requests 中文乱码
在学习爬虫过程中,使用requests模块爬取网页时,有时会出现中文乱码的问题,是由于requests采用错误的解码方式造成的,我们只需给它指定正确的解码方式就可以了:
1 # 指定 url 2 url = 'https://www.baidu.com' 3 4 # 发起 get 请求:get 方法会返回请求成功的相应对象 5 response = requests.get(url=url) 6 7 # 获取响应中的数据值:text 可以获取响应对象中字符串形式的页面数据 8 page_data = response.text 9 print(page_data)
得到的响应如下:
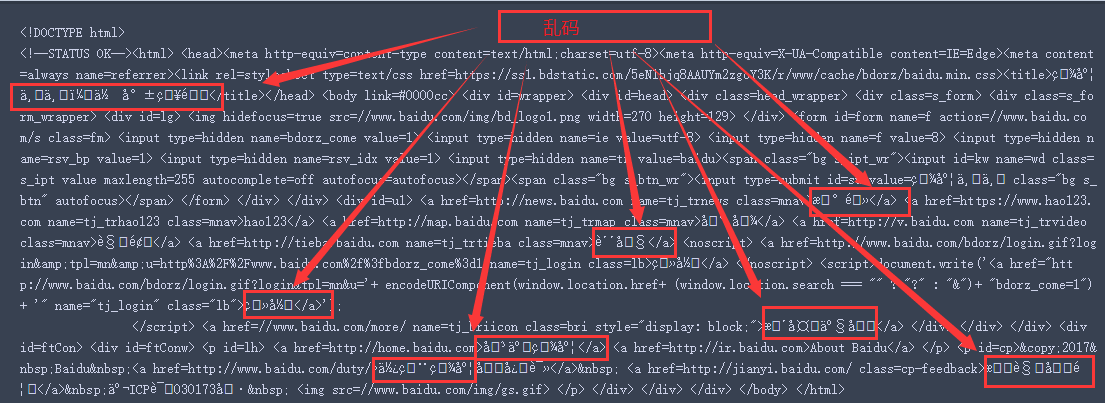
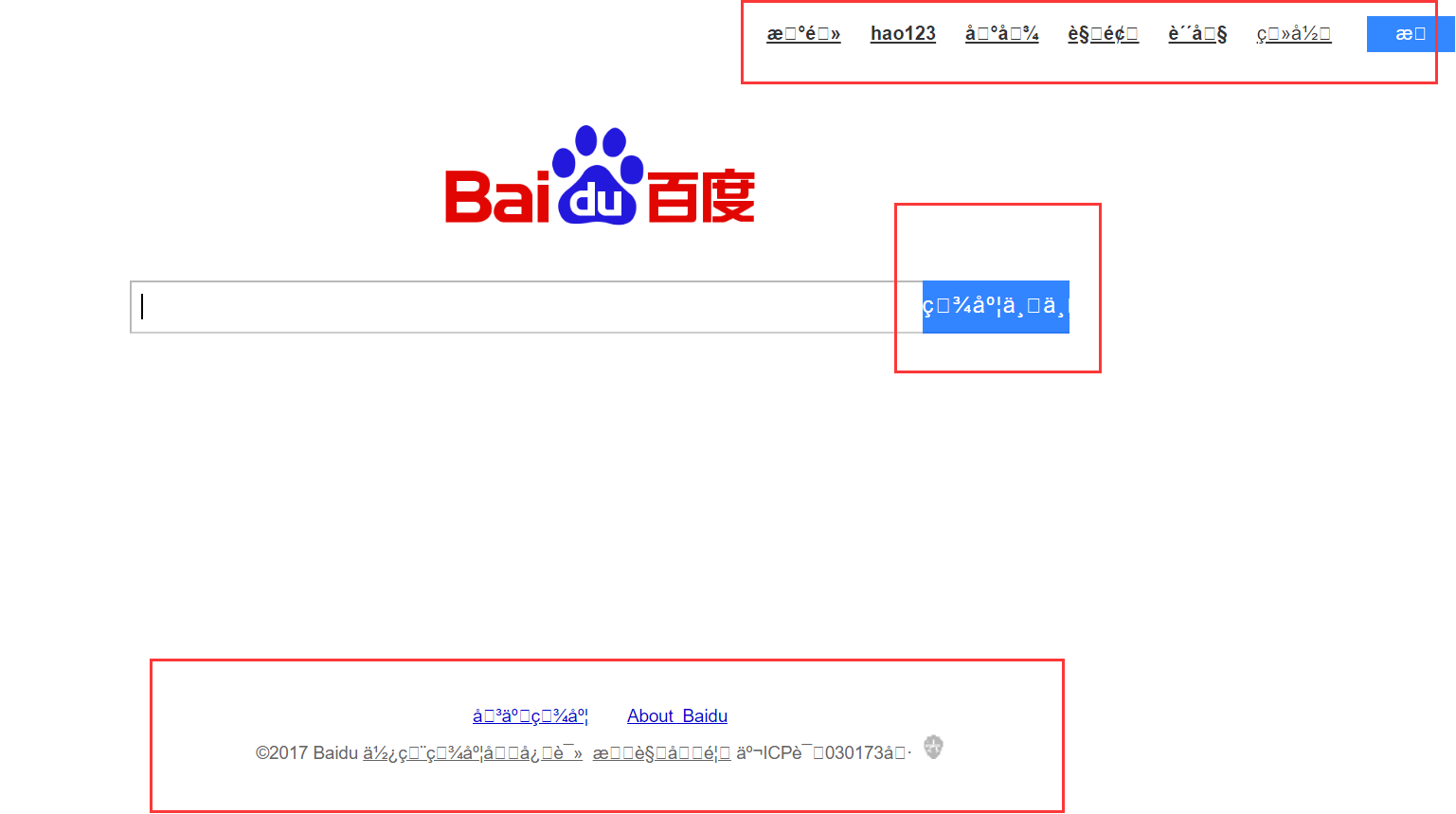
然后我们查看一下,页面的编码:知道页面的编码是 utf-8

所以我们只需在代码中加入一行代码,指定一下 编码格式为utf-8 就可以了,修改后代码如下:


1 import requests 2 # 指定 url 3 url = 'https://www.baidu.com' 4 5 # 发起 get 请求:get 方法会返回请求成功的相应对象 