ArrayList源码详解
1 ArrayList源码
工作中经常听到别人讲容器,各种各样的容器,话说到底什么是容器,通俗的讲容器就是用来装东西的器皿,比如:水桶就是用来盛水的,水桶就是一个容器
在我们写程序的时候常常要对大量的对象进行管理,比如查询,遍历,修改等。jdk为我们提供的容器位于java.util包,也是我们平时用的最多的包之一。
但是为什么不用数组(其实也不是不用,只是不直接用)呢,因为数组的长度需要提前确定,而且不能改变大小,用起来手脚受限嘛。
下面步入正题,首先一个对象管理容器需要哪些功能?增加,删除,修改,查询(crud对不对?)还有呢?遍历,容量,是否包含某个元素。。。
功能是有了,如果让你自己实现一个这样的容器该怎么实现呢?
看看ArrayList是怎么实现这些功能的。
1.1 ArrayList定义
首先先来看下顶级接口Collection的定义,
public interface Collection<E> extends Iterable<E> {
int size();
boolean isEmpty();
boolean contains(Object o);
Iterator<E> iterator();
Object[] toArray();
<T> T[] toArray(T[] a);
boolean add(E e);
boolean remove(Object o);
boolean containsAll(Collection<?> c);
boolean addAll(Collection<? extends E> c);
boolean removeAll(Collection<?> c);
boolean retainAll(Collection<?> c);
void clear();
boolean equals(Object o);
int hashCode();
}
然后是接口List的定义,
public interface List<E> extends Collection<E> {
int size();
boolean isEmpty();
boolean contains(Object o);
Iterator<E> iterator();
Object[] toArray();
<T> T[] toArray(T[] a);
boolean add(E e);
boolean remove(Object o);
boolean containsAll(Collection<?> c);
boolean addAll(Collection<? extends E> c);
boolean addAll( int index, Collection<? extends E> c);
boolean removeAll(Collection<?> c);
boolean retainAll(Collection<?> c);
void clear();
boolean equals(Object o);
int hashCode();
E get( int index);
E set( int index, E element);
void add( int index, E element);
E remove( int index);
int indexOf(Object o);
int lastIndexOf(Object o);
ListIterator<E> listIterator();
ListIterator<E> listIterator( int index);
List<E> subList( int fromIndex, int toIndex);
}
再看下ArrayList的定义
public class ArrayList<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable
可以看出ArrayList继承AbstractList(这是一个抽象类,对一些基础的list操作进行封装),实现List,RandomAccess,Cloneable,Serializable几个接口,RandomAccess是一个标记接口,用来表明其支持快速随机访问。
1.2 底层存储
ArrayList就是用数组实现的List容器,既然是用数组实现,当然底层用数组来保存数据啦。。。
private transient Object[] elementData;
private int size;
可以看到用一个Object数组来存储数据,用一个int值来计数,记录当前容器的数据大小。
另外,细心的人会发现elementData数组是使用transient修饰的,关于transient关键字的作用简单说就是java自带默认机制进行序列化的时候,被其修饰的属性不需要维持。会不会产生一点疑问?elementData不需要维持,那么怎么进行反序列化,又怎么保证序列化和反序列化数据的正确性?难道不需要存储?既然需要存储,它是怎么实现的呢?
默认序列化机制,ArrayList一定是使用了自定义的序列化方式,到底是不是这样的呢?看下面两个方法:
/** * Save the state of the <tt>ArrayList</tt> instance to a stream (that
* is, serialize it).
*
* @serialData The length of the array backing the <tt>ArrayList </tt>
* instance is emitted (int), followed by all of its elements
* (each an <tt>Object</tt> ) in the proper order.
*/ private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException{
// Write out element count, and any hidden stuff12 int expectedModCount = modCount ;
s.defaultWriteObject();
// Write out array length16 s.writeInt( elementData.length );
// Write out all elements in the proper order.19 for (int i=0; i<size; i++)
s.writeObject( elementData[i]);
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
/** * Reconstitute the <tt>ArrayList</tt> instance from a stream (that is,
* deserialize it).
