

IO流分类讲解
1 IO流基础
javaIO就是输入输出体系,简单的理解就是java对于文件内存网络资源的操作,在java传统的IO体系中,虽然可以完成基本所有需求的操作,但是为了实现java一次编写到处运行的目标,java虚拟机在各个操作系统上做了很多让步,放弃了很多操作系统的特性,这样的结果只能使java的IO效率不高。为了提高javaIO的效率,在java4版本中增加了java new IO简称为NIO非阻塞的IO。
1.1 IO基础
在介绍IO之前我们需要先掌握一些基本知识。就是File类。File类是IO最基础的类,File是我们磁盘上文件目录的抽象,我们可以通过一个路径来创建这个类,File类中有许多方法可以让我得到这个文件或目录的属性,如果是一个不存在的目录或文件可以用这个类创建。具体代码大家可以自己试一下,在这贴出一些简单的例子。
例子:
import java.io.File;
import java.io.IOException;
public classTest1 {
public static void main(String[] args) {
File file=new File("e:\\out.txt");
if(!file.exists()){
try {
file.createNewFile();
}catch(IOException e) {
e.printStackTrace();
}
}
// file.mkdir();
// file.mkdirs();
// File.listRoots();列出文件系统的根
System.out.println(file.canExecute());
System.out.println(file.canRead());
System.out.println(file.canWrite());
System.out.println(file.isAbsolute());
System.out.println("------默认相对路径,取得路径不同-----");
File f = new File("..\\src\\file");
System.out.println(f.getPath());
System.out.println(f.getAbsolutePath());
System.out.println(f.getCanonicalPath());
System.out.println("------默认相对路径,取得路径不同-----");
File f2 = new File(".\\src\\file");
System.out.println(f2.getPath());
System.out.println(f2.getAbsolutePath());
System.out.println(f2.getCanonicalPath());
System.out.println("------默认绝对路径,取得路径相同-----");
File f3 = new File("C:\\src\\file");
System.out.println(f3.getPath());
System.out.println(f3.getAbsolutePath());
System.out.println(f3.getCanonicalPath());
执行结果为:
------默认相对路径,取得路径不同-----
..\src\file
C:\workspace\Tip\..\src\file
C:\workspace\src\file
------默认相对路径,取得路径不同-----
.\src\file
C:\workspace\Tip\.\src\file
C:\workspace\Tip\src\file
------默认绝对路径,取得路径相同-----
C:\src\file
C:\src\file
C:\src\file
比较可以得到
getPath()返回的是构造方法里的路径,不做任何处理
getAbsolutePath()返回的是 user.dir+getPath(),也就是执行路径加上构造方法中的路径
getCanonicalPath()返回的是将符号完全解析的路径,也就是全路径
}
}
1.2 流分类
按流向分类:
输入流: 程序可以从中读取数据的流。输出流: 程序能向其中写入数据的流。
按数据传输单位分类:
字节流:以字节(8位二进制)为单位进行处理。主要用于读写诸如图像或声音的二进制数据。字符流:以字符(16位二进制)为单位进行处理。
都是通过字节流的方式实现的。字符流是对字节流进行了封装,方便操作。在最底层,所有的输入输出都是字节形式的。
按功能分类:
节点流:从特定的地方读写的流类,如磁盘或者一块内存区域。过滤流:使用节点流作为输入或输出。过滤流是使用一个已经存在的输入流或者输出流连接创建的。
刚开始学习的java的io基本都是BIO也就是阻塞的IO。阻塞就是我们才操作该方法时需要一定时间的等待该方法完成后才能继续进行。阻塞的IO在我们读或者写的时候如果设备或读写资源比较繁忙时我们的程序会被堵在一个地方。
流相当是一种管道,我们的资源数据会在流中传输。java的IO主要分为以下几种流。
1.2.1 Java字节流Stream
InputStream跟OutputStream是所有字节流的父类他是一个抽象类
所有的读操作都继承自一个公共超类java.io.InputStream类。
