete。管理员需要根据用户的期望来配置 StorageClass; 否则 PV 卷被创建之后必须要被编辑或者修补。
回收(已被废弃)
如果下层的卷插件支持,回收策略 Recycle 会在卷上执行一些基本的擦除 (rm -rf /thevolume/*)操作,之后允许该卷用于新的 PVC 申领。
PVC卷的回收策略
目前的回收策略有:
Retain -- 手动回收
Recycle -- 基本擦除 (rm -rf /thevolume/*)
Delete -- 诸如 AWS EBS、GCE PD、Azure Disk 或 OpenStack Cinder 卷这类关联存储资产也被删除
目前,仅 NFS 和 HostPath 支持回收(Recycle)。 AWS EBS、GCE PD、Azure Disk 和 Cinder 卷都支持删除(Delete)。
6.集群备份
-
物理备份:etcd 备份,保存某一个时刻的快照,快捷方便。
-
逻辑备份:基于 velero 或者自研功能,允许用户自己选择备份的内容、自动或定时备份,也可以恢复特定内容。同时备份的就是 yaml,用户可读可修改。
7.dockerfile
FROM #获取基础镜像,必须位于第一条
MAINTAINER #指定镜像作者信息
LABLE #添加元数据
USER #指定后续命令时使用的用户和用户组
RUN #构建镜像运行时执行的指令
EXPOSE #指定镜像使用端口,可以多个
CMD #指定容器默认执行命令,如果docker run时指定会将其覆盖
ENTRYPOINT #同CMD不过不会被docker run给覆盖
VOLUME #指定挂载目录
WORKDIR #指定工作目录
ENV #指定环境变量
COPY #从外面复制文件到镜像内
ADD #同COPY但是可以使用文件连接和解压文件
ARG #定义一个变量,用户在构建镜像时使用docker build --build-arg =将变量传递给构造器
如何减小镜像的大小
1.镜像时分层的dockerfile中的每条RUN指令都是一层,可以合并RUN指令来减少层。
2.选择一个合适的基础镜像(首选alpine)。
3.删除RUN指令造成的缓存文件。
4.分阶段构建,比如阶段一进项代码打包编译操作,把构建好的包拷贝到二阶段的镜像内,这样打出的镜像会少很多依赖文件。
8.kube-proxy(ipvs)的负载均衡策略
• rr:轮询
• lc:最少连接数
• dh:目的地址哈希
• sh:源地址哈希
• sed:最短期望延时
• nq:从不排队
9.一个pod的创建流程
用户通过kubectl命名发起请求。
apiserver通过对应的kubeconfig进行认证,认证通过后将yaml中的pod信息存到etcd。
Controller-Manager通过apiserver的watch接口发现了pod信息的更新,执行该资源所依赖的拓扑结构整合,整合后将对应的信息交给apiserver,apiserver写到etcd。
Scheduler同样通过apiserver的watch接口更新到pod可以被调度,通过算法给pod分配节点,并将pod和对应节点绑定的信息交给apiserver,apiserver写到etcd。
kubelet从apiserver获取需要创建的pod信息,调用CNI接口给pod创建pod网络,调用CRI接口去启动容器,调用CSI进行存储卷的挂载。
网络,容器,存储创建完成后pod创建完成,等业务进程启动后,pod运行成功。
10.kube-scheduler的调度策略
kube-scheduler 给一个 Pod 做调度选择时包含两个步骤:
过滤
打分
过滤阶段会将所有满足 Pod 调度需求的节点选出来。 例如,PodFitsResources 过滤函数会检查候选节点的可用资源能否满足 Pod 的资源请求。 在过滤之后,得出一个节点列表,里面包含了所有可调度节点;通常情况下, 这个节点列表包含不止一个节点。如果这个列表是空的,代表这个 Pod 不可调度。
在打分阶段,调度器会为 Pod 从所有可调度节点中选取一个最合适的节点。 根据当前启用的打分规则,调度器会给每一个可调度节点进行打分。
最后,kube-scheduler 会将 Pod 调度到得分最高的节点上。 如果存在多个得分最高的节点,kube-scheduler 会从中随机选取一个。
11.常见的pod控制器
Deployment: 无状态服务,将实际状态更改为期望状态。
Statefulset: 有状态服务,和 Deployment 类似, StatefulSet 管理基于相同容器规约的一组 Pod。但和 Deployment 不同的是, StatefulSet 为它们的每个 Pod 维护了一个有粘性的 ID。这些 Pod 是基于相同的规约来创建的, 但是不能相互替换:无论怎么调度,每个 Pod 都有一个永久不变的 ID。
daemonset: 守护进程的方式部署,保证每个节点上有一个pod运行。
12.Flannel和Calico的区别
答:Flannel配置简单,不需要额外存储,配置起来相对Calico更简单一些。但是flannel在三层网络下路由转发的基础上进行了封包和解包的操作,这样会有额外的额开销。flannel使用overlay虚拟网络,相当于在现有网络上构建了一个虚拟网络,这个网络对网络性能有一定损耗,而calico一般使用BGP协议通过路由规则和特定策略来发送跨网络效率和物理网络接近。
Flannel:
(1)引入了多个网络组件,在网络通信时需要转到flannel0网络接口,再转到用户态的flanneld程序,到对端后还需要走这个过程的反过程,所以也会引入一些网络的时延损耗。
(2)Flannel模型默认采用了UDP作为底层传输协议,UDP本身是非可靠协议,虽然两端的TCP实现了可靠传输,但在大流量、高并发的应用场景下还建议多次测试。
Calico:
(1)节点组网时可以直接利用数据中心的网络结构(L2或者L3),不需要额外的NAT、隧道或者Overlay Network,没有额外的封包解包,能够节约CPU运算,提高网络效率。
(2) 在小规模集群中可以直接互联,在大规模集群中可以通过额外的BGP route reflector来完成。
13.calico和flannel集中网络模式
flannel
udp:使用用户态udp封装,默认使用8285端口。由于是在用户态封装和解包,性能上有较大的损失
vxlan:vxlan封装,需要配置VNI,Port(默认8472)和GBP
host-gw:直接路由的方式,将容器网络的路由信息直接更新到主机的路由表中,仅适用于二层直接可达的网络
aws-vpc:使用 Amazon VPC route table 创建路由,适用于AWS上运行的容器
gce:使用Google Compute Engine Network创建路由,所有instance需要开启IP forwarding,适用于GCE上运行的容器
ali-vpc:使用阿里云VPC route table 创建路由,适用于阿里云上运行的容器
优点
配置安装简单,使用方便
与云平台集成较好,VPC的方式没有额外的性能损失
缺点
VXLAN模式对zero-downtime restarts支持不好
calico
Calico 的不足
既然是三层实现,当然不支持 VRF
不支持多租户网络的隔离功能,在多租户场景下会有网络安全问题
Calico 控制平面的设计要求物理网络得是 L2 Fabric,这样 vRouter 间都是直接可达的
14.为什么先用glusterfs又改用ceph呢?
答:因为ceph相对glusterfs搞起来有些复杂上手难度相对高一些,而且一些项目无法提供裸盘或者裸分区来部署ceph所以最开始选择glusterfs。glusterfs这种无中心架构,节点之间采用全互联模式的,也就意味着通信带宽消耗要求会比master/slave这种高很多。而且glusterfs的生态不如ceph的活跃,glusterfs的一些用来管理glusterfs的组件官方已经停止维护了,1.25版本的kubernetes也不再支持glusterfs。
15.kube-proxy的三种工作模式(iptables和ipvs的区别)
user namespace(legacy) (不常用)
-
客户端访问服务的ClusterIP
-
根据iptables规则, 将其转发到kube-proxy进程监控的端口
-
kube-proxy查找服务注册中心将请求转发给某个实例
优势:当请求某个实例失败时,因为在用户空间,可以进行重试其他实例。 劣势:效率低,因为第二步涉及到内核空间和用户空间的切换。

iptables
-
客户端访问服务的ClusterIP
-
根据iptables规则直接写成转发包到服务实例
优势: 不涉及内核用户态切换,效率更高。因为不用将包从内核转到kube-proxy进程处理,然后再切回来。
劣势: 比较难debug,不像第一种方式那样可以直接看kube-proxy访问日志/var/log/kube-proxy。你不得不去看内核处理iptables规则的日志。
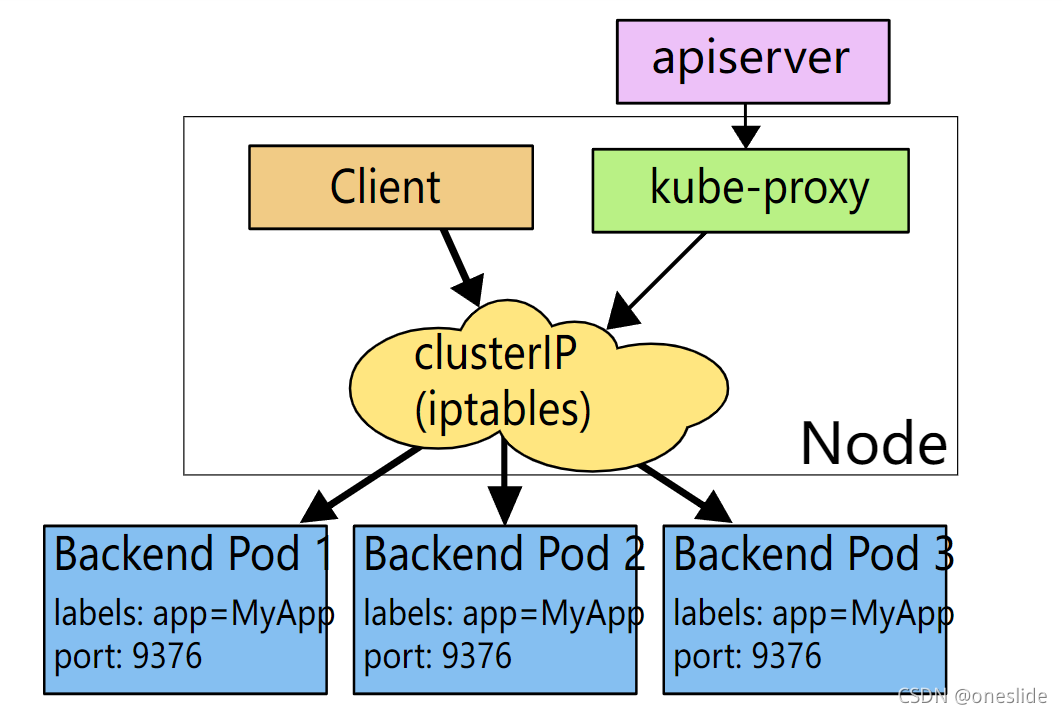
ipvs
-
客户端访问服务的ClusterIP
-
根据ipvs规则直接写成转发包到服务实例(和第二种唯一区别是将iptables换成ipvs)
优势: IPVS基于netfilter钩子函数实现类似iptables功能,但使用hash表作为底层数据结构来查找路由规则,ipvs是一个内核模块,且也在内核态工作。iptables使用数组遍历方式处理规则,因此效率和路由规则数量呈正比。当服务增加到1000+, 效率比用hash表处理规则的ipvs差了。
劣势: 需要高版本内核,低版本内核没有ipvs模块,这个时候如果设置ipvs模式,kube-proxy会自动降级到iptables模式。
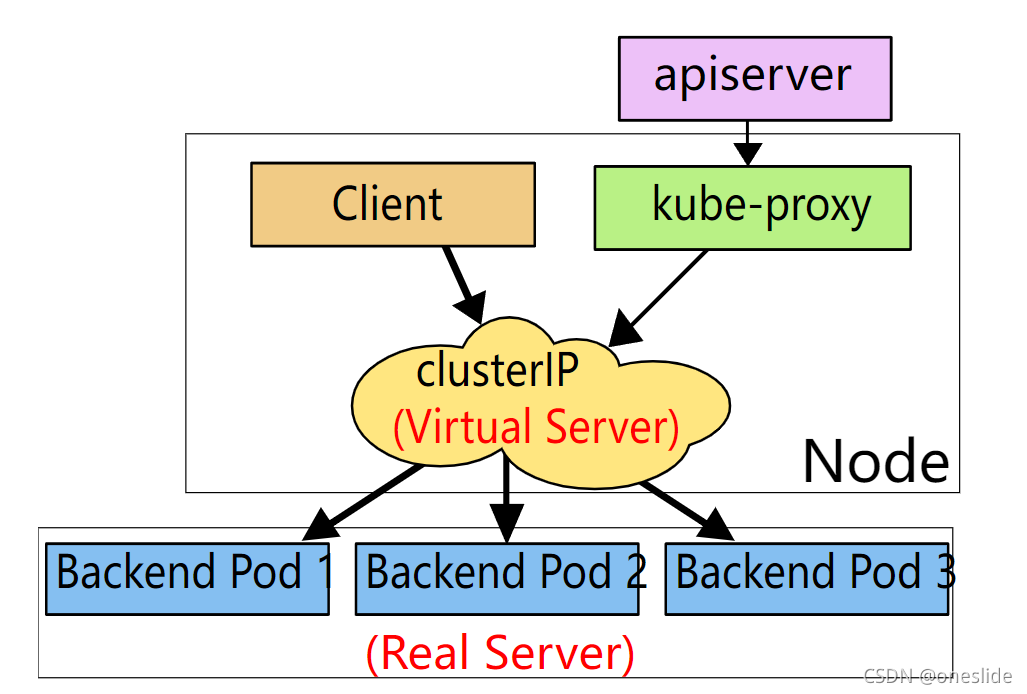
16.K8S三层网络方案
一个K8S的集群中至少有三个网络:
1、 集群节点所在的网络,这个网络就是你的主机所在的网络,通常情况下是你的网络基础设施提供。如果你的node处于不同的网段,那么你需要保证路由可达。如上图中的 192.168.10.0/24和10.0.0.0/8这两个网络
2、第二个网络是Pod的网络, K8s中一个Pod由多个容器组成,但是一个pod只有一个IP地址,Pod中所有的容器共享同一个IP。这个IP启动pod时从一个IP池中分配的, 叫做 pod CIDR, 或者叫network_cidr(如图,默认配置是10.1.0.0/16)。 可以在配置文件中配置。
3、K8S服务网络, service_cluster_ip_range(如图,默认的配置是的10.0.0.1/24)

17.K8S中service是如何和pod关联(绑定)
答:标签和标签选择器。资源对象在创建时可以添加一个或多个标签,如pod在创建时添加标签
apiVersion: v1
kind: Pod
metadata:
name: label-demo
labels:
environment: production
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
service通过标签选择器来关联pod
apiVersion: v1
kind: Service
metadata:
name: nginx-svc
spec:
ports:
- port: 7474
name: nginx
type: NodePort
selector:
app: nginx
18.K8S的组件
控制平面组件:
kube-apiserver: Kubernetes API 是通过 HTTP 提供的基于资源 (RESTful) 的编程接口。 它支持通过标准 HTTP 动词(POST、PUT、PATCH、DELETE、GET)检索、创建、更新和删除主要资源。
kube-contorller-manager:kube-controller-manager 由一系列的控制器组成,在 Kubernetes 中,控制器通过监控集群的公共状态,并致力于将当前状态转变为期望的状态。
kube-scheduler: 负责监视新创建的、未指定运行节点(node)的 Pods, 并选择节点来让 Pod 在上面运行。
etcd: 一致且高度可用的键值存储,用作 Kubernetes 的所有集群数据的后台数据库。
Node组件:
kubelet: kubelet 会在集群中每个节点(node)上运行。 它保证容器(containers)都运行在 Pod 中。
kube-proxy:kube-proxy 是集群中每个节点(node)上所运行的网络代理, 实现 Kubernetes 服务(Service) 概念的一部分.
kube-proxy 维护节点上的一些网络规则, 这些网络规则会允许从集群内部或外部的网络会话与 Pod 进行网络通信。
如果操作系统提供了可用的数据包过滤层,则 kube-proxy 会通过它来实现网络规则。 否则,kube-proxy 仅做流量转发。
容器运行时:
docker或者 containerd比较常用
插件:
DNS: cordens
网络插件: flannel或calico比较常用
19.K8S为什么选用etcd做存储
Kubernetes 选择 etcd 作为存储是因为它具有以下特点:
分布式:etcd 是一种分布式键值存储,可以跨多个节点存储数据。Kubernetes 需要存储全局状态以便在整个集群中协调它的行为。
可靠:etcd 使用 Raft 协议来保证一致性,以确保在集群中的任何节点故障时仍然可以提供可靠的服务。
快速:etcd 是一种快速的存储,能够处理大量请求。Kubernetes 的控制器需要快速访问状态,以确保其行为是一致的。
简单:etcd 具有简单的数据模型和 API,易于使用和集成。Kubernetes 的开发人员可以快速地存储和读取状态。
因此,Kubernetes 选择了 etcd 作为其存储,以便在保证可靠性、快速性和简单性的同时存储全局状态。
20.kubernetes中service突然无法访问pod了是什么原因?
有多种原因可能导致 Kubernetes 中的 Service 突然无法访问 Pod。以下是一些常见的原因:
-
网络故障:如果集群的网络出现故障,可能会导致 Service 无法访问 Pod。
-
集群中的节点故障:如果集群中的某个节点出现故障,这可能会导致 Service 无法访问其中的 Pod。
-
Pod 故障:如果 Pod 故障或关闭,Service 将无法访问其中的服务。
-
Endpoint 配置错误:如果 Endpoint 的配置错误,Service 可能无法正确地访问 Pod。
-
访问控制限制:如果访问控制限制不正确,Service 可能无法正确地访问 Pod。
21.kubernetes中二进制部署的集群如何替换证书
在 Kubernetes 集群中替换证书的步骤如下:
-
准备新证书:您需要准备一份新证书,并将其保存到安全的位置。
-
替换证书:在每个集群节点上,替换原始证书文件,使用新证书文件进行替换。位置取决于您是如何安装和配置集群的,请参考您使用的文档。
-
重启 kubelet 和 API server:在每个节点上,重启 kubelet 和 API server 以使用新证书。方法取决于您使用的操作系统,请参考相关文档。
-
检查证书:使用
kubectl get componentstatuses命令检查证书是否已更新。如果所有组件的状态都是正常的,则证书已成功更新。
请注意,替换证书是一项重要的操作,请确保您熟悉执行步骤,并在生产环境中进行测试,以确保替换证书后的集群仍能正常运行。
22.pod处于pending状态的原因
Pod 处于 pending 状态的原因可能有很多,下面是一些常见的原因:
-
资源不足:如果 Kubernetes 集群中的节点没有足够的 CPU 或内存资源,Pod 可能无法启动。
-
网络问题:如果 Pod 无法访问它需要的网络,它可能处于 pending 状态。
-
容器镜像问题:如果容器镜像无法正确加载,Pod 可能处于 pending 状态。
-
其他依赖问题:如果 Pod 需要的其他资源(如 ConfigMap 或 Secret)没有准备好,Pod 可能处于 pending 状态。
23.非k8s节点的机器怎么直接访问pod的IP?
在非 K8S 节点和集群节点之间,添加一个网络转发设备(比如路由器或者 L3 交换机),将 Pod IP 子网添加到这个设备上,通过这个设备实现非 K8S 节点和集群节点之间的网络通信。
24.容器化和虚拟化的区别
容器虚拟化是指通过容器技术,在一个物理主机上运行多个隔离的用户空间(namespace)实例,每个实例都有自己的文件系统、进程空间、网络接口等资源。容器与宿主机共享同一个操作系统内核,因此容器的启动速度较快,资源占用较少。容器可以快速迁移、复制,使得应用的开发、测试和部署变得更加灵活。
物理虚拟化是指通过虚拟机监控器(VMM)在一台物理主机上创建多个虚拟机,每个虚拟机都具有独立的操作系统和完整的硬件资源(包括 CPU、内存、硬盘、网卡等)。虚拟机之间相互隔离,因此虚拟机可以运行不同的操作系统和应用程序。虚拟化技术为应用程序提供了更高的隔离性和安全性,并且可以利用硬件资源更加高效地运行多个操作系统和应用程序。
25.容器核心技术--Cgroup 与 Namespace
容器 = cgroup + namespace + rootfs + 容器引擎
-
Cgroup: 资源控制
-
namespace: 访问隔离
-
rootfs:文件系统隔离。镜像的本质就是一个rootfs文件
-
容器引擎:生命周期控制
1.cgroup
Cgroup 是 Control group 的简称,是 Linux 内核提供的一个特性,用于限制和隔离一组进程对系统资源的使用。对不同资源的具体管理是由各个子系统分工完成的。
| 子系统 | 作用 |
|---|---|
| devices | 设备权限控制 |
| cpuset | 分配指定的CPU和内存节点 |
| CPU | 控制CPU使用率 |
| cpuacct | 统计CPU使用情况 |
| memory | 限制内存的使用上限 |
| freezer | 暂停Cgroup 中的进程 |
| net_cls | 配合流控限制网络带宽 |
| net_prio | 设置进程的网络流量优先级 |
2.Namespace
Namespace 是将内核的全局资源做封装,使得每个namespace 都有一份独立的资源,因此不同的进程在各自的namespace内对同一种资源的使用互不干扰。
举个例子,执行sethostname这个系统调用会改变主机名,这个主机名就是全局资源,内核通过 UTS Namespace可以将不同的进程分隔在不同的 UTS Namespace 中,在某个 Namespace 修改主机名时,另一个 Namespace 的主机名保持不变。
目前,Linux 内核实现了6种 Namespace。
| Namespace | 作用 |
|---|---|
| IPC | 隔离 System V IPC 和 POSIX 消息队列 |
| Network | 隔离网络资源 |
| Mount | 隔离文件系统挂载点 |
| PID | 隔离进程ID |
| UTS | 隔离主机名和域名 |
| User | 隔离用户和用户组 |
与命名空间相关的三个系统调用: clone创建全新的Namespace,由clone创建的新进程就位于这个新的namespace里。创建时传入 flags参数,可选值有 CLONE_NEWIPC, CLONE_NEWNET, CLONE_NEWNS, CLONE_NEWPID, CLONE_NEWUTS, CLONE_NEWUSER, 分别对应上面六种namespace。
unshare为已有进程创建新的namespace。
setns把某个进程放在已有的某个namespace里。
回到 Docker 上,经过上述讨论,namespace 和 cgroup 的使用很灵活,需要注意的地方也很多。 Docker 通过 Libcontainer 来做这些脏活累活。用户只需要使用 Docker API 就可以优雅地创建一个容器。docker exec 的底层实现就是上面提过的 setn
3.rootfs
rootfs 代表一个 Docker 容器在启动时(而非运行后)其内部进程可见的文件系统视角,或者叫 Docker 容器的根目录。 先来看一下,Linux 操作系统内核启动时,内核会先挂载一个只读的 rootfs,当系统检测其完整性之后,决定是否将其切换到读写模式。 Docker 沿用这种思想,不同的是,挂载rootfs 完毕之后,没有像 Linux 那样将容器的文件系统切换到读写模式,而是利用联合挂载技术,在这个只读的 rootfs 上挂载一个读写的文件系统,挂载后该读写文件系统空空如也。Docker 文件系统简单理解为:只读的 rootfs + 可读写的文件系统。 假设运行了一个 Ubuntu 镜像,其文件系统简略如下