*/ private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
// Read in size, and any hidden stuff35 s.defaultReadObject();
// Read in array length and allocate array38 int arrayLength = s.readInt();
Object[] a = elementData = new Object[arrayLength];
// Read in all elements in the proper order.42 for (int i=0; i<size; i++)
a[i] = s.readObject();
}
英语注释很详细,也很容易读懂,就不进行翻译了。那么想一下为什么要这样设计呢,岂不是很麻烦。下面简单进行解释下:
elementData 是一个数据存储数组,而数组是定长的,它会初始化一个容量,等容量不足时再扩充容量(扩容方式为数据拷贝,后面会详细解释),再通俗一点说就是比如elementData 的长度是10,而里面只保存了3个对象,那么数组中其余的7个元素(null)是没有意义的,所以也就不需要保存,以节省序列化后的内存容量,好了到这里就明白了这样设计的初衷和好处,顺便好像也明白了长度单独用一个int变量保存,而不是直接使用elementData.length的原因。
1.3 构造方法
/** * 构造一个具有指定容量的list
*/ public ArrayList( int initialCapacity) {
super();
if (initialCapacity < 0)
throw new IllegalArgumentException( "Illegal Capacity: " +
initialCapacity);
this.elementData = new Object[initialCapacity];
}
/** * 构造一个初始容量为10的list
*/ public ArrayList() {
this(10);
}
/** * 构造一个包含指定元素的list,这些元素的是按照Collection的迭代器返回的顺序排列的
*/ public ArrayList(Collection<? extends E> c) {
elementData = c.toArray();
size = elementData .length;
// c.toArray might (incorrectly) not return Object[] (see 6260652)26 if (elementData .getClass() != Object[].class)
elementData = Arrays.copyOf( elementData, size , Object[].class);
}
构造方法看完了,想一下指定容量的构造方法的意义,既然默认为10就可以那么为什么还要提供一个可以指定容量大小的构造方法呢
1.4 增加
/** * 添加一个元素
*/
public boolean add(E e) {
// 进行扩容检查 ensureCapacity( size + 1); // Increments modCount
// 将e增加至list的数据尾部,容量+1 8 elementData[size ++] = e;
return true;
}
/** * 在指定位置添加一个元素
*/ public void add(int index, E element) {
// 判断索引是否越界,这里会抛出多么熟悉的异常。。。
if (index > size || index < 0)
throw new IndexOutOfBoundsException(
"Index: "+index+", Size: " +size);
// 进行扩容检查
ensureCapacity( size+1); // Increments modCount
// 对数组进行复制处理,目的就是空出index的位置插入element,并将index后的元素位移一个位置
System. arraycopy(elementData, index, elementData, index + 1,
size - index);
// 将指定的index位置赋值为element
elementData[index] = element;
// list容量+1
size++;
}
/** * 增加一个集合元素
*/
public boolean addAll(Collection<? extends E> c) {
//将c转换为数组
Object[] a = c.toArray();
int numNew = a.length ;
//扩容检查
ensureCapacity( size + numNew); // Increments modCount
//将c添加至list的数据尾部
System. arraycopy(a, 0, elementData, size, numNew);
//更新当前容器大小
size += numNew;
return numNew != 0;
}
/** * 在指定位置,增加一个集合元素
*/
public boolean addAll(int index, Collection<? extends E> c) {
if (index > size || index < 0)
throw new IndexOutOfBoundsException(
"Index: " + index + ", Size: " + size);
Object[] a = c.toArray();
int numNew = a.length ;
ensureCapacity( size + numNew); // Increments modCount
// 计算需要移动的长度(index之后的元素个数)
int numMoved = size - index;
// 数组复制,空出第index到index+numNum的位置,即将数组index后的元素向右移动numNum个位置
if (numMoved > 0)
System. arraycopy(elementData, index, elementData, index + numNew,
numMoved);
// 将要插入的集合元素复制到数组空出的位置中66 System. arraycopy(a, 0, elementData, index, numNew);
size += numNew;
return numNew != 0;
}
/** * 数组容量检查,不够时则进行扩容
*/
public void ensureCapacity( int minCapacity) {
modCount++;
// 当前数组的长度77
int oldCapacity = elementData .length;
// 最小需要的容量大于当前数组的长度则进行扩容
if (minCapacity > oldCapacity) {
Object oldData[] = elementData;
// 新扩容的数组长度为旧容量的1.5倍+1
int newCapacity = (oldCapacity * 3)/2 + 1;