6 response = requests.get(url=url) 7 8 # 在这里指定下编码格式为:utf-8 9 response.encoding = 'utf-8' 10 11 # 获取响应中的数据值:text 可以获取响应对象中字符串形式的页面数据 12 page_data = response.text 13 print(page_data)
也可以这样写,用一行代码解决 ( 推荐 ) :
1 import requests 2 3 4 # 指定 url 5 url = 'https://www.baidu.com' 6 7 # 发起 get 请求:get 方法会返回请求成功的相应对象 8 # 并指定解码方式,在python3中默认编码为utf-8,所以这里的utf-8也可以省略不写,若是其他的编码,则必须注明 9 response = requests.get(url=url).content.decode('utf-8') 10 11 print(response)
修改后,结果如下:
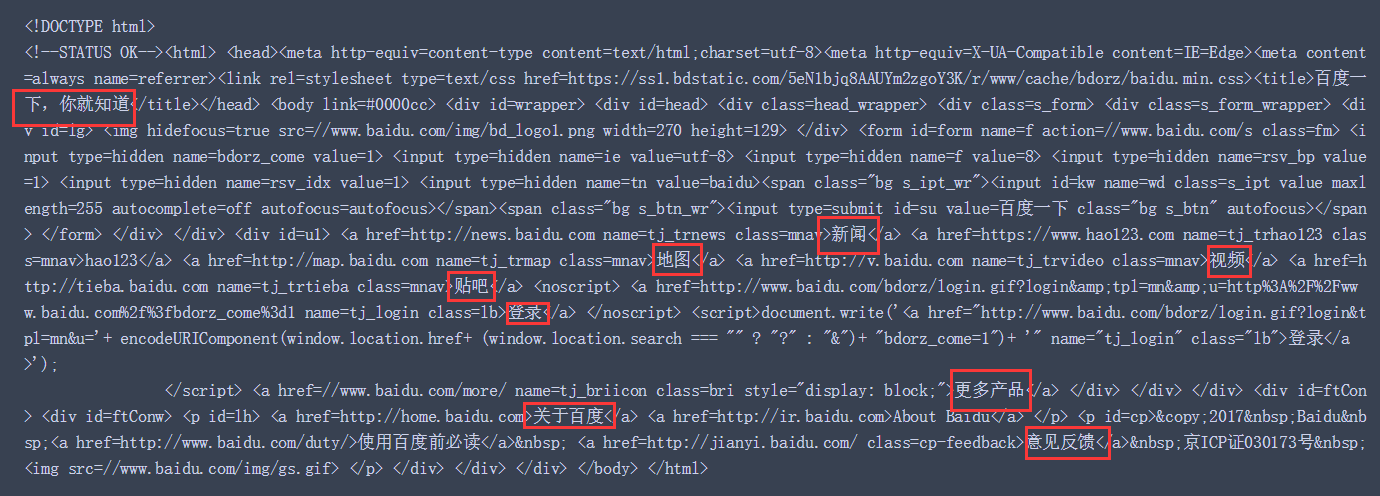
看,中文可以正常显示了!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号