Java多线程之Fork/Join框架和障碍器
1 Fork/Join框架
1.1 什么是Fork/Join框架
Fork/Join框架是Java7提供了的一个用于并行执行任务的框架, 是一个把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果的框架。
我们再通过Fork和Join这两个单词来理解下Fork/Join框架,Fork就是把一个大任务切分为若干子任务并行的执行,Join就是合并这些子任务的执行结果,最后得到这个大任务的结果。比如计算1+2+。。+10000,可以分割成10个子任务,每个子任务分别对1000个数进行求和,最终汇总这10个子任务的结果。
1.2 工作窃取算法
工作窃取(work-stealing)算法是指某个线程从其他队列里窃取任务来执行。工作窃取的运行流程图如下:

那么为什么需要使用工作窃取算法呢?假如我们需要做一个比较大的任务,我们可以把这个任务分割为若干互不依赖的子任务,为了减少线程间的竞争,于是把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里的任务,线程和队列一一对应,比如A线程负责处理A队列里的任务。但是有的线程会先把自己队列里的任务干完,而其他线程对应的队列里还有任务等待处理。干完活的线程与其等着,不如去帮其他线程干活,于是它就去其他线程的队列里窃取一个任务来执行。而在这时它们会访问同一个队列,所以为了减少窃取任务线程和被窃取任务线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行。
工作窃取算法的优点是充分利用线程进行并行计算,并减少了线程间的竞争,其缺点是在某些情况下还是存在竞争,比如双端队列里只有一个任务时。并且消耗了更多的系统资源,比如创建多个线程和多个双端队列。
1.3 Fork/Join框架的介绍
我们已经很清楚Fork/Join框架的需求了,那么我们可以思考一下,如果让我们来设计一个Fork/Join框架,该如何设计?这个思考有助于理解Fork/Join框架的设计。
- 第一步分割任务。首先我们需要有一个
fork类来把大任务分割成子任务,有可能子任务还是很大,所以还需要不停的分割,直到分割出的子任务足够小。 - 第二步执行任务并合并结果。分割的子任务分别放在双端队列里,然后几个启动线程分别从双端队列里获取任务执行。子任务执行完的结果都统一放在一个队列里,启动一个线程从队列里拿数据,然后合并这些数据。
Fork/Join使用两个类来完成以上两件事情:
ForkJoinTask:我们要使用ForkJoin框架,必须首先创建一个ForkJoin任务。它提供在任务中执行fork()和join()操作的机制,通常情况下我们不需要直接继承ForkJoinTask类,而只需要继承它的子类,Fork/Join框架提供了以下两个子类:
RecursiveAction:用于没有返回结果的任务。
RecursiveTask:用于有返回结果的任务。ForkJoinPool:ForkJoinTask需要通过ForkJoinPool来执行,任务分割出的子任务会添加到当前工作线程所维护的双端队列中,进入队列的头部。当一个工作线程的队列里暂时没有任务时,它会随机从其他工作线程的队列的尾部获取一个任务。
1.4 使用Fork/Join框架
让我们通过一个简单的需求来使用下Fork/Join框架,需求是:计算1+2+3+4的结果。
使用Fork/Join框架首先要考虑到的是如何分割任务,如果我们希望每个子任务最多执行两个数的相加,那么我们设置分割的阈值是2,由于是4个数字相加,所以Fork/Join框架会把这个任务fork成两个子任务,子任务一负责计算1+2,子任务二负责计算3+4,然后再join两个子任务的结果。
因为是有结果的任务,所以必须继承RecursiveTask,实现代码如下:
importjava.util.concurrent.ExecutionException;
importjava.util.concurrent.ForkJoinPool;
importjava.util.concurrent.Future;
importjava.util.concurrent.RecursiveTask;
public class CountTask extends RecursiveTask {
private static final int THRESHOLD= 2;//阈值
private int start;
private int end;
public CountTask(int start,int end) {
this.start= start;
this.end= end;
}
@Override
protected Integer compute() {
int sum = 0;
//如果任务足够小就计算任务
boolean canCompute = (end-start) <=THRESHOLD;
if(canCompute) {
for(int i =start; i <=end; i++) {
sum += i;
}
}else{
//如果任务大于阀值,就分裂成两个子任务计算
int middle = (start+end) / 2;
CountTask leftTask =new CountTask(start, middle);
CountTask rightTask =new CountTask(middle + 1,end);
leftTask.fork();
rightTask.fork();
//等待子任务执行完,并得到其结果
int leftResult=(int)leftTask.join();