// 如果新扩容的数组长度还是比最小需要的容量小,则以最小需要的容量为长度进行扩容
if (newCapacity < minCapacity)
newCapacity = minCapacity;
// minCapacity is usually close to size, so this is a win:
// 进行数据拷贝,Arrays.copyOf底层实现是System.arrayCopy()
elementData = Arrays.copyOf( elementData, newCapacity);
}
}
1.5 删除
/** * 根据索引位置删除元素
*/
public E remove( int index) {
// 数组越界检查
RangeCheck(index);
modCount++;
// 取出要删除位置的元素,供返回使用
E oldValue = (E) elementData[index];
// 计算数组要复制的数量
int numMoved = size - index - 1;
// 数组复制,就是将index之后的元素往前移动一个位置
if (numMoved > 0)
System. arraycopy(elementData, index+1, elementData, index,
numMoved);
// 将数组最后一个元素置空(因为删除了一个元素,然后index后面的元素都向前移动了,所以最后一个就没用了),好让gc尽快回收
// 不要忘了size减一
elementData[--size ] = null; // Let gc do its work
return oldValue;
}
/** * 根据元素内容删除,只删除匹配的第一个
*/
public boolean remove(Object o) {
// 对要删除的元素进行null判断
// 对数据元素进行遍历查找,知道找到第一个要删除的元素,删除后进行返回,如果要删除的元素正好是最后一个那就惨了,时间复杂度可达O(n) 。。。
if (o == null) {
for (int index = 0; index < size; index++)
// null值要用==比较
if (elementData [index] == null) {
fastRemove(index);
return true;
}
} else {
for (int index = 0; index < size; index++)
// 非null当然是用equals比较了
if (o.equals(elementData [index])) {
fastRemove(index);
return true;
}
}
return false;
}
/*
* Private remove method that skips bounds checking and does not
* return the value removed.
*/
private void fastRemove(int index) {
modCount++;
// 原理和之前的add一样,还是进行数组复制,将index后的元素向前移动一个位置,不细解释了,
int numMoved = size - index - 1;
if (numMoved > 0)
System. arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size ] = null; // Let gc do its work60 }
/** * 数组越界检查
*/
private void RangeCheck(int index) {
if (index >= size )
throw new IndexOutOfBoundsException(
"Index: "+index+", Size: " +size);
}
看到了这个方法,便可jdk源码有些地方写的也不是那么精巧,比如这里remove时将数组越界检查封装成了一个单独方法,可是往前翻一下add方法中的数组越界就没有进行封装,需要检查的时候都是写一遍一样的代码
增加和删除方法到这里就解释完了,代码是很简单,主要需要特别关心的就两个地方:1.数组扩容,2.数组复制,这两个操作都是极费效率的,最惨的情况下(添加到list第一个位置,删除list最后一个元素或删除list第一个索引位置的元素)时间复杂度可达O(n)
为什么提供一个可以指定容量大小的构造方法?看到这里是不是有点明白了呢,简单解释下:如果数组初试容量过小,假设默认的10个大小,而我们使用ArrayList的主要操作时增加元素,不断的增加,一直增加,不停的增加,会出现上面后果?那就是数组容量不断的受挑衅,数组需要不断的进行扩容,扩容的过程就是数组拷贝System.arraycopy的过程,每一次扩容就会开辟一块新的内存空间和数据的复制移动,这样势必对性能造成影响。那么在这种以写为主(写会扩容,删不会缩容)场景下,提前预知性的设置一个大容量,便可减少扩容的次数,提高了性能。
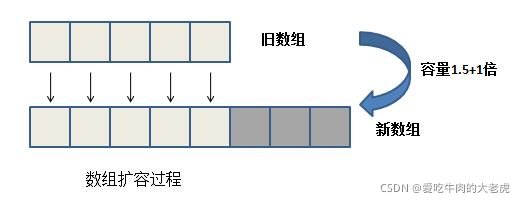
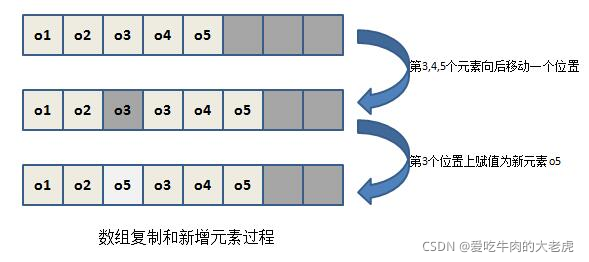
上面两张图分别是数组扩容和数组复制的过程,需要注意的是,数组扩容伴随着开辟新建的内存空间以创建新数组然后进行数据复制,而数组复制不需要开辟新内存空间,只需将数据进行复制。
上面讲增加元素可能会进行扩容,而删除元素却不会进行缩容,如果在已删除为主的场景下使用list,一直不停的删除而很少进行增加,那么会出现什么情况?再或者数组进行一次大扩容后,我们后续只使用了几个空间,会出现什么情况?空间浪费
/** * 将底层数组的容量调整为当前实际元素的大小,来释放空间。
*/
public void trimToSize() {
modCount++;
// 当前数组的容量
int oldCapacity = elementData .length;
// 如果当前实际元素大小 小于 当前数组的容量,则进行缩容
if (size < oldCapacity) {
elementData = Arrays.copyOf( elementData, size );
}
1.6 更新
/** * 将指定位置的元素更新为新元素
*/
public E set( int index, E element) {
// 数组越界检查
RangeCheck(index);
// 取出要更新位置的元素,供返回使用
E oldValue = (E) elementData[index];
// 将该位置赋值为行的元素
elementData[index] = element;
// 返回旧元素
return oldValue;
}
1.7 查找
/** * 查找指定位置上的元素
*/
public E get( int index) {
RangeCheck(index);
return (E) elementData [index];
}
由于ArrayList使用数组实现,更新和查找直接基于下标操作,变得十分简单。
1.8 是否包含
/** * Returns <tt>true</tt> if this list contains the specified element.