Ubuntu 容器文件视角
在容器中修改用户视角下文件时,Docker 借助 COW(copy-on-write) 机制节省不必要的内存分配。
2.linux系统相关
1.内存大页
在 Linux 中,物理内存是以页为单位来管理的。默认的,页的大小为 4KB。 CPU 中有一个内置的内存管理单元(MMU),用于存储这些页的列表(页表),每页都有一个对应的入口地址。4KB 大小的页面在 “分页机制” 提出的时候是合理的,因为当时的内存大小不过几十兆字节。然而,当前计算机的物理内存容量已经增长到 GB 甚至 TB 级别了,操作系统仍然以 4KB 大小为页面的基本单位的话,会导致 CPU 中 MMU 的页面空间不足以存放所有的地址条目,则会造成内存的浪费。
同时,在 Linux 操作系统上运行内存需求量较大的应用程序时,采用的默认的 4KB 页面,将会产生较多 TLB Miss 和缺页中断,从而大大影响应用程序的性能。当操作系统以 2MB 甚至更大作为分页的单位时,将会大大减少 TLB Miss 和缺页中断的数量,显著提高应用程序的性能。
为了解决上述问题,自 Linux Kernel 2.6 起,引入了 Huge pages(巨型页)的概念,目的是通过使用大页内存来取代传统的 4KB 内存页面, 以适应越来越大的内存空间。Huge pages 有 2MB 和 1GB 两种规格,2MB 大小(默认)适合用于 GB 级别的内存,而 1GB 大小适合用于 TB 级别的内存。
2.一台新机器给你会做哪些操作
一般内网的话会关闭selinux和防火墙;
如果有需要会关闭swap分区;
更新国内yum源;
添加普通用户通过sodu授权;
禁止root远程连接;
调整文件描述符的数量;
清空/etc/issue,去除系统及内核版本登录前的屏幕显示;
定时自动更新服务器时间;
3.linux中病毒怎么办
1)最简单有效的方法就是重装系统
2)要查的话就是找到病毒文件然后删除,中毒之后一般机器cpu、内存使用率会比较高,机器向外发包等异常情况,排查方法简单介绍下
- top 命令找到cpu使用率最高的进程
- 一般病毒文件命名都比较乱,可以用 ps aux 找到病毒文件位置
- rm -f 命令删除病毒文件
- 检查计划任务、开机启动项和病毒文件目录有无其他可以文件等
3)由于即使删除病毒文件不排除有潜伏病毒,所以最好是把机器备份数据之后重装一下
4.简述raid0 raid1 raid5 三种工作模式的工作原理及特点
RAID 0:RAID0 是一种非常简单的的方式,它将多块磁盘组合在一起形成一个大容量的存储。当我们要写数据的时候,会将数据分为N份,以独立的方式实现N块磁盘的读写,那么这N份数据会同时并发的写到磁盘中,因此执行性能非常的高。但它没有数据冗余,RAID 0 只是单纯地提高性能,并没有为数据的可靠性提供保证,而且其中的一个磁盘失效将影响到所有数据。因此,RAID 0 不能应用于数据安全性要求高的场合
RAID 1:镜像卷,它是通过磁盘数据镜像实现数据冗余,在成对的独立磁盘上产生互为备份的数据,不能提升写数据效率。当原始数据繁忙时,可直接从镜像拷贝中读取数据,因此RAID1 可以提高读取性能,RAID 1 是磁盘阵列中单位成本最高的,镜像卷可用容量为总容量的1/2,但提供了很高的数据安全性和可用性,当一个磁盘失效时,系统可以自动切换到镜像磁盘上读写,而不需要重组失效的数据
RAID5:至少由3块硬盘组成,分布式奇偶校验的独立磁盘结构,它的奇偶校验码存在于所有磁盘上,任何一个硬盘损坏,都可以根据其它硬盘上的校验位来重建损坏的数据(最多允许1块硬盘损坏),所以raid5可以实现数据冗余,确保数据的安全性,同时raid5也可以提升数据的读写性能
RAID6:为了进一步提高存储的高可用,聪明的人们又提出了RAID6方案,可以在有两块磁盘同时损坏的情况下,也能保障数据可恢复。为什么RAID6这么牛呢,因为RAID6在RAID5的基础上再次改进,引入了双重校验的概念。RAID6除了每块磁盘上都有同级数据XOR校验区以外,还有针对每个数据块的XOR校验区,这样的话,相当于每个数据块有两个校验保护措施,因此数据的冗余性更高了。但是RAID6的这种设计也带来了很高的复杂度,虽然数据冗余性好,读取的效率也比较高,但是写数据的性能就很差。因此RAID6在实际环境中应用的比较少。
RAID10:兼备了RAID1和RAID0的有优点。首先基于RAID1模式将磁盘分为2份,当要写入数据的时候,将所有的数据在两份磁盘上同时写入,相当于写了双份数据,起到了数据保障的作用。且在每一份磁盘上又会基于RAID0技术讲数据分为N份并发的读写,这样也保障了数据的效率。但也可以看出RAID10模式是有一半的磁盘空间用于存储冗余数据的,浪费的很严重,因此用的也不是很多。
5.shell问题
1.获取apache/nginx 日志中访问最多的五个IP
tail -10000 /usr/local/nginx/logs/access.log | awk '{print $1}' | sort |uniq -c|sort -k1 -nr | head -5
6.如何查看系统负载
top命令(cpu和内存)
| 行数 | 信息 | 含义 |
|---|---|---|
| 第一行 | 16:44:26 | 当前时间 |
| up | 服务器运行时间 | |
| 1 user | 当前用户登录数 | |
| load average | 系统负载 分别表示1分钟,5分钟,15分钟前到现在的平均值。 | |
| 第二行 | 255 total | 服务器运行的进程总数 |
| 1 running | 正在运行的进程数 | |
| 254 sleep | 正在睡眠的进程数 | |
| 0stopped | 停止的进程数 | |
| 0zombie | 僵尸进程 | |
| 第三行 | 6.3us | 系统用户进程占用cpu百分比 |
| 1.6sy | 内核中进程占用cpu百分比 | |
| 0.0ni | 用户进程数空间内,改变过优先级的进程占用cpu的百分比 | |
| 92.1 id | 空闲cpu百分比 | |
| 0.0 wa | cpu等待i/o完成时间的总量 | |
| 0.0 hi | 硬中断占cpu百分比 | |
| 0.0 si | 软中断占cpu百分比 | |
| 0.0 st | 虚拟机占用物理机的时间 | |
| 第四行 | mem 15990504 total | 物理内存总量 |
| free | 空闲内存总内存量 | |
| used | 使用内存总内存量 | |
| buff/cache | 内核缓存的内存量 | |
| 第五行 | swap 0 total | 交换分区总量 |
| free | 交换分区空闲量 | |
| used | 交换分区使用量 | |
| avail mem | 总的可利用内存量 |
load average 其平均值和cpu逻辑核数成正比,当单核值>1时表示有些忙碌了,>3时表示负载已经比较高了。核数越多其值越高。
查看逻辑核心数 cat /proc/cpuinfo | grep ‘processor’ | sort | uniq | wc -l 2
第七行

iostat(磁盘负载)
-
-d:显示设备(磁盘)使用状态。
-
-k:表示让某些使用block为单位的列强制使用kB为单位。
-
2:数据显示每隔2秒刷新一次。
iostat -d -k 2
iotop(io负载)
这个效果和top命令相似,可以从进程的角度实时来查看io负载。
sar(网络)
sar可以从网络接口层面来分析数据包的收发情况、错误信息等。使用sar来监控网络流量的常用命令如下所示。(该命令也可以查看其它系统负载)
sar -n DEV [interval] [count] #interval参数是统计间隔,count参数是统计次数。

显示结果主要字段说明
-
IFACE:网络接口名称。
-
rxpck/s、txpck/s:每秒收或发的数据包数量。
-
rxkB/s、txkB/s:每秒收或发的字节数,以kB/s为单位。
-
rxcmp/s、txcmp/s:每秒收或发的压缩过的数据包数量。
-
rxmcst/s:每秒收到的多播数据包。
iftop(网络)
iftop命令常见用法如下。参数-i后跟的interface表示网络接口名,比如eth0、eth1等等。如果不通过-i参数指定接口名,则默认检测第一块网卡的使用情况。
iftop [-i interface]

-
第一行:带宽使用情况显示。
-
中间部分为外部连接列表,即记录了哪些IP正在和本机的网络连接。
-
中间部分靠右侧部分是实时流量信息,分别是该访问IP连接到本机2秒、10 秒和40秒的平均流量。
-
=>代表发送数据,<=代表接收数据。 -
底部三行。
-
第一列:TX表示发送流量,RX表示接收流量,TOTAL表示总流量。
-
第二列cum:表示第一列各种情况的总流量。
-
第三列peak:表示第一列各种情况的流量峰值。
-
第四列rates:表示第一列各种情况2秒、10秒、40秒内的平均流量。
-
iftop的流量显示单位是Mb,这里的b是比特(bit),不是字节(byte)。而ifstat显示的单位是KB中的B,也就是字节。1byte等于8bit。
ss和netstat(统计连接数)
ss命令用来替代netstat的,可以用来获取socket统计信息,它可以显示和netstat类似的内容。 但ss的优势在于它能够显示更多更详细的有关TCP和连接状态的信息,而且比netstat更快速更高效。
3.常用中间件相关
1.负载均衡
负载均衡的策略
轮询、权重、ip_hash绑定
负载均衡选择
LVS:是基于四层的转发
HAproxy:是基于四层和七层的转发,是专业的代理服务器
Nginx:是WEB服务器,缓存服务器,又是反向代理服务器,可以做七层的转发
区别:LVS由于是基于四层的转发所以只能做端口的转发、而基于URL的、基于目录的这种转发LVS就做不了
工作选择:HAproxy和Nginx由于可以做七层的转发,所以URL和目录的转发都可以做,在很大并发量的时候我们就要选择LVS,像中小型公司的话并发量没那么大,选择HAproxy或者Nginx足已,由于HAproxy由是专业的代理服务器,配置简单,所以中小型企业推荐使用HAproxy
2.redis
1.reidis的优缺点
redis的优点
-
数据存储在内存, 读写速度快,性能优异
-
支持数据持久化,便于数据备份、恢复
-
支持简单的事务,操作满足原子性
-
支持String、List、Hash、Set、Zset五种数据类型,满足多场景需求
-
支持主从复制,实现读写分离,分担读的压力
-
支持哨兵机制,实现自动故障转移
-
支持集群模式,实现高并发高可用
redis的缺点
-
数据存储在内存,主机断电则数据丢失
-
存储容量受到物理内存的限制,只能用于小数据量的高性能操作
-
在线扩容比较困难,系统上线时必须确保有足够的空间
-
用于缓存时,易出现’缓存雪崩‘,’缓存击穿‘等问题
2.高可用
持久化:持久化是最简单的高可用方法(有时甚至不被归为高可用的手段),主要作用是数据备份,即将数据存储在硬盘,保证数据不会因进程退出而丢失。
复制:复制是高可用Redis的基础,哨兵和集群都是在复制基础上实现高可用的。复制主要实现了数据的多机备份,以及对于读操作的负载均衡和简单的故障恢复。缺陷:故障恢复无法自动化;写操作无法负载均衡;存储能力受到单机的限制。
哨兵:在复制的基础上,哨兵实现了自动化的故障恢复。缺陷:写操作无法负载均衡;存储能力受到单机的限制。
集群:通过集群,Redis解决了写操作无法负载均衡,以及存储能力受到单机限制的问题,实现了较为完善的高可用方案。
3.数据类型
string 字符串
Hash 哈希
List 列表
set 集合
zset 有序集合
4.什么是Redis持久化?Redis有哪几种持久化方式?优缺点是什么?
持久化就是把内存的数据写到磁盘中去,防止服务宕机了内存数据丢失。
Redis 提供了两种持久化方式:RDB(默认) 和AOF
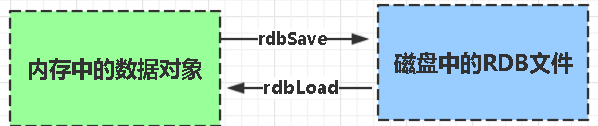
RDB
rdb是Redis DataBase缩写即内存快照
有全量快照和增量快照
功能核心函数rdbSave(生成RDB文件)和rdbLoad(从文件加载内存)两个函数
AOF
Aof是Append-only file缩写
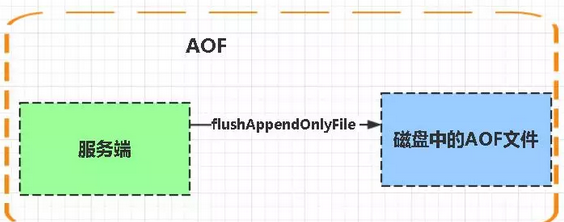
每当执行服务器(定时)任务或者函数时flushAppendOnlyFile 函数都会被调用, 这个函数执行以下两个工作
aof写入保存:
WRITE:根据条件,将 aof_buf 中的缓存写入到 AOF 文件
SAVE:根据条件,调用 fsync 或 fdatasync 函数,将 AOF 文件保存到磁盘中。
存储结构:
内容是redis通讯协议(RESP )格式的命令文本存储。
比较:
1、aof文件比rdb更新频率高,优先使用aof还原数据。
2、aof比rdb更安全也更大
3、rdb性能比aof好
4、如果两个都配了优先加载AOF
5.缓存穿透、缓存击穿、缓存雪崩及其解决方法
1.缓存击穿
什么是缓存击穿
缓存击穿是指当缓存中某个热点数据过期了,在该热点数据重新载入缓存之前,有大量的查询请求穿过缓存,直接查询数据库。这种情况会导致数据库压力瞬间骤增,造成大量请求阻塞,甚至直接挂掉。
缓存击穿的解决方案
解决缓存击穿的方法也有两种,第一种是设置key永不过期;第二种是使用分布式锁,保证同一时刻只能有一个查询请求重新加载热点数据到缓存中,这样,其他的线程只需等待该线程运行完毕,即可重新从Redis中获取数据。
第一种方式比较简单,在设置热点key的时候,不给key设置过期时间即可。不过还有另外一种方式也可以达到key不过期的目的,就是正常给key设置过期时间,不过在后台同时启一个定时任务去定时地更新这个缓存。

第二种方式使用了加锁的方式,锁的对象就是key,这样,当大量查询同一个key的请求并发进来时,只能有一个请求获取到锁,然后获取到锁的线程查询数据库,然后将结果放入到缓存中,然后释放锁,此时,其他处于锁等待的请求即可继续执行,由于此时缓存中已经有了数据,所以直接从缓存中获取到数据返回,并不会查询数据库。

2.缓存雪崩
什么是缓存雪崩
缓存雪崩是指当缓存中有大量的key在同一时刻过期,或者Redis直接宕机了,导致大量的查询请求全部到达数据库,造成数据库查询压力骤增,甚至直接挂掉。

缓存雪崩的解决方案
针对第一种大量key同时过期的情况,解决起来比较简单,只需要将每个key的过期时间打散即可,使它们的失效点尽可能均匀分布。
针对第二种redis发生故障的情况,部署redis时可以使用redis的几种高可用方案部署。
除了上面两种解决方式,还可以使用其他策略,比如设置key永不过期、加分布式锁等。
3.缓存穿透
什么是缓存穿透
缓存穿透是指查询一个缓存中和数据库中都不存在的数据,导致每次查询这条数据都会透过缓存,直接查库,最后返回空。当用户使用这条不存在的数据疯狂发起查询请求的时候,对数据库造成的压力就非常大,甚至可能直接挂掉。这种情况的流程就变成下图这样了:

缓存穿透解决方案
解决缓存穿透的方法一般有两种,第一种是缓存空对象,第二种是使用布隆过滤器。
第一种方法比较好理解,就是当数据库中查不到数据的时候,我缓存一个空对象,然后给这个空对象的缓存设置一个过期时间,这样下次再查询该数据的时候,就可以直接从缓存中拿到,从而达到了减小数据库压力的目的。
但这种解决方式有两个缺点:
(1)需要缓存层提供更多的内存空间来缓存这些空对象,当这种空对象很多的时候,就会浪费更多的内存;
(2)会导致缓存层和存储层的数据不一致,即使在缓存空对象时给它设置了一个很短的过期时间,那也会导致这一段时间内的数据不一致问题。
第二种方案是使用布隆过滤器,这是比较推荐的方法。
所谓布隆过滤器,就是一种数据结构,它是由一个长度为m bit的位数组与n个hash函数组成的数据结构,位数组中每个元素的初始值都是0。在初始化布隆过滤器时,会先将所有key进行n次hash运算,这样就可以得到n个位置,然后将这n个位置上的元素改为1。这样,就相当于把所有的key保存到了布隆过滤器中了。
布隆过滤器就相当于一个位于客户端与缓存层中间的拦截器一样,负责判断key是否在集合中存在。
布隆过滤器的好处就是解决了第一种缓存空值的不足,但布隆过滤器也存在缺陷,它有误判的可能。