所有的写操作都继承自一个公共超类java.io.OutputStream类
其主要实现子类有:ByteArrayInputStream字节数组输入流, FileInputStream文件流,ObjectInputStream对象流, ZipFileInputStream压缩流,PipedInputStream从线程管道中读取数据字节,StringBufferInputStream从字符串中读取数据字节,SequenceInputStream从两个或多个低级流中读取数据字节,当到达流的末尾时从一个流转到另一个流,System.in从用户控制台读取数据字节
FilterInputStream过滤器流,过滤器流即能把基本流包裹起来,提供更多方便的用法。FilterInputStream类的构造方法为FilterInputStream(InputStream),在指定的输入流之上,创建一个输入流过滤器
java流体系:缓存流、转换流、内存流、退出输入流、管道流、对象流。
字节流的read方法读取的是一个字节也就是8位2进制,而字符流读取的是一个字符是16位2进制
其实在我们读取操作的时候,最终是利用的操作系统的读取,而默认操作系统是通过块来返回我们的IO读取的数据,但是java的IO却是以1个字节字节的传输,势必会使性能降低,但我们可以通过缓冲区来改善这种情况。
但是缓冲区的大小第一成多大才能让速度更快呢?在这里并没有确定的数值,只能是根据操作系统来定,但是这个值必须是8的倍数,这跟内存页有关 系,内存的翻页其实消耗的性能是比较多的
其实内存页的概念就跟磁盘的扇区是差不多的,磁盘是分扇区的,而内存也是分页的,都是为了方便数据的管理,也是数据存储的小单元。
抽象类InputStream的类层次
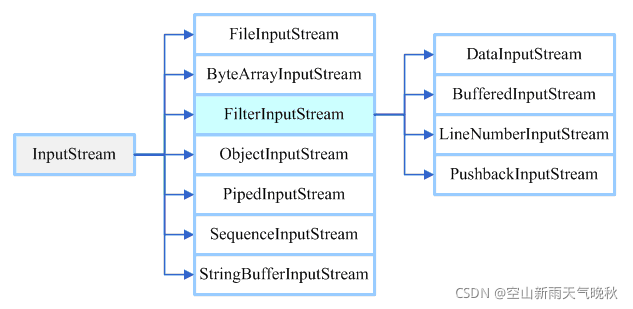
抽象类OutputStream的类层次结构:

1.2.1.1 使用缓冲区读入
例子:普通的方式没有使用缓冲区
public static void f1() throwsException{
FileInputStream fis=new FileInputStream(new File("e:\\out.txt"));
int length=0;
while((length=fis.read())!=-1){
System.out.print((char)length);
}
fis.close();
}
例子:我们使用缓冲区来读写,虽然速度快了但是出现第二个问题,就是读出的数据会有很多空格,这是因为最后一次缓冲区并没有填满,后面的空间被自动补充,导致出现很多空格。
/**
* 会多读很多
* @throws Exception
*/
public static void f2() throws Exception{
FileInputStream fis=new FileInputStream(new File("e:\\out.txt"));
byte[] buffer=new byte[1024];
int length=0;
while((length=fis.read(buffer))!=-1){
System.out.print(new String(buffer));
}
fis.close();
}
例子:我们接来改进一下这个例子。我们在构建数据的时候通过一个参数截取缓冲区中读到的数据长度,这样就保证了速度又不会出现过多的空格。
public static void f3() throws Exception{
FileInputStream fis=new FileInputStream(new File("e:\\out.txt"));
byte[] buffer=new byte[1024];
int length=0;
while((length=fis.read(buffer))!=-1){
System.out.print(new String(buffer,0,length));
}
fis.close();
}
1.2.1.2 使用缓冲区写出
写入的例子:
public staticvoidf4()throws Exception{
FileOutputStream fos=new FileOutputStream("e:\\in.txt");
String s="helloworld";
fos.write(s.getBytes());
fos.flush();
fos.close();
}
大家可能比较奇怪flush是做什么用的:其实flush刷新就是刷新此输出流并强制缓存输出字节。在这里我们再扩充一下知识:什么是读缓存跟写缓存
读缓存:读缓存也是经常见到的缓存,例如我们去数据库查询数据,当我们第一次查找ID为1的数据时需要去数据库中查找,但是当我们第二次再去查 找ID为1的数据时还需要去数据库查找吗?答案是否定的,数据库查找数据是相对比较慢的一个操作,而我们在第一次去读取数据时已经将他放到一个缓存中,这 里大家可以把它想象成一个hashmap,第二次查找时我们先去hashmap中查找,如果没有再去数据库查找。写缓存:学过数据库的读者应该都知道,数据库的插入操作其实耗费的时间是比较可观的,尤其是读写比较频繁的数据库,无疑压力是非常的大的,如何才能缓解这种情况,这里就需要用到写缓存,我们在写入文件时,其实并不是正在的写入数据库,我们可以先将他写入内存,如果有人读取,我们直接从内存中给他,而当压力小的时候我们可以再写入数据库,但是我们不得不考虑一个情形就是万一机器断电,那么我们未写入的岂不是丢失了,数据丢失对于企业来说无疑是灾难,我们可以写入日志,直接把元数据写入文件,就跟我们计算机休眠一样,将内存的数据写入内存,当恢复休眠时再从硬盘恢复到内存。
