

Go语言基础语法
Go语言基础语法
1.变量
变量声明方式
1.单个变量声明
var age int //单个变量声明
age = 18 //变量赋值
var age int = 18 //单个变量声明并初始化
var age = 18 //go语言会自动推算变量类型
2.多个变量声明
var width,height int = 180,150 //声明多个同类型变量并初始化
var (
name1 = zhangsan,
age = 18
height int
) //赋值不同类型
3.简短声明
//简短声明的语法要求 := 操作符的左边至少有一个变量是尚未声明的
// := 这种简短声明方式必须包含在一个结构体内
name,age := "zhangsan",18 //简短声明
由于 Go 是强类型(Strongly Typed)语言,因此不允许某一类型的变量赋值为其他类型的值。
2.类型
-
bool
-
数字类型
-
- int8, int16, int32, int64, int
- uint8, uint16, uint32, uint64, uint
- float32, float64
- complex64, complex128
- byte
- rune
-
string
类型转换
Go语言是强类型转换。
package main
import (
"fmt"
)
func main() {
i := 55 //int
j := 67.8 //float64
sum := i + int(j) //j is converted to int
fmt.Println(sum)
}
3.常量
const a = 55 //数字常量
const hello = "hello world" //字符串常量
//无类型的常量有一个与它们相关联的默认类型,并且当且仅当一行代码需要时才提供它
const hello string = "hello world" //有类型的常量
const b = true //布尔常量
4.函数
1.函数声明
//有返回值的函数
func functionname(parametername type) returntype {
// 函数体(具体实现的功能)
}
//无返回值的函数
func functionname() {
// 译注: 表示这个函数不需要输入参数,且没有返回值
}
//多返回值函数
func functionname(parametername,parametername type) (returntype,returntype) {
// 函数体(具体实现的功能)
}
2.命名返回值
//从函数中可以返回一个命名值。一旦命名了返回值,可以认为这些值在函数第一行就被声明为变量了。
func rectProps(length, width float64)(area, perimeter float64) {
area = length * width
perimeter = (length + width) * 2
return // 不需要明确指定返回值,默认返回 area, perimeter 的值
}
3.空白符
_ 在 Go 中被用作空白符,可以用作表示任何类型的任何值。
4.可变参数函数
//如果函数最后一个参数被记作 ...T,这时函数可以接受任意个 T 类型参数作为最后一个参数。
//请注意只有函数的最后一个参数才允许是可变的。
package main
import (
"fmt"
)
func find(num int, nums ...int) {
fmt.Printf("type of nums is %T\n", nums)
found := false
for i, v := range nums {
if v == num {
fmt.Println(num, "found at index", i, "in", nums)
found = true
}
}
if !found {
fmt.Println(num, "not found in ", nums)
}
fmt.Printf("\n")
}
func main() {
find(89, 89, 90, 95)
find(45, 56, 67, 45, 90, 109)
find(78, 38, 56, 98)
find(87)
}
//在上面程序中 func find(num int, nums ...int) 中的 nums 可接受任意数量的参数。在 find 函数中,参数 nums 相当于一个整型切片。
//可变参数函数的工作原理是把可变参数转换为一个新的切片。以上面程序中的第 22 行为例,find 函数中的可变参数是 89,90,95 。find 函数接受一个 int 类型的可变参数。因此这三个参数被编译器转换为一个 int 类型切片 int []int{89, 90, 95} 然后被传入 find 函数。
//在第 10 行, for 循环遍历 nums 切片,如果 num 在切片中,则打印 num 的位置。如果 num 不在切片中,则打印提示未找到该数字。
5.包
包用于组织 Go 源代码,提供了更好的可重用性与可读性。
1.main函数和main包
所有可执行的 Go 程序都必须包含一个 main 函数。这个函数是程序运行的入口。main 函数应该放置于 main 包中。
package main
import (
"fmt"
)
func find(num int, nums ...int) {
fmt.Printf("type of nums is %T\n", nums)
found := false
for i, v := range nums {
if v == num {
fmt.Println(num, "found at index", i, "in", nums)
found = true
}
}
if !found {
fmt.Println(num, "not found in ", nums)
}
fmt.Printf("\n")
}
func main() {
find(89, 89, 90, 95)
find(45, 56, 67, 45, 90, 109)
find(78, 38, 56, 98)
find(87)
}
2.创建自定义包
// rectprops.go
package rectangle
import "math"
func Area(len, wid float64) float64 {
area := len * wid
return area
}
func Diagonal(len, wid float64) float64 {
diagonal := math.Sqrt((len * len) + (wid * wid))
return diagonal
}
3.导入自定义包
// 文件夹结构
src
geometry
geometry.go
rectangle
rectprops.go
//导入包
// geometry.go
package main
import (
"fmt"
"geometry/rectangle" // 导入自定义包
)
func main() {
var rectLen, rectWidth float64 = 6, 7
fmt.Println("Geometrical shape properties")
/*Area function of rectangle package used*/
fmt.Printf("area of rectangle %.2f\n", rectangle.Area(rectLen, rectWidth))
/*Diagonal function of rectangle package used*/
fmt.Printf("diagonal of the rectangle %.2f ", rectangle.Diagonal(rectLen, rectWidth))
}
// 在 Go 中,任何以大写字母开头的变量或者函数都是被导出的名字。其它包只能访问被导出的函数和变量。
4.init函数
//所有包都可以包含一个 init 函数。init 函数不应该有任何返回值类型和参数,在我们的代码中也不能显式地调用它。
func init() {
}
//init 函数可用于执行初始化任务,也可用于在开始执行之前验证程序的正确性。
包的初始化顺序如下:
- 首先初始化包级别(Package Level)的变量
- 紧接着调用 init 函数。包可以有多个 init 函数(在一个文件或分布于多个文件中),它们按照编译器解析它们的顺序进行调用。
如果一个包导入了另一个包,会先初始化被导入的包。
尽管一个包可能会被导入多次,但是它只会被初始化一次。
5.使用空白标识符
//导入了包,却不在代码中使用它,这在 Go 中是非法的。
package main
import (
"geometry/rectangle"
)
var _ = rectangle.Area // 错误屏蔽器
func main() {
}
6.循环控制语句
1.if-else语句
//else 语句应该在 if 语句的大括号 } 之后的同一行中。如果不是,编译器会不通过。
// if单个条件判断时
if condition {
}
// if多条件判断时
if condition {
} else if condition {
} else {
}
//在判断之前运行语句
if statement; condition {
}
package main
import (
"fmt"
)
func main() {
if num := 10; num % 2 == 0 { //checks if number is even
fmt.Println(num,"is even")
} else {
fmt.Println(num,"is odd")
}
}
2.for循环
//for 是 Go 语言唯一的循环语句。
for initialisation; condition; post {
}
//break 语句用于在完成正常执行之前突然终止 for 循环,之后程序将会在 for 循环下一行代码开始执行。
func main() {
for i := 1; i <= 10; i++ {
if i > 5 {
break //loop is terminated if i > 5
}
fmt.Printf("%d ", i)
}
fmt.Printf("\nline after for loop")
}