6.redis为什么这么快?
◆纯内存操作
◆单线程操作,避免了频繁的上下文切换
◆采用了非阻塞 I/O 多路复用机制
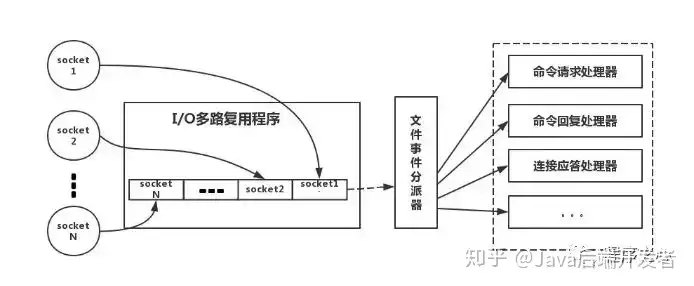
简单来说,就是我们的 redis-client 在操作的时候,会产生具有不同事件类型的 Socket。
在服务端,有一段 I/O 多路复用程序,将其置入队列之中。然后,文件事件分派器,依次去队列中取,转发到不同的事件处理器中。
7.Redis 的过期策略以及内存淘汰机制
1.比如你 Redis 只能存 5G 数据,可是你写了 10G,那会删 5G 的数据。怎么删的,这个问题思考过么?
答:Redis 采用的是定期删除+惰性删除策略。
2.为什么不用定时删除策略?
定时删除,用一个定时器来负责监视 Key,过期则自动删除。虽然内存及时释放,但是十分消耗 CPU 资源。
在大并发请求下,CPU 要将时间应用在处理请求,而不是删除 Key,因此没有采用这一策略。
3.定期删除+惰性删除是如何工作?
定期删除,Redis 默认每个 100ms 检查,是否有过期的 Key,有过期 Key 则删除。
需要说明的是,Redis 不是每个 100ms 将所有的 Key 检查一次,而是随机抽取进行检查(如果每隔 100ms,全部 Key 进行检查,Redis 岂不是卡死)。
因此,如果只采用定期删除策略,会导致很多 Key 到时间没有删除。于是,惰性删除派上用场。
惰性删除是指你获取某个 Key 的时候,Redis 会检查一下,这个 Key 如果设置了过期时间,那么是否过期了,如果过期了此时就会删除。
4.你的数据已经设置了过期时间,但是时间到了,内存占用率还是比较高,有思考过原因么?
答:如果定期删除没删除 Key。然后你也没即时去请求 Key,也就是说惰性删除也没生效。这样,Redis的内存会越来越高。那么就应该采用内存淘汰机制。
5.淘汰策略
当现有内存大于 maxmemory 时,便会触发redis主动淘汰内存方式,通过设置 maxmemory-policy ,有如下几种淘汰方式:
1)volatile-lru 利用LRU算法移除设置过过期时间的key (LRU:最近使用 Least Recently Used ) 。
2)allkeys-lru 利用LRU算法移除任何key (和上一个相比,删除的key包括设置过期时间和不设置过期时间的)。通常使用该方式。
3)volatile-random 移除设置过过期时间的随机key 。
4)allkeys-random 无差别的随机移除。
5)volatile-ttl 移除即将过期的key(minor TTL)
6)noeviction 不移除任何key,只是返回一个写错误 ,默认选项,一般不会选用。
8.Redis 和数据库双写一致性问题
一致性问题是分布式常见问题,还可以再分为最终一致性和强一致性。数据库和缓存双写,就必然会存在不一致的问题。
答这个问题,先明白一个前提。就是如果对数据有强一致性要求,不能放缓存。我们所做的一切,只能保证最终一致性。
另外,我们所做的方案从根本上来说,只能说降低不一致发生的概率,无法完全避免。因此,有强一致性要求的数据,不能放缓存。
回答:首先,采取正确更新策略,先更新数据库,再删缓存。其次,因为可能存在删除缓存失败的问题,提供一个补偿措施即可,例如利用消息队列。
3.mysql
1.主从复制
1.主从复制原理
在MySQL集群环境中,可以分为主节点与从节点,通过主从复制可以实现数据备份、故障转移、MySQL集群、高可用、读写分离等。
MySQL的主从复制是MySQL本身自带的一个功能,不需要额外的第三方软件就可以实现,其复制功能并不是copy文件来实现的,而是借助binlog日志文件里面的SQL命令实现的主从复制,可以理解为我再Master端执行了一条SQL命令,那么在Salve端同样会执行一遍,从而达到主从复制的,同步数据的效果。
Mysql 中有一种日志叫做 bin 日志(二进制日志)。这个日志会记录下所有修改了数据库的SQL 语句(insert,update,delete,create/alter/drop table, grant 等等)从库生成两个线程,一个I/O线程,一个SQL线程; i/o线程去请求主库 的binlog,并将得到的binlog日志写到relay log(中继日志) 文件中;
主库会生成一个 log dump 线程,用来给从库 i/o线程传binlog; SQL 线程,会读取relay log文件中的日志,并解析成具体操作,来实现主从的操作一致,而最终数据一致;
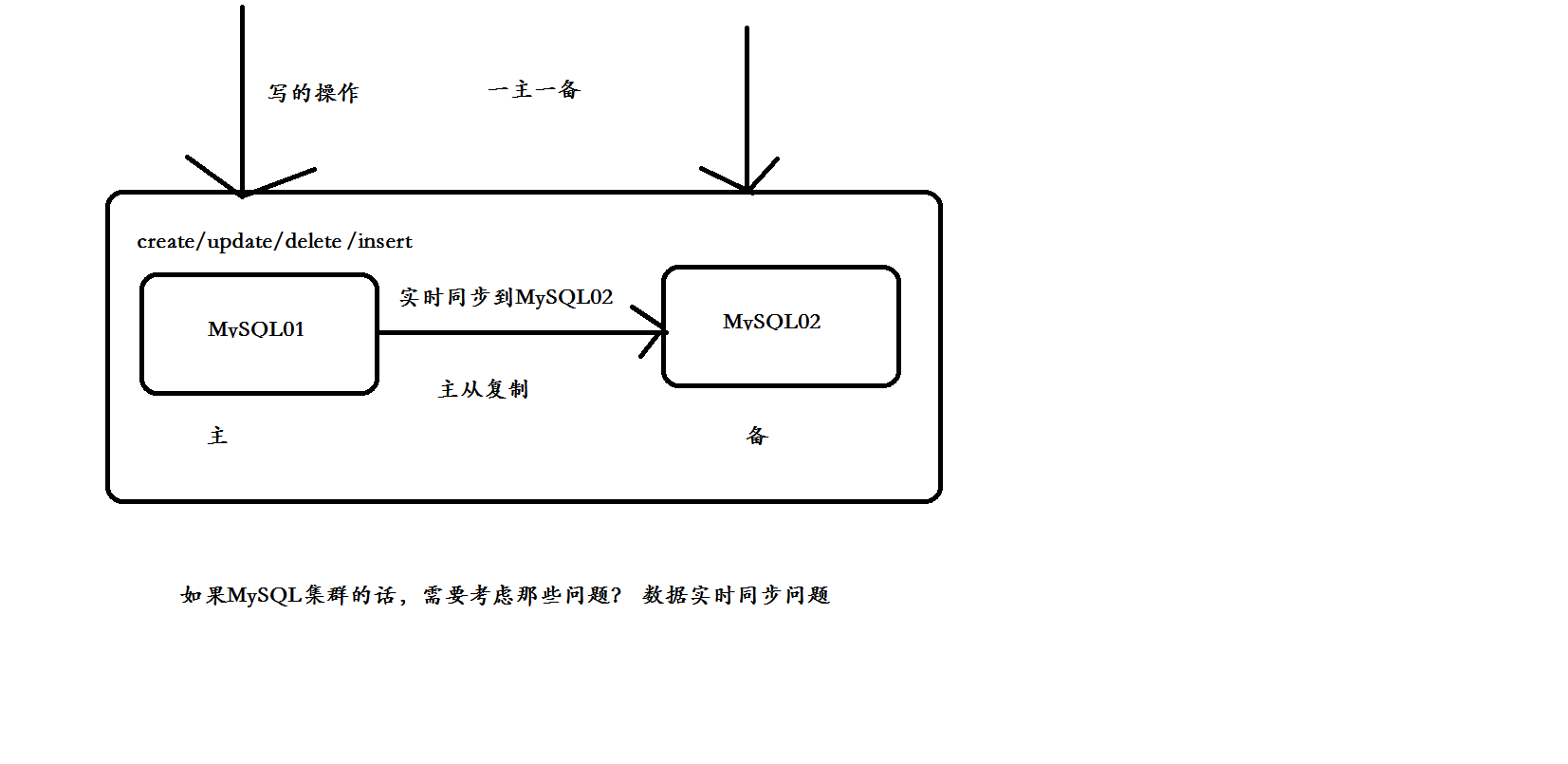


主从复制类型
1、 基于语句的复制:
在主服务器上执行的sql语句,在从服务器上会执行同样的语句。Mysql默认采用基于语句的复制,效率比较高,但是有时不能实现精准复制。
#2, 基于行的复制:
把改变的内容复制过去,而不是把命令在从服务器上执行一遍。
#3、 混合类型的复制:
默认采用基于语句的复制,一旦发现基于语句的复制不能精准复制时,就会采用基于行的复制。
2.复制过程
-
1、主节点必须启用二进制日志,记录任何修改了数据库数据的事件。
-
2、从节点开启一个线程(I/O Thread)把自己扮演成 mysql 的客户端,通过 mysql 协议,请求主节点的二进制日志文件中的事件
-
3、主节点启动一个线程(dump Thread),检查自己二进制日志中的事件,跟对方请求的位置对比,如果不带请求位置参数,则主节点就会从第一个日志文件中的第一个事件一个一个发送给从节点。
-
4、从节点接收到主节点发送过来的数据把它放置到中继日志(Relay log)文件中。并记录该次请求到主节点的具体哪一个二进制日志文件内部的哪一个位置(主节点中的二进制文件会有多个,在后面详细讲解)。
-
5、从节点启动另外一个线程(sql Thread ),把 Relay log 中的事件读取出来,并在本地再执行一次。
3.mysql复制特点
1、异步复制:主节点中一个用户请求一个写操作时,主节点不需要把写的数据在本地操作完成同时发送给从服务器并等待从服务器反馈写入完成,再响应用户。
主节点只需要把写入操作在本地完成,就响应用户。但是,从节点中的数据有可能会落后主节点,可以使用(很多软件来检查是否落后)
2、主从数据不一致。
4.主从复制的延迟问题
问题产生的原因
我们知道, 一个服务器开放N个链接给客户端来连接的, 这样有会有大并发的更新操作, 但是从服务器的里面读取binlog 的线程仅有一个, 当某个SQL在从服务器上执行的时间稍长 或者由于某个SQL要进行锁表就会导致,主服务器的SQL大量积压,未被同步到从服务器里。这就导致了主从不一致, 也就是主从延迟。
判断方法
MySQL提供了从服务器状态命令,可以通过 show slave status 进行查看, 比如可以看看Seconds_Behind_Master参数的值来判断,是否有发生主从延时。
其值有这么几种:
NULL - 表示io_thread或是sql_thread有任何一个发生故障,也就是该线程的Running状态是No,而非Yes.
0 - 该值为零,是我们极为渴望看到的情况,表示主从复制状态正常
解决方法
实际上主从同步延迟根本没有什么一招制敌的办法, 因为所有的SQL必须都要在从服务器里面执行一遍,但是主服务器如果不断的有更新操作源源不断的写入, 那么一旦有延迟产生, 那么延迟加重的可能性就会原来越大。 当然我们可以做一些缓解的措施。
a. 我们知道因为主服务器要负责更新操作, 他对安全性的要求比从服务器高, 所有有些设置可以修改,比如sync_binlog=1,innodb_flush_log_at_trx_commit = 1 之类的设置,而slave则不需要这么高的数据安全,完全可以讲sync_binlog设置为0或者关闭binlog,innodb_flushlog,innodb_flush_log_at_trx_commit 也 可以设置为0来提高sql的执行效率 这个能很大程度上提高效率。另外就是使用比主库更好的硬件设备作为slave。
b. 就是把,一台从服务器当度作为备份使用, 而不提供查询, 那边他的负载下来了, 执行relay log 里面的SQL效率自然就高了。
c. 增加从服务器喽,这个目的还是分散读的压力, 从而降低服务器负载。
5.主从数据库的区别
从数据库(Slave)是主数据库的备份,当主数据库(Master)变化时从数据库要更新,这些数据库软件可以设计更新周期。这是提高信息安全的手段。主从数据库服务器不在一个地理位置上,当发生意外时数据库可以保存。
(1) 主从分工
其中Master负责写操作的负载,也就是说一切写的操作都在Master上进行,而读的操作则分摊到Slave上进行。这样一来的可以大大提高读取的效率。在一般的互联网应用中,经过一些数据调查得出结论,读/写的比例大概在 10:1左右 ,也就是说大量的数据操作是集中在读的操作,这也就是为什么我们会有多个Slave的原因。但是为什么要分离读和写呢?熟悉DB的研发人员都知道,写操作涉及到锁的问题,不管是行锁还是表锁还是块锁,都是比较降低系统执行效率的事情。我们这样的分离是把写操作集中在一个节点上,而读操作其其他的N个节点上进行,从另一个方面有效的提高了读的效率,保证了系统的高可用性。
(2) 基本过程
-
1)、Mysql的主从同步就是当master(主库)发生数据变化的时候,会实时同步到slave(从库)。
-
2)、主从复制可以水平扩展数据库的负载能力,容错,高可用,数据备份。
-
3)、不管是delete、update、insert,还是创建函数、存储过程,都是在master上,当master有操作的时候,slave会快速的接受到这些操作,从而做同步。
(3) 用途和条件
1)、mysql主从复制用途
-
实时灾备,用于故障切换
-
读写分离,提供查询服务
-
备份,避免影响业务
2)、主从部署必要条件:
-
主库开启binlog日志(设置log-bin参数)
-
主从server-id不同
-
从库服务器能连通主库
6.mysql复制的形式
mysql主从复制 灵活
-
一主一从
-
主主复制
-
一主多从---扩展系统读取的性能,因为读是在从库读取的;
-
多主一从---5.7开始支持
-
联级复制---

7.主从复制--异步复制原理、半同步复制和并行复制原理比较


并行复制
-
社区版5.6中新增
-
并行是指从库多线程apply binlog
-
库级别并行应用binlog,同一个库数据更改还是串行的(5.7版并行复制基于事务组)设置set global slave_parallel_workers=10;设置sql线程数为10
原理:从库多线程apply binlog在社区5.6中新增库级别并行应用binlog,同一个库数据更改还是串行的5.7版本并行复制基于事务组
8.MySql数据库从库同步其他问题及解决方案
1)、mysql主从复制存在的问题:
-
主库宕机后,数据可能丢失
-
从库只有一个sql Thread,主库写压力大,复制很可能延时
2)、解决方法:
-
半同步复制---解决数据丢失的问题
-
并行复制----解决从库复制延迟的问题
3)、半同步复制mysql semi-sync(半同步复制)半同步复制:
-
5.5集成到mysql,以插件的形式存在,需要单独安装
-
确保事务提交后binlog至少传输到一个从库
-
不保证从库应用完这个事务的binlog
-
性能有一定的降低,响应时间会更长
-
网络异常或从库宕机,卡主主库,直到超时或从库恢复
2.读写分离
1.目前常见的读写分离方式
1、 基于中间代理层实现
代理一般位于客户端和服务器之间,代理服务器接收到客户端请求后通过判断后转发到后端数据库。如下有两个常用代理:
*MyCat
2012年,阿里巴巴开源Cobar;2013年,Leaderus 基于Cobar开发出 Mycat,功能:读写分离,读负载均衡,高可用(心跳检测,故障切换),垂直拆分(分库),水平分片(分表)。
需要部署,自己及运维一套中间件,运维成本高,但是好处在于对于各个项目是透明的,如果遇到升级之类的都是自己中间件那里搞就行了。
Amoeba
由陈思儒开发,该程序由Java语言进行开发。这个软件致力于mysql的分布式数据库前端代理层,它主要为应用层访问mysql的时候充当sql路由功能。Amoeba能够完成多数据源的高可用、负载均衡、数据切片等功能。
Mysql-proxy
其为mysql的开源项目,通过其自带的lua脚本进行sql判断,虽然是mysql官方产品,但是mysql官方并不建议其使用到生产环境中。
*sharding-jdbc
SQL语法支持较多,支持分库分表、读写分离、分布式id生成、柔性事务(最大努力送达型事务、TCC事务)。现在已经升级为Apache组织的项目。
这种client层方案的优点:
不用部署,运维成本低,无需代理层的二次转发请求,性能很高
但遇到升级啥的需要各个系统都重新升级版本再发布,各个系统都需要耦合sharding-jdbc的依赖。
选型
推荐使用sharding-jdbc和mycat:
-
小型公司选用sharding-jdbc,client层方案轻便,而且维护成本低,不需要额外增派人手,而且中小型公司系统复杂度会低一些,项目也没那么多
-
中大型公司最好还是选用mycat这类proxy层方案,因为可能大公司系统和项目非常多,团队很大,人员充足,那么最好是专门弄个人来研究和维护mycat,然后大量项目直接透明使用即可
2、 基于程序代码的内部实现
在代码中根据select、insert进行路由分类,这类方法也是目前生产环境中较为常用的,优点是性能较好,因为在程序代码中实现,不需要增加额外的设备作为硬件开支;缺点是需要研发人员来实现,运维人员无从下手。
springboot 框架中提供了很好的支撑。
2.MyCat介绍
1.功能和原理
功能:读写分离,读负载均衡,高可用(心跳检测,故障切换),垂直拆分(分库),水平分片(分表)
原理:作为代理,拦截SQL语句,做特定的分析(分片分析、路由分析、读写分离分析、缓存分析等),然后将此SQL发往后端的真实数据库,并将返回的结果做适当的处理,最终再返回给用户
2.概念
-
逻辑仓库:schema,客户端看到的db
-
主备仓库:dataNode,主从数据库集群里的同名(主备)db
-
主从集群:dataHost,主从数据库集群master-slave
-
具体数据库:writeHost,readHost,实际存储数据的rds
3.分库分表
分库分表,又分为垂直拆分和水平拆分。
水平拆分:统一个表的数据拆到不同的库不同的表中。可以根据时间、地区、或某个业务键维度,也可以通过hash进行拆分,最后通过路由访问到具体的数据。拆分后的每个表结构保持一致。
垂直拆分:就是把一个有很多字段的表给拆分成多个表,或者是多个库上去。每个库表的结构都不一样,每个库表都包含部分字段。
常见分表、分库常用策略:
1)平均进行分配hash(object)%N(适用于简单架构)。
2)按照权重进行分配且均匀轮询。
3)按照业务进行分配。
4)按照一致性hash算法进行分配(适用于集群架构,在集群中节点的添加和删除不会造成数据丢失,方便数据迁移)。
3.慢sql
4.备份与恢复
备份与恢复的概述
按照是否能够继续提供服务,将数据库备份类型划分为:
热备份:(在线备份)在数据库运行的过程中进行备份,并且不影响数据库的任何操作
温备份:能读不能写,在数据运行的过程中进行备份,但是对数据有影响,如需要加全局锁保证数据的一致性。
冷备份:(离线备份)在停止数据库的情况下,复制备份数据库的物理文件。
按照备份后文件的内容分类:
逻辑备份:备份文件时可读的文本文件,比如sql语句,适合数据库的迁移和升级,但是恢复时间比较长。
裸文件备份:复制数据库的物理文件
按照备份数据库的内容分类:
完全备份:对数据库进行一个完整的备份
增量备份:在完全备份的基础上,对数据库的增量进行备份
日志备份:只要是对binlog的备份
冷备份
xtrabackup 可以实现
只需要备份mysql数据库的frm文件,共享表空间文件,独立表空间文件(*.ibd),重做日志文件,以及msyql的配置文件my.cnf。
优点:
-
备份简单,只需要复制文件就可以
-
恢复简单,只需要把文件恢复到指定位置
-
恢复速度快,
缺点:
-
备份文件较大,因为表空间存在大量的其他数据,比如undo段,插入缓冲等
-
不能总是轻易跨平台
逻辑备份
mysqldump
使用方法
mysqldump -uroot -p123456 -A -r all.sql #备份所有数据库
mysqldump -uroot -p123456 -A > all.sql #备份所有数据库
mysqldump -uroot -p123456 -B test test1 > db_test.sql #备份test和test1数据库
mysqldump -uroot -p123456 --single-transaction -A > all.sql #innodb开始事务备份所有数据
mysqldump -uroot -p123456 --default-character-set=latin1 -A > all.sql #指定字符集备份所有数据
mysqldump -uroot -p123456 --tables test gxt1 -r gxt.sql #备份test库的gxt1表
mysqldump工具使用建议
1.从性能考虑:在需要导出大量数据的时候,使用--quick选项可以加速导出,但导入速度不变。如果是innodb表,则可以同时加上--no-autocommit选项,这样大量数据量导入时将极大提升性能。
2.一致性考虑:对于innodb表,几乎没有理由不用--single-transaction选项。对于myisam表,使用--lock-all-tables选项要好于--lock-tables。既有innodb又有myisam表时,可以分开导出,又能保证一致性,还能保证效率。
3.方便管理和维护性考虑:在导出时flush log很有必要。加上--flush-logs选项即可。而且一般要配合--lock-all-tables选项或者--single-transaction选项一起使用,因为同时使用时,只需刷新一次日志即可,并且也能保证一致性。同时,还可以配合--master-data=2,这样就可以方便地知道二进制日志中备份结束点的位置。
4.字符集考虑:如果有表涉及到了中文数据,在dump时,一定要将dump的字符集设置的和该表的字符集一样。
5.杂项考虑:备份过程中会产生二进制日志,但是这是没有必要的。所以在备份前可以关掉,备份完后开启。set sql_log_bin=0关闭,set sql_log_bin=1开启。
msyqldump结合binlog日志实现增量备份
-
1、首先全备:mysqldump -uroot -p123456 -q --no-autocommit --flush-logs --single-transaction --master-data=2 --tables test gxt1 > gxt.sql
-
2、修改表中的数据:insert into test.gxt1 values(1,'王麻子');
-
3、备份二进制日志:mysqlbinlog mysql-bin.000002 >new_gxt.sql #这里需要指定时间或者指定position对增量进行备份
-
4、模拟删掉:drop table test.gxt1;
-
5、恢复:
mysql>use test;
mysql>source gxt.sql;
mysql>source new_gxt.sql;
恢复备份的库中特定一个或多个表
假设你有一个名为 backup.sql 的备份文件,其中包含多个数据库和表的备份,你要恢复其中的一个名为 my_database 的数据库,可以使用如下命令:
mysql --one-database my_database < backup.sql
mysql --one-database my_database --tables table1 table2 table3 < backup.sql
总结:
msyqldump是属于逻辑备份,备份sql语句,简单,但是由于恢复时都是通过insert进行插入,所有恢复速度慢,mysqldump备份myisam表时因为要加--lock-all-tables,这时要备份的数据库全部被上锁,可读不可写,所以实现的是温备。
mysqldump备份innodb表时因为要加--single-transaction,会自动将隔离级别设置为repeatable read并开启一个事务,这时mysqldump将获取dump执行前一刻的行版本,并处于一个长事务中直到dump结束。所以不影响目标数据库的使用,可读也可写,即实现的是热备
5.MySQL 数据库管理 + 密码破解 (用户管理+日志管理+数据乱码解决)
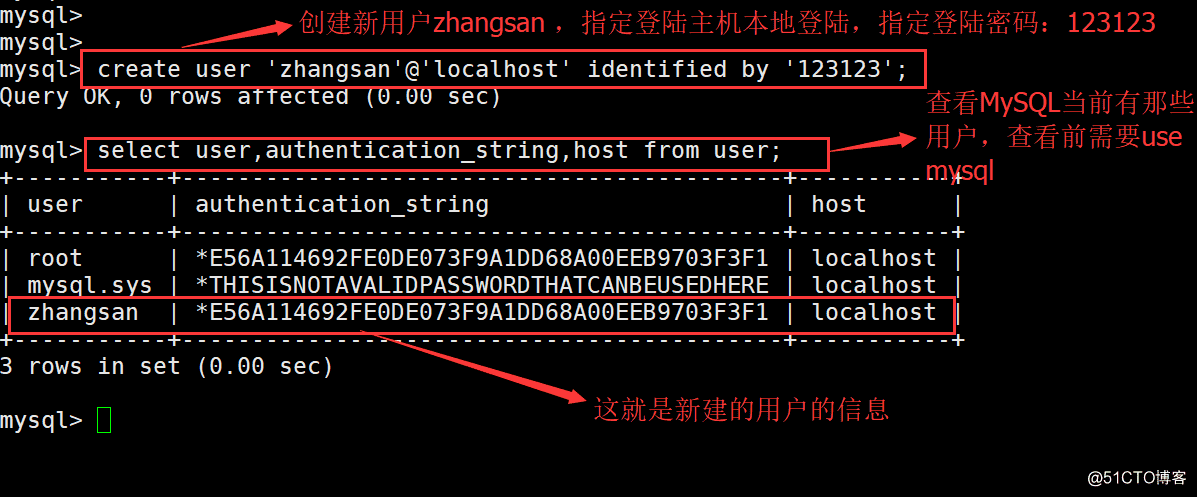
1.新建用户
新建用户的命令格式: CREATE USER ‘username’@‘host’ INDETIFIED BY PASSWORD ‘password’;
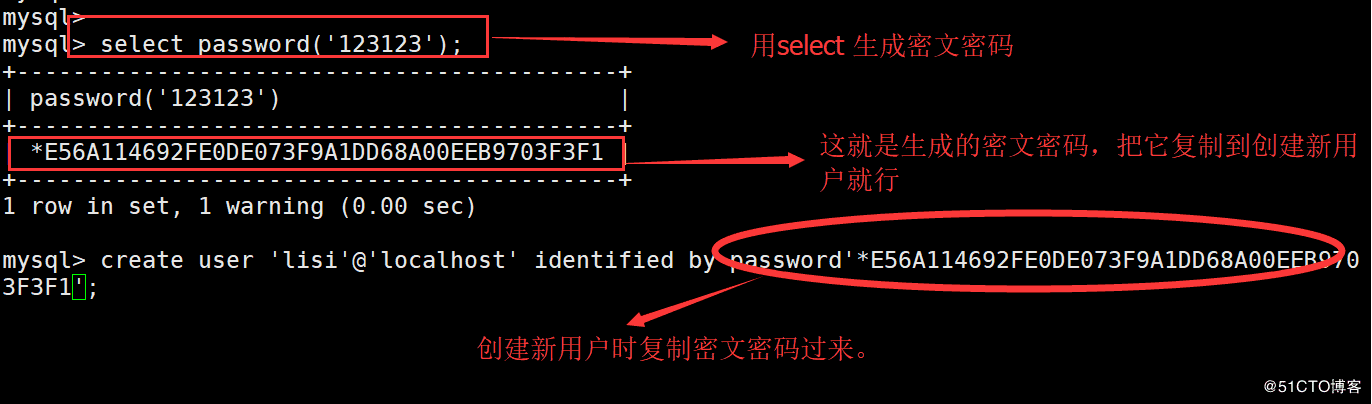
2.使用密文作为密码
mysql> select password(‘123123’);-----用select 生成一段密文密码 ±+ | password(‘123123’) | ±+ | *E56A114692FE0DE073F9A1DD68A00EEB9703F3F1 | ±+ 1 row in set, 1 warning (0.00 sec)
mysql> create user ‘lisi’@‘localhost’ identified by password’*E56A114692FE0DE073F9A1DD68A00EEB9703F3F1’;
3.删除用户
删除用户命令格式: DROP USER ‘删除的用户名’@‘允许登陆的地点’;