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
public classTest3 {
public static void copy(String src,String des)throws Exception{
FileInputStream fis=new FileInputStream(src);
FileOutputStream fos=new FileOutputStream(des);
byte[] buffer=new byte[1024];
int hasRead=0;
while((hasRead=fis.read(buffer))!=-1){
fos.write(buffer,0, hasRead);
fos.flush();
}
fis.close();
fos.close();
}
}
1.2.2 java字符流Reader Writer
Reader跟Writer是所有字节流的父类,都继承了reader跟writer。
所有的读操作都继承自一个公共超类java.io.Reader类。
所有的写操作都继承自一个公共超类java.io.Writer类。
字符流是一个字符一个字符的读取写入。对于文字操作非常的方便。
CharArrayReader从字符数组中读取数据,
FileReader(InputStreamReader的子类)从本地文件系统中读取字符序列
StringReader从字符串中读取字符序列
PipedReader从线程管道中读取字符序列
public classTest4 {
public void testRead() throws Exception{
FileReader read=new FileReader("");
char[] buffer=new char[1024];
int hasRead=0;
while((hasRead=read.read(buffer))!=-1){
String s=new String(buffer,0,hasRead);
System.out.println(s);
}
read.close();
}
public void testWriter() throws Exception{
FileWriter writer=new FileWriter("");
String s="aaaaaaaa";
writer.write(s);
writer.flush();
writer.close();
}
}
1.2.3 Java缓冲流
BufferedReader缓冲流是将字符流转换成缓冲流,缓冲流主要实现了readline方法,可以一次读取一行数据。BufferWriter也是缓冲流,但是我们经常使用的是PrintWriter可以实现我们向控制台打印一样方便。
java.io.BufferedReader和java.io.BufferedWriter类各拥有8192字符的缓冲区。当BufferedReader在读取文本文件时,会先尽量从文件中读入字符数据并置入缓冲区,而后若使用read()方法,会先从缓冲区中进行读取。如果缓冲区数据不足,才会再从文件中读取,使用BufferedWriter时,写入的数据并不会先输出到目的地,而是先存储至缓冲区中。如果缓冲区中的数据满了,才会一次对目的地进行写出。- 从标准输入流
System.in中直接读取使用者输入时,使用者每输入一个字符,System.in就读取一个字符。为了能一次读取一行使用者的输入,使用了BufferedReader来对使用者输入的字符进行缓冲。readLine()方法会在读取到使用者的换行字符时,再一次将整行字符串传入。
例子:
public class Test5 {
public void test() throws Exception{
File file=new File("");
FileReader reader=new FileReader(file);
BufferedReader br=new BufferedReader(reader);
Strings="";
while((s=br.readLine())!=null){
System.out.println(s);
}
reader.close();
br.close();
}
}
1.2.4 Java转换流
转换流:将inputstream字节流转换为reader将outputstream字节流转换成writer可以使用inputstreamreader跟outputstreamwriter
public voidtest2() throwsException{
BufferedReader br=new BufferedReader(new InputStreamReader(System.in));
while(br.read()!=-1){
}
}
System.in是一个位流,为了转换为字符流,可使用InputStreamReader为其进行字符转换,然后再使用BufferedReader为其增加缓冲功能。