//continue 语句用来跳出 for 循环中当前循环。在 continue 语句后的所有的 for 循环语句都不会在本次循环中执行。循环体会在一下次循环中继续执行。
func main() {
for i := 1; i <= 10; i++ {
if i%2 == 0 {
continue
}
fmt.Printf("%d ", i)
}
}
//无限循环
for {
}
3.switch语句
//switch 是一个条件语句,用于将表达式的值与可能匹配的选项列表进行比较,并根据匹配情况执行相应的代码块。它可以被认为是替代多个 if else 子句的常用方式。
//默认情况
//当所有case都不匹配时可以返回一个默认情况
//case判断中不允许有重复的情况出现会报错
package main
import (
"fmt"
)
func main() {
switch finger := 8; finger {
case 1:
fmt.Println("Thumb")
case 2:
fmt.Println("Index")
case 3:
fmt.Println("Middle")
case 4:
fmt.Println("Ring")
case 5:
fmt.Println("Pinky")
default: // 默认情况
fmt.Println("incorrect finger number")
}
}
//多表达式判断
package main
import (
"fmt"
)
func main() {
letter := "i"
switch letter {
case "a", "e", "i", "o", "u": // 一个选项多个表达式
fmt.Println("vowel")
default:
fmt.Println("not a vowel")
}
}
//无表达式判断
package main
import (
"fmt"
)
func main() {
num := 75
switch { // 表达式被省略了
case num >= 0 && num <= 50:
fmt.Println("num is greater than 0 and less than 50")
case num >= 51 && num <= 100:
fmt.Println("num is greater than 51 and less than 100")
case num >= 101:
fmt.Println("num is greater than 100")
}
}
//fallthrough语句
//在 Go 中,每执行完一个 case 后,会从 switch 语句中跳出来,不再做后续 case 的判断和执行。使用 fallthrough 语句可以在已经执行完成的 case 之后,把控制权转移到下一个 case 的执行代码中。
package main
import (
"fmt"
)
func number() int {
num := 15 * 5
return num
}
func main() {
switch num := number(); { // num is not a constant
case num < 50:
fmt.Printf("%d is lesser than 50\n", num)
fallthrough
case num < 100:
fmt.Printf("%d is lesser than 100\n", num)
fallthrough
case num < 200:
fmt.Printf("%d is lesser than 200", num)
}
}
//输出结果
75 is lesser than 100
75 is lesser than 200
7.数组、切片和map
1.数组
//数组的大小是类型的一部分。因此 [5]int 和 [25]int 是不同类型。数组不能调整大小。
//数组是同一类型元素的集合。例如,整数集合 5,8,9,79,76 形成一个数组。Go 语言中不允许混合不同类型的元素,例如包含字符串和整数的数组。
1.数组的声明
//当只声明数组时,数组中的所有元素都被自动赋值为数组类型的零值。
package main
import (
"fmt"
)
func main() {
var a [3]int //int array with length 3
fmt.Println(a)
}
//输出
[0 0 0]
// 数组的索引从0开始
package main
import (
"fmt"
)
func main() {
var a [3]int //int array with length 3
a[0] = 12 // array index starts at 0
a[1] = 78
a[2] = 50
fmt.Println(a)
}
//简略声明
func main() {
a := [3]int{12, 78, 50} // short hand declaration to create array
fmt.Println(a)
}
//在简略声明中,不需要将数组中所有的元素赋值。
func main() {
a := [3]int{12}
fmt.Println(a)
}
//输出
[12 0 0]
//你甚至可以忽略声明数组的长度,并用 ... 代替,让编译器为你自动计算长度
func main() {
a := [...]int{12, 78, 50} // ... makes the compiler determine the length
fmt.Println(a)
}
2.数组时值类型
//Go 中的数组是值类型而不是引用类型。这意味着当数组赋值给一个新的变量时,该变量会得到一个原始数组的一个副本。如果对新变量进行更改,则不会影响原始数组。
package main
import "fmt"
func main() {
a := [...]string{"USA", "China", "India", "Germany", "France"}
b := a // a copy of a is assigned to b
b[0] = "Singapore"
fmt.Println("a is ", a)
fmt.Println("b is ", b)
}
//输出
a is [USA China India Germany France]
b is [Singapore China India Germany France]
//当数组作为参数传递给函数时,它们是按值传递,而原始数组保持不变。
package main
import "fmt"
func changeLocal(num [5]int) {
num[0] = 55
fmt.Println("inside function ", num)
}
func main() {
num := [...]int{5, 6, 7, 8, 8}
fmt.Println("before passing to function ", num)
changeLocal(num) //num is passed by value
fmt.Println("after passing to function ", num)
}
//输出
before passing to function [5 6 7 8 8]
inside function [55 6 7 8 8]
after passing to function [5 6 7 8 8]
3.数组的长度
package main
import "fmt"
func main() {
a := [...]float64{67.7, 89.8, 21, 78}
fmt.Println("length of a is",len(a))
}
4.range迭代数组
package main
import "fmt"
func main() {
a := [...]float64{67.7, 89.8, 21, 78}
sum := float64(0)
for i, v := range a {//range returns both the index and value
fmt.Printf("%d the element of a is %.2f\n", i, v)
sum += v
}
fmt.Println("\nsum of all elements of a",sum)
}
5.多维数组
package main
import (
"fmt"
)
func printarray(a [3][2]string) {
for _, v1 := range a {
for _, v2 := range v1 {
fmt.Printf("%s ", v2)
}
fmt.Printf("\n")
}
}
func main() {
a := [3][2]string{
{"lion", "tiger"},
{"cat", "dog"},
{"pigeon", "peacock"}, // this comma is necessary. The compiler will complain if you omit this comma
}
printarray(a)
var b [3][2]string
b[0][0] = "apple"
b[0][1] = "samsung"
b[1][0] = "microsoft"
b[1][1] = "google"
b[2][0] = "AT&T"
b[2][1] = "T-Mobile"
fmt.Printf("\n")
printarray(b)
}
2.切片
//切片是由数组建立的一种方便、灵活且功能强大的包装(Wrapper)。切片本身不拥有任何数据。它们只是对现有数组的引用。
1.切片的操作
//创建一个切片
func main() {
a := [5]int{76, 77, 78, 79, 80}
var b []int = a[1:4] // creates a slice from a[1] to a[3]
fmt.Println(b)
}
//切片的修改
//切片自己不拥有任何数据。它只是底层数组的一种表示。对切片所做的任何修改都会反映在底层数组中。
func main() {
darr := [...]int{57, 89, 90, 82, 100, 78, 67, 69, 59}
dslice := darr[2:5]
fmt.Println("array before", darr)