4.重命名用户
重命名用户的格式: RENMAE USER ‘旧用户名’@‘登陆地点’ TO ‘新用户名’@‘登陆地点’;
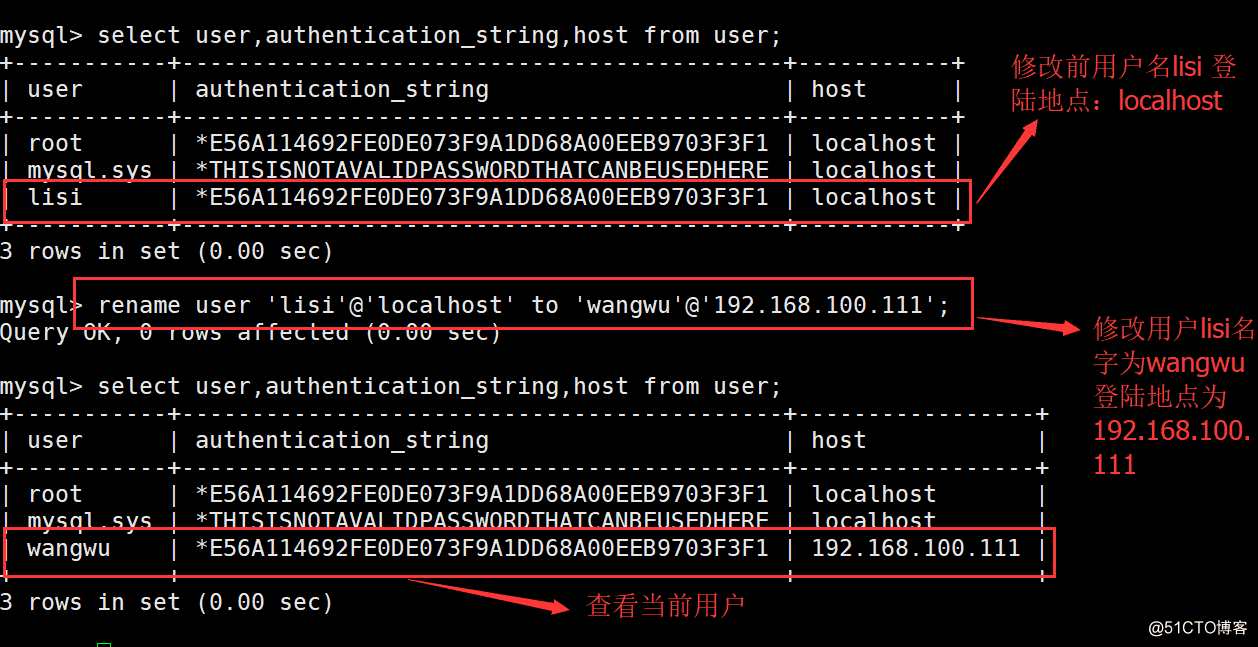
5·修改用户登陆密码
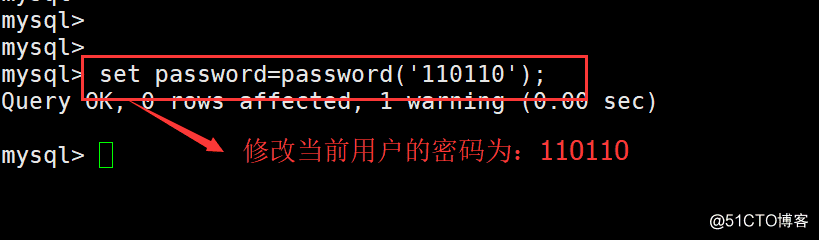
(1)修改当前登陆用户密码命令格式: SET PASSWORD=PASSWORD(‘密码’);
(2)修改其他用户密码命令格式: SET PASSWORD FOR ‘需要修改的用户’@‘登陆地点’=PASSWORD(‘密码’);

6.mysql5.7密码破解
[root@localhost ~]# systemctl stop mysqld.service (停止mysql服务)
[root@localhost ~]# vim /etc/my.cnf --(进入主配置文件)
#[mysqld] 加入以下一段话,跳过密码登陆 skip-grant-tables
[root@localhost ~]# systemctl start mysqld.service (启动mysql服务)
[root@localhost ~]# mysql -uroot ----(使用root用户登陆,可以不用密码)
mysql> update mysql.user set authentication_string=password(‘123123’) where user=‘root’; ---(这样修改root 密码)
[root@localhost ~]# vim /etc/my.cnf ——(进入主配置文件删除skip-grant-tables)
[root@localhost ~]# systemctl restart mysqld.service ——(重启服务)

7.授权控制
1· 授予权限使用命令 grant 命令,
GRANT 给予的权限 ON 库名.表名 TO ‘用户名’@‘登陆的主机’ IDENTIFIED BY ‘密码’;
这里需要注意的是,如果在MySQL中没有wangwu这个用户,则创建用户;如果存在则修改权限,并且密码也同时修改。

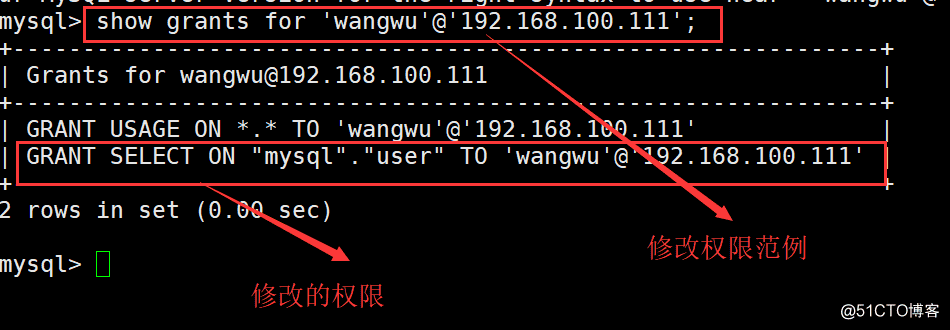
2.查看权限
查看用户拥有的权限命令格式如下: SHOW GRANTS FOR ‘用户名’@‘登陆主机’;
3.撤销权限
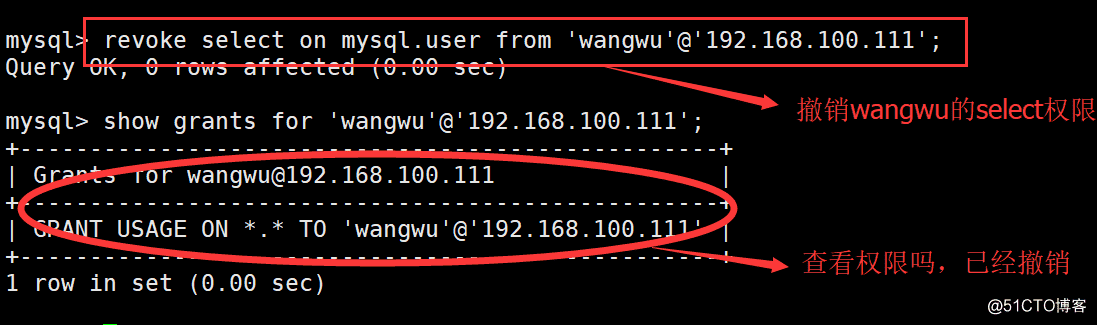
使用 REVOKE 语句可以撤销指定用户的权限,格式如下: REVOKE 撤销的权限 ON 数据库名.表名 FROM ‘用户’@‘登陆地址’;
这里需要注意的是:如果需要撤销所有权限则使用,all 关键字。
MySQL 日志管理:
1·错误日志:
主要记录当MySQL 启动和停止时,以及运行中发生任何错误的 相关信息,默认路径保存在 MySQL的安装路径data 文件下。在MySQL配置文件中,可以指定日志文件的保存位子和日志的文件名。log_error=file_name 选项来指定保存错误日志的文件位子。
2·通用查询日志
(1)通用查询日志用来记录MySQL的所有连接和语句,默认是关闭的。使用show 语句可以查询出日志信息。 mysql> show variables like ‘general%’; -----(查询通用日志状态,是否关闭和路径)
(2)修改MySQL配置文件的 general_log=ON 选项,可以打开通用查询通用日志,general_log_file=存放路径,定义日志位子
3·二进制日志
(1)二进制日志用来记录所有更新了数据或者已经在更新数据的语句,记录了数据的变更,它的主要目的是在恢复数据是能够最大成都的恢复数据库,它默认是开启的,在data 文件下,数据量大时,它会自动分割成多个文件,以数值作为扩展名。
(2)因为是 二进制 文件,所以只有机器能识别,人要识别,需要使用MySQL的工具 mysqlbinlog 查看二进制文件 mysqlbinlog --no-defaults mysql-bin.000001 -----(查看二进制格式范例)
4·慢日志
慢日志记录所有执行时间超过 long_query_time 秒的SQL 语句,用于找到哪些查询语句执行时间长,以便对其进行优化。默认慢查询日志是关闭的。可以在MySQL主配置文件 使用 slow_query_log=ON 开启慢日志查询
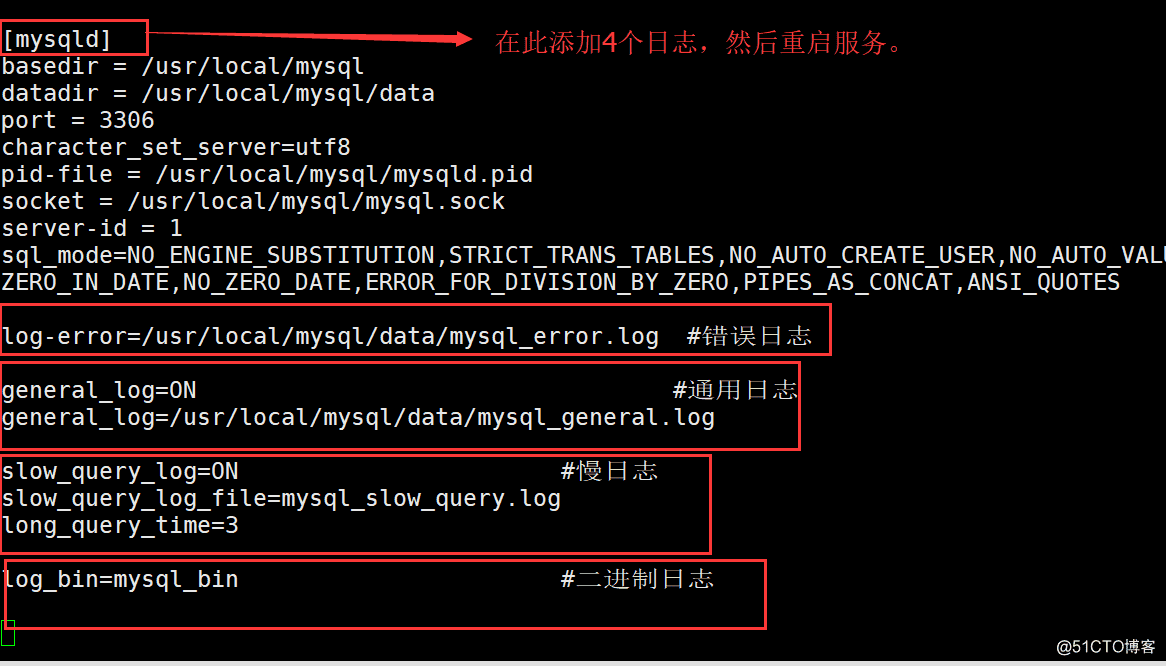
MySQL数据乱码:
乱码产生原因:
1·服务器系统字符设置问题
2·数据表语设置的问题。
3·客户端连接语系问题
UTF-8是可变储存长度的字符集,如英文字母只需要一个字节,节省了存储空间,所以数据库中通常采用 UTF-8的字符集。
MySQL 乱码解决方法:
(1)对于MySQL服务器,只要设置存储的字符集为 UTF-8,对应的客户端也使用相同编码,就不会产生乱码。
(2)修改MySQL配置文件时,在 [client] 部分,加入选项 default-character-set=utf8 ,可以设置字符集,这样就可以统一数据库的字符集,重启后字符集生效,如果有其他的字符集需要使用,再特殊指定。