int rightResult=(int)rightTask.join();
//合并子任务
sum = leftResult + rightResult;
}
return sum;
}
public static void main(String[] args) {
ForkJoinPool forkJoinPool =new ForkJoinPool();
//生成一个计算任务,负责计算1+2+3+4
CountTask task =new CountTask(1, 4);
//执行一个任务
Future result = forkJoinPool.submit(task);
try{
System.out.println(result.get());
}catch(InterruptedException e) {
}catch(ExecutionException e) {
}
}
}
通过这个例子让我们再来进一步了解ForkJoinTask,ForkJoinTask与一般的任务的主要区别在于它需要实现compute方法,在这个方法里,首先需要判断任务是否足够小,如果足够小就直接执行任务。如果不足够小,就必须分割成两个子任务,每个子任务在调用fork方法时,又会进入compute方法,看看当前子任务是否需要继续分割成孙任务,如果不需要继续分割,则执行当前子任务并返回结果。使用join方法会等待子任务执行完并得到其结果。
1.5 Fork/Join框架的异常处理
ForkJoinTask在执行的时候可能会抛出异常,但是我们没办法在主线程里直接捕获异常,所以ForkJoinTask提供了isCompletedAbnormally()方法来检查任务是否已经抛出异常或已经被取消了,并且可以通过ForkJoinTask的getException方法获取异常。使用如下代码:
if(task.isCompletedAbnormally()){
System.out.println(task.getException());
}
getException方法返回Throwable对象,如果任务被取消了则返回CancellationException。如果任务没有完成或者没有抛出异常则返回null。
1.6 Fork/Join框架的实现原理
ForkJoinPool由ForkJoinTask数组和ForkJoinWorkerThread数组组成,ForkJoinTask数组负责存放程序提交给ForkJoinPool的任务,而ForkJoinWorkerThread数组负责执行这些任务。
ForkJoinTask的fork方法实现原理。当我们调用ForkJoinTask的fork方法时,程序会调用ForkJoinWorkerThread的pushTask方法异步的执行这个任务,然后立即返回结果。代码如下:
public final ForkJoinTask fork() {
((ForkJoinWorkerThread) Thread.currentThread())
.pushTask(this);
return this;
}
pushTask方法把当前任务存放在ForkJoinTask 数组queue里。然后再调用ForkJoinPool的signalWork()方法唤醒或创建一个工作线程来执行任务。代码如下:
final void pushTask(ForkJoinTask t) {
ForkJoinTask[] q; int s, m;
if ((q = queue) != null) { // ignore if queue removed
long u = (((s = queueTop) & (m = q.length - 1)) << ASHIFT) + ABASE;
UNSAFE.putOrderedObject(q, u, t);
queueTop = s + 1; // or use putOrderedInt
if ((s -= queueBase) <= 2)
pool.signalWork();
else if (s == m)
growQueue();
}
}
ForkJoinTask的join方法实现原理。Join方法的主要作用是阻塞当前线程并等待获取结果。让我们一起看看ForkJoinTask的join方法的实现,代码如下:
public final V join() {
if (doJoin() != NORMAL)
return reportResult();
else
return getRawResult();
}
private V reportResult() {
int s; Throwable ex;
if ((s = status) == CANCELLED)
throw new CancellationException();
if (s == EXCEPTIONAL && (ex = getThrowableException()) != null)
UNSAFE.throwException(ex);
return getRawResult();
}
首先,它调用了doJoin()方法,通过doJoin()方法得到当前任务的状态来判断返回什么结果,任务状态有四种:已完成(NORMAL),被取消(CANCELLED),信号(SIGNAL)和出现异常(EXCEPTIONAL)。
如果任务状态是已完成,则直接返回任务结果。
如果任务状态是被取消,则直接抛出CancellationException。
如果任务状态是抛出异常,则直接抛出对应的异常。
让我们再来分析下doJoin()方法的实现代码:
private int doJoin() {