for i := range dslice {
dslice[i]++
}
fmt.Println("array after", darr)
}
//输出
array before [57 89 90 82 100 78 67 69 59]
array after [57 89 91 83 101 78 67 69 59]
//多个切片引用同一数组
func main() {
numa := [3]int{78, 79 ,80}
nums1 := numa[:] // creates a slice which contains all elements of the array
nums2 := numa[:]
fmt.Println("array before change 1", numa)
nums1[0] = 100
fmt.Println("array after modification to slice nums1", numa)
nums2[1] = 101
fmt.Println("array after modification to slice nums2", numa)
}
//输出
array before change 1 [78 79 80]
array after modification to slice nums1 [100 79 80]
array after modification to slice nums2 [100 101 80]
//切片的长度是切片中的元素数。切片的容量是从创建切片索引开始的底层数组中元素数。
func main() {
fruitarray := [...]string{"apple", "orange", "grape", "mango", "water melon", "pine apple", "chikoo"}
fruitslice := fruitarray[1:3]
fmt.Printf("length of slice %d capacity %d\n", len(fruitslice), cap(fruitslice)) // length of is 2 and capacity is 6
fruitslice = fruitslice[:cap(fruitslice)] // re-slicing furitslice till its capacity
fmt.Println("After re-slicing length is",len(fruitslice), "and capacity is",cap(fruitslice))
}
//输出
length of slice 2 capacity 6
After re-slicing length is 6 and capacity is 6
//make创建切片
//func make([]T,len,cap)[]T 通过传递类型,长度和容量来创建切片。容量是可选参数, 默认值为切片长度。make 函数创建一个数组,并返回引用该数组的切片。
func main() {
i := make([]int, 5, 5)
fmt.Println(i)
}
//追加切片
//当新的元素被添加到切片时,会创建一个新的数组。现有数组的元素被复制到这个新数组中,并返回这个新数组的新切片引用。现在新切片的容量是旧切片的两倍。
//切片的容量有一套单独的数,不是每次都是翻倍。
func main() {
cars := []string{"Ferrari", "Honda", "Ford"}
fmt.Println("cars:", cars, "has old length", len(cars), "and capacity", cap(cars)) // capacity of cars is 3
cars = append(cars, "Toyota")
fmt.Println("cars:", cars, "has new length", len(cars), "and capacity", cap(cars)) // capacity of cars is doubled to 6
}
//输出
cars: [Ferrari Honda Ford] has old length 3 and capacity 3
cars: [Ferrari Honda Ford Toyota] has new length 4 and capacity 6
//也可以使用 ... 运算符将一个切片添加到另一个切片。
func main() {
veggies := []string{"potatoes", "tomatoes", "brinjal"}
fruits := []string{"oranges", "apples"}
food := append(veggies, fruits...)
fmt.Println("food:",food)
}
//当切片传递给函数时,即使它通过值传递,指针变量也将引用相同的底层数组。因此,当切片作为参数传递给函数时,函数内所做的更改也会在函数外可见。
func subtactOne(numbers []int) {
for i := range numbers {
numbers[i] -= 2
}
}
func main() {
nos := []int{8, 7, 6}
fmt.Println("slice before function call", nos)
subtactOne(nos) // function modifies the slice
fmt.Println("slice after function call", nos) // modifications are visible outside
}
//输出
array before function call [8 7 6]
array after function call [6 5 4]
//多维切片
func main() {
pls := [][]string {
{"C", "C++"},
{"JavaScript"},
{"Go", "Rust"},
}
for _, v1 := range pls {
for _, v2 := range v1 {
fmt.Printf("%s ", v2)
}
fmt.Printf("\n")
}
}
2.内存回收
//切片持有对底层数组的引用。只要切片在内存中,数组就不能被垃圾回收。在内存管理方面,这是需要注意的。让我们假设我们有一个非常大的数组,我们只想处理它的一小部分。然后,我们由这个数组创建一个切片,并开始处理切片。这里需要重点注意的是,在切片引用时数组仍然存在内存中。
一种解决方法是使用 copy函数 func copy(dst,src[]T)int 来生成一个切片的副本。这样我们可以使用新的切片,原始数组可以被垃圾回收。
package main
import (
"fmt"
)
func countries() []string {
countries := []string{"USA", "Singapore", "Germany", "India", "Australia"}
neededCountries := countries[:len(countries)-2]
countriesCpy := make([]string, len(neededCountries))
copy(countriesCpy, neededCountries) //copies neededCountries to countriesCpy
return countriesCpy
}
func main() {
countriesNeeded := countries()
fmt.Println(countriesNeeded)
}
//在上述程序的第 9 行,neededCountries := countries[:len(countries)-2 创建一个去掉尾部 2 个元素的切片 countries,在上述程序的 11 行,将 neededCountries 复制到 countriesCpy 同时在函数的下一行返回 countriesCpy。现在 countries 数组可以被垃圾回收, 因为 neededCountries 不再被引用。
3.切片的容量计算
//runtime/slice.go 关于 slice 扩容增长的代码如下:
newcap := old.cap
if newcap+newcap < cap {
newcap = cap
} else {
for {
if old.len < 1024 {
newcap += newcap
} else {
newcap += newcap / 4
}
if newcap >= cap {
break
}
}
}
对于这段代码,只要理解前两行,其他的就不攻自破了
- 第一行的 old.cap:扩容前的容量,对于此例,就是 2
- 第二行的 cap:扩容前容量加上扩容的元素数量,对于此例,就是 2+3
整段代码的核心就是要计算出扩容后的预估容量,也就是 newcap,计算的具体逻辑是:
- 若 old.cap * 2 小于 cap,那 newcap 就取大的 cap
- 若 old.cap * 2 大于 cap,并且old.cap 小于 1024,那 newcap 还是取大,也即 newcap = old.cap * 2
- 若 old.cap * 2 大于 cap,但是old.cap 大于 1024,那两倍冗余可能就有点大了,系数换成 1.25,也即 newcap = old.cap * 2
但 newcap 只是预估容量,并不是最终的容量,要计算最终的容量,还需要参考另一个维度,也就是内存分配。
3.maps
//map 是在 Go 中将值(value)与键(key)关联的内置类型。通过相应的键可以获取到值。
personSalary := make(map[string]int)
1.map新增元素
func main() {
personSalary := make(map[string]int)
personSalary["steve"] = 12000
personSalary["jamie"] = 15000
personSalary["mike"] = 9000
fmt.Println("personSalary map contents:", personSalary)
}
//声明时初始化元素
personSalary := map[string]int {
"steve": 12000,