总结:
1·MySQL 创建用户需要指定权限,all 代表所有权限。
2·忘记 root 密码,可以跳过权限表,登陆MySQL 修改密码。
3·MySQL 日志包括:错误日志、通用查询日志、二进制日志、慢查询日志。
4·MySQL 乱码问题可以采用指定字符集 UTF-8 来解决
数据库三大范式是什么
-
第一范式:每个列都不可以再拆分。
-
第二范式:在第一范式的基础上,非主键列完全依赖于主键,而不能是依赖于主键的一部分。
-
第三范式:在第二范式的基础上,非主键列只依赖于主键,不依赖于其他非主键。
4.prometheus
1.prometheus数据持久化
答:像平时我们使用prometheus-operator部署在K8S中是默认使用挂载pvc的方式进行持久化存储的。如果不是部署在K8S中的话,prometheus也提供了一些长期存储方案,像Thanos、Grafana Mimir等。
2.prometheus遇到大规模集群怎么办?(跨区域聚合计算)
答:可以用prometheus federation(联邦),使用多个prometheus server来收集数据然后数据汇聚到Global prometheus中进行计算和存储。
3.超大规模的prometheus集群
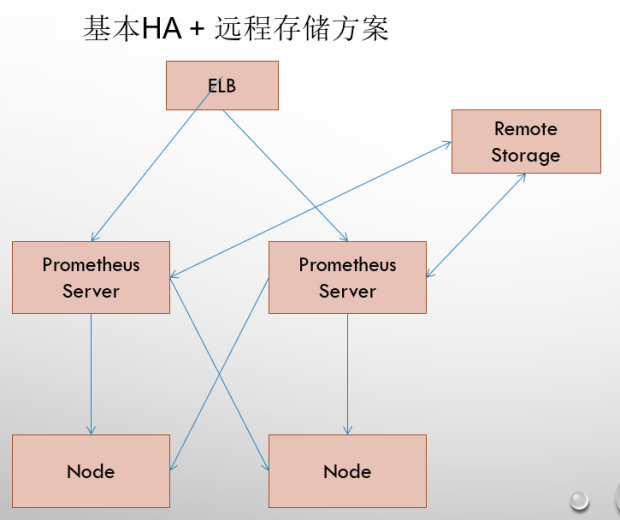
在解决了Promthues服务可用性的基础上,同时确保了数据的持久化,当Promthues Server发生宕机或者数据丢失的情况下,可以快速的恢复。 同时Promthues Server可能很好的进行迁移。因此,该方案适用于用户监控规模不大,但是希望能够将监控数据持久化,同时能够确保Promthues Server的可迁移性的场景。
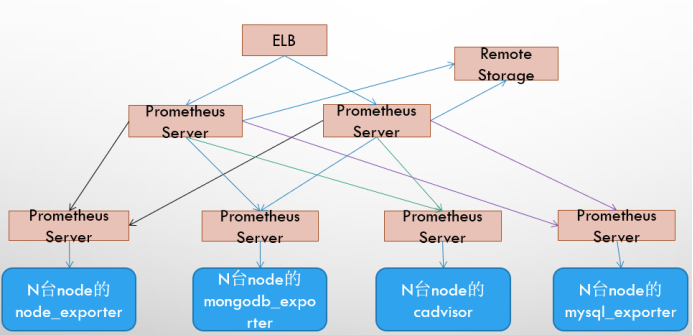
Promthues的性能瓶颈主要在于大量的采集任务,因此用户需要利用Prometheus联邦集群的特性,将不同类型的采集任务划分到不同的Promthues子服务中,从而实现功能分区。例如一个Promthues Server负责采集基础设施相关的监控指标,另外一个Prometheus Server负责采集应用监控指标。再有上层Prometheus Server实现对数据的汇聚。
4.Prometheus的4种数据类型
1、Counter
Counter是计数器类型:
-
Counter 用于累计值,例如记录请求次数、任务完成数、错误发生次数。
-
一直增加,不会减少。
-
重启进程后,会被重置。
# Counter类型示例
http_response_total{method="GET",endpoint="/api/tracks"} 100
http_response_total{method="GET",endpoint="/api/tracks"} 160
Counter 类型数据可以让用户方便的了解事件产生的速率的变化,在PromQL内置的相关操作函数可以提供相应的分析,比如以HTTP应用请求量来进行说明
1)通过rate()函数获取HTTP请求量的增长率:rate(http_requests_total[5m])
2)查询当前系统中,访问量前10的HTTP地址:topk(10, http_requests_total)
2、Gauge
Gauge是测量器类型:
-
Gauge是常规数值,例如温度变化、内存使用变化。
-
可变大,可变小。
-
重启进程后,会被重置
# Gauge类型示例
memory_usage_bytes{host="master-01"} 100
memory_usage_bytes{host="master-01"} 30
memory_usage_bytes{host="master-01"} 50
memory_usage_bytes{host="master-01"} 80
对于 Gauge 类型的监控指标,通过 PromQL 内置函数 delta() 可以获取样本在一段时间内的变化情况,例如,计算 CPU 温度在两小时内的差异: dalta(cpu_temp_celsius{host="zeus"}[2h])
你还可以通过PromQL 内置函数 predict_linear() 基于简单线性回归的方式,对样本数据的变化趋势做出预测。例如,基于 2 小时的样本数据,来预测主机可用磁盘空间在 4 个小时之后的剩余情况:predict_linear(node_filesystem_free{job="node"}[2h], 4 * 3600) < 0
3、Histogram
3.1、Histogram作用及特点
histogram是柱状图,在Prometheus系统的查询语言中,有三种作用:
1)在一段时间范围内对数据进行采样(通常是请求持续时间或响应大小等),并将其计入可配置的存储桶(bucket)中. 后续可通过指定区间筛选样本,也可以统计样本总数,最后一般将数据展示为直方图。
2)对每个采样点值累计和(sum)
3)对采样点的次数累计和(count)
度量指标名称: [basename]上面三类的作用度量指标名称
1)[basename]bucket{le="上边界"}, 这个值为小于等于上边界的所有采样点数量
2)[basename]_sum_
3)[basename]_count
小结:如果定义一个度量类型为Histogram,则Prometheus会自动生成三个对应的指标
3.2、为什需要用histogram柱状图
在大多数情况下人们都倾向于使用某些量化指标的平均值,例如 CPU 的平均使用率、页面的平均响应时间。这种方式的问题很明显,以系统 API 调用的平均响应时间为例:如果大多数 API 请求都维持在 100ms 的响应时间范围内,而个别请求的响应时间需要 5s,那么就会导致某些 WEB 页面的响应时间落到中位数的情况,而这种现象被称为长尾问题。 为了区分是平均的慢还是长尾的慢,最简单的方式就是按照请求延迟的范围进行分组。例如,统计延迟在 0~10ms 之间的请求数有多少,而 10~20ms 之间的请求数又有多少。通过这种方式可以快速分析系统慢的原因。Histogram 和 Summary 都是为了能够解决这样问题的存在,通过 Histogram 和 Summary 类型的监控指标,我们可以快速了解监控样本的分布情况。
Histogram 类型的样本会提供三种指标(假设指标名称为 <basename>):
1)样本的值分布在 bucket 中的数量,命名为 <basename>_bucket{le="<上边界>"}。解释的更通俗易懂一点,这个值表示指标值小于等于上边界的所有样本数量。
# 1、在总共2次请求当中。http 请求响应时间 <=0.005 秒 的请求次数为0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.005",} 0.0
# 2、在总共2次请求当中。http 请求响应时间 <=0.01 秒 的请求次数为0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.01",} 0.0
# 3、在总共2次请求当中。http 请求响应时间 <=0.025 秒 的请求次数为0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.025",} 0.0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.05",} 0.0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.075",} 0.0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="7.5",} 2.0
# 4、在总共2次请求当中。http 请求响应时间 <=10 秒 的请求次数为 2
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="10.0",} 2.0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="+Inf",} 2.0
2)所有样本值的大小总和,命名为 <basename>_sum
# 实际含义: 发生的2次 http 请求总的响应时间为 13.107670803000001 秒
io_namespace_http_requests_latency_seconds_histogram_sum{path="/",method="GET",code="200",} 13.107670803000001
3)样本总数,命名为 <basename>_count,值和 <basename>_bucket{le="+Inf"} 相同
# 实际含义: 当前一共发生了 2 次 http 请求
io_namespace_http_requests_latency_seconds_histogram_count{path="/",method="GET",code="200",} 2.0
注意: 1)bucket 可以理解为是对数据指标值域的一个划分,划分的依据应该基于数据值的分布。注意后面的采样点是包含前面的采样点的,假设 xxx_bucket{...,le="0.01"} 的值为 10,而 xxx_bucket{...,le="0.05"} 的值为 30,那么意味着这 30 个采样点中,有 10 个是小于 0.01s的,其余 20 个采样点的响应时间是介于0.01s 和 0.05s之间的。
2)可以通过 histogram_quantile() 函数来计算 Histogram 类型样本的分位数。分位数可能不太好理解,你可以理解为分割数据的点。我举个例子,假设样本的 9 分位数(quantile=0.9)的值为 x,即表示小于 x 的采样值的数量占总体采样值的 90%。Histogram 还可以用来计算应用性能指标值(Apdex score)。
4、Summary
与 Histogram 类型类似,用于表示一段时间内的数据采样结果(通常是请求持续时间或响应大小等),但它直接存储了分位数(通过客户端计算,然后展示出来),而不是通过区间来计算。它也有三种作用:
1)对于每个采样点进行统计,并形成分位图。(如:正态分布一样,统计低于60分不及格的同学比例,统计低于80分的同学比例,统计低于95分的同学比例)
2)统计班上所有同学的总成绩(sum)
3)统计班上同学的考试总人数(count)
带有度量指标的[basename]的summary 在抓取时间序列数据有如命名。
1、观察时间的φ-quantiles (0 ≤ φ ≤ 1), 显示为[basename]{分位数="[φ]"}
2、[basename]_sum, 是指所有观察值的总和_
3、[basename]_count, 是指已观察到的事件计数值
样本值的分位数分布情况,命名为 <basename>{quantile="<φ>"}。
# 1、含义:这 12 次 http 请求中有 50% 的请求响应时间是 3.052404983s
io_namespace_http_requests_latency_seconds_summary{path="/",method="GET",code="200",quantile="0.5",} 3.052404983
# 2、含义:这 12 次 http 请求中有 90% 的请求响应时间是 8.003261666s
io_namespace_http_requests_latency_seconds_summary{path="/",method="GET",code="200",quantile="0.9",} 8.003261666
所有样本值的大小总和,命名为 <basename>_sum。
# 1、含义:这12次 http 请求的总响应时间为 51.029495508s
io_namespace_http_requests_latency_seconds_summary_sum{path="/",method="GET",code="200",} 51.029495508
样本总数,命名为 <basename>_count。
# 1、含义:当前一共发生了 12 次 http 请求
io_namespace_http_requests_latency_seconds_summary_count{path="/",method="GET",code="200",} 12.0
Histogram 与 Summary 的异同:
它们都包含了 <basename>_sum 和 <basename>_count 指标,Histogram 需要通过 <basename>_bucket 来计算分位数,而 Summary 则直接存储了分位数的值。
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.5"} 0.012352463
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.9"} 0.014458005
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.99"} 0.017316173
prometheus_tsdb_wal_fsync_duration_seconds_sum 2.888716127000002
prometheus_tsdb_wal_fsync_duration_seconds_count 216
# 从上面的样本中可以得知当前Promtheus Server进行wal_fsync操作的总次数为216次,耗时2.888716127000002s。其中中位数(quantile=0.5)的耗时为0.012352463,9分位数(quantile=0.9)的耗时为0.014458005s。
5.prometheus能监控什么?
# Databases---数据库
Aerospike exporter
ClickHouse exporter
Consul exporter (official)
Couchbase exporter
CouchDB exporter
ElasticSearch exporter
EventStore exporter
Memcached exporter (official)
MongoDB exporter
MSSQL server exporter
MySQL server exporter (official)
OpenTSDB Exporter
Oracle DB Exporter
PgBouncer exporter
PostgreSQL exporter
ProxySQL exporter
RavenDB exporter
Redis exporter
RethinkDB exporter
SQL exporter
Tarantool metric library
Twemproxy
# Hardware related---硬件相关
apcupsd exporter
Collins exporter
IBM Z HMC exporter
IoT Edison exporter
IPMI exporter
knxd exporter
Netgear Cable Modem Exporter
Node/system metrics exporter (official)
NVIDIA GPU exporter
ProSAFE exporter
Ubiquiti UniFi exporter
# Messaging systems---消息服务
Beanstalkd exporter
Gearman exporter
Kafka exporter
NATS exporter
NSQ exporter
Mirth Connect exporter
MQTT blackbox exporter
RabbitMQ exporter
RabbitMQ Management Plugin exporter
# Storage---存储
Ceph exporter
Ceph RADOSGW exporter
Gluster exporter
Hadoop HDFS FSImage exporter
Lustre exporter
ScaleIO exporter
# HTTP---网站服务
Apache exporter
HAProxy exporter (official)
Nginx metric library
Nginx VTS exporter
Passenger exporter
Squid exporter
Tinyproxy exporter
Varnish exporter
WebDriver exporter
# APIs
AWS ECS exporter
AWS Health exporter
AWS SQS exporter
Cloudflare exporter
DigitalOcean exporter
Docker Cloud exporter
Docker Hub exporter
GitHub exporter
InstaClustr exporter
Mozilla Observatory exporter
OpenWeatherMap exporter
Pagespeed exporter
Rancher exporter
Speedtest exporter
# Logging---日志
Fluentd exporter
Google's mtail log data extractor
Grok exporter
# Other monitoring systems
Akamai Cloudmonitor exporter
Alibaba Cloudmonitor exporter
AWS CloudWatch exporter (official)
Cloud Foundry Firehose exporter
Collectd exporter (official)
Google Stackdriver exporter
Graphite exporter (official)
Heka dashboard exporter
Heka exporter
InfluxDB exporter (official)
JavaMelody exporter
JMX exporter (official)
Munin exporter
Nagios / Naemon exporter
New Relic exporter
NRPE exporter
Osquery exporter
OTC CloudEye exporter
Pingdom exporter
scollector exporter
Sensu exporter
SNMP exporter (official)
StatsD exporter (official)
# Miscellaneous---其他
ACT Fibernet Exporter
Bamboo exporter
BIG-IP exporter
BIND exporter
Bitbucket exporter
Blackbox exporter (official)
BOSH exporter
cAdvisor
Cachet exporter
ccache exporter
Confluence exporter
Dovecot exporter
eBPF exporter
Ethereum Client exporter
Jenkins exporter
JIRA exporter
Kannel exporter
Kemp LoadBalancer exporter
Kibana Exporter
Meteor JS web framework exporter
Minecraft exporter module
PHP-FPM exporter
PowerDNS exporter
Presto exporter
Process exporter
rTorrent exporter
SABnzbd exporter
Script exporter
Shield exporter
SMTP/Maildir MDA blackbox prober
SoftEther exporter
Transmission exporter
Unbound exporter
Xen exporter
# Software exposing Prometheus metrics---Prometheus度量指标
App Connect Enterprise
Ballerina
Ceph
Collectd
Concourse
CRG Roller Derby Scoreboard (direct)
Docker Daemon
Doorman (direct)
Etcd (direct)
Flink
FreeBSD Kernel
Grafana
JavaMelody
Kubernetes (direct)
Linkerd
6.prometheus-operator有哪些资源对象
1:*Prometheus:表示一个 Prometheus 集群,由一组规则、服务发现和其他配置项组成
2:*Alertmanager:表示一个告警管理器,负责接收来自 Prometheus 的告警并进行处理,可以进行去重、分组、静默等处理,并支持以邮件、Slack、Webhook 等形式发送告警信息。
3:*ServiceMonitor:使用标签选择来定义哪儿些Service被选择进行监控,这可以让团队制定一个如何暴露监控指标的规范,然后按照这些规范自动发现新的服务,而无需重新配置。
4:*PodMonitor: 使用标签选择来定义哪儿些Pods被选择进行监控,同样团队中可以制定一些规范来暴露监控的指标。
5:Probe: 表示一个可用性探测,类似于 Prometheus 的 Blackbox Exporter,可以对 HTTP、TCP、ICMP 等协议的网络端点进行探测并记录指标数据。
6:*ThanosRuler::表示一个 Thanos Ruler 集群,Thanos 是一个分布式的 Prometheus 存储方案,通过 Thanos Ruler 可以实现 Prometheus 指标数据的水平扩展和数据持久化。
7:PrometheusRule:用于配置 Prometheus 的 Rule 规则文件,包括 recording rules 和 alerting,可以自动被 Prometheus 加载。
8:AlertmanagerConfig:表示告警管理器的配置,可以包括路由规则、静默期、SMTP 等配置。
7.kube-state-metrics 在大规模集群下的优化
当我们使用 Prometheus 来监控 Kubernetes 集群的时候,kube-state-metrics(KSM) 基本属于一个必备组件,它通过 Watch APIServer 来生成资源对象的状态指标,它并不会关注单个 Kubernetes 组件的健康状况,而是关注各种资源对象的健康状态,比如 Deployment、Node、Pod、Ingress、Job、Service 等等,每种资源对象中包含了需要指标,我们可以在官方文档 https://github.com/kubernetes/kube-state-metrics/tree/main/docs 处进行查看。
我们以deployment方式来部署一个KMS然后只需要让 Prometheus 来发现 KSM 实例就可以了,当然有很多方式,比如可以通过添加注解来自动发现,也可以单独为 KSM 创建一个独立的 Job,如果使用的是 Prometheus Operator,也可以创建 ServiceMonitor 对象来获取 KSM 指标数据。这种方式对于小规模集群是没太大问题的,数据量不大,可以正常提供服务,只需要保证 KSM 高可用就可以在生产环境使用了。但是对于大规模的集群来说,就非常困难了。
我们需要从KSM端入手解决,优化方案又三种:
1.通过修改KSM的启动参数,过滤掉一些不需要的指标。
可以通过 --metric-allowlist 或者 --metric-denylist 参数进行过滤。
但是如果即使过滤了不需要的指标或标签后指标接口数据仍然非常大又该怎么办呢?
2.分片处理
其实我们可以想象一下,无论怎么过滤,请求一次到达 metrics 接口后的数据量都是非常大的,这个时候是不是只能对指标数据进行拆分了,可以部署多个 KSM 实例,每个实例提供一部分接口数据,是不是就可以缓解压力了,这其实就是我们常说的水平分片。为了水平分片 kube-state-metrics,它已经实现了一些自动分片功能,它是通过以下标志进行配置的:
--shard (从 0 开始)
--total-shards
分片是通过对 Kubernetes 对象的 UID 进行 MD5 哈希和对总分片数进行取模运算来完成的,每个分片决定是否由 kube-state-metrics 的相应实例处理对象。不过需要注意的是,kube-state-metrics 的所有实例,即使已经分片,也会处理所有对象的网络流量和资源消耗,而不仅仅是他们负责那部分对象,要优化这个问题,Kubernetes API 需要支持分片的 list/watch 功能。在最理想的情况下,每个分片的内存消耗将比未分片设置少 1/n。通常,为了使 kube-state-metrics 能够迅速返回其指标给 Prometheus,需要进行内存和延迟优化。减少 kube-state-metrics 和 kube-apiserver 之间的延迟的一种方法是使用 --use-apiserver-cache 标志运行 KSM,除了减少延迟,这个选项还将导致减少对 etcd 的负载,所以我们也是建议启用该参数的。
由于手动去配置分片可能会出现错误,所以 KSM 也提供了自动分片的功能,可以通过 StatefulSet 方式来部署多个副本的 KSM,自动分片允许每个分片在 StatefulSet 中部署时发现其实例位置,这对于自动配置分片非常有用。所以要启用自动分片,必须通过 StatefulSet 运行 kube-state-metrics,并通过 --pod 和 --pod-namespace 标志将 pod 名称和命名空间传递给 kube-state-metrics 进程
当然使用自动分片的部署方式也是有缺点的,主要是来自于 StatefulSet 支持的滚动升级策略,当由 StatefulSet 管理时,一个一个地替换 pod,当 pod 先被终止后,然后再重新创建,这样的升级速度较慢,也可能会导致每个分片的短暂停机,如果在升级期间进行 Prometheus 抓取,则可能会错过 kube-state-metrics 导出的某些指标。
3.每个节点单独分片
此外我们还可以单独针对 pod 指标按照每个节点进行分片,只需要加上 --node 和 --resource 即可,这个时候我们直接使用一个 DaemonSet 来创建 KSM 实例即可。
5.elasticSearch
1.es数据量特别大的时候怎么处理?(数据清理)
答:删除elasticsearch数据分为两种:一种是删除索引(数据和表结构同时删除,作用同sql server 中 drop table "表格名"),另一种是删除数据(不删除表结构,作用同 sql server中delete 语句)。一般会写一个定时任务来清理过期的索引。
2.es日志量比较大时应该怎么划分索引
当 ES 集群中的索引数据量比较大时,需要考虑如何进行索引的设计以提高查询性能和减少存储空间。
一些索引设计策略:
1.时间分片索引
将索引按时间分片,每个时间段使用一个索引。这样可以更好地控制每个索引的大小,减少索引的数据冗余,并在查询时只查询需要的时间段。
2.索引字段选择
仅将需要搜索和聚合的字段添加到索引中,避免将无用的字段添加到索引中造成存储浪费和查询缓慢。
3.索引压缩
可以使用 Elasticsearch 提供的索引压缩功能来压缩索引大小。这样可以减少磁盘空间的使用,并提高查询性能。
4.副本分片
在 ES 集群中设置副本分片可以提高集群的容错性和可用性。但是,在索引数据量较大时,副本分片可能会增加查询响应时间。因此,建议在设计索引时仔细考虑副本分片数量。
5.分区
在 ES 中,可以将索引分成多个分区,每个分区由一个或多个分片组成。可以根据业务需求来决定索引的分区数量,从而提高查询性能和可扩展性。
6.索引缓存
可以使用 Elasticsearch 的索引缓存功能来缓存常用的索引数据,从而加快查询速度。索引缓存可以减少对磁盘的读取操作,提高查询性能。
6.ansible
ansible是一个自动化运维工具,基于Python开发,集合了众多运维工具(puppet、cfengine、chef、func、fabric)的优点,实现了批量系统配置、批量程序部署、批量运行命令等功能。
特性
无客户端:不使用时系统开销为0
无服务器:直接运行命令
基于模块工作:可以使用任何语言开放自定义模块
yaml:使用yaml语言定制playbook-
默认基于ssh工作
幂等性:多次运行,结果不变
架构
ansible是基于模块工作的,本身没有批量部署的能力。真正具有批量部署的是ansible所运行的模块,ansible只是提供一种框架。主要包括:
-
核心:ansible
-
核心模块(Core Modules):这些都是 ansible 自带的模块
-
扩展模块(Custom Modules):如果核心模块不足以完成某种功能,可以添加扩展模块
-
插件(Plugins):完成模块功能的补充
-
剧本(Playbooks):ansible 的任务配置文件,将多个任务定义在剧本中,由 ansible 自动执行
-
连接插件(Connectior Plugins):ansible 基于连接插件连接到各个主机上,虽然 ansible 是使用 ssh 连接到各个主机的,但是它还支持其他的连接方法,所以需要有连接插件
-
主机清单(Host Inventory):定义 ansible 管理的主机

ansible配置
-
配置文件 (1)ansible应用程序的主配置文件:/etc/ansible/ansible.cfg (2) Host Inventory定义管控主机:/etc/ansible/hosts
Ansible 可以同时操作一个组的多台主机。组和主机之间的关系通过inventory文件 配置。默认路径为/etc/ansible/hosts。
基本定义
mail.example.com <==直接指定某个主机
[webservers] <==组名
foo.example.com <==组成员
bar.example.com <==组成员
[dbservers] <==组名
one.example.com:9527 <==指定非标准ssh端口
foo.example.com <==同一台主机,可以属于多个组
172.16.80.100 <==直接用主机IP
批量host简写
[webservers]
www[1:50].example.com <==简写数字范围
db-[a:f].example.com <==简写字母范围
定义主机和变量
[atlanta]
host1 http_port=80 maxRequestsPerChild=808
host2 http_port=303 maxRequestsPerChild=909
组和变量
[web]
192.168.182.130
192.168.182.110
[mysql]
192.168.182.111
#子分组
[nfs:children]
web
mysql
#对分组定义统一变量
[nfs:vars]
http_port=8080
https_port=443
ansible_ssh_user=root
ansible_ssh_pass=123456
ansible_ssh_port=22
主机账号密码
# 默认主机配置文件:/etc/ansible/hosts
192.168.182.130 ansible_ssh_user=root ansible_ssh_pass=123456
[web]
192.168.182.130 ansible_ssh_user=root ansible_ssh_pass=123456