Thread t; ForkJoinWorkerThread w; int s; boolean completed;
if ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread) {
if ((s = status) < 0)
return s;
if ((w = (ForkJoinWorkerThread)t).unpushTask(this)) {
try {
completed = exec();
} catch (Throwable rex) {
return setExceptionalCompletion(rex);
}
if (completed)
return setCompletion(NORMAL);
}
return w.joinTask(this);
}
else
return externalAwaitDone();
}
在doJoin()方法里,首先通过查看任务的状态,看任务是否已经执行完了,如果执行完了,则直接返回任务状态,如果没有执行完,则从任务数组里取出任务并执行。如果任务顺利执行完成了,则设置任务状态为NORMAL,如果出现异常,则纪录异常,并将任务状态设置为EXCEPTIONAL
2 障碍器
2.1 CyclicBarrier
2.1.1 CyclicBarrier概念
Java5中,添加了障碍器类,为了适应一种新的设计需求,比如一个大型的任务,常常需要分配好多子任务去执行,只有当所有子任务都执行完成时候,才能执行主任务,这时候,除了上面的Fork/Join框架就可以选择障碍器CyclicBarrier。
CyclicBarrier:从字面上的意思可以知道,这个类的中文意思是循环栅栏。大概的意思就是一个可循环利用的屏障。
它的作用就是会让所有线程都等待完成后才会继续下一步行动。
举个例子,就像生活中我们会约朋友们到某个餐厅一起吃饭,有些朋友可能会早到,有些朋友可能会晚到,但是这个餐厅规定必须等到所有人到齐之后才会让我们进去。这里的朋友们就是各个线程,餐厅就是CyclicBarrier
2.1.2 方法
2.1.2.1 构造方法
public CyclicBarrier(int parties)
public CyclicBarrier(int parties, Runnable barrierAction)
parties是参与线程的个数
第二个构造方法有一个 Runnable 参数,这个参数的意思是最后一个到达线程要做的任务
2.1.2.2 await方法
public int await() throws InterruptedException, BrokenBarrierException
public int await(long timeout, TimeUnit unit) throws InterruptedException, BrokenBarrierException, TimeoutException
线程调用 await() 表示自己已经到达栅栏
BrokenBarrierException 表示栅栏已经被破坏,破坏的原因可能是其中一个线程 await() 时被中断或者超时
2.1.3 使用CyclicBarrier
障碍器是多线程并发控制的一种手段,用法很简单。下面给个例子:
import java.util.concurrent.BrokenBarrierException;
import java.util.concurrent.CyclicBarrier;
/**
* Java线程:新特征-障碍器
*/
public class Test {
public static void main(String[] args) {
//创建障碍器,并设置MainTask为所有定数量的线程都达到障碍点时候所要执行的任务(Runnable)
CyclicBarrier cb = new CyclicBarrier(7, new MainTask());
new SubTask("A", cb).start();
new SubTask("B", cb).start();
new SubTask("C", cb).start();
new SubTask("D", cb).start();
new SubTask("E", cb).start();
new SubTask("F", cb).start();
new SubTask("G", cb).start();
}
}
/**
* 主任务
*/
class MainTask implements Runnable {
public void run() {
System.out.println(">>>>主任务执行了!<<<<");
}
}
/**
* 子任务
*/
class SubTask extends Thread {
private String name;
private CyclicBarrier cb;
SubTask(String name, CyclicBarrier cb) {
this.name = name;
this.cb = cb;
}
public void run() {
System.out.println("[子任务" + name + "]开始执行了!");
for (int i = 0; i < 999999; i++) ; //模拟耗时的任务
System.out.println("[子任务" + name + "]开始执行完成了,并通知障碍器已经完成!");
try {
//通知障碍器已经完成
cb.await();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
}
}
运行结果:
[子任务E]开始执行了!