public class BufferedReaderWriterDemo
{
public static void main(String[] args)
{
try
{
//缓冲System.in输入流
//System.in是位流,可以通过InputStreamReader将其转换为字符流
BufferedReader bufReader = new BufferedReader(new InputStreamReader(System.in));
//缓冲FileWriter
BufferedWriter bufWriter = new BufferedWriter(new FileWriter(args[0]));
String input = null;
//每读一行进行一次写入动作
while(!(input = bufReader.readLine()).equals("quit"))
{
bufWriter.write(input);
//newLine()方法写入与操作系统相依的换行字符,依执行环境当时的OS来决定该输出那种换行字符
bufWriter.newLine();
}
bufReader.close();
bufWriter.close();
}
catch(ArrayIndexOutOfBoundsException e)
{
System.out.println("没有指定文件");
}
catch(IOException e)
{
e.printStackTrace();
}
}
}
运行时 java ysu.hxy.BufferedReaderWriterDemo test2.txt
1.2.5 数据流
dataoutputstream和datainputstream
public void test1() throws Exception{
DataOutputStream dos=new DataOutputStream(new FileOutputStream(""));
// dos.writeInt();写入一个四位的
// dos.writeByte()
DataInputStream dis=new DataInputStream(new FileInputStream(""));
dis.readBoolean();
dis.readInt();
dis.readChar();
}
1.2.6 随机访问流RandomAccessFile
RandomAccessFile流有两个重要的方法,longgetFilePointer()放回文件指针当前位置,void seek(long pos)将文件的指针定位到pos位置。
read方法默认是从指针位置开始操作。文件的访问模式有四种:r只读方式,如果写入操作则抛出异常,rw读写方式如果没有文件则创建文件。rws除了rw还对文件内容或元数据进行更新同步写入,而rwd对文件内容同步更新。
1.2.7 对象流
序列化:将对象写入到文件中,ObjectOutputStream 接受一个字节流,必须实现序列化接口
Java序列化深入讲解
1.2.8 流复用问题
IO流就像一个水管,只能单向流动,结束了就会报流结束异常java.io.EOFException,如:
@Test
public void testIO() {
try (InputStream is = new BufferedInputStream(new FileInputStream("D:\\test.txt"));
OutputStream os = new FileOutputStream("D:\\test123.txt");)
{
System.out.println(is.available());
IOUtils.copy(is, os);
os.flush();
ObjectInputStream ois = new ObjectInputStream(is);
while (true) {//循环打印输出对象
try {
System.out.println(ois.readObject());
} catch (EOFException e) {
break;
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
运行结果:
java.io.EOFException
at java.io.ObjectInputStream$PeekInputStream.readFully(ObjectInputStream.java:2638)
...
点击了解IOUtils工具类
这时候就用到流的mark和reset方法,可以解决流复用问题
public void mark(int readlimit): 其功能是对输入流进行定位,如果是字节流,则定位字节,如果是字符流则定位字符。参数readlimit指的是在mark之后,可以从输入流中读取的字节个数或者字符个数,如果超出的话,reset()函数将出现问题,但是需要缓冲流才可以使用,若直接使用InputStream会报错public void reset() throws IOException: 将此流重新定位到最后一次对此输入流调用mark方法时的位置
@Test
public void testIO() {
