
Stanford机器学习---第十一讲.异常检测
之前一直在看Standford公开课machine learning中Andrew老师的视频讲解https://class.coursera.org/ml/class/index
同时配合csdn知名博主Rachel Zhang的系列文章进行学习。
不过博主的博客只写到“第十讲 数据降维” http://blog.csdn.net/abcjennifer/article/details/8002329,后面还有三讲,内容比较偏应用,分别是异常检测、大数据机器学习、photo OCR。为了学习的完整性,我将把后续三讲的内容补充上来,写作方法借鉴博主Rachel Zhang。
本栏目(Machine learning)包括单参数的线性回归、多参数的线性回归、Octave Tutorial、Logistic Regression、Regularization、神经网络、机器学习系统设计、SVM(Support Vector Machines 支持向量机)、聚类、降维、异常检测、大规模机器学习等章节。内容大多来自Standford公开课machine learning中Andrew老师的讲解和其他书籍的借鉴。(https://class.coursera.org/ml/class/index)
第十一讲. 异常检测——Anomaly Detection
===============================
(一)、什么叫异常检测?
(二)、高斯分布(正态分布)
(三)、异常检测算法
(四)、设计一个异常检测系统
(五)、如何选取或设计feature
(六)、异常检测 VS 监督学习
(七)、多元高斯分布及其在异常检测问题上的应用
=====================================
(一)、什么叫异常检测?
举个栗子先:
飞机引擎正常情况下都是OK的状态,以防出现异常,当有新的引擎来到时,需要用一个模型去测试其 OK or anomaly,类似这样的问题就是异常检测问题。
x1和x2是引擎的两种特征,数据分布如下图1所示。
如果学习得到的模型是p(x),用来描述样本x属于not anomaly的概率,设置一个概率阈值,那么小于这个阈值时,就属异常。如下图2所示。
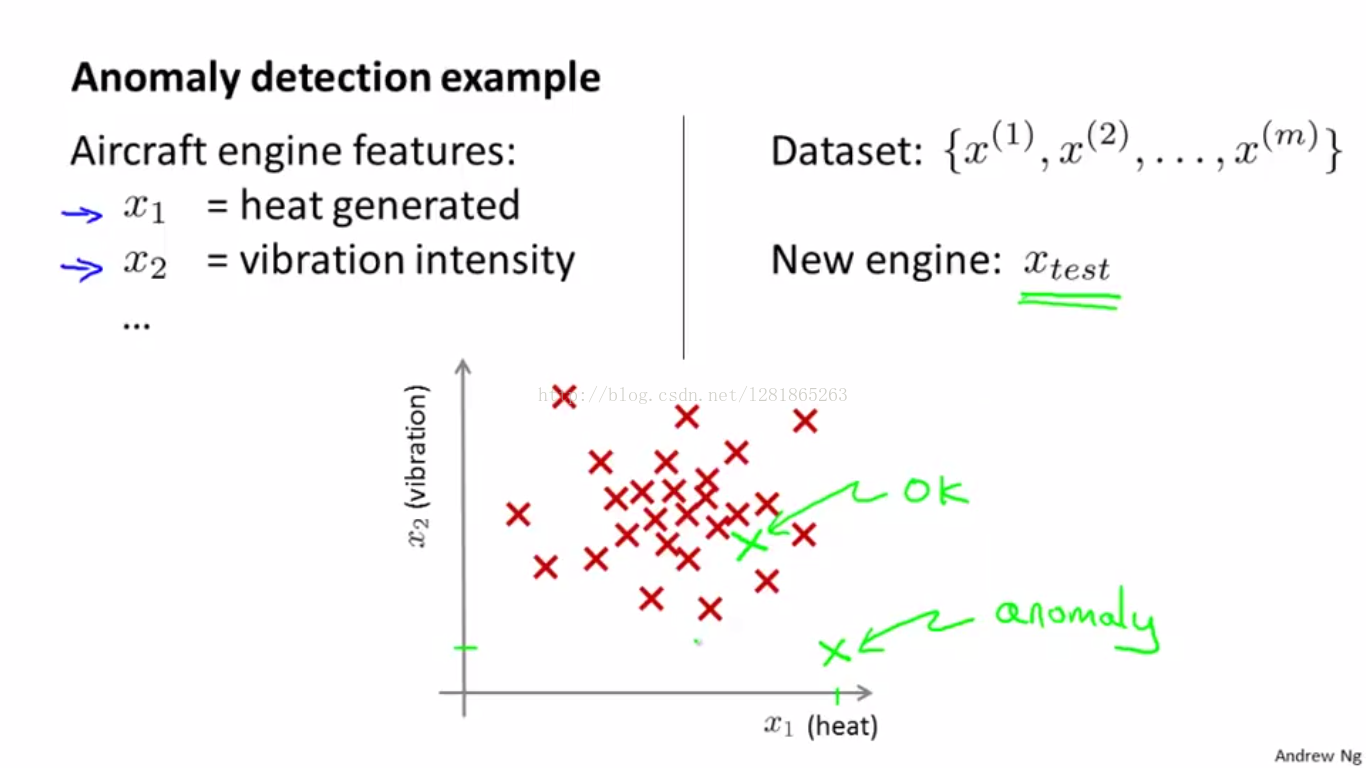
图1 举例说明异常检测问题

图2 密度估计原理
(二)、高斯分布(正态分布)