[子任务E]开始执行完成了,并通知障碍器已经完成!
[子任务F]开始执行了!
[子任务G]开始执行了!
[子任务F]开始执行完成了,并通知障碍器已经完成!
[子任务G]开始执行完成了,并通知障碍器已经完成!
[子任务C]开始执行了!
[子任务B]开始执行了!
[子任务C]开始执行完成了,并通知障碍器已经完成!
[子任务D]开始执行了!
[子任务A]开始执行了!
[子任务D]开始执行完成了,并通知障碍器已经完成!
[子任务B]开始执行完成了,并通知障碍器已经完成!
[子任务A]开始执行完成了,并通知障碍器已经完成!
>>>>主任务执行了!<<<<
从执行结果可以看出,所有子任务完成的时候,主任务执行了,达到了控制的目标。
2.1.4 CyclicBarrier与CountDownLatch区别
CountDownLatch 是一次性的,CyclicBarrier是可循环利用的
CountDownLatch 参与的线程的职责是不一样的,有的在倒计时,有的在等待倒计时结束。CyclicBarrier 参与的线程职责是一样的
2.2 CountDownLatch
2.2.1 CountDownLatch是什么
CountDownLatch是在java1.5被引入的,跟它一起被引入的并发工具类还有CyclicBarrier、Semaphore、ConcurrentHashMap和BlockingQueue,它们都存在于java.util.concurrent包下。CountDownLatch是一个同步工具类,这个类能够使一个线程等待其他线程完成各自的工作后再执行。例如,应用程序的主线程希望在负责启动框架服务的线程已经启动所有的框架服务之后再执行。
CountDownLatch是通过一个计数器来实现的,计数器的初始值为线程的数量。每当一个线程完成了自己的任务后,计数器的值就会减1。当计数器值到达0时,它表示所有的线程已经完成了任务,然后在闭锁上等待的线程就可以恢复执行任务。

CountDownLatch的伪代码如下所示:
Main thread start
Create CountDownLatch for N threads
Create and start N threads
Main thread wait on latch
N threads completes there tasks are returns
Main thread resume execution
2.2.2 CountDownLatch如何工作
CountDownLatch.java类中定义的构造函数:
public CountDownLatch(int count) { };
构造器中的计数值(count)实际上就是闭锁需要等待的线程数量。这个值只能被设置一次,而且CountDownLatch没有提供任何机制去重新设置这个计数值。
与CountDownLatch的第一次交互是主线程等待其他线程。主线程必须在启动其他线程后立即调用CountDownLatch.await()方法。这样主线程的操作就会在这个方法上阻塞,直到其他线程完成各自的任务。
其他N个线程必须引用闭锁对象,因为他们需要通知CountDownLatch对象,他们已经完成了各自的任务。这种通知机制是通过CountDownLatch.countDown()方法来完成的;每调用一次这个方法,在构造函数中初始化的count值就减1。所以当N个线程都调 用了这个方法,count的值等于0,然后主线程就能通过await()方法,恢复执行自己的任务。
类中有三个方法是最重要的:
await():调用await()方法的线程会被挂起,它会等待直到count值为0才继续执行
public void await() throws InterruptedException { };await(long timeout, TimeUnit unit):和await()类似,只不过等待一定的时间后count值还没变为0的话就会继续执行
public boolean await(long timeout, TimeUnit unit) throws InterruptedException { };countDown():将count值减1
public void countDown() { };
2.2.3 CountDownLatch使用例子
用一个最典型的i++例子来说明:
public class Test {
private int i = 0;
private final CountDownLatch mainLatch = new CountDownLatch(1);
public void add(){
i++;
}
private class Work extends Thread{
private CountDownLatch threadLatch;
public Work(CountDownLatch latch){
threadLatch = latch;
}