try (InputStream is = new BufferedInputStream(new FileInputStream("D:\\test.txt"));
OutputStream os = new FileOutputStream("D:\\test123.txt");)
{
System.out.println(is.available());
is.mark(is.available()+1);
IOUtils.copy(is, os);
os.flush();
is.reset();
ObjectInputStream ois = new ObjectInputStream(is);
while (true) {//循环打印输出对象
try {
System.out.println(ois.readObject());
} catch (EOFException e) {
break;
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
1.3 IO底层工作原理
1.3.1 缓存处理和内核vs用户空间
缓冲与缓冲的处理方式,是所有I/O操作的基础。术语输入、输出只对数据移入和移出缓存有意义。任何时候都要把它记在心中。通常,进程执行操作系统的I/O请求包括数据从缓冲区排出(写操作)和数据填充缓冲区(读操作)。这就是I/O的整体概念。在操作系统内部执行这些传输操作的机制可以非常复杂,但从概念上讲非常简单。
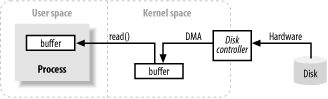
上图显示了一个简化的逻辑图,它表示块数据如何从外部源,例如一个磁盘,移动到进程的存储区域(例如RAM)中。首先,进程要求其缓冲通过read()系统调用填满。这个系统调用导致内核向磁盘控制硬件发出一条命令要从磁盘获取数据。磁盘控制器通过DMA直接将数据写入内核的内存缓冲区,不需要主CPU进一步帮助。当请求read()操作时,一旦磁盘控制器完成了缓存的填写,内核从内核空间的临时缓存拷贝数据到进程指定的缓存中。
有一点需要注意,在内核试图缓存及预取数据时,内核空间中进程请求的数据可能已经就绪了。如果这样,进程请求的数据会被拷贝出来。如果数据不可用,则进程被挂起。内核将把数据读入内存。
1.3.2 虚拟内存
所有现代操作系统都使用虚拟内存。虚拟内存意味着人工或者虚拟地址代替物理(硬件RAM)内存地址。虚拟地址有两个重要优势:
- 多个虚拟地址可以映射到相同的物理地址
- 一个虚拟地址空间可以大于实际可用硬件内存
在上面介绍中,从内核空间拷贝到最终用户缓存看起来增加了额外的工作。为什么不告诉磁盘控制器直接发送数据到用户空间的缓存呢?好吧,这是由虚拟内存实现的。用到了上面的优势1。通过将内核空间地址映射到相同的物理地址作为一个用户空间的虚拟地址,DMA硬件(只能访问物理内存地址)可以填充缓存。这个缓存同时对内核和用户空间进程可见。
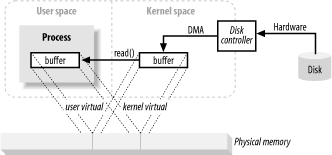
这就消除了内核和用户空间之间的拷贝,但是需要内核和用户缓冲区使用相同的页面对齐方式。
缓冲区必须使用的块大小的倍数磁盘控制器(通常是512字节的磁盘扇区)。操作系统将其内存地址空间划分为页面,这是固定大小的字节组。这些内存页总是磁盘块大小的倍数和通常为2倍(简化寻址)。典型的内存页面大小是1024、2048和4096字节。虚拟和物理内存页面大小总是相同的。
1.3.3 内存分页
为了支持虚拟内存的第2个优势(拥有大于物理内存的可寻址空间)需要进行虚拟内存分页(通常称为页交换)。
这种机制凭借虚拟内存空间的页可以持久保存在外部磁盘存储,从而为其他虚拟页放入物理内存提供了空间。本质上讲,物理内存担当了分页区域的缓存。分页区是磁盘上的空间,内存页的内容被强迫交换出物理内存时会保存到这里。
调整内存页面大小为磁盘块大小的倍数,让内核可以直接发送指令到磁盘控制器硬件,将内存页写到磁盘或者在需要时重新加载。事实证明,所有的磁盘I/O操作都是在页面级别上完成的。这是数据在现代分页操作系统上在磁盘与物理内存之间移动的唯一方式。
现代CPU包含一个名为内存管理单元(MMU)的子系统。这个设备逻辑上位于CPU与物理内存之间。它包含从虚拟地址向物理内存地址转化的映射信息。当CPU引用一个内存位置时,MMU决定哪些页需要驻留(通常通过移位或屏蔽地址的某些位)以及转化虚拟页号到物理页号(由硬件实现,速度奇快)。
1.3.4 面向文件、块I/O
文件I/O总是发生在文件系统的上下文切换中。文件系统跟磁盘是完全不同的事物。磁盘按段存储数据,每段512字节 。 它是硬件设备,对保存的文件语义一无所知。它们只是提供了一定数量的可以保存数据的插槽。从这方面来说,一个磁盘的段与内存分页类似。它们都有统一的大小并且是个可寻址的大数组
另一方面,文件系统是更高层抽象。文件系统是 安排和翻译保存磁盘(或其它可随机访问,面向块的设备)数据的一种特殊方法。你写的代码几乎总是与文件系统交互,而不与磁盘直接交互。文件系统定义了文件名、路径、文件、文件属性等抽象。
一个文件系统(在硬盘中)组织了一系列均匀大小的数据块。有些块保存元信息,如空闲块的映射、目录、索引等。其它块包含实际的文件数据。单个文件的元信息描述哪些块包含文件数据、数据结束位置、最后更新时间等。当用户进程发送请求来读取文件数据时,文件系统实现准确定位数据在磁盘上的位置。然后采取行动将这些磁盘扇区放入内存中。