"jamie": 15000,
}
2.获取元素
//当获取一个不存在的元素时会返回0值
func main() {
personSalary := map[string]int{
"steve": 12000,
"jamie": 15000,
}
personSalary["mike"] = 9000
employee := "jamie"
fmt.Println("Salary of", employee, "is", personSalary[employee])
fmt.Println("Salary of joe is", personSalary["joe"])
}
//输出
Salary of jamie is 15000
Salary of joe is 0
//判断是否i存在对应的key
func main() {
personSalary := map[string]int{
"steve": 12000,
"jamie": 15000,
}
personSalary["mike"] = 9000
newEmp := "joe"
value, ok := personSalary[newEmp]
if ok == true {
fmt.Println("Salary of", newEmp, "is", value)
} else {
fmt.Println(newEmp,"not found")
}
}
//遍历map
func main() {
personSalary := map[string]int{
"steve": 12000,
"jamie": 15000,
}
personSalary["mike"] = 9000
fmt.Println("All items of a map")
for key, value := range personSalary {
fmt.Printf("personSalary[%s] = %d\n", key, value)
}
}
3.删除元素
//删除 map 中 key 的语法是 delete(map, key)。这个函数没有返回值。
func main() {
personSalary := map[string]int{
"steve": 12000,
"jamie": 15000,
}
personSalary["mike"] = 9000
fmt.Println("map before deletion", personSalary)
delete(personSalary, "steve")
fmt.Println("map after deletion", personSalary)
}
//获取长度,len函数
func main() {
personSalary := map[string]int{
"steve": 12000,
"jamie": 15000,
}
personSalary["mike"] = 9000
fmt.Println("length is", len(personSalary))
}
4.map特性
//和 slices类似,map 也是引用类型。当 map 被赋值为一个新变量的时候,它们指向同一个内部数据结构。因此,改变其中一个变量,就会影响到另一变量。
//当 map 作为函数参数传递时也会发生同样的情况。函数中对 map 的任何修改,对于外部的调用都是可见的。
func main() {
personSalary := map[string]int{
"steve": 12000,
"jamie": 15000,
}
personSalary["mike"] = 9000
fmt.Println("Original person salary", personSalary)
newPersonSalary := personSalary
newPersonSalary["mike"] = 18000
fmt.Println("Person salary changed", personSalary)
}
//输出
Original person salary map[steve:12000 jamie:15000 mike:9000]
Person salary changed map[steve:12000 jamie:15000 mike:18000]
//map 之间不能使用 == 操作符判断,== 只能用来检查 map 是否为 nil。
8.字符串
//Go 语言中的字符串是一个字节切片。
//Go 中的字符串是兼容 Unicode 编码的,并且使用 UTF-8 进行编码。
//循环字符串
func printCharsAndBytes(s string) {
for index, rune := range s {
fmt.Printf("%c starts at byte %d\n", rune, index)
}
}
func main() {
name := "Señor"
printCharsAndBytes(name)
}
//用len函数获取字符串长度
func length(s string) {
fmt.Printf("length of %s is %d\n", s, utf8.RuneCountInString(s))
}
func main() {
word1 := "Señor"
length(word1)
word2 := "Pets"
length(word2)
}
//Go 中的字符串是不可变的。一旦一个字符串被创建,那么它将无法被修改。
9.指针
指针是一种存储变量内存地址(Memory Address)的变量。
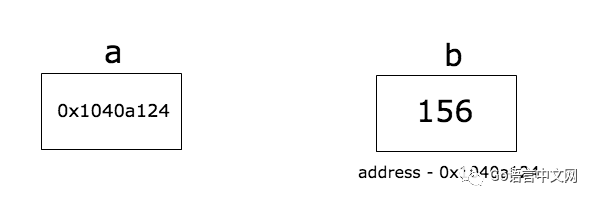
如上图所示,变量 b 的值为 156,而 b 的内存地址为 0x1040a124。变量 a 存储了 b 的地址。我们就称 a 指向了 b。
//指针变量的类型为 \*T,该指针指向一个 T 类型的变量。
1.指针的声明
//指针变量的类型为 \*T,该指针指向一个 T 类型的变量。
package main
import (
"fmt"
)
func main() {
b := 255
var a *int = &b
fmt.Printf("Type of a is %T\n", a)
fmt.Println("address of b is", a)
}
//& 操作符用于获取变量的地址。上面程序的第 9 行我们把 b 的地址赋值给 *int 类型的 a。我们称 a 指向了 b。当我们打印 a 的值时,会打印出 b 的地址。程序将输出:
Type of a is *int
address of b is 0x1040a124
//由于 b 可能处于内存的任何位置,你应该会得到一个不同的地址。
2.指针的零值
//指针的零值是 nil。
package main
import (
"fmt"
)
func main() {
a := 25
var b *int
if b == nil {
fmt.Println("b is", b)
b = &a
fmt.Println("b after initialization is", b)
}
}
//上面的程序中,b 初始化为 nil,接着将 a 的地址赋值给 b。程序会输出:
b is <nil>
b after initialisation is 0x1040a124
3.指针的解引用
指针的解引用可以获取指针所指向的变量的值。将 a 解引用的语法是 *a。
func main() {
b := 255
a := &b
fmt.Println("address of b is", a)
fmt.Println("value of b is", *a)
*a++
fmt.Println("new value of b is", b)
}
//在上面程序的第 12 行中,我们把 a 指向的值加 1,由于 a 指向了 b,因此 b 的值也发生了同样的改变。于是 b 的值变为 256。程序会输出:
address of b is 0x1040a124
value of b is 255
new value of b is 256
4.向函数传递指针
func change(val *int) {
*val = 55
}
func main() {
a := 58
fmt.Println("value of a before function call is",a)
b := &a
change(b)
fmt.Println("value of a after function call is", a)
}
5.用切片向函数传递指针,不要使用数组
package main
import (
"fmt"
)
func modify(sls []int) {
sls[0] = 90
}
func main() {
a := [3]int{89, 90, 91}
modify(a[:])
fmt.Println(a)
}
6.go不支持指针运算
Go 并不支持其他语言(例如 C)中的指针运算。
10.结构体
1.结构体声明
//命名结构体
type Employee struct {
firstName string
lastName string
age int
}
//初始化
emp1 := Employee{
firstName: "Sam",
age: 25,
salary: 500,
lastName: "Anderson",
}
//匿名结构体
var employee struct {
firstName, lastName string
age int
}
//初始化
emp3 := struct {
firstName, lastName string
age, salary int
}{
firstName: "Andreah",
lastName: "Nikola",
age: 31,
salary: 5000,
}
2.结构体的零值
当定义好的结构体并没有被显式地初始化时,该结构体的字段将默认赋为零值。
package main
import (
"fmt"
)
type Employee struct {
firstName, lastName string
age, salary int
}
func main() {
var emp4 Employee //zero valued structure
fmt.Println("Employee 4", emp4)
}
//输出
Employee 4 { 0 0}