@Override
public void run() {
try {
mainLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
for (int j = 0; j < 1000; j++) {
add();
}
threadLatch.countDown();
}
}
public static void main(String[] args) throws InterruptedException {
for(int k = 0; k < 10; k++){
Test test = new Test();
CountDownLatch threadLatch = new CountDownLatch(10);
for (int i = 0; i < 10; i++) {
test.new Work(threadLatch).start();
}
test.mainLatch.countDown();
threadLatch.await();
System.out.println(test.i);
}
}
}
2.2.4 CountDownLatch示例说明
java.util.concurrent.CountDownLatch的作用就像一个门闩或是闸门那样。上面这段代码一共执行10次,每次启动10个线程同时执行。在每次的10个线程中,mainLatch.await()相当于门闩挡着线程,让每次准备好的10线程处于等待状态,当每次的10个线程都准备好时再调用mainLatch.countDown()方法,打开门闩让线程同时执行。mainLatch.await()在这里用的原因,是想让创建的10个线程都准备好后再一起并发执行,这样才能很明显的看出add方法里面的i++效果。如果不引入CountDownLatch,只执行test.new Work(threadLatch).start(),则获得的结果可能看不出来线程竞争共享变量产生的错误情况。
主线程中threadLatch这个CountDownLatch的作用是让10个线程都执行完run方法的for循环后,通知主线程的threadLatch.await()停止等待打印出当前i的值。
取了几个比较明显的结果。当然,你也可以多运行几次看看效果。


共享变量i没做任何同步操作,当有多个线程都要读取并修改它时,问题就产生了。正确的结果应该是10000,但是我们看到了,不是每次结果都是10000。这段代码最初的版本不是这样的,因为现在的CPU哪怕是家用级PC的CPU核心频率都非常高,所以完全看不出效果,run方法中的循环次数越大,i 的并发问题就越明显,大家可以动手试下。对于上图的运行结果,和硬件平台有关
在Java中,线程是怎么操作共享变量的呢?我们都知道,Java代码在编译后会变成字节码,然后在JVM里面运行,而像实例域i 这样的变量是存储在堆内存Heap Memory中的,堆内存是内存中的一块区域。线程的执行其实说到底就是CPU的执行,当今的CPU(Intel)基本上都是多核的,因此多线程都是由多核CPU来处理,并且都有L1、L2或L3等CPU缓存,CPU为了提高处理速度,在执行的时候,会从内存中把数据读到缓存后再操作,而每个线程执行add方法操作i++的过程是这样的:
- 线程从堆内存中读取i的值,将它复制到缓存中
- 在缓存中执行
i++操作,并将结果赋给变量i - 再用缓存中的值刷新堆内存中的变量i的值
上面写的这三步并不是严格按照JVM及CPU指令的步骤来的,但过程就是这么一回事,方便大家理解。通过上面这个过程我们可以看出问题了,如果有多个线程同时要修改i,那么都需要先读取堆内存中的变量i值,然后把它复制到缓存后执行i++操作,再将结果写回到堆内存的变量i中。这个执行的时间非常短,可能只有零点几纳秒(主要还是跟硬件平台有关),但还是出现了错误。产生这种错误的原因是共享变量的可见性,线程1在读取变量i的值的时候,线程2正在更新变量i的值,而线程1这时看不到线程2修改的值。这种现象就是常说的共享变量可见性。
下图是线程执行的抽象图,也可以说是Java内存模型的抽象示意图,可能不严谨,但大意是这样的。

现在选用开发框架一般都会选择Spring,或是类似Spring这样的东西,而代码中经常用到的依赖注入的Bean如果没做处理一般都会是单例模式。试想一下,按下面这个方式引用Service或其它类似的Bean,在UserService中又不小心用到了共享变量,同时没有处理它的共享可见性,即同步,那将会产生意想不到的结果。不光Service是单例的,Spring MVC中的Controller也是单例的,所以编写代码的时候一定要注意共享变量的问题。
@Autowired
private UserService userService;
所以要尽可能的不使用共享变量,避开它,因为处理好共享变量可见性不是一个很简单的问题。如果有非用不可的理由,请使用java.util.concurrent.atomic包下面的原子类来代替常用变量类型。比如用AtomicInteger代替int,AtomicLong代替long等等