文件系统也有页的概念,它的大小可能与一个基本内存页面大小相同或者是它的倍数。典型的文件系统页面大小范围从2048到8192字节,并且总是一个基本内存页面大小的倍数。
分页文件系统执行I/O可以归结为以下逻辑步骤:
- 确定请求跨越了哪些文件系统分页(磁盘段的集合)。磁盘上的文件内容及元数据可能分布在多个文件系统页面上,这些页面可能是不连续的。
- 分配足够多的内核空间内存页面来保存相同的文件系统页面。
- 建立这些内存分页与磁盘上文件系统分页的映射。
- 对每一个内存分页产生分页错误。
- 虚拟内存系统陷入分页错误并且调度
pagins(页面调入),通过从磁盘读取内容来验证这些页面。 - 一旦
pageins完成,文件系统分解原始数据来提取请求的文件内容或属性信息。
需要注意的是,这个文件系统数据将像其它内存页一样被缓存起来。在随后的I/O请求中,一些数据或所有文件数据仍然保存在物理内存中,可以直接重用不需要从磁盘重读。
1.3.5 文件锁定
文件加锁是一种机制,一个进程可以阻止其它进程访问一个文件或限制其它进程访问该文件。虽然名为文件锁定,意味着锁定整个文件(经常做的)。锁定通常可以在一个更细粒度的水平。
随着粒度下降到字节级,文件的区域通常会被锁定。锁与特定文件相关联,起始于文件的指定字节位置并运行到指定的字节范围。这一点很重要,因为它允许多个进程协作访问文件的特定区域而不妨碍别的进程在文件其它位置操作。
文件锁有两种形式:共享和独占
- 多个共享锁可以同时在相同的文件区域有效。
- 独占锁要求没有其它锁对请求的区域有效。
1.3.6 流I/O
并非所有的I/O是面向块的。还有流I/O,它是管道的原型,必须顺序访问I/O数据流的字节。常见的数据流有TTY(控制台)设备、打印端口和网络连接。
数据流通常但不一定比块设备慢,提供间歇性输入。大多数操作系统允许在非阻塞模式下工作。允许一个进程检查数据流的输入是否可用,不必在不可用时发生阻塞。这种管理允许进程在输入到达时进行处理,在输入流空闲时可以执行其他功能。
比非阻塞模式更进一步的是有条件的选择(readiness selection)。它类似于非阻塞模式(并且通常建立在非阻塞模式基础上),但是减轻了操作系统检查流是否就绪准备的负担。操作系统可以被告知观察流集合,并向进程返回哪个流准备好的指令。这种能力允许进程通过利用操作系统返回的准备信息,使用通用代码和单个线程复用多个活动流。这种方式被广泛用于网络服务器,以便处理大量的网络连接。准备选择对于大容量扩展是至关重要的。
1.4 IO流中flush原理
大家在使用Java IO流中OutputStream、PrintWriter ……时,会经常用到它的flush()方法。那么为什么要flush?
与在网络硬件中缓存一样,流还可以在软件中得到缓存,即直接在Java代码中缓存。这可以通过BufferedOutputStream或BufferedWriter链接到底层流上来实现。因此,在写完数据时,flush就显得尤为重要
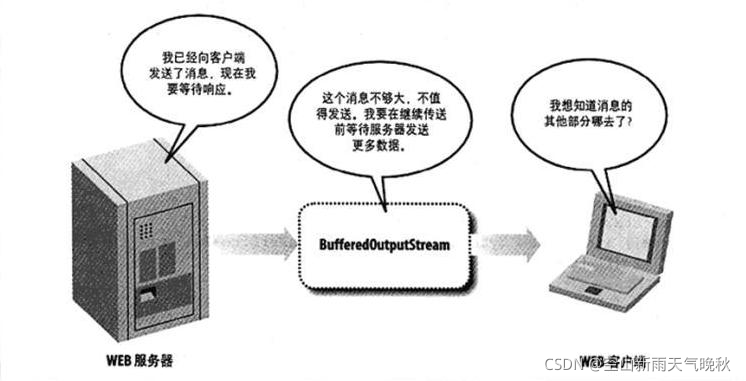
上图中WEB服务器通过输出流向客户端响应了一个300字节的信息,但是,这时的输出流有一个1024字节的缓冲区。所以,输出流就一直等着WEB服务器继续向客户端响应信 息,当WEB服务器的响应信息把输出流中的缓冲区填满时,这时,输出流才向WEB客户端响应消息。
为了解决这种尴尬的局面,flush()方法出现了。flush()方法可以强迫输出流(或缓冲的流)发送数据,即使此时缓冲区还没有填满,以此来打破这种死锁状态
当我们使用输出流发送数据时,当数据不能填满输出流的缓冲区时,这时,数据就会被存储在输出流的缓冲区中。如果,我们这个时候调用关闭(close)输出流,存储在输出流的缓冲区中的数据就会丢失。所以说,关闭(close)输出流时,应先刷新(flush)换冲的输出流,话句话说就是:迫使所有缓冲的输出数据被写出到底层输出流中
解读flush()源码:
下面以BufferedOutputStream类为例:
public class BufferedOutputStream extends FilterOutputStream {
public synchronizedvoid flush() throws IOException{
flushBuffer();
out.flush();
}
private void flushBuffer() throws IOException {
if(count > 0) {
out.write(buf, 0, count);
count = 0;
}
}
}
看到这里大家明白了吧,其实flush()也是通过out.write()将数据写入底层输出流的
1.5 System.out.println(hello world)原理
我们初学java的第一个程序是hello world
public class HelloWorld {
public static void main(String[] args) {
System.out.println("hello world");
}
}
上面程序到底是怎么在屏幕上输出hello world的呢?这就是本来要讲解的内容,即System.out.println("hello world")的原理。
我们先看看System.out.println的流程。先看看System.java中out的定义,源码如下
public final class System {
...