//当然还可以为某些字段指定初始值,而忽略其他字段。这样,忽略的字段名会赋值为零值。
3.访问结构体字段
点号操作符 . 用于访问结构体的字段。
type Employee struct {
firstName, lastName string
age, salary int
}
func main() {
emp6 := Employee{"Sam", "Anderson", 55, 6000}
fmt.Println("First Name:", emp6.firstName)
fmt.Println("Last Name:", emp6.lastName)
fmt.Println("Age:", emp6.age)
fmt.Printf("Salary: $%d", emp6.salary)
}
4.结构体指针
创建指向结构体的指针
package main
import (
"fmt"
)
type Employee struct {
firstName, lastName string
age, salary int
}
func main() {
emp8 := &Employee{"Sam", "Anderson", 55, 6000}
fmt.Println("First Name:", (*emp8).firstName)
fmt.Println("Age:", (*emp8).age)
}
//Go 语言允许我们在访问 firstName 字段时,可以使用 emp8.firstName 来代替显式的解引用 (\*emp8).firstName。
5.匿名字段
//当我们创建结构体时,字段可以只有类型,而没有字段名。这样的字段称为匿名字段
//虽然匿名字段没有名称,但其实匿名字段的名称就默认为它的类型
type Person struct {
string
int
}
func main() {
var p1 Person
p1.string = "naveen"
p1.int = 50
fmt.Println(p1)
}
6.结构体嵌套
结构体的字段有可能也是一个结构体。这样的结构体称为嵌套结构体。
package main
import (
"fmt"
)
type Address struct {
city, state string
}
type Person struct {
name string
age int
address Address
}
func main() {
var p Person
p.name = "Naveen"
p.age = 50
p.address = Address {
city: "Chicago",
state: "Illinois",
}
fmt.Println("Name:", p.name)
fmt.Println("Age:",p.age)
fmt.Println("City:",p.address.city)
fmt.Println("State:",p.address.state)
}
7.提升字段
//如果是结构体中有匿名的结构体类型字段,则该匿名结构体里的字段就称为提升字段。这是因为提升字段就像是属于外部结构体一样,可以用外部结构体直接访问。
package main
import (
"fmt"
)
type Address struct {
city, state string
}
type Person struct {
name string
age int
Address
}
func main() {
var p Person
p.name = "Naveen"
p.age = 50
p.Address = Address{
city: "Chicago",
state: "Illinois",
}
fmt.Println("Name:", p.name)
fmt.Println("Age:", p.age)
fmt.Println("City:", p.city) //city is promoted field
fmt.Println("State:", p.state) //state is promoted field
}
8.导出字段
如果结构体名称以大写字母开头,则它是其他包可以访问的导出类型(Exported Type)。同样,如果结构体里的字段首字母大写,它也能被其他包访问到。
package computer
type Spec struct { //exported struct
Maker string //exported field
model string //unexported field
Price int //exported field
}
9.结构体相等性
//结构体是值类型。如果它的每一个字段都是可比较的,则该结构体也是可比较的。如果两个结构体变量的对应字段相等,则这两个变量也是相等的。
//如果结构体包含不可比较的字段,则结构体变量也不可比较。
package main
import (
"fmt"
)
type name struct {
firstName string
lastName string
}
func main() {
name1 := name{"Steve", "Jobs"}
name2 := name{"Steve", "Jobs"}
if name1 == name2 {
fmt.Println("name1 and name2 are equal")
} else {
fmt.Println("name1 and name2 are not equal")
}
name3 := name{firstName:"Steve", lastName:"Jobs"}
name4 := name{}
name4.firstName = "Steve"
if name3 == name4 {
fmt.Println("name3 and name4 are equal")
} else {
fmt.Println("name3 and name4 are not equal")
}
11.方法
方法其实就是一个函数,在 func 这个关键字和方法名中间加入了一个特殊的接收器类型。接收器可以是结构体类型或者是非结构体类型。接收器是可以在方法的内部访问的。
1.方法示例
package main
import (
"fmt"
)
type Employee struct {
name string
salary int
currency string
}
/*
displaySalary() 方法将 Employee 做为接收器类型
*/
func (e Employee) displaySalary() {
fmt.Printf("Salary of %s is %s%d", e.name, e.currency, e.salary)
}
func main() {
emp1 := Employee {
name: "Sam Adolf",
salary: 5000,
currency: "$",
}
emp1.displaySalary() // 调用 Employee 类型的 displaySalary() 方法
}
2.值接收器和指针接收器
值接收器只可以接收值类型数据,指针接收器可以接收值和指针类型数据
值接收器和指针接收器之间的区别在于,在指针接收器的方法内部的改变对于调用者是可见的,然而值接收器的情况不是这样的。
package main
import (
"fmt"
)
type Employee struct {
name string
age int
}
/*
使用值接收器的方法。
*/
func (e Employee) changeName(newName string) {
e.name = newName
}
/*
使用指针接收器的方法。
*/
func (e *Employee) changeAge(newAge int) {
e.age = newAge
}
func main() {
e := Employee{
name: "Mark Andrew",
age: 50,
}
fmt.Printf("Employee name before change: %s", e.name)
e.changeName("Michael Andrew")
fmt.Printf("\nEmployee name after change: %s", e.name)
fmt.Printf("\n\nEmployee age before change: %d", e.age)
(&e).changeAge(51)
fmt.Printf("\nEmployee age after change: %d", e.age)
}
"""
在上面的程序中,changeName 方法有一个值接收器 (e Employee),而 changeAge 方法有一个指针接收器 (e *Employee)。在 changeName 方法中对 Employee 结构体的字段 name 所做的改变对调用者是不可见的,因此程序在调用 e.changeName("Michael Andrew") 这个方法的前后打印出相同的名字。由于 changeAge 方法是使用指针 (e *Employee) 接收器的,所以在调用 (&e).changeAge(51) 方法对 age 字段做出的改变对调用者将是可见的。该程序输出如下:
"""
Employee name before change: Mark Andrew
Employee name after change: Mark Andrew
Employee age before change: 50
Employee age after change: 51
3.匿名字段方法
属于结构体的匿名字段的方法可以被直接调用,就好像这些方法是属于定义了匿名字段的结构体一样。
package main
import (
"fmt"
)
type address struct {
city string
state string
}
func (a address) fullAddress() {
fmt.Printf("Full address: %s, %s", a.city, a.state)
}
type person struct {
firstName string
lastName string
address
}
func main() {
p := person{
firstName: "Elon",
lastName: "Musk",
address: address {
city: "Los Angeles",