* More formally, returns <tt>true</tt> if and only if this list contains
* at least one element <tt>e</tt> such that
* <tt>(o==null ? e==null : o.equals(e))</tt>.
*
* @param o element whose presence in this list is to be tested
* @return <tt> true</tt> if this list contains the specified element
*/
public boolean contains(Object o) {
return indexOf(o) >= 0;
}
/**
* Returns the index of the first occurrence of the specified element
* in this list, or -1 if this list does not contain the element.
* More formally, returns the lowest index <tt>i</tt> such that
* <tt>(o==null ? get(i)==null : o.equals(get(i)))</tt>,
* or -1 if there is no such index.
*/
public int indexOf(Object o) {
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData [i]==null)
return i;
} else {
for (int i = 0; i < size; i++)
if (o.equals(elementData [i]))
return i;
}
return -1;
}
/**
* Returns the index of the last occurrence of the specified element
* in this list, or -1 if this list does not contain the element.
* More formally, returns the highest index <tt>i</tt> such that
* <tt>(o==null ? get(i)==null : o.equals(get(i)))</tt>,
* or -1 if there is no such index.
*/
public int lastIndexOf(Object o) {
if (o == null) {
for (int i = size-1; i >= 0; i--)
if (elementData [i]==null)
return i;
} else {
for (int i = size-1; i >= 0; i--)
if (o.equals(elementData [i]))
return i;
}
return -1;
}
contains主要是检查indexOf,也就是元素在list中出现的索引位置也就是数组下标,再看indexOf和lastIndexOf代码,和public boolean remove(Object o) 的代码一样,都是元素null判断,都是循环比较,但是要知道,最差的情况(要找的元素是最后一个)也是很惨的。。。
1.9 容量判断
/**
* Returns the number of elements in this list.
*
* @return the number of elements in this list
*/
public int size() {
return size ;
}
/**
* Returns <tt>true</tt> if this list contains no elements.
*
* @return <tt> true</tt> if this list contains no elements
*/
public boolean isEmpty() {
return size == 0;
}
由于使用了size进行计数,发现list大小获取和判断好容易
1.10 ArrayList和LinkedList
1.10.1 二者区别
底层数据结构:ArrayList使用数组作为底层数据结构,而LinkedList使用双向链表作为底层数据结构随机访问性能:ArrayList支持通过索引直接访问元素,因为底层数组的连续存储特性,所以时间复杂度为O(1)。而LinkedList需要从头或尾部开始遍历链表,时间复杂度为O(n)。插入和删除操作:ArrayList在尾部插入和删除元素的时间复杂度为O(1),因为它只需要调整数组的长度即可。但在中间或头部插入和删除元素时,需要将后续元素进行移动,时间复杂度为O(n)。而LinkedList在任意位置插入和删除元素的时间复杂度为O(1),因为只需要调整节点的指针即可。内存占用:ArrayList在每个元素中都存储了实际的数据,而LinkedList在每个节点中存储了数据和前后节点的指针。因此,相同数量的元素情况下,LinkedList通常比ArrayList占用更多的内存空间。
1.10.2 应用场景区别
如果需要频繁进行随机访问操作,而对插入和删除操作要求不高,可以选择ArrayList。
如果需要频繁进行插入和删除操作,而对随机访问操作要求不高,可以选择LinkedList。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号