2.3 Semaphore
2.3.1 简介
Semaphore (信号量),在 Java 的 java.util.concurrent(JUC)包里,是一个限流工具,用来控制同时访问某一资源或某一组资源的线程数,达到限流的效果。
当一个线程执行时先通过其方法进行获取许可操作,获取到许可的线程继续执行业务逻辑,当线程执行完成后进行释放许可操作,未获取达到许可的线程进行等待或者直接结束。
2.3.2 主要方法说明
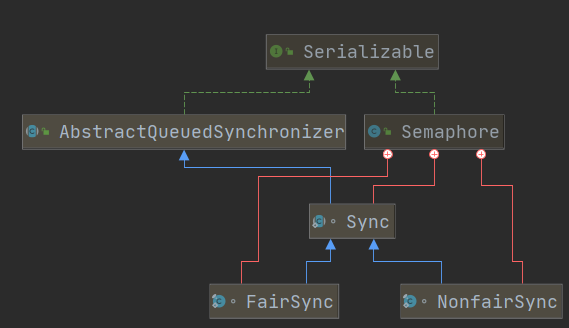
类关系图如下,Sync是Semaphore的一个内部类,该类继承 AQS,这个类又有公平和非公平的两个子类,这个内置的同步器实现Semaphore的功能
2.3.2.1 构造函数源码部分
// 指定许可数量
public Semaphore(int permits) {
// sync属性赋值 默认未非公平实现
sync = new NonfairSync(permits);
}
// 指定许可数量和是否公平实现
public Semaphore(int permits, boolean fair) {
sync = fair ? new FairSync(permits) : new NonfairSync(permits);
}
2.3.2.2 获取许可
在Semaphore中提供了如下的获取许可的方法
void acquire() throws InterruptedException:获取一个许可,会阻塞等待其他线程释放许可,方法没有返回值,当许可不足时会阻塞线程等待其他线程释放许可void acquire(int permits) throws InterruptedException:获取指定的许可数 ,会阻塞等待其他线程释放void acquireUninterruptibly():获取一个许可,会阻塞等待其他线程释放许可,可被中断void acquireUninterruptibly(int permits):获取指定的许可数,会阻塞等待其他线程释放许可,可被中断boolean tryAcquire():尝试获取许可,不会进行阻塞等待,这个方法的返回值表示是否获取许可成功,不会阻塞等待其他线程释放许可,没有许可了会直返返回falseboolean tryAcquire(int permits):尝试获取指定的许可数,不会阻塞等待boolean tryAcquire(long timeout, TimeUnit unit):尝试获取许可,可指定等待时间boolean tryAcquire(int permits, long timeout, TimeUnit unit):尝试获取指定的许可数,可指定等待时间
2.3.2.3 释放许可
释放许可的方法为release方法,其源码如下:
public void release() {
sync.releaseShared(1);
}
// AQS中的方法
public final boolean releaseShared(int arg) {
// 模板方法 需要子类实现
if (tryReleaseShared(arg)) {
doReleaseShared();
// 成功
return true;
}
// 失败
return false;
}
2.3.3 操作使用
private static class MyRunnable implements Runnable {
// 成员属性 Semaphore对象
private final Semaphore semaphore;
public MyRunnable(Semaphore semaphore) {
this.semaphore = semaphore;
}
public void run() {
String threadName = Thread.currentThread().getName();
// 获取许可
boolean acquire = semaphore.tryAcquire();
// 未获取到许可 结束
if (!acquire) {
System.out.println("线程【" + threadName + "】未获取到许可,结束");
return;
}
// 获取到许可
try {
System.out.println("线程【" + threadName + "】获取到许可");
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
// 释放许可
semaphore.release();
System.out.println("线程【" + threadName + "】释放许可");
}
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号