state: "California",
},
}
p.fullAddress() //访问 address 结构体的 fullAddress 方法
}
4.在方法中使用值接收器与在函数中使用参数
当一个函数有一个值参数,它只能接受一个值参数。
当一个方法有一个值接收器,它可以接受值接收器和指针接收器。
package main
import (
"fmt"
)
type rectangle struct {
length int
width int
}
func area(r rectangle) {
fmt.Printf("Area Function result: %d\n", (r.length * r.width))
}
func (r rectangle) area() {
fmt.Printf("Area Method result: %d\n", (r.length * r.width))
}
func main() {
r := rectangle{
length: 10,
width: 5,
}
area(r)
r.area()
p := &r
/*
compilation error, cannot use p (type *rectangle) as type rectangle
in argument to area
*/
//area(p)
p.area()//通过指针调用值接收器
}
”“”
第 12 行的函数 func area(r rectangle) 接受一个值参数,方法 func (r rectangle) area() 接受一个值接收器。
在第 25 行,我们通过值参数 area(r) 来调用 area 这个函数,这是合法的。同样,我们使用值接收器来调用 area 方法 r.area(),这也是合法的。
在第 28 行,我们创建了一个指向 r 的指针 p。如果我们试图把这个指针传递到只能接受一个值参数的函数 area,编译器将会报错。所以我把代码的第 33 行注释了。如果你把这行的代码注释去掉,编译器将会抛出错误 compilation error, cannot use p (type *rectangle) as type rectangle in argument to area.。这将会按预期抛出错误。
现在到了棘手的部分了,在第35行的代码 p.area() 使用指针接收器 p 调用了只接受一个值接收器的方法 area。这是完全有效的。原因是当 area 有一个值接收器时,为了方便Go语言把 p.area() 解释为 (*p).area()。
该程序将会输出:
“”“
Area Function result: 50
Area Method result: 50
Area Method result: 50
5.非结构体方法
//为了在一个类型上定义一个方法,方法的接收器类型定义和方法的定义应该在同一个包中。到目前为止,我们定义的所有结构体和结构体上的方法都是在同一个 main 包中,因此它们是可以运行的。
package main
import "fmt"
type myInt int
func (a myInt) add(b myInt) myInt {
return a + b
}
func main() {
num1 := myInt(5)
num2 := myInt(10)
sum := num1.add(num2)
fmt.Println("Sum is", sum)
}
12.接口
接口指定了一个类型应该具有的方法,并由该类型决定如何实现这些方法。
1.接口的定义与实现
package main
import (
"fmt"
)
//interface definition
type VowelsFinder interface {
FindVowels() []rune
}
type MyString string
//MyString implements VowelsFinder
func (ms MyString) FindVowels() []rune {
var vowels []rune
for _, rune := range ms {
if rune == 'a' || rune == 'e' || rune == 'i' || rune == 'o' || rune == 'u' {
vowels = append(vowels, rune)
}
}
return vowels
}
func main() {
name := MyString("Sam Anderson")
var v VowelsFinder
v = name // possible since MyString implements VowelsFinder
fmt.Printf("Vowels are %c", v.FindVowels())
}
//接口VowelsFinder下有一个FindVowels方法,而结构体MyString包含了FindVowels方法,我们则认为MyString实现了该接口。
//如果一个接口下的所有方法都被某个结构体包含,则认为改结构体实现了该接口。
2.空接口
没有包含方法的接口称为空接口。空接口表示为 interface{}。由于空接口没有方法,因此所有类型都实现了空接口。
package main
import (
"fmt"
)
func describe(i interface{}) {
fmt.Printf("Type = %T, value = %v\n", i, i)
}
func main() {
s := "Hello World"
describe(s)
i := 55
describe(i)
strt := struct {
name string
}{
name: "Naveen R",
}
describe(strt)
}
3.类型断言
类型断言用于提取接口的底层值(Underlying Value)。
在语法 i.(T) 中,接口 i 的具体类型是 T,该语法用于获得接口的底层值。
package main
import (
"fmt"
)
func assert(i interface{}) {
v, ok := i.(int)
fmt.Println(v, ok)
}
func main() {
var s interface{} = 56
assert(s)
var i interface{} = "Steven Paul"
assert(i)
}
//类型断言一般用于对要处理的数据不确定其类型时使用
//类型选择
类型选择用于将接口的具体类型与很多 case 语句所指定的类型进行比较。它与一般的 switch 语句类似。唯一的区别在于类型选择指定的是类型,而一般的 switch 指定的是值。
类型选择的语法类似于类型断言。类型断言的语法是 i.(T),而对于类型选择,类型 T 由关键字 type 代替。
package main
import (
"fmt"
)
func findType(i interface{}) {
switch i.(type) {
case string:
fmt.Printf("I am a string and my value is %s\n", i.(string))
case int:
fmt.Printf("I am an int and my value is %d\n", i.(int))
default:
fmt.Printf("Unknown type\n")
}
}
func main() {
findType("Naveen")
findType(77)
findType(89.98)
}
//还可以将一个类型和接口相比较。如果一个类型实现了接口,那么该类型与其实现的接口就可以互相比较。
package main
import "fmt"
type Describer interface {
Describe()
}
type Person struct {
name string
age int
}
func (p Person) Describe() {
fmt.Printf("%s is %d years old", p.name, p.age)
}
func findType(i interface{}) {
switch v := i.(type) {
case Describer:
v.Describe()
default:
fmt.Printf("unknown type\n")
}
}
func main() {
findType("Naveen")
p := Person{
name: "Naveen R",
age: 25,
}
findType(p)
}
4.指针接受者与值接受者
package main
import "fmt"
type Describer interface {
Describe()
}
type Person struct {
name string
age int
}
func (p Person) Describe() { // 使用值接受者实现
fmt.Printf("%s is %d years old\n", p.name, p.age)
}
type Address struct {
state string
country string
}
func (a *Address) Describe() { // 使用指针接受者实现
fmt.Printf("State %s Country %s", a.state, a.country)
}
func main() {
var d1 Describer
p1 := Person{"Sam", 25}
d1 = p1
d1.Describe()
p2 := Person{"James", 32}
d1 = &p2
d1.Describe()
var d2 Describer
a := Address{"Washington", "USA"}
/* 如果下面一行取消注释会导致编译错误:
cannot use a (type Address) as type Describer
in assignment: Address does not implement
Describer (Describe method has pointer
receiver)
*/
//d2 = a
d2 = &a // 这是合法的
// 因为在第 22 行,Address 类型的指针实现了 Describer 接口
d2.Describe()
}