ansible常用模块
获取模块列表:ansible-doc -l
常用模块:
1、 command模块
在远程主机运行命令 如:ansible webservers -m command -a "/sbin/reboot -t now"
2、shell模块
在远程主机在shell进程下运行命令,支持shell特性,如管道等 。command的不支持重定向、管道。
3、copy模块
从本地主机拷贝文件到远程、主机
-
参数 dest=(远程主机上路径) src=(本地主机路径) content=(直接指明内容) owner= group= mode=
-
用法:
-
指明源文件路基、目标文件路径
ansible 172.16.80.101 -m copy -a 'src=/etc/hosts dest=/app/hosts' -
指明文件内容、目标文件路径
ansible 172.16.80.101 -m copy -a 'content=hello dest=/app/helloword'
-
4、cron模块
管理crontab
-
参数 minute= day= month= weekday= hour= job= *name= state= present(创建)或者absent(删除)
-
用法
ansible all -m cron -a 'name='Time' state=present minute='\*/5' job='/usr/sbin/ntpdate 172.168.0.1 &> /dev/null''
5、fetch模块
从远程主机上取文件
6、file模块
设置文件属性
-
用法 (1) 创建链接文件:*path= src= state=link (2) 修改属性:path= owner= mode= group= (3) 创建目录:path= state=directory
ansible all -m file -a 'path=/tmp/testdir state=directory'
7、yum模块
你懂的
-
参数 name=:程序包名称,可以带版本号; state=present、latest、absent
8、service模块
管理服务
-
参数 *name= state=started、stopped、restarted enabled= runlevel=
9、user模块
-
参数 *name= system= uid= shell= group= groups= comment= home=
10、script模块
-
用法
ansible all -m script -a '/tmp/a.sh'
11、setup模块
获取远程主机的facts
-
用法
ansible all -m setup
12、raw模块
raw 模块 [类似于 command 模块、支持管道传递]。
ansible web -m raw -a "ifconfig eth0 |sed -n 2p |awk '{print \$2}' |awk -F: '{print \$2}'"
13、unarchive 模块(解包模块)
-
copy——默认为 yes,当 copy=yes,那么拷贝的文件是从 ansible 主机复制到远程主机上的,如果设置为 copy=no,那么会在远程主机上寻找 src 源文件。 -
src——源路径,可以是 ansible 主机上的路径,也可以是远程主机上的路径,如果是远程主机上的路径,则需要设置 copy=no。 -
dest——远程主机上的目标路径。 -
mode——设置解压缩后的文件权限。
ansible 192.168.182.129 -m unarchive -a 'src=/testdir/ansible/data.tar.gz dest=/tmp/tmp/'
14、archive 模块(打包模块)
ansible 192.168.182.129 -m archive -a 'path=/tmp/ format=gz dest=/tmp/tmp/t.tar.gz'
playbook
更强大的地方在于,在 playbooks 中可以编排有序的执行过程,甚至于做到在多组机器间,来回有序的执行特别指定的步骤,并且可以同步或异步的发起任务。
我们使用 ad-hoc 时,主要是使用 /usr/bin/ansible 程序执行任务。而使用 playbooks 时,更多是将之放入源码控制之中,用之推送你的配置或是用于确认你的远程系统的配置是否符合配置规范。
核心元素:
-
Hosts:主机
-
Tasks:任务列表
-
Variables:变量
-
Templates:包含了模板语法的文本文件;
-
Handlers:由特定条件触发的任务;
-
Roles:角色
Task列表
每一个 play 包含了一个 tasks 列表(任务列表),每个task拥有一个name和module。
tasks: <==任务列表
- name: ensure apache is at the latest version <==任务1的名字
yum: pkg=httpd state=latest <==任务1具体执行的内容
- name: write the apache config file <==任务2的名字
template: src=/srv/httpd.j2 dest=/etc/httpd.conf
notify:
- restart apache
- name: ensure apache is running <==任务3的名字
service: name=httpd state=started
name 由于注释这个task的功能,这样在运行 playbook 时,从其输出的任务执行信息中可以很好的辨别出是属于哪一个 task 的。如果没有定义 name,‘action’ 的值将会用作输出信息中标记特定的 task。
modules 通过调用上述的command、shell、copy、cron、file、yum等模块执行的动作
-
执行顺序 tasks从上到下执行 需要注意的是,在这play中的所有主机,全部主机执行完一个task,才会继续执行下一个task。 比如webservers 有两台主机web1和web2。当web1执行任务2失败,那么web1就会从整个playbook的rotation(轮转)中移除。
-
幂等性 重复多次执行 playbook 的结果是一样的
Variables
(1)变量命名:字母、数字和下划线组成,只能以字母开头; (2)变量类型:
-
(a) facts:可直接调用,通过setup模块直接获取目标主机的facters
-
(b)Inventory中定义变量,这些变量直接传递给单个主机。具体定义格式,请参考上面Inventory的内容。
-
(c)playbook中定义变量
-
(d) 在roles定义变量
playbook定义变量格式:
- hosts: webservers
vars:
http_port: 80
变量引用:{{ variable }}
Templates:包含了模板语法的文本文件;
Handlers:由特定条件触发的任务;
roles角色
ansible如果不用免密登录和密钥怎么连接服务器?
Ansible 支持使用密码进行连接,您可以在 ansible.cfg 文件中设置相关参数:
[defaults]
remote_user = <username>
ask_pass = True
在运行 playbook 时,Ansible 将询问您输入密码:
ansible-playbook <playbook.yml>
也可以将密码存储在 playbook 中,但这不是安全的做法。为了提高安全性,推荐使用密钥对进行连接。
7.nginx
为什么Nginx性能这么高?
因为他的事件处理机制:异步非阻塞事件处理机制:运用了epoll模型,提供了一个队列,排队解决
Nginx如何处理HTTP请求的?
它结合多进程机制(单线程)和异步非阻塞方式。
1、多进程机制(单线程)
服务器每当收到一个客户端时,就有 服务器主进程 ( master process )生成一个 子进程( worker process )出来和客户端建立连接进行交互,直到连接断开,该子进程就结束了。
2、异步非阻塞机制
每个工作进程 使用 异步非阻塞方式 ,可以处理 多个客户端请求 。 运用了epoll模型,提供了一个队列,排队解决。
当某个 工作进程 接收到客户端的请求以后,调用 IO 进行处理,如果不能立即得到结果,就去 处理其他请求 (即为 非阻塞 );而 客户端 在此期间也 无需等待响应 ,可以去处理其他事情(即为 异步 )。
当 IO 返回时,就会通知此 工作进程 ;该进程得到通知,暂时 挂起 当前处理的事务去 响应客户端请求 。
Nginx的master和worker是如何工作的?
1、Nginx 在启动后,会有一个 master 进程和多个相互独立的 worker 进程。
2、master 接收来自外界的信号,先建立好需要 listen 的 socket(listenfd) 之后,然后再 fork 出多个 worker 进程,然后向各worker进程发送信号,每个进程都有可能来处理这个连接。
3、所有 worker 进程的 listenfd 会在新连接到来时变得可读 ,为保证只有一个进程处理该连接,所有 worker 进程在注册 listenfd 读事件前抢占 accept_mutex ,抢到互斥锁的那个进程注册 listenfd 读事件 ,在读事件里调用 accept 接受该连接。
4、当一个 worker 进程在 accept 这个连接之后,就开始读取请求、解析请求、处理请求,产生数据后,再返回给客户端 ,最后才断开连接。
什么是正向代理和反向代理?
正向代理就是一个人发送一个请求直接就到达了目标的服务器
反方代理就是请求统一被Nginx接收,nginx反向代理服务器接收到之后,按照一定的规 则分发给了后端的业务处理服务器进行处理了
ngx_http_upstream_module模块了解吗?
ngx_http_upstream_module模块用于将多个服务器定义成服务器组,可通过fastcgi传递、proxy传递、uwsgi传递、memcached传递和scgi传递指令来引用的服务器组。
Nginx的优缺点?
优点:
-
占内存小,可实现高并发连接,处理响应快
-
可实现http服务器、虚拟主机、方向代理、负载均衡
-
Nginx配置简单
-
可以不暴露正式的服务器IP地址
缺点: 动态处理差:nginx处理静态文件好,耗费内存少,但是处理动态页面则很鸡肋,现在一般前端用nginx作为反向代理抗住压力,
如何用Nginx解决前端跨域问题?
使用Nginx转发请求。把跨域的接口写成调本域的接口,然后将这些接口转发到真正的请求地址。
限流怎么做的?
Nginx 提供两种限流方式,一是控制速率,二是控制并发连接数。
-
Nginx限流就是限制用户请求速度,防止服务器受不了
-
限流有3种
-
正常限制访问频率(正常流量)
-
突发限制访问频率(突发流量)
-
限制并发连接数
-
-
Nginx的限流都是基于漏桶流算法,底下会说道什么是桶铜流
实现三种限流算法
正常限制访问频率(正常流量):
-
限制一个用户发送的请求,我Nginx多久接收一个请求。
-
Nginx中使用ngx_http_limit_req_module模块来限制的访问频率,限制的原理实质是基于漏桶算法原理来实现的。在nginx.conf配置文件中可以使用limit_req_zone命令及limit_req命令限制单个IP的请求处理频率。
#定义限流维度,一个用户一分钟一个请求进来,多余的全部漏掉
limit_req_zone $binary_remote_addr zone=one:10m rate=1r/m;
#绑定限流维度
server{
location/seckill.html{
limit_req zone=zone;
proxy_pass http://lj_seckill;
}
}
-
1r/s代表1秒一个请求,1r/m一分钟接收一个请求, 如果Nginx这时还有别人的请求没有处理完,Nginx就会拒绝处理该用户请求。
突发限制访问频率(突发流量):
-
限制一个用户发送的请求,我Nginx多久接收一个。
-
上面的配置一定程度可以限制访问频率,但是也存在着一个问题:如果突发流量超出请求被拒绝处理,无法处理活动时候的突发流量,这时候应该如何进一步处理呢?Nginx提供burst参数结合nodelay参数可以解决流量突发的问题,可以设置能处理的超过设置的请求数外能额外处理的请求数。我们可以将之前的例子添加burst参数以及nodelay参数:
#定义限流维度,一个用户一分钟一个请求进来,多余的全部漏掉
limit_req_zone $binary_remote_addr zone=one:10m rate=1r/m;
#绑定限流维度
server{
location/seckill.html{
limit_req zone=zone burst=5 nodelay;
proxy_pass http://lj_seckill;
}
}
-
为什么就多了一个 burst=5 nodelay; 呢,多了这个可以代表Nginx对于一个用户的请求会立即处理前五个,多余的就慢慢来落,没有其他用户的请求我就处理你的,有其他的请求的话我Nginx就漏掉不接受你的请求
限制并发连接数
-
Nginx中的ngx_http_limit_conn_module模块提供了限制并发连接数的功能,可以使用limit_conn_zone指令以及limit_conn执行进行配置。接下来我们可以通过一个简单的例子来看下:
http {
limit_conn_zone $binary_remote_addr zone=myip:10m;
limit_conn_zone $server_name zone=myServerName:10m;
}
server {
location / {
limit_conn myip 10;
limit_conn myServerName 100;
rewrite / http://www.lijie.net permanent;
}
}
上面配置了单个IP同时并发连接数最多只能10个连接,并且设置了整个虚拟服务器同时最大并发数最多只能100个链接。当然,只有当请求的header被服务器处理后,虚拟服务器的连接数才会计数。刚才有提到过Nginx是基于漏桶算法原理实现的,实际上限流一般都是基于漏桶算法和令牌桶算法实现的。
漏桶流算法和令牌桶算法知道?
漏桶算法
-
漏桶算法是网络世界中流量整形或速率限制时经常使用的一种算法,它的主要目的是控制数据注入到网络的速率,平滑网络上的突发流量。漏桶算法提供了一种机制,通过它,突发流量可以被整形以便为网络提供一个稳定的流量。也就是我们刚才所讲的情况。漏桶算法提供的机制实际上就是刚才的案例:
突发流量会进入到一个漏桶,漏桶会按照我们定义的速率依次处理请求,如果水流过大也就是突发流量过大就会直接溢出,则多余的请求会被拒绝。所以漏桶算法能控制数据的传输速率。
令牌桶算法
-
令牌桶算法是网络流量整形和速率限制中最常使用的一种算法。典型情况下,令牌桶算法用来控制发送到网络上的数据的数目,并允许突发数据的发送。Google开源项目Guava中的RateLimiter使用的就是令牌桶控制算法。令牌桶算法的机制如下:存在一个大小固定的令牌桶,会以恒定的速率源源不断产生令牌。如果令牌消耗速率小于生产令牌的速度,令牌就会一直产生直至装满整个令牌桶。
Nginx配置高可用性怎么配置?
-
当上游服务器(真实访问服务器),一旦出现故障或者是没有及时相应的话,应该直接轮训到下一台服务器,保证服务器的高可用
-
Nginx配置代码:
server {
listen 80;
server_name www.lijie.com;
location / {
### 指定上游服务器负载均衡服务器
proxy_pass http://backServer;
###nginx与上游服务器(真实访问的服务器)超时时间 后端服务器连接的超时时间_发起握手等候响应超时时间
proxy_connect_timeout 1s;
###nginx发送给上游服务器(真实访问的服务器)超时时间
proxy_send_timeout 1s;
### nginx接受上游服务器(真实访问的服务器)超时时间
proxy_read_timeout 1s;
index index.html index.htm;
}
}
8.tomcat
Tomcat是什么?
-
Tomcat 服务器Apache软件基金会项目中的一个核心项目,是一个免费的开放源代码的Web 应用服务器,属于轻量级应用服务器,在中小型系统和并发访问用户不是很多的场合下被普遍使用,是开发和调试JSP 程序的首选。
Tomcat的目录结构
/bin:存放用于启动和暂停Tomcat的脚本
/conf:存放Tomcat的配置文件
/lib:存放Tomcat服务器需要的各种jar包
/logs:存放Tomcat的日志文件
/temp:Tomcat运行时用于存放临时文件
/webapps:web应用的发布目录
/work:Tomcat把有jsp生成Servlet防御此目录下
tomcat 如何优化?
1.改Tomcat最大线程连接数 需要修改conf/server.xml文件,修改里面的配置文件: maxThreads=”150”//Tomcat使用线程来处理接收的每个请求。这个值表示Tomcat可 创建的最大的线程数。默认值200。可以根据机器的时期性能和内存大小调整,一般 可以在400-500。最大可以在800左右。
2.Tomcat内存优化,启动时告诉JVM我要多大内存 调优方式的话,修改: Windows 下的catalina.bat Linux 下的catalina.sh 修改方式如: JAVA_OPTS=’-Xms256m -Xmx512m’-Xms JVM初始化堆的大小-Xmx JVM堆的最大值 实际参数大
tomcat 有哪几种Connector 运行模式(优化)?
BIO:同步并阻塞 一个线程处理一个请求。缺点:并发量高时,线程数较多,浪费资源。Tomcat7或以下,在Linux系统中默认使用这种方式。 配制项:protocol=”HTTP/1.1”
NIO:同步非阻塞IO 利用Java的异步IO处理,可以通过少量的线程处理大量的请求,可以复用同一个线程处理多个connection(多路复用)。
Tomcat8在Linux系统中默认使用这种方式。 Tomcat7必须修改Connector配置来启动。 配制项:protocol=”org.apache.coyote.http11.Http11NioProtocol” 备注:我们常用的Jetty,Mina,ZooKeeper等都是基于java nio实现.
APR:即Apache Portable Runtime,从操作系统层面解决io阻塞问题。 AIO方式,异步非阻塞IO(Java NIO2又叫AIO) 主要与NIO的区别主要是操作系统的底层区别.可以做个比喻:比作快递,NIO就是网购后要自己到官网查下快递是否已经到了(可能是多次),然后自己去取快递;AIO就是快递员送货上门了(不用关注快递进度)。
配制项:protocol=”org.apache.coyote.http11.Http11AprProtocol” 备注:需在本地服务器安装APR库。Tomcat7或Tomcat8在Win7或以上的系统中启动默认使用这种方式。Linux如果安装了apr和native,Tomcat直接启动就支持apr。
9.mq
MQ的优点
异步处理 - 相比于传统的串行、并行方式,提高了系统吞吐量。
应用解耦 - 系统间通过消息通信,不用关心其他系统的处理。
流量削锋 - 可以通过消息队列长度控制请求量;可以缓解短时间内的高并发请求。
日志处理 - 解决大量日志传输。
消息通讯 - 消息队列一般都内置了高效的通信机制,因此也可以用在纯的消息通讯。比如实现点对点消息队列,或者聊天室等。
消息队列有什么缺点
缺点有以下几个:
-
系统可用性降低
本来系统运行好好的,现在你非要加入个消息队列进去,那消息队列挂了,你的系统不是呵呵了。因此,系统可用性会降低;
-
系统复杂度提高
加入了消息队列,要多考虑很多方面的问题,比如:一致性问题、如何保证消息不被重复消费、如何保证消息可靠性传输等。因此,需要考虑的东西更多,复杂性增大。
-
一致性问题
A 系统处理完了直接返回成功了,人都以为你这个请求就成功了;但是问题是,要是 BCD 三个系统那里,BD 两个系统写库成功了,结果 C 系统写库失败了,咋整?你这数据就不一致了。
10.数据同步
1.canal
4.devops相关
1.敏捷开发和devops的区别
DevOps 和敏捷有相似性,但是它们不完全相同,一些人认为 DevOps 比敏捷更好。为了避免造成混淆,深入地了解它们是很重要的。
相似之处
毫无疑问,两者都是软件开发技术。
敏捷已经存在了 20 多年,DevOps 是最近才出现的。
两者都追求软件的快速开发,它们的理念都基于怎样在不伤害客户或运维利益的情况下快速开发出软件。
不同之处
两者的差异在于软件开发完成后发生的事情。
在 DevOps 和敏捷中,都有软件开发、测试和部署的阶段。然而,敏捷流程在这三个阶段之后会终止。相反,DevOps 包括后续持续的运维。因此,DevOps 会持续的监控软件运行情况和进行持续的开发。
敏捷中,不同的人负责软件的开发、测试和部署。而 DevOps 工程角色负责所有活动,开发即运维,运维即开发。
DevOps 更关注于削减成本,而敏捷则是精益和减少浪费的代名词,侧重于像敏捷项目会计和最小可行产品的概念。
敏捷专注于并体现了经验主义(适应、透明和检查),而不是预测性措施。
2.devops与CICD
DevOps是一种思想,是一种文化,主要强调软件开发测试运维的一体化,目标是减少各个部门之间的沟通成本从而实现软件的快速高质量的发布。cicd是指持续集成发布部署,是一套流程实现软件的构建测试部署的自动化。
Devops更相当于理论思想,而cicd更偏向于实践。
devops的发展过程:
传统瀑布模型(Waterfall Development)
持续集成(Continuous Integration)
持续发布(Continuous Delivery)
持续部署(Continuous Deployment)
3.devops(ci/cd)工具有哪些
实现自动化的发布,主要需要如下类型的工具:
源代码管理
配置管理
容器编排
构建工具,分布式构建
测试框架
持续集成sever
artifact的管理工具
部署分发
监控工具
5.go相关
https://github.com/lifei6671/interview-go
https://learnku.com/articles/69250
https://learnku.com/blog/ssdlh
1.GPM调度模型
GPM代表了三个角色,分别是Goroutine、Processor、Machine。
Goroutine:就是咱们常用的用go关键字创建的执行体,它对应一个结构体g,结构体里保存了goroutine的堆栈信息
Machine:表示操作系统的线程
Processor:表示处理器,有了它才能建立G、M的联系
三者关系
首先,默认启动四个线程四个处理器,然后互相绑定。
这个时候,一个Goroutine结构体被创建,在进行函数体地址、参数起始地址、参数长度等信息以及调度相关属性更新之后,它就要进到一个处理器的队列等待发车。
啥,又创建了一个G?那就轮流往其他P里面放呗,相信你排队取号的时候看到其他窗口没人排队也会过去的。
假如有很多G,都塞满了怎么办呢?那就不把G塞到处理器的私有队列里了,而是把它塞到全局队列里(候车大厅)。
除了往里塞之外,M这边还要疯狂往外取,首先去处理器的私有队列里取G执行,如果取完的话就去全局队列取,如果全局队列里也没有的话,就去其他处理器队列里偷,哇,这么饥渴,简直是恶魔啊!
如果哪里都没找到要执行的G呢?那M就会因为太失望和P断开关系,然后去睡觉(idle)了。
那如果两个Goroutine正在通过channel做一些恩恩爱爱的事阻塞住了怎么办,难道M要等他们完事了再继续执行?显然不会,M并不稀罕这对Go男女,而会转身去找别的G执行。
系统调用
如果G进行了系统调用syscall,M也会跟着进入系统调用状态,那么这个P留在这里就浪费了,怎么办呢?这点精妙之处在于,P不会傻傻的等待G和M系统调用完成,而会去找其他比较闲的M执行其他的G。
当G完成了系统调用,因为要继续往下执行,所以必须要再找一个空闲的处理器发车。
如果没有空闲的处理器了,那就只能把G放回全局队列当中等待分配。
sysmon
sysmon是我们的保洁阿姨,它是一个M,又叫监控线程,不需要P就可以独立运行,每20us~10ms会被唤醒一次出来打扫卫生,主要工作就是回收垃圾、回收长时间系统调度阻塞的P、向长时间运行的G发出抢占调度等等。
2.对于已经关闭的chan进行读写会怎么样
读已经关闭的 chan 能一直读到东西,但是读到的内容根据通道内关闭前是否有元素而不同。
如果 chan 关闭前,buffer 内有元素还未读 , 会正确读到 chan 内的值,且返回的第二个 bool 值(是否读成功)为 true。
如果 chan 关闭前,buffer 内有元素已经被读完,chan 内无值,接下来所有接收的值都会非阻塞直接成功,返回 channel 元素的零值,但是第二个 bool 值一直为 false。
写已经关闭的 chan 会 panic
3.怎么调用一个接口
type Duck interface {
GaGaSpeaking()
OfficialWalking()
}
type Actor interface {
MakeFun()
}
type DonaldDuck struct {
height uint
name string
}
func (dd *DonaldDuck) GaGaSpeaking() { fmt.Println("DonaldDuck gaga") }
func (dd *DonaldDuck) OfficialWalking() { fmt.Println("DonaldDuck walk") }
func (dd *DonaldDuck) MakeFun() { fmt.Println("DonaldDuck make fun") }
func main() {
dd := &DonaldDuck{10, "tang lao ya"}
var duck Duck = dd
var actor Actor = dd
duck.GaGaSpeaking()
actor.MakeFun()
dd.OfficialWalking()
}
4.如何读取一个大文件
方案一:使用流处理
func ReadFile(filePath string, handle func(string)) error {
f, err := os.Open(filePath)
defer f.Close()
if err != nil {
return err
}
buf := bufio.NewReader(f)
for {
line, err := buf.ReadLine("\n")
line = strings.TrimSpace(line)
handle(line)
if err != nil {
if err == io.EOF{
return nil
}
return err
}
return nil
}
}
方案二:分片处理
没有换行符的时候可以使用下面的代码
func ReadBigFile(fileName string, handle func([]byte)) error {
f, err := os.Open(fileName)
if err != nil {
fmt.Println("can't opened this file")
return err
}
defer f.Close()
s := make([]byte, 4096)
for {
switch nr, err := f.Read(s[:]); true {
case nr < 0:
fmt.Fprintf(os.Stderr, "cat: error reading: %s\n
PS:golang 读取大文件处理sync.pool + bufio.NewReader(f)
5.go的协程和多线程有什么区别
1.进程、线程、协程介绍
进程:系统中所有的应用程序都是以进程(process)的方式运行,是系统进行资源分配和调度的基本单位,每个进程都有自己的独立的地址空间,使得进程之间的地址空间相互隔离。
线程:线程是程序执行流的最小单元上,通常意义上,一个进程由一个到多个线程组成,各个线程之间共享程序的内存空间(包括代码段、数据段、堆等)及一些进程级的资源(如打开的文件和信号)。
协程:协程在Go语言中,由轻量级线程实现,由Go运行时(runtime)管理。
这里特别说明下并发和并行:
-
并发:多线程程序在单核上运行
-
并行:多线程程序在多核上运行
2.协程与进程、线程的区别
1)进程拥有自己的堆栈,不共享堆和栈,是由操作系统进行调度的。 2)线程拥有自己的独立的栈和共享的堆,也是由操作系统进行调度。 3)协程共享堆,不共享栈,协程的调度由用户控制。
3.协程的优点
1)代码编辑简单,可以将异步处理逻辑代码用同步的方式编写,将多个异步操作集中到一个函数中完成。 2)单线程模式,没有线程安全的问题,不需要加锁操作。 3)性能好,协程是用户态线程,切换更加高效。
4.协程和线程轻量分析
一旦我们创建完线程,就无法决定它什么时候获得时间片,什么时候让出时间片,这里都交给了内核。和我们编写协程时可以控制,可控的切换时机和很小的切换代价,从操作系统有没有调度权来看,协程就是因为不需要进行内核态的切换。
1)Go协程调用跟切换比线程效率高 线程并发执行流程: 线程是内核对外提供的服务,应用程序可以通过系统调用让内核启动线程,由内核来负责线程调度和切换,线程在等待IO操作时标为unrunnable状态会触发上下文切换。现代操作系统一般采用抢占式调度,上下文切换一般发生在时钟中断和系统调用返回前,调度器计算当前线程的时间片,如果需要切换就从运行队列中选出一个目标线程,保存当前线程的环境,并且恢复目标线程的运行环境,最典型的就是切换ESP指向目标线程内核堆栈,将EIP指向目标线程上次被调度出时的指令地址。 Go协程并发执行流程: 不依赖操作系统和其提供的线程,Golang自己实现的
2)Go协程占用内存小 执行Go协程只需要极少的栈内存(大概4~5KB),默认情况下,线程栈的大小为1MB。 Goroutine就是一段代码,一个函数入口,以及在堆上为其分配的一个堆栈,所以它非常廉价,我们可以很轻松的创建上万个Goroutine,但它们并不是被操作系统所调度执行。
6.gin框架的路由实现
gin框架中采用的路由库是基于httprouter做的,httprouter的实现原理是使用了一个radix tree(压缩字典树)来管理请求Url的。基数树是一种更节省空间的前缀树,对于基数树的每个节点,如果该节点是唯一的子树的话,就和父节点合并。
前缀树算法
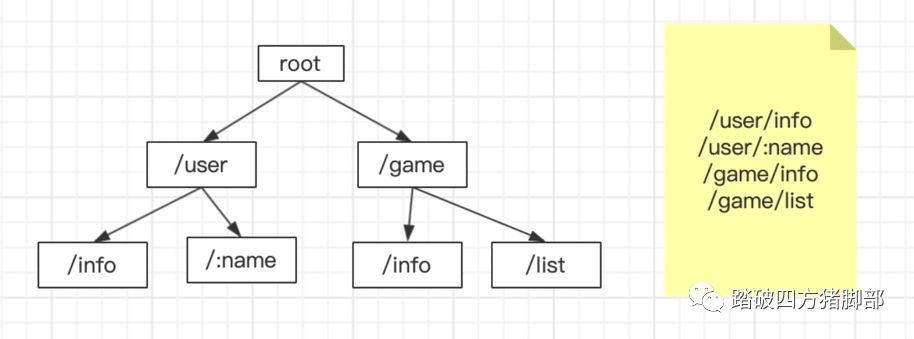
前缀树的本质就是一棵查找树,有别于普通查找树,它适用于一些特殊场合,比如用于字符串的查找。比如一个在路由的场景中,有1W个路由字符串,每个字符串长度不等,我们可以使用数组来储存,查找的时间复杂度是O(n),可以用map来储存,查找的复杂度是O(1),但是都没法解决动态匹配的问题,如果用前缀树时间复杂度是O(logn),也可以解决动态匹配参数的问题。
下图展示了前缀树的原理,有以下6个字符串,如果要查找cat字符串,步骤如下:
-
先拿字符c和root的第一个节点a比较,如果不等,再继续和父节点root的第二个节点比较,直到找到c。
-
再拿字符a和父节点c的第一个节点a比较,结果相等,则继续往下。
-
再拿字符t和父节点a的第一个节点t比较,结果相等,则完成。
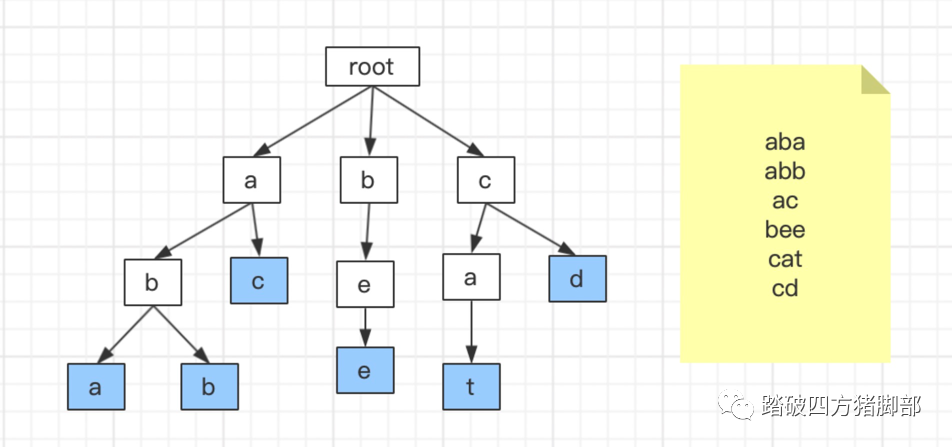
同理,在路由中,前缀树可以规划成如下:
7.make和new的区别
make
在 Go 语言中,内置函数 make 仅支持 slice、map、channel 三种数据类型的内存创建,其返回值是所创建类型的本身,而不是新的指针引用。
new
在 Go 语言中,内置函数 new 可以对类型进行内存创建和初始化。其返回值是所创建类型的指针引用,与 make 函数在实质细节上存在区别。
区别
-
make函数: -
-
能够分配并初始化类型所需的内存空间和结构,返回引用类型的本身。
-
具有使用范围的局限性,仅支持
channel、map、slice三种类型。 -
具有独特的优势,
make函数会对三种类型的内部数据结构(长度、容量等)赋值。
-
-
new函数: -
-
能够分配类型所需的内存空间,返回指针引用(指向内存的指针)。
-
可被替代,能够通过字面值快速初始化。
-
8.go中如何修改字符串
Go 语言中字符串是不可变的,因此不能直接修改字符串的内容。但是,您可以使用以下两种方法来实现修改字符串的效果:
1.重新赋值:您可以将原始字符串赋值给一个新的字符串变量,并在新字符串上进行修改。
str := "Hello, World!"
str = "Hello, Go!"
2.将字符串转换为字节切片,然后对其进行修改:
str := "Hello, World!"
b := []byte(str)
b[7] = 'G'
str = string(b)
6.微服务
服务网格
服务网格(Service Mesh)是处理服务间通信的基础设施层。它负责构成现代云原生应用程序的复杂服务拓扑来可靠地交付请求。在实践中,Service Mesh 通常以轻量级网络代理阵列的形式实现,这些代理与应用程序代码部署在一起,对应用程序来说无需感知代理的存在。
如果用一句话来解释什么是 Service Mesh,可以将它比作是应用程序或者说微服务间的 TCP/IP,负责服务之间的网络调用、限流、熔断和监控。
Service Mesh特点
Service Mesh的特点
Service Mesh 有如下几个特点:
应用程序间通信的中间层
轻量级网络代理
应用程序无感知
解耦应用程序的重试/超时、监控、追踪和服务发现
Service Mesh如何工作?
下面以 Istio 为例讲解 Service Mesh 如何工作,后续文章将会详解 Istio 如何在 Kubernetes 中工作。
-
Sidecar(Istio 中使用
-
当 sidecar 确认了目的地址后,将流量发送到相应服务发现端点,在 Kubernetes 中是 service,然后 service 会将服务转发给后端的实例。
-
Sidecar 根据它观测到最近请求的延迟时间,选择出所有应用程序的实例中响应最快的实例。
-
Sidecar 将请求发送给该实例,同时记录响应类型和延迟数据。
-
如果该实例挂了、不响应了或者进程不工作了,sidecar 会将把请求发送到其他实例上重试。
-
如果该实例持续返回 error,sidecar 会将该实例从负载均衡池中移除,稍后再周期性得重试。
-
如果请求的截止时间已过,sidecar 主动标记该请求为失败,而不是再次尝试添加负载。
-
SIdecar 以 metric 和分布式追踪的形式捕获上述行为的各个方面,这些追踪信息将发送到集中 metric 系统。
istio
Istio 服务网格从逻辑上分为数据平面和控制平面。
-
数据平面 由一组智能代理(
-
控制平面 管理并配置代理来进行流量路由。