高斯分布又叫正态分布,这个我们都已经很熟悉了。异常检测的训练样本都是非异常样本,我们假设这些样本的特征服从高斯分布,在此基础上估计出一个概率模型,从而用该模型估计待测样本属于非异常样本的可能性。
什么叫高斯分布呢?如下图:

也就是说,高斯分布包含两个模型参数:均值,方差(或标准差)
举例说明这两个模型参数与高斯分布曲线的关系,如下图:
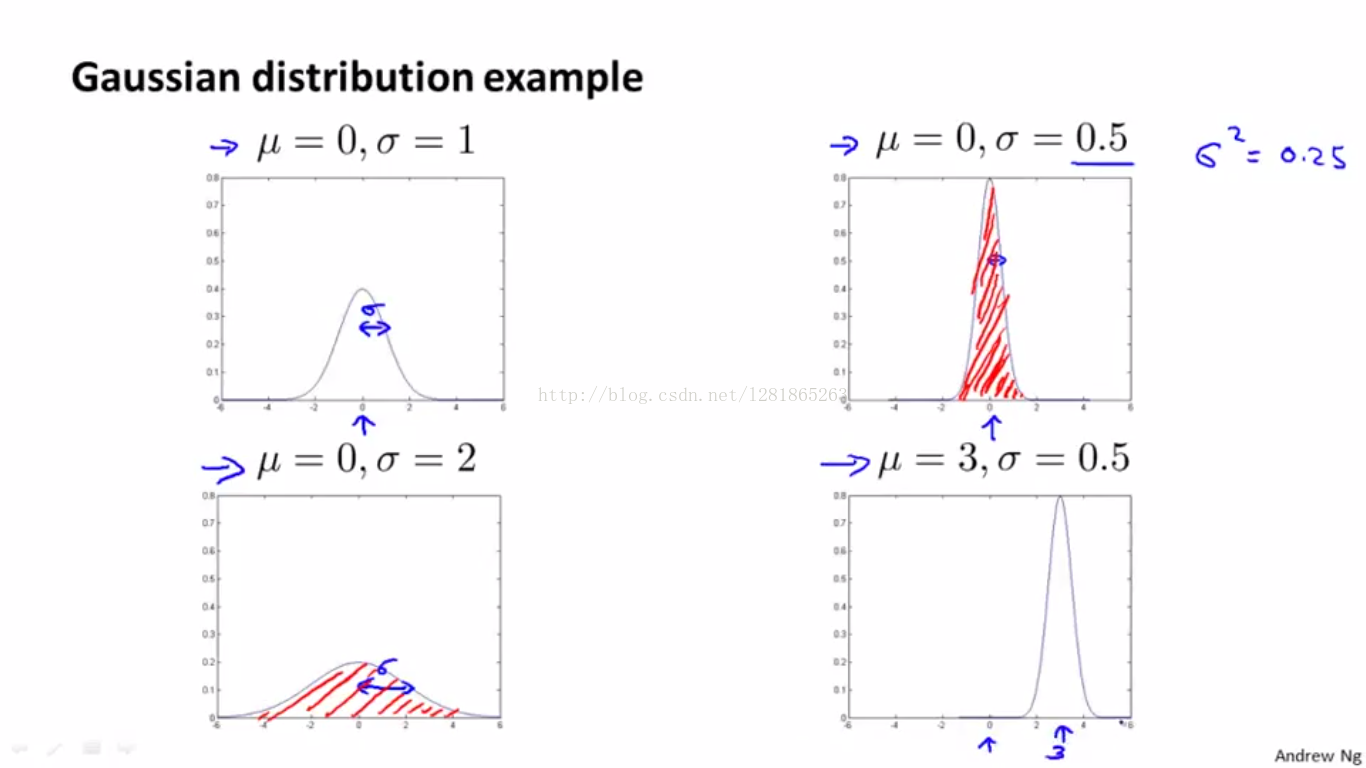
那么,标准差越大曲线越扁平,数据分布越发散,反之数据分布就越集中。
均值和标准差的估计方法如下图两个公式:

(三)、异常检测算法
假设训练数据的每一维特征都服从高斯分布,那么我们设计异常检测算法的训练过程如下:

相应的预测流程:
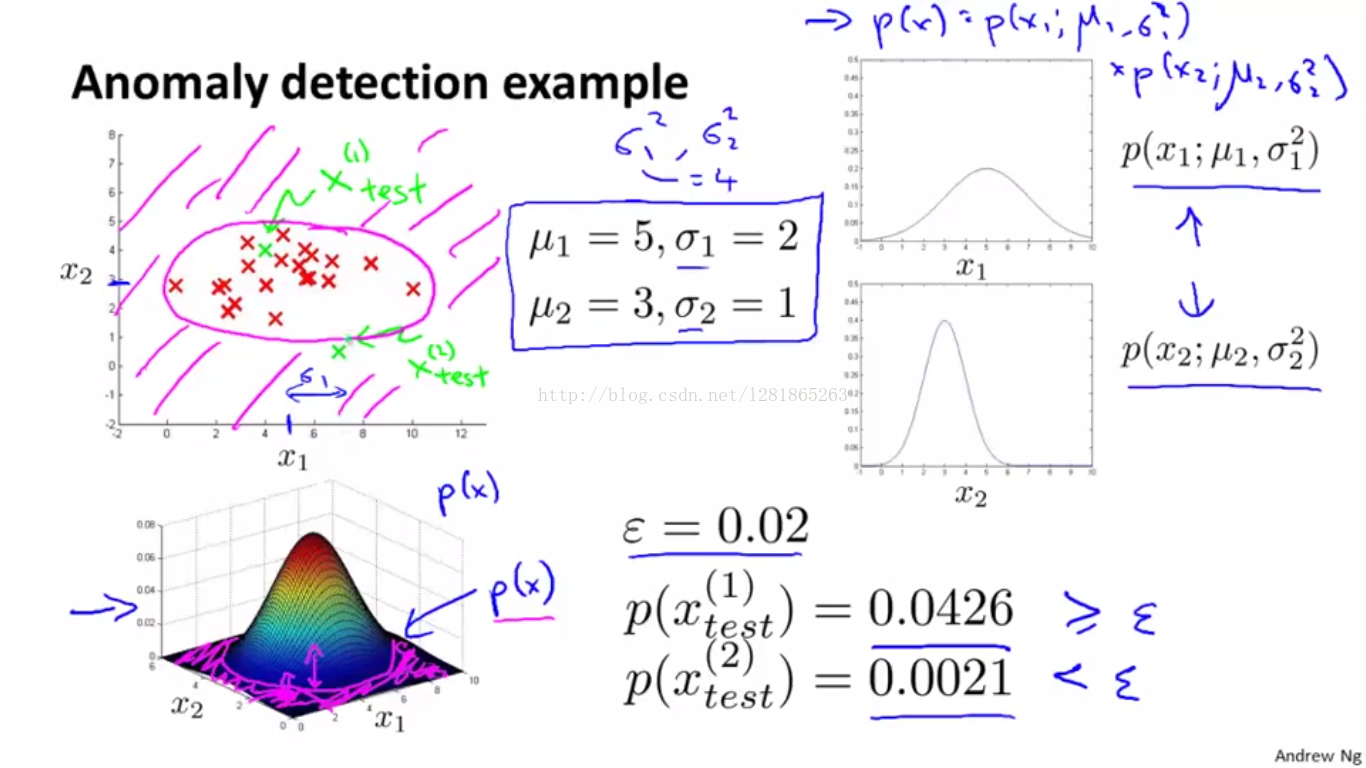
(四)、设计一个异常检测系统
要设计一个异常检测系统,我们需要考虑:
1、数据:在异常检测问题中,训练集里只有normal的样本,但为了测试系统性能等指标,我们当然也需要一些abnormal的样本。当然也就是说我们需要一批labeled数据,其中normal样本label为0,abnormal样本label为1。注意训练时只用label为0的样本
2、数据分组:我们需要train,cross validation,test三组数据