//对于使用指针接受者的方法,用一个指针或者一个可取得地址的值来调用都是合法的。但接口中存储的具体值(Concrete Value)并不能取到地址,因此在第 45 行,对于编译器无法自动获取 a 的地址,于是程序报错。
5.多接口
类型可以实现多个接口
package main
import (
"fmt"
)
type SalaryCalculator interface {
DisplaySalary()
}
type LeaveCalculator interface {
CalculateLeavesLeft() int
}
type Employee struct {
firstName string
lastName string
basicPay int
pf int
totalLeaves int
leavesTaken int
}
func (e Employee) DisplaySalary() {
fmt.Printf("%s %s has salary $%d", e.firstName, e.lastName, (e.basicPay + e.pf))
}
func (e Employee) CalculateLeavesLeft() int {
return e.totalLeaves - e.leavesTaken
}
func main() {
e := Employee {
firstName: "Naveen",
lastName: "Ramanathan",
basicPay: 5000,
pf: 200,
totalLeaves: 30,
leavesTaken: 5,
}
var s SalaryCalculator = e
s.DisplaySalary()
var l LeaveCalculator = e
fmt.Println("\nLeaves left =", l.CalculateLeavesLeft())
}
6.接口嵌套
ackage main
import (
"fmt"
)
type SalaryCalculator interface {
DisplaySalary()
}
type LeaveCalculator interface {
CalculateLeavesLeft() int
}
type EmployeeOperations interface {
SalaryCalculator
LeaveCalculator
}
type Employee struct {
firstName string
lastName string
basicPay int
pf int
totalLeaves int
leavesTaken int
}
func (e Employee) DisplaySalary() {
fmt.Printf("%s %s has salary $%d", e.firstName, e.lastName, (e.basicPay + e.pf))
}
func (e Employee) CalculateLeavesLeft() int {
return e.totalLeaves - e.leavesTaken
}
func main() {
e := Employee {
firstName: "Naveen",
lastName: "Ramanathan",
basicPay: 5000,
pf: 200,
totalLeaves: 30,
leavesTaken: 5,
}
var empOp EmployeeOperations = e
empOp.DisplaySalary()
fmt.Println("\nLeaves left =", empOp.CalculateLeavesLeft())
}
7.接口零值
接口的零值是 nil。对于值为 nil 的接口,其底层值(Underlying Value)和具体类型(Concrete Type)都为 nil。
对于值为 nil 的接口,由于没有底层值和具体类型,当我们试图调用它的方法时,程序会产生 panic 异常。
package main
import "fmt"
type Describer interface {
Describe()
}
func main() {
var d1 Describer
if d1 == nil {
fmt.Printf("d1 is nil and has type %T value %v\n", d1, d1)
}
}
//输出
d1 is nil and has type <nil> value <nil>
13.协程
- 启动一个新的协程时,协程的调用会立即返回。与函数不同,程序控制不会去等待 Go 协程执行完毕。在调用 Go 协程之后,程序控制会立即返回到代码的下一行,忽略该协程的任何返回值。
- 如果希望运行其他 Go 协程,Go 主协程必须继续运行着。如果 Go 主协程终止,则程序终止,于是其他 Go 协程也不会继续运行。
package main
import (
"fmt"
"time"
)
func hello() {
fmt.Println("Hello world goroutine")
}
func main() {
go hello()
time.Sleep(1 * time.Second)
fmt.Println("main function")
}
在上面程序的第 13 行,我们调用了 time 包里的函数 Sleep[4],该函数会休眠执行它的 Go 协程。在这里,我们使 Go 主协程休眠了 1 秒。因此在主协程终止之前,调用 go hello() 就有足够的时间来执行了。该程序首先打印 Hello world goroutine,等待 1 秒钟之后,接着打印 main function。
在 Go 主协程中使用休眠,以便等待其他协程执行完毕,这种方法只是用于理解 Go 协程如何工作的技巧。信道可用于在其他协程结束执行之前,阻塞 Go 主协程。
//多协程
package main
import (
"fmt"
"time"
)
func numbers() {
for i := 1; i <= 5; i++ {
time.Sleep(250 * time.Millisecond)
fmt.Printf("%d ", i)
}
}
func alphabets() {
for i := 'a'; i <= 'e'; i++ {
time.Sleep(400 * time.Millisecond)
fmt.Printf("%c ", i)
}
}
func main() {
go numbers()
go alphabets()
time.Sleep(3000 * time.Millisecond)
fmt.Println("main terminated")
}
第一张蓝色的图表示 numbers 协程,第二张褐红色的图表示 alphabets 协程,第三张绿色的图表示 Go 主协程,而最后一张黑色的图把以上三种协程合并了,表明程序是如何运行的。在每个方框顶部,诸如 0 ms 和 250 ms 这样的字符串表示时间(以微秒为单位)。在每个方框的底部,1、2、3 等表示输出。蓝色方框表示:250 ms 打印出 1,500 ms 打印出 2,依此类推。最后黑色方框的底部的值会是 1 a 2 3 b 4 c 5 d e main terminated,这同样也是整个程序的输出。以上图片非常直观,你可以用它来理解程序是如何运作的。
14.信道
信道可以想像成 Go 协程之间通信的管道。如同管道中的水会从一端流到另一端,通过使用信道,数据也可以从一端发送,在另一端接收。
所有信道都关联了一个类型。信道只能运输这种类型的数据,而运输其他类型的数据都是非法的。
chan T 表示 T 类型的信道。
信道的零值为 nil。信道的零值没有什么用,应该像对 map 和切片所做的那样,用 make 来定义信道。
package main
import "fmt"
func main() {
var a chan int
if a == nil {
fmt.Println("channel a is nil, going to define it")
a = make(chan int)
fmt.Printf("Type of a is %T", a)
}
}
1.信道的数据发送与接收
在第一行,箭头对于 a 来说是向外指的,因此我们读取了信道 a 的值,并把该值存储到变量 data。
在第二行,箭头指向了 a,因此我们在把数据写入信道 a。
data := <- a // 读取信道 a
a <- data // 写入信道 a
2.信道阻塞
发送与接收默认是阻塞的。这是什么意思?当把数据发送到信道时,程序控制会在发送数据的语句处发生阻塞,直到有其它 Go 协程从信道读取到数据,才会解除阻塞。与此类似,当读取信道的数据时,如果没有其它的协程把数据写入到这个信道,那么读取过程就会一直阻塞着。
信道的这种特性能够帮助 Go 协程之间进行高效的通信,不需要用到其他编程语言常见的显式锁或条件变量。
package main
import (
"fmt"
"time"
)
func hello(done chan bool) {
fmt.Println("hello go routine is going to sleep")
time.Sleep(4 * time.Second)
fmt.Println("hello go routine awake and going to write to done")
done <- true
}
func main() {
done := make(chan bool)
fmt.Println("Main going to call hello go goroutine")
go hello(done)
<-done
fmt.Println("Main received data")
}
//程序首先会打印 Main going to call hello go goroutine。接着会开启 hello 协程,打印 hello go routine is going to sleep。打印完之后,hello 协程会休眠 4 秒钟,而在这期间,主协程会在 <-done 这一行发生阻塞,等待来自信道 done 的数据。4 秒钟之后,打印 hello go routine awake and going to write to done,接着再打印 Main received data。
3.死锁