public final static PrintStream out = null;
...
}
从中,我们发现:
out是System.java的静态变量。而且out是PrintStream对象,PrintStream.java中有许多重载的println()方法。
我们知道了out是PrintStream对象。接下来,看它是如何被初始化的,它是怎么和屏幕输出关联的?
我们还是一步步来分析,首先看看System.java的initializeSystemClass()方法。
initializeSystemClass()的源码如下
private static void initializeSystemClass() {
props = new Properties();
initProperties(props); // initialized by the VM 5
sun.misc.VM.saveAndRemoveProperties(props);
lineSeparator = props.getProperty("line.separator");
sun.misc.Version.init();
FileInputStream fdIn = new FileInputStream(FileDescriptor.in);
FileOutputStream fdOut = new FileOutputStream(FileDescriptor.out);
FileOutputStream fdErr = new FileOutputStream(FileDescriptor.err);
setIn0(new BufferedInputStream(fdIn));
setOut0(new PrintStream(new BufferedOutputStream(fdOut, 128), true));
setErr0(new PrintStream(new BufferedOutputStream(fdErr, 128), true));
loadLibrary("zip");
Terminator.setup();
sun.misc.VM.initializeOSEnvironment();
Thread current = Thread.currentThread();
current.getThreadGroup().add(current);
setJavaLangAccess();
sun.misc.VM.booted();
}
我们只需要关注部分代码:即
FileOutputStream fdOut = new FileOutputStream(FileDescriptor.out);
setOut0(new PrintStream(new BufferedOutputStream(fdOut, 128), true));
将这两句话细分,可以划分为以下几步:
- FileDescriptor fd = FileDescriptor.out;
- FileOutputStream fdOut = new FileOutputStream(fd);
- BufferedOutputStream bufOut = new BufferedOutputStream(fdOut, 128);
- PrintStream ps = new PrintStream(bufout, true);
- setOut0(ps);
说明:
第1步,获取FileDescriptor.java中的静态成员out,out是一个FileDescriptor对象,它实际上是标准输出(屏幕)的标识符。
FileDescriptor.java中与FileDescriptor.out相关代码如下
public final class FileDescriptor {
private int fd;
public static final FileDescriptor out = new FileDescriptor(1);
private FileDescriptor(int fd) {
this.fd = fd;
useCount = new AtomicInteger();
}
...
}
创建标准输出(屏幕)对应的文件输出流。
创建文件输出流对应的缓冲输出流。目的是为“文件输出流”添加缓冲功能。
创建“缓冲输出流”对应的“打印输出流”。目的是为“缓冲输出流”提供方便的打印接口,如print(), println(), printf();使其能方便快捷的进行打印输出。
执行setOut0(ps);


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· 浏览器原生「磁吸」效果!Anchor Positioning 锚点定位神器解析
· 没有源码,如何修改代码逻辑?
· 一个奇形怪状的面试题:Bean中的CHM要不要加volatile?
· 分享4款.NET开源、免费、实用的商城系统
· 全程不用写代码,我用AI程序员写了一个飞机大战
· Obsidian + DeepSeek:免费 AI 助力你的知识管理,让你的笔记飞起来!
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· 白话解读 Dapr 1.15:你的「微服务管家」又秀新绝活了