组件
Envoy
Istio 使用 Envoy 代理的扩展版本。Envoy 是用 C++ 开发的高性能代理,用于协调服务网格中所有服务的入站和出站流量。Envoy 代理是唯一与数据平面流量交互的 Istio 组件。
Envoy 代理被部署为服务的 Sidecar,在逻辑上为服务增加了 Envoy 的许多内置特性,例如:
动态服务发现
负载均衡
TLS 终端
HTTP/2 与 gRPC 代理
熔断器
健康检查
基于百分比流量分割的分阶段发布
故障注入
丰富的指标
这种 Sidecar 部署允许 Istio 可以执行策略决策,并提取丰富的遥测数据,接着将这些数据发送到监视系统以提供有关整个网格行为的信息。
Sidecar 代理模型还允许您向现有的部署添加 Istio 功能,而不需要重新设计架构或重写代码。
由 Envoy 代理启用的一些 Istio 的功能和任务包括:
流量控制功能:通过丰富的 HTTP、gRPC、WebSocket 和 TCP 流量路由规则来执行细粒度的流量控制。
网络弹性特性:重试设置、故障转移、熔断器和故障注入。
安全性和身份认证特性:执行安全性策略,并强制实行通过配置 API 定义的访问控制和速率限制。
基于 WebAssembly 的可插拔扩展模型,允许通过自定义策略执行和生成网格流量的遥测。
Istiod
Istiod 提供服务发现、配置和证书管理。
Istiod 将控制流量行为的高级路由规则转换为 Envoy 特定的配置,并在运行时将其传播给 Sidecar。Pilot 提取了特定平台的服务发现机制,并将其综合为一种标准格式,任何符合 Envoy API 的 Sidecar 都可以使用。
您可以使用 Istio 流量管理 API 让 Istiod 重新构造 Envoy 的配置,以便对服务网格中的流量进行更精细的控制。
Istiod 安全通过内置的身份和凭证管理,实现了强大的服务对服务和终端用户认证。您可以使用 Istio 来升级服务网格中未加密的流量。使用 Istio,运营商可以基于服务身份而不是相对不稳定的第 3 层或第 4 层网络标识符来执行策略。此外,您可以使用 Istio 的授权功能控制谁可以访问您的服务。
Istiod 充当证书授权(CA),并生成证书以允许在数据平面中进行安全的 mTLS 通信。
抽象四大功能:流量管理、扩展性、安全认证、可观测性
istio流量管理
虚拟服务(可以不存在): 一个用于做路由策略处理的服务,请求发送到虚拟服务后会根据路由规则将请求转发到对应的目标服务
目标规则:
您可以将虚拟服务视为将流量如何路由到给定目标地址,然后使用目标规则来配置该目标的流量。在评估虚拟服务路由规则之后,目标规则将应用于流量的“真实”目标地址。
特别是,您可以使用目标规则来指定命名的服务子集,例如按版本为所有给定服务的实例分组。然后可以在虚拟服务的路由规则中使用这些服务子集来控制到服务不同实例的流量。
目标规则还允许您在调用整个目的地服务或特定服务子集时定制 Envoy 的流量策略,比如您喜欢的负载均衡模型、TLS 安全模式或熔断器设置。在目标规则参考中可以看到目标规则选项的完整列表。
路由规则按从上到下的顺序选择,虚拟服务中定义的第一条规则有最高优先级。
负载均衡
Istio默认采用轮询的方式将流量转发,除轮询还有以下方案
随机:请求以随机的方式转到池中的实例。
权重:请求根据指定的百分比转到实例。
最少请求:请求被转到最少被访问的实例。
网关
如果需要为想要工作的网关指定路由,您必须把网关绑定到虚拟服务上。
服务入口
使用
-
为外部目标 redirect 和转发请求,例如来自 web 端的 API 调用,或者流向遗留老系统的服务。
-
为外部目标定义
-
添加一个运行在虚拟机的服务来
您不需要为网格服务要使用的每个外部服务都添加服务入口。默认情况下,Istio 配置 Envoy 代理将请求传递给未知服务。但是,您不能使用 Istio 的特性来控制没有在网格中注册的目标流量。
Sidecar
默认情况下,Istio 让每个 Envoy 代理都可以访问来自和它关联的工作负载的所有端口的请求,然后转发到对应的工作负载。您可以使用
-
微调 Envoy 代理接受的端口和协议集。
-
限制 Envoy 代理可以访问的服务集合。
您可能希望在较庞大的应用程序中限制这样的 sidecar 可达性,配置每个代理能访问网格中的任意服务可能会因为高内存使用量而影响网格的性能。
网络弹性和测试
除了为您的网格导流之外,Istio 还提供了可选的故障恢复和故障注入功能,您可以在运行时动态配置这些功能。使用这些特性可以让您的应用程序运行稳定,确保服务网格能够容忍故障节点,并防止局部故障级联影响到其他节点。
超时
重试
熔断器
故障注入
故障注入是一种将错误引入系统以确保系统能够承受并从错误条件中恢复的测试方法。使用故障注入特别有用,能确保故障恢复策略不至于不兼容或者太严格,这会导致关键服务不可用。
两种方式:
延迟:延迟是时间故障。它们模拟增加的网络延迟或一个超载的上游服务。
终止:终止是崩溃失败。他们模仿上游服务的失败。终止通常以 HTTP 错误码或 TCP 连接失败的形式出现。
7.hadoop
8.openstack
9.存储相关
详细的可见 https://zhuanlan.zhihu.com/p/468843946
1.ceph
1.ceph介绍
Ceph是一个统一的分布式存储系统,有以下四大优点:
1、高性能
-
-
摒弃了传统的集中式存储元数据寻址的方案,采用CRUSH算法,数据分布均衡,并行度高
-
考虑了容灾域的隔离,能够实现各类负载的副本放置规则,例如跨机房、机架感知等
-
能够支持上千个存储节点的规模。支持TB到PB级的数据
-
2、高可用
-
-
副本数可以灵活控制
-
支持故障域分隔,数据强一致性
-
多种故障场景自动进行修复自愈
-
没有单点故障,自动管理
-
3、高扩展性
-
-
去中心化
-
扩展灵活
-
随着节点增加,性能线性增长
-
4、特性丰富
-
-
支持三种存储接口:对象存储,块设备存储,文件存储
-
支持自定义接口,支持多种语言驱动
-
2.Ceph基本结构
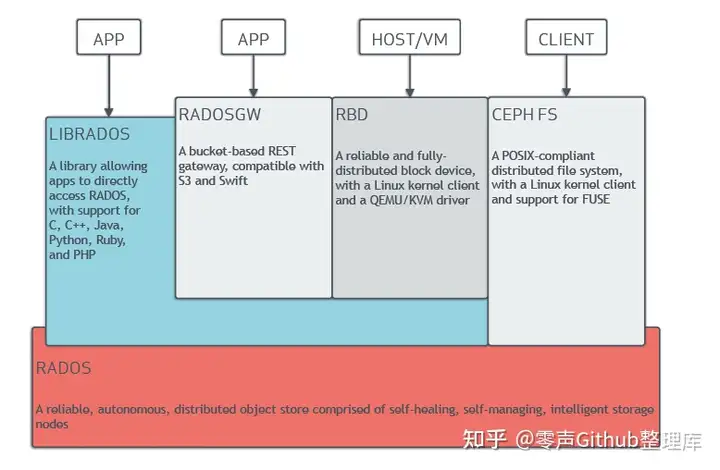
Ceph的底层是RADOS,RADOS本身也是分布式存储系统,Ceph所有的存储功能都是基于RADOS实现的。RADOS采用C++开发,所提供的原生Librados API包括C和C++两种。Ceph的上层应用调用本机上的librados API,再由后者通过socket与RADOS集群中的其他节点通信并完成各种操作。
RADOS GateWay、RBD其作用是在librados库的基础上提供抽象层次更高、更便于应用或客户端使用的上层接口。其中RADOS GW是一个提供与Amazon S3和Swift兼容的RESTful API的gateway,以供相应的对象存储应用开发使用。RBD则提供了一个标准的块设备接口,常用于在虚拟化的场景下为虚拟机创建volume。目前,RedHat已经将RBD驱动集成在KVM/QEMU中,以提供虚拟机访问性能。这两种方式目前在云计算中应用的比较多。
CephFS则提供了POSIX接口,用户可直接通过客户端挂载使用。它是内核态的程序,所有无需调用用户空间的librados库。它通过内核中的net模块来与RADOS进行交互。
10.常识
1.HTTP(HTTPS)协议
HTTP是一个基于TCP/IP通信协议来传递数据(HTML 文件, 图片文件, 查询结果等)。
HTTP是一个属于应用层的面向对象的协议,由于其简捷、快速的方式,适用于分布式超媒体信息系统。
HTTP协议工作于客户端-服务端架构为上。浏览器作为HTTP客户端通过URL向HTTP服务端即WEB服务器发送所有请求。Web服务器根据接收到的请求后,向客户端发送响应信息。
特点
1、简单快速:客户向服务器请求服务时,只需传送请求方法和路径。请求方法常用的有GET、HEAD、POST。每种方法规定了客户与服务器联系的类型不同。由于HTTP协议简单,使得HTTP服务器的程序规模小,因而通信速度很快。
2、灵活:HTTP允许传输任意类型的数据对象。正在传输的类型由Content-Type加以标记。
3.无连接:无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。
4.无状态:HTTP协议是无状态协议。无状态是指协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。另一方面,在服务器不需要先前信息时它的应答就较快。
5、支持B/S及C/S模式。
HTTP常见状态码
200 OK //客户端请求成功
400 Bad Request //客户端请求有语法错误,不能被服务器所理解
401 Unauthorized //请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用
403 Forbidden //服务器收到请求,但是拒绝提供服务
404 Not Found //请求资源不存在,eg:输入了错误的URL
500 Internal Server Error //服务器发生不可预期的错误
503 Server Unavailable //服务器当前不能处理客户端的请求,一段时间后可能恢复正常
HTTP请求方法
GET 请求指定的页面信息,并返回实体主体。
HEAD 类似于get请求,只不过返回的响应中没有具体的内容,用于获取报头
POST 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的建立和/或已有资源的修改。
PUT 从客户端向服务器传送的数据取代指定的文档的内容。
DELETE 请求服务器删除指定的页面。
CONNECT HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。
OPTIONS 允许客户端查看服务器的性能。
TRACE 回显服务器收到的请求,主要用于测试或诊断。
HTTP的一次请求过程
对www.baidu.com这个网址进行DNS域名解析,得到对应的IP地址
根据这个IP,找到对应的服务器,发起TCP的三次握手
建立TCP连接后发起HTTP请求
服务器响应HTTP请求,浏览器得到html代码
浏览器解析html代码,并请求html代码中的资源(如js、css、图片等)(先得到html代码,才能去找这些资源)
浏览器对页面进行渲染呈现给用户
服务器关闭关闭TCP连接
HTTP的长短链接
介绍
长连接:长连接,指在一个连接上可以连续发送多个数据包,在连接保持期间,如果没有数据包发送,需要双方发链路检测包。
人话:长连接建立后会一直保持链接知道一方关闭连接
短链接:连接(short connnection)是相对于长连接而言的概念,指的是在数据传送过程中,只在需要发送数据时,才去建立一个连接,数据发送完成后,则断开此连接,即每次连接只完成一项业务的发送。
人话:每次请求都建立一个连接,发送完数据就关闭,下次再来再建立新连接
应用场景
长连接:长连接多用于操作频繁,点对点的通讯,而且连接数不能太多情况。每个TCP连接都需要三步握手,这需要时间,如果每个操作都是先连接,再操作的话那么处理速度会降低很多,所以每个操作完后都不断开,次处理时直接发送数据包就OK了,不用建立TCP连接。
例如:数据库的连接用长连接, 如果用短连接频繁的通信会造成socket错误,而且频繁的socket 创建也是对资源的浪费。
短连接:而像WEB网站的http服务一般都用短链接,因为长连接对于服务端来说会耗费一定的资源,而像WEB网站这么频繁的成千上万甚至上亿客户端的连接用短连接会更省一些资源,如果用长连接,而且同时有成千上万的用户,如果每个用户都占用一个连接的话,那可想而知吧。
所以并发量大,但每个用户无需频繁操作情况下需用短连好。
优势与缺点
TCP短连接:
我们模拟一下TCP短连接的情况,client向server发起连接请求,server接到请求,然后双方建立连接。client向server发送消息,server回应client,然后一次读写就完成了,这时候双方任何一个都可以发起close操作,不过一般都是client先发起close操作。
为什么呢,一般的server不会回复完client后立即关闭连接的,当然不排除有特殊的情况。从上面的描述看,短连接一般只会在client/server间传递一次读写操作
短连接的优点是:管理起来比较简单,存在的连接都是有用的连接,不需要额外的控制手段。
TCP长连接:
接下来我们再模拟一下长连接的情况,client向server发起连接,server接受client连接,双方建立连接。Client与server完成一次读写之后,它们之间的连接并不会主动关闭,后续的读写操作会继续使用这个连接。
首先说一下TCP/IP详解上讲到的TCP保活功能,保活功能主要为服务器应用提供,服务器应用希望知道客户主机是否崩溃,从而可以代表客户使用资源。如果客户已经消失,使得服务器上保留一个半开放的连接,而服务器又在等待来自客户端的数据,则服务器将应远等待客户端的数据,保证功能就是试图在服务器端检测到这种半开放的连接。
如果一个给定的连接在两小时内没有任何的动作,则服务器就向客户发一个探测报文段,客户主机必须处于以下4个状态之一:
客户主机依然正常运行,并从服务器可达。客户的TCP响应正常,而服务器也知道对方是正常的,服务器在两小时后将保证定时器复位。
客户主机已经崩溃,并且关闭或者正在重新启动。在任何一种情况下,客户的TCP都没有响应。服务端将不能收到对探测的响应,并在75秒后超时。服务器总共发送10个这样的探测 ,每个间隔75秒。如果服务器没有收到一个响应,它就认为客户主机已经关闭并终止连接。
客户主机崩溃并已经重新启动。服务器将收到一个对其保证探测的响应,这个响应是一个复位,使得服务器终止这个连接。
客户机正常运行,但是服务器不可达,这种情况与2类似,TCP能发现的就是没有收到探查的响应。
从上面可以看出,TCP保活功能主要为探测长连接的存活状况,不过这里存在一个问题,存活功能的探测周期太长,还有就是它只是探测TCP连接的存活,属于比较斯文的做法,遇到恶意的连接时,保活功能就不够使了。
在长连接的应用场景下,client端一般不会主动关闭它们之间的连接,Client与server之间的连接如果一直不关闭的话,会存在一个问题,随着客户端连接越来越多,server早晚有扛不住的时候,这时候server端需要采取一些策略,如关闭一些长时间没有读写事件发生的连接,这样可以避免一些恶意连接导致server端服务受损;如果条件再允许就可以以客户端机器为颗粒度,限制每个客户端的最大长连接数,这样可以完全避免某个蛋疼的客户端连累后端服务。
长连接和短连接的产生在于client和server采取的关闭策略,具体的应用场景采用具体的策略,没有十全十美的选择,只有合适的选择。
2.TCP/IP协议
tcp/ip协议分层
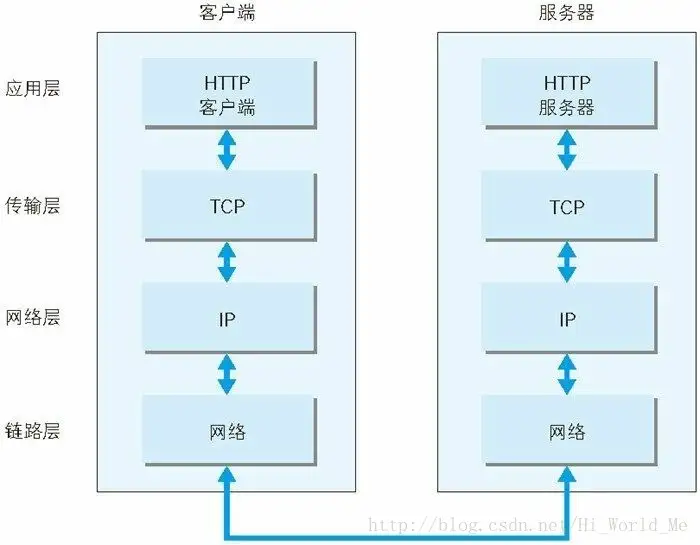