使用信道需要考虑的一个重点是死锁。当 Go 协程给一个信道发送数据时,照理说会有其他 Go 协程来接收数据。如果没有的话,程序就会在运行时触发 panic,形成死锁。
同理,当有 Go 协程等着从一个信道接收数据时,我们期望其他的 Go 协程会向该信道写入数据,要不然程序就会触发 panic。
package main
func main() {
ch := make(chan int)
ch <- 5
}
4.单向信道
我们目前讨论的信道都是双向信道,即通过信道既能发送数据,又能接收数据。其实也可以创建单向信道,这种信道只能发送或者接收数据。
这就需要用到信道转换(Channel Conversion)了。把一个双向信道转换成唯送信道或者唯收(Receive Only)信道都是行得通的,但是反过来就不行。
package main
import "fmt"
func sendData(sendch chan<- int) {
sendch <- 10
}
func main() {
cha1 := make(chan int)
go sendData(cha1)
fmt.Println(<-cha1)
}
5.关闭信道和遍历信道
数据发送方可以关闭信道,通知接收方这个信道不再有数据发送过来。
当从信道接收数据时,接收方可以多用一个变量来检查信道是否已经关闭。
package main
import (
"fmt"
)
func producer(chnl chan int) {
for i := 0; i < 10; i++ {
chnl <- i
}
close(chnl)
}
func main() {
ch := make(chan int)
go producer(ch)
for v := range ch {
fmt.Println("Received ",v)
}
}
package main
import (
"fmt"
)
func digits(number int, dchnl chan int) {
for number != 0 {
digit := number % 10
dchnl <- digit
number /= 10
}
close(dchnl)
}
func calcSquares(number int, squareop chan int) {
sum := 0
dch := make(chan int)
go digits(number, dch)
for digit := range dch {
sum += digit * digit
}
squareop <- sum
}
func calcCubes(number int, cubeop chan int) {
sum := 0
dch := make(chan int)
go digits(number, dch)
for digit := range dch {
sum += digit * digit * digit
}
cubeop <- sum
}
func main() {
number := 589
sqrch := make(chan int)
cubech := make(chan int)
go calcSquares(number, sqrch)
go calcCubes(number, cubech)
squares, cubes := <-sqrch, <-cubech
fmt.Println("Final output", squares+cubes)
}
6. 缓冲信道
我们还可以创建一个有缓冲(Buffer)的信道。只在缓冲已满的情况,才会阻塞向缓冲信道(Buffered Channel)发送数据。同样,只有在缓冲为空的时候,才会阻塞从缓冲信道接收数据。
通过向 make 函数再传递一个表示容量的参数(指定缓冲的大小),可以创建缓冲信道。
ch := make(chan type, capacity)
//要让一个信道有缓冲,上面语法中的 capacity 应该大于 0。无缓冲信道的容量默认为 0,因此我们在上一教程创建信道时,省略了容量参数。
package main
import (
"fmt"
"time"
)
func write(ch chan int) {
for i := 0; i < 5; i++ {
ch <- i
fmt.Println("successfully wrote", i, "to ch")
}
close(ch)
}
func main() {
ch := make(chan int, 2)
go write(ch)
time.Sleep(2 * time.Second)
for v := range ch {
fmt.Println("read value", v,"from ch")
time.Sleep(2 * time.Second)
}
}
package main
import (
"fmt"
)
func main() {
ch := make(chan string, 2)
ch <- "naveen"
ch <- "paul"
ch <- "steve"
fmt.Println(<-ch)
fmt.Println(<-ch)
}
在上面程序里,我们向容量为 2 的缓冲信道写入 3 个字符串。当在程序控制到达第 3 次写入时(第 11 行),由于它超出了信道的容量,因此这次写入发生了阻塞。现在想要这次写操作能够进行下去,必须要有其它协程来读取这个信道的数据。但在本例中,并没有并发协程来读取这个信道,因此这里会发生死锁(deadlock)。
7.长度和容量
缓冲信道的容量是指信道可以存储的值的数量。我们在使用 make 函数创建缓冲信道的时候会指定容量大小。
缓冲信道的长度是指信道中当前排队的元素个数。
package main
import (
"fmt"
)
func main() {
ch := make(chan string, 3)
ch <- "naveen"
ch <- "paul"
fmt.Println("capacity is", cap(ch))
fmt.Println("length is", len(ch))
fmt.Println("read value", <-ch)
fmt.Println("new length is", len(ch))
}
8.WaitGroup
WaitGroup 用于等待一批 Go 协程执行结束。程序控制会一直阻塞,直到这些协程全部执行完毕。假设我们有 3 个并发执行的 Go 协程(由 Go 主协程生成)。Go 主协程需要等待这 3 个协程执行结束后,才会终止。这就可以用 WaitGroup 来实现。
package main
import (
"fmt"
"sync"
"time"
)
func process(i int, wg *sync.WaitGroup) {
fmt.Println("started Goroutine ", i)
time.Sleep(2 * time.Second)
fmt.Printf("Goroutine %d ended\n", i)
wg.Done()
}
func main() {
no := 3
var wg sync.WaitGroup
for i := 0; i < no; i++ {
wg.Add(1)
go process(i, &wg)
}
wg.Wait()
fmt.Println("All go routines finished executing")
}
9.工作池
- 创建一个 Go 协程池,监听一个等待作业分配的输入型缓冲信道。
- 将作业添加到该输入型缓冲信道中。
- 作业完成后,再将结果写入一个输出型缓冲信道。
- 从输出型缓冲信道读取并打印结果。
package main
import (
"fmt"
"math/rand"
"sync"
"time"
)
type Job struct {
id int
randomno int
}
type Result struct {
job Job
sumofdigits int
}
var jobs = make(chan Job, 10)
var results = make(chan Result, 10)
func digits(number int) int {
sum := 0
no := number
for no != 0 {
digit := no % 10
sum += digit
no /= 10
}
time.Sleep(2 * time.Second)
return sum
}
func worker(wg *sync.WaitGroup) {
for job := range jobs {
output := Result{job, digits(job.randomno)}
results <- output
}
wg.Done()
}
func createWorkerPool(noOfWorkers int) {
var wg sync.WaitGroup
for i := 0; i < noOfWorkers; i++ {
wg.Add(1)
go worker(&wg)
}
wg.Wait()
close(results)
}
func allocate(noOfJobs int) {
for i := 0; i < noOfJobs; i++ {
randomno := rand.Intn(999)
job := Job{i, randomno}
jobs <- job
}
close(jobs)
}
func result(done chan bool) {
for result := range results {
fmt.Printf("Job id %d, input random no %d , sum of digits %d\n", result.job.id, result.job.randomno, result.sumofdigits)
}
done <- true
}
func main() {
startTime := time.Now()
noOfJobs := 100
go allocate(noOfJobs)
done := make(chan bool)
go result(done)
noOfWorkers := 10
createWorkerPool(noOfWorkers)
<-done
endTime := time.Now()
diff := endTime.Sub(startTime)
fmt.Println("total time taken ", diff.Seconds(), "seconds")
}