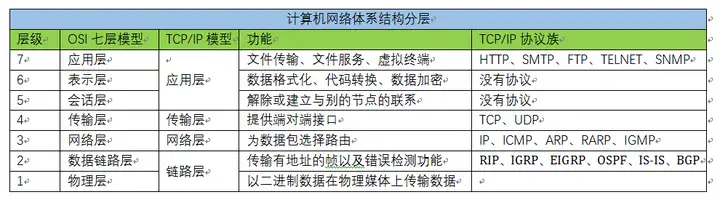
应用层
应用层决定了向用户提供应用服务时通信的活动。TCP/IP 协议族内预存了各类通用的应用服务。比如,FTP(FileTransfer
Protocol,文件传输协议)和 DNS(Domain Name System,域名系统)服务就是其中两类。HTTP 协议也处于该层。
传输层
传输层对上层应用层,提供处于网络连接中的两台计算机之间的数据传输。在传输层有两个性质不同的协议:TCP(Transmission ControlProtocol,传输控制协议)和UDP(User Data Protocol,用户数据报协议)。
网络层(又名网络互连层)
网络层用来处理在网络上流动的数据包。数据包是网络传输的最小数据单位。该层规定了通过怎样的路径(所谓的传输路线)到达对方计算机,并把数据包传送给对方。与对方计算机之间通过多台计算机或网络设备进行传输时,网络层所起的作用就是在众多的选项内选择一条传输路线。
链路层(又名数据链路层,网络接口层)
用来处理连接网络的硬件部分。包括控制操作系统、硬件的设备驱动、NIC(Network Interface Card,网络适配器,即网卡),及光纤等物理可见部分(还包括连接器等一切传输媒介)。硬件上的范畴均在链路层的作用范围之内。
tcp三次握手与四次挥手
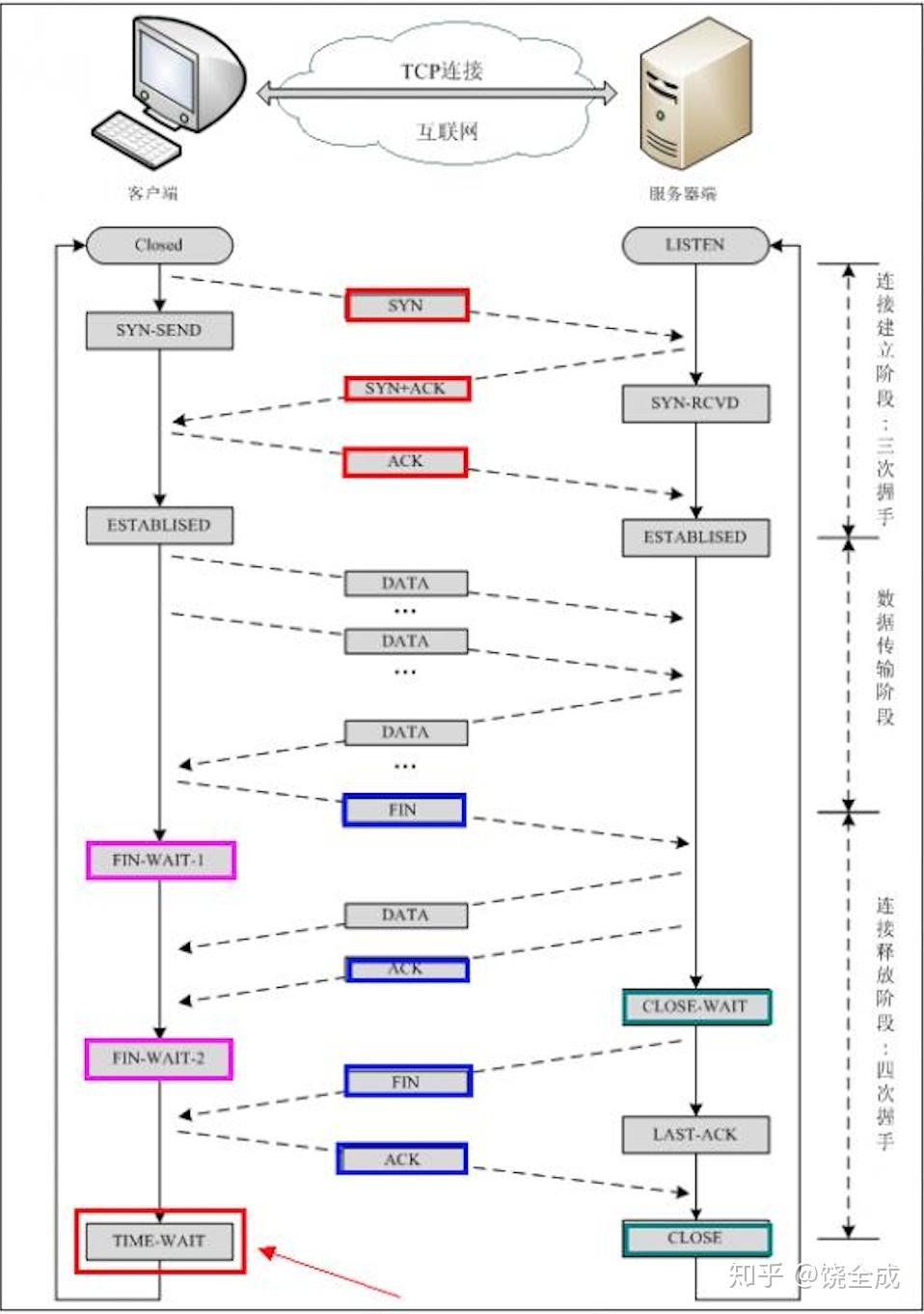
三次握手
第一次握手(SYN=1, seq=x):
客户端发送一个 TCP 的 SYN 标志位置1的包,指明客户端打算连接的服务器的端口,以及初始序号 X,保存在包头的序列号(Sequence Number)字段里。
发送完毕后,客户端进入 SYN_SEND 状态。
第二次握手(SYN=1, ACK=1, seq=y, ACKnum=x+1):
服务器发回确认包(ACK)应答。即 SYN 标志位和 ACK 标志位均为1。服务器端选择自己 ISN 序列号,放到 Seq 域里,同时将确认序号(Acknowledgement Number)设置为客户的 ISN 加1,即X+1。 发送完毕后,服务器端进入 SYN_RCVD 状态。
第三次握手(ACK=1,ACKnum=y+1)
客户端再次发送确认包(ACK),SYN 标志位为0,ACK 标志位为1,并且把服务器发来 ACK 的序号字段+1,放在确定字段中发送给对方,并且在数据段放写ISN的+1
发送完毕后,客户端进入 ESTABLISHED 状态,当服务器端接收到这个包时,也进入 ESTABLISHED 状态,TCP 握手结束。
四次挥手
TCP 的连接的拆除需要发送四个包,因此称为四次挥手(Four-way handshake),也叫做改进的三次握手。客户端或服务器均可主动发起挥手动作,在 socket 编程中,任何一方执行 close() 操作即可产生挥手操作。
第一次挥手(FIN=1,seq=x)
假设客户端想要关闭连接,客户端发送一个 FIN 标志位置为1的包,表示自己已经没有数据可以发送了,但是仍然可以接受数据。
发送完毕后,客户端进入 FIN_WAIT_1 状态。
第二次挥手(ACK=1,ACKnum=x+1)
服务器端确认客户端的 FIN 包,发送一个确认包,表明自己接受到了客户端关闭连接的请求,但还没有准备好关闭连接。
发送完毕后,服务器端进入 CLOSE_WAIT 状态,客户端接收到这个确认包之后,进入 FIN_WAIT_2 状态,等待服务器端关闭连接。
第三次挥手(FIN=1,seq=y)
服务器端准备好关闭连接时,向客户端发送结束连接请求,FIN 置为1。
发送完毕后,服务器端进入 LAST_ACK 状态,等待来自客户端的最后一个ACK。
第四次挥手(ACK=1,ACKnum=y+1)
客户端接收到来自服务器端的关闭请求,发送一个确认包,并进入 TIME_WAIT状态,等待可能出现的要求重传的 ACK 包。
服务器端接收到这个确认包之后,关闭连接,进入 CLOSED 状态。
客户端等待了某个固定时间(两个最大段生命周期,2MSL,2 Maximum Segment Lifetime)之后,没有收到服务器端的 ACK ,认为服务器端已经正常关闭连接,于是自己也关闭连接,进入 CLOSED 状态。
SYN攻击
#什么是 SYN 攻击(SYN Flood)?
在三次握手过程中,服务器发送 SYN-ACK 之后,收到客户端的 ACK 之前的 TCP 连接称为半连接(half-open connect)。此时服务器处于 SYN_RCVD 状态。当收到 ACK 后,服务器才能转入 ESTABLISHED 状态.
SYN 攻击指的是,攻击客户端在短时间内伪造大量不存在的IP地址,向服务器不断地发送SYN包,服务器回复确认包,并等待客户的确认。由于源地址是不存在的,服务器需要不断的重发直至超时,这些伪造的SYN包将长时间占用未连接队列,正常的SYN请求被丢弃,导致目标系统运行缓慢,严重者会引起网络堵塞甚至系统瘫痪。
SYN 攻击是一种典型的 DoS/DDoS 攻击。
#如何检测 SYN 攻击?
检测 SYN 攻击非常的方便,当你在服务器上看到大量的半连接状态时,特别是源IP地址是随机的,基本上可以断定这是一次SYN攻击。在 Linux/Unix 上可以使用系统自带的 netstats 命令来检测 SYN 攻击。
#如何防御 SYN 攻击?
SYN攻击不能完全被阻止,除非将TCP协议重新设计。我们所做的是尽可能的减轻SYN攻击的危害,常见的防御 SYN 攻击的方法有如下几种:
缩短超时(SYN Timeout)时间
增加最大半连接数
过滤网关防护
SYN cookies技术
TCP KeepAlive
TCP 通信双方建立交互的连接,但是并不是一直存在数据交互,有些连接会在数据交互完毕后,主动释放连接,而有些不会。在长时间无数据交互的时间段内,交互双方都有可能出现掉电、死机、异常重启等各种意外,当这些意外发生之后,这些 TCP 连接并未来得及正常释放,在软件层面上,连接的另一方并不知道对端的情况,它会一直维护这个连接,长时间的积累会导致非常多的半打开连接,造成端系统资源的消耗和浪费,为了解决这个问题,在传输层可以利用 TCP 的 KeepAlive 机制实现来实现。主流的操作系统基本都在内核里支持了这个特性。
-
原理:
TCP KeepAlive 的基本原理是,隔一段时间给连接对端发送一个探测包,如果收到对方回应的 ACK,则认为连接还是存活的,在超过一定重试次数之后还是没有收到对方的回应,则丢弃该 TCP 连接。
-
TCP KeepAlive局限性:
首先 TCP KeepAlive 监测的方式是发送一个 probe 包,会给网络带来额外的流量,另外 TCP KeepAlive 只能在内核层级监测连接的存活与否,而连接的存活不一定代表服务的可用。例如当一个服务器 CPU 进程服务器占用达到 100%,已经卡死不能响应请求了,此时 TCP KeepAlive 依然会认为连接是存活的。
TCP/IP协议簇
应用协议:TCP/IP体系中的应用层协议,主要包括HTTP(超文本传输协议)、SMTP(简单邮件传送协议)、FTP(文件传输协议)、TELNET(远程登录协议)、SNMP(简单网络管理协议)。
传输协议:TCP/IP体系中的传输层协议,主要包括TCP(传输控制协议)、UDP(用户数据报协议)。
网际互联协议:TCP/IP体系中的网络层协议,主要包括IP(Internet协议)、ARP(地址解析协议)、RARP(逆地址解析协议)、ICMP(因特网控制报文协议)、IGMP(因特网组管理协议)。
路由控制协议:TCP/IP体系中的链路层协议,分为内部网关协议和域间路由协议。内部网关协议包括RIP(路由信息协议)、IGRP(内部网关路由协议)、EIGRP(增强内部网关路由协议)、OSPF(开放式最短路径优先协议)、IS-IS(中间系统到中间系统路由协议)。域间路由协议包括BGP(边界网关协议)。
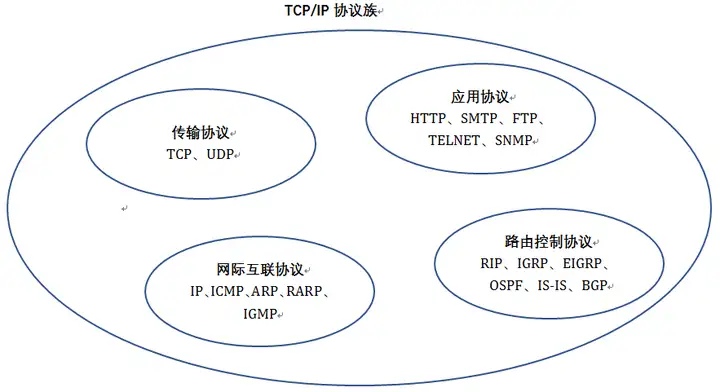
工作原理
当HTTP发起一个消息请求时,应用层、传输层、网络层和链路层的相关协议依次对该消息请求附加对应的首部,这个首部标明了协议应该如何读取数据,最终在链路层生成以太网数据包,以太网数据包通过物理介质传输到目的主机,目的主机接收到以太网数据包以后,再一层一层采用对应的协议进行拆包,最后把应用层数据交给应用程序处理。简单来说,就是"发送请求时,封包,接收数据时,拆包。"
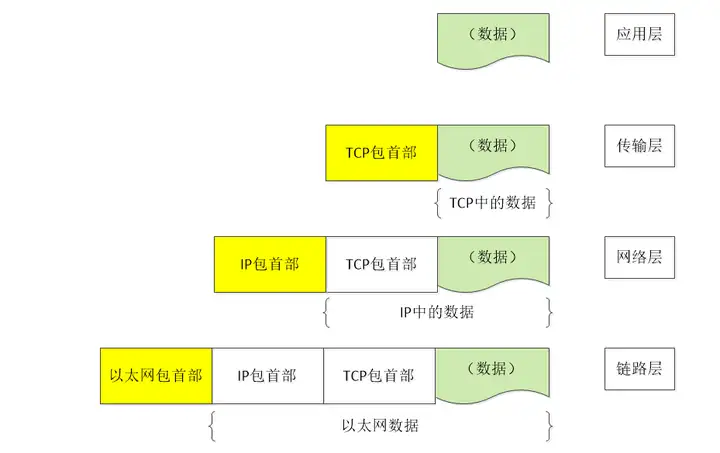
工作流程
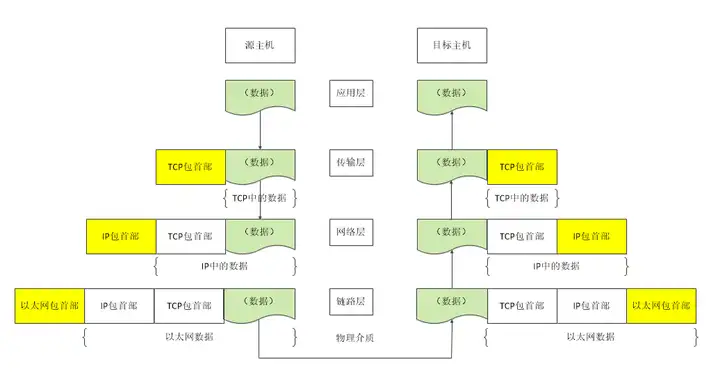
源主机封包:
1、 应用层:源主机将数据向下传输给传输层;
2、 传输层:将数据分组,加上TCP首部形成TCP数据段,向下传输给网络层;
3、 网络层:给TCP数据段加上源主机、目的主机IP首部,生成IP数据包,向下传输给链路层;
4、 链路层:链路层在其MAC帧的数据部分装上IP数据包,再加上源主机,目的主机的MAC地址和帧头,并根据其目的的MAC地址,将MAC帧发往目的主机或IP路由器;
目的主机拆包:
1、 链路层:在目的主机,链路层将MAC帧的帧头去掉,并将IP数据包向上传递给网络层;
2、 网路层:检查IP报头,如果报头中校验和计算结果不一致,则丢弃该IP数据包,若校验和计算结果一致,则去掉IP报头,将TCP数据段向上传递给传输层;
3、 传输层:检查顺序号,判断是否是正确的TCP分组,然后检查TCP报头数据,若正确,则向源主机发送确认信息,若不正确或丢包,则向源主机要求重发信息;
4、 应用层:目的主机,传输层去掉TCP报头,将排好顺序的分组组成应用数据流送给应用程序,这样目的主机接收到的来自源主机的字节流,就像是直接接收来自源主机的字节流一样。
总结
数据在每层有不同的格式,从上到下依次叫数据段,数据包,数据帧,数据从应用层通过协议栈向下传递,每经过一层加上对应层协议报头,最后封装成"数据帧"发送到传输介质上,到达路由器或者目的主机去掉头部,交付给上层需要者。这一过程称为封装,传输,分离,分用。
数据段:TCP 数据流中的信息;
数据包:IP 和 UDP 等网络层以上的分层中包的单位;
数据帧:数据链路层中包的单位;
3.DNS
域名结构解析
难道 DNS 服务器(比如 1.1.1.1)保存了世界上所有域名(包括二级域名、三级域名)的 IP 地址?
当然不是。DNS 是一个分布式系统,1.1.1.1 只是用户查询入口,它也需要再向其他 DNS 服务器查询,才能获得最终的 IP 地址。
要说清楚 DNS 完整的查询过程,就必须了解 域名是一个树状结构。
最顶层的域名是根域名(root),然后是顶级域名(top-level domain,简写 TLD),再是一级域名、二级域名、三级域名。

(1)根域名
所有域名的起点都是根域名,它写作一个点.,放在域名的结尾。因为这部分对于所有域名都是相同的,所以就省略不写了,比如example.com等同于example.com.(结尾多一个点)。根域名服务器全世界一共有13台(都是服务器集群)。
(2)顶级域名
根域名的下一级是顶级域名。它分成两种:通用顶级域名(gTLD,比如 .com 和 .net)和国别顶级域名(ccTLD,比如 .cn 和 .us)。
顶级域名由国际域名管理机构 ICANN 控制,它委托商业公司管理 gTLD,委托各国管理自己的国别域名。
(3)一级域名
一级域名就是你在某个顶级域名下面,自己注册的域名。比如,ruanyifeng.com就是我在顶级域名.com下面注册的。
(4)二级域名
二级域名是一级域名的子域名,是域名拥有者自行设置的,不用得到许可。比如,es6.ruanyifeng.com中es6 就是 ruanyifeng.com 的二级域名。
逐级查询
这种树状结构的意义在于,只有上级域名,才知道下一级域名的 IP 地址,需要逐级查询。
每一级域名都有自己的 DNS 服务器,存放下级域名的 IP 地址。
如果想要查询二级域名 es6.ruanyifeng.com 的 IP 地址,需要三个步骤。
第一步,查询根域名服务器,获得顶级域名服务器.com(又称 TLD 服务器)的 IP 地址。
第二步,查询 TLD 服务器 .com,获得一级域名服务器 ruanyifeng.com 的 IP 地址。
第三步,查询一级域名服务器 ruanyifeng.com,获得二级域名 es6 的 IP 地址。
DNS服务器种类
在上面我们一共提到了四种DNS服务器
1.1.1.1
根域名服务器
TLD 服务器
一级域名服务器
递归 DNS 服务器
后三种服务器只用来查询下一级域名的 IP 地址,而 1.1.1.1 则把分步骤的查询过程自动化,方便用户一次性得到结果,所以它称为递归 DNS 服务器(recursive DNS server),即可以自动递归查询。
我们平常说的 DNS 服务器,一般都是指递归 DNS 服务器。它把 DNS 查询自动化了,只要向它查询就可以了。
它内部有缓存,可以保存以前查询的结果,下次再有人查询,就直接返回缓存里面的结果。所以它能加快查询,减轻源头 DNS 服务器的负担。
权威DNS服务器
一级域名服务器的正式名称叫做权威域名服务器(Authoritative Name Server)。
-
根域名服务器
-
TLD 服务器
-
权威域名服务器
-
递归域名服务器
4.单臂路由
单臂路由是一种网络架构,常用于网络流量监控和网络安全策略实施。在单臂路由的网络架构中,网络流量只会经过一个网络接口,而不是经过多个网络接口进行转发。这个网络接口可以是物理接口或者虚拟接口,也可以是一个网络设备或者服务器上的一个进程。通过单臂路由可以将所有流量引导到一个集中的地方进行监控和分析,从而实现对网络流量的精细管理。
公链 没有身份 比特币 以太坊
私链 和公链技术相同 只是和公链的网络号不同


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· winform 绘制太阳,地球,月球 运作规律
· 上周热点回顾(3.3-3.9)