3、评估系统:在异常检测问题中,大部分数据是normal的,所以0和1两类样本严重不均衡,这时候评估系统性能时就不能简单地用分类错误率或者正确率来描述了。前面也提到过,针对这样的skewed class,需要用precision、recall、F-measure等概念来度量。
接下来,第一个问题“数据”我们上面已经叙述清楚了,关于第二个问题“数据分组”,我们来举个栗子:
假如我们所有的飞机引擎数据中有10000个正常样本,20个异常样本,此时建议分组比例如下:
- train set: 6000个正常样本
- cross validation set: 2000个正常样本,10个异常样本
- test set: 2000个正常样本,10个异常样本
那么关于第三个问题“系统评估”:
- 在train set上获得概率分布模型
- 在validation/test set上,预测样本的label(0 or 1)
- 计算evaluation metrics,可能包括:true positive, false positive, true negative, false negative, precision, recall, F1-score
- 此外,还可以用以上系统评估的方法,指导分类的概率阈值,即上图中epsilon的选取。
(五)、如何选取或设计feature
下面我们说说异常检测问题中的feature应如何选取或设计。
这部分将介绍两个方面:一是数据变换,二是增加更具辨别力的feature
一、数据变换
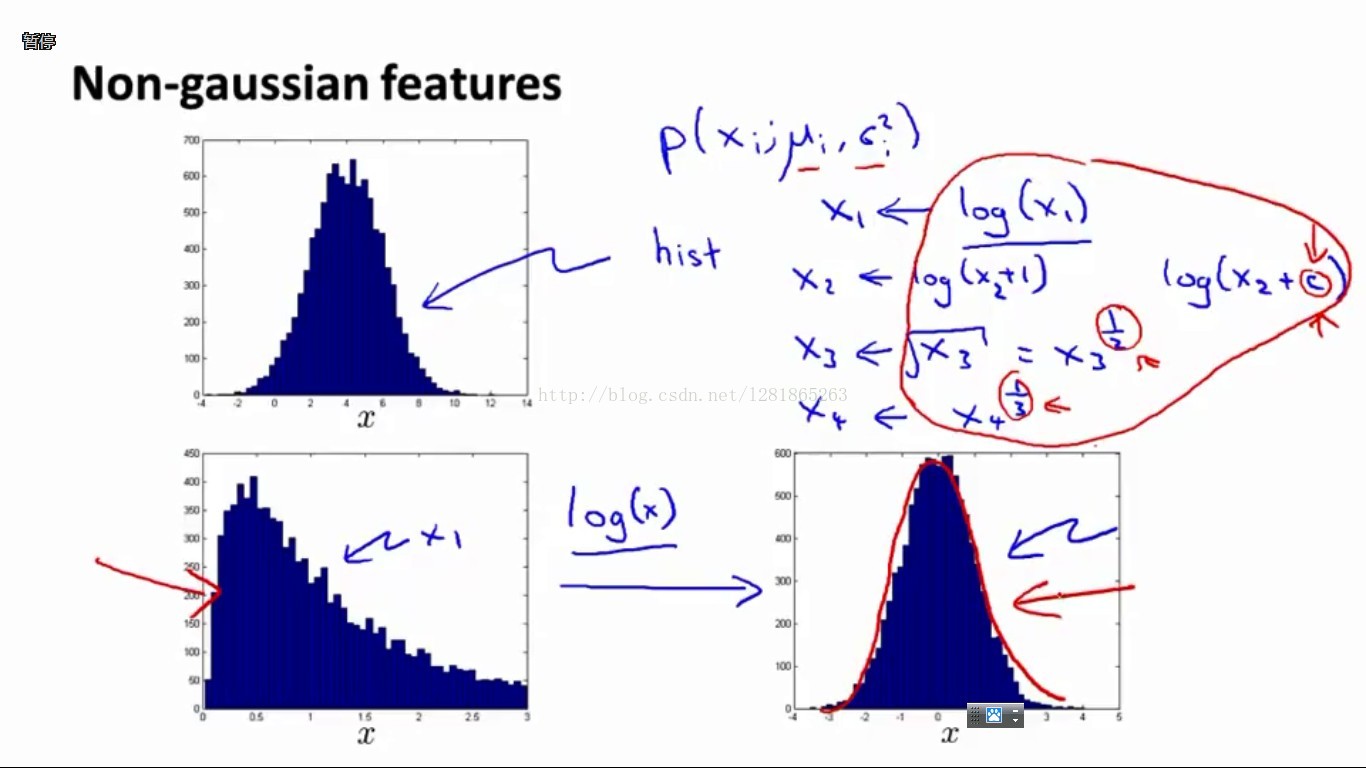
我们知道,上述异常检测系统是建立在每一维数据都服从高斯分布的假设基础上的。那么如果原始数据并不服从高斯分布呢?办法就是,先对原始数据进行某种变换,其实也相当于是设计新的feature。举例说明如下图:
左上图:统计数据x的直方图,发现基本符合高斯分布
左下图:发现数据的直方图并不符合高斯分布
右下图:对x进行log(x)变换以后,统计直方图基本符合高斯分布了
类似log(x)的变换有很多,如右上显示的几种函数都可以在实验时尝试。
下面举个实验中的例子,具体阐述一下如何做数据变换。如接下来的几幅图所示,代码是Octave的:
初始数据是这个样子的:
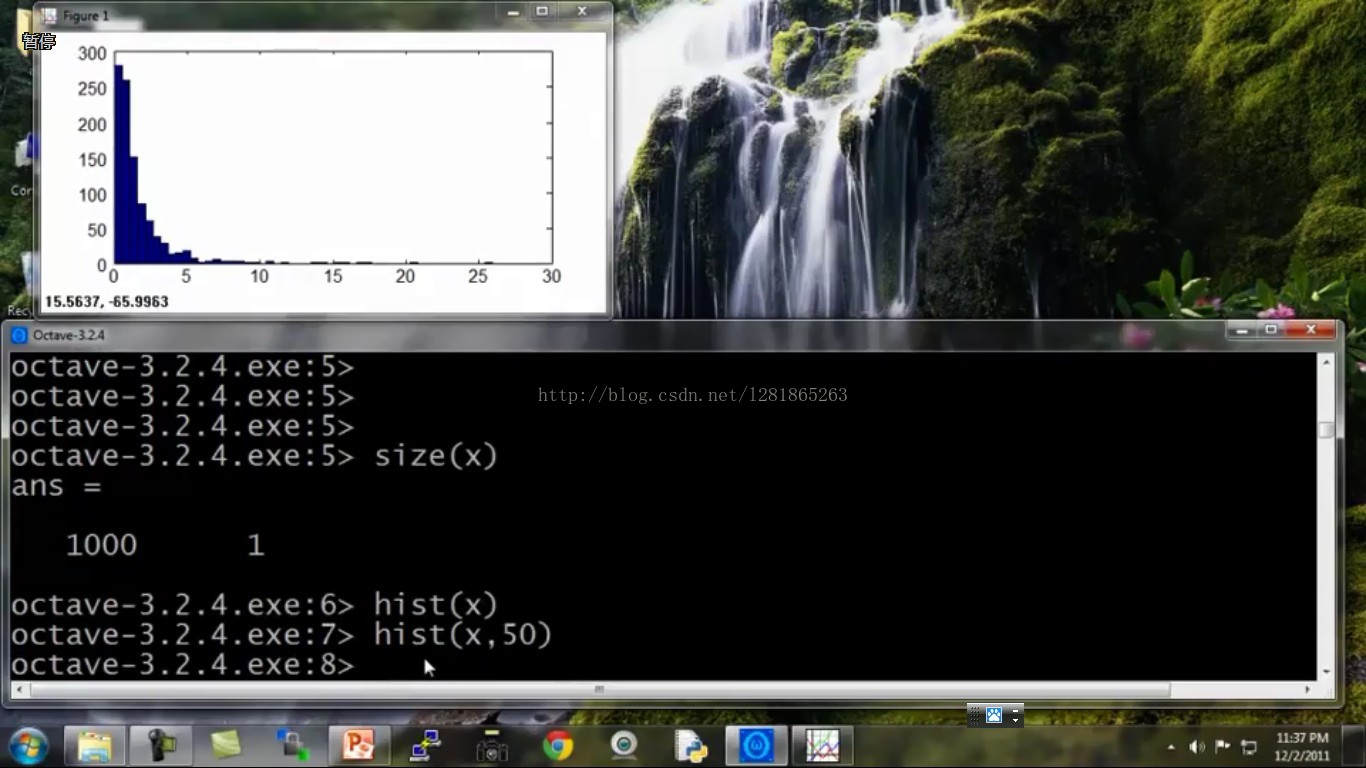
hist(x,50)中的50是hist函数的一个参数,这里不用太在意
好,下面试着找个函数做一下变换,就变成了接下来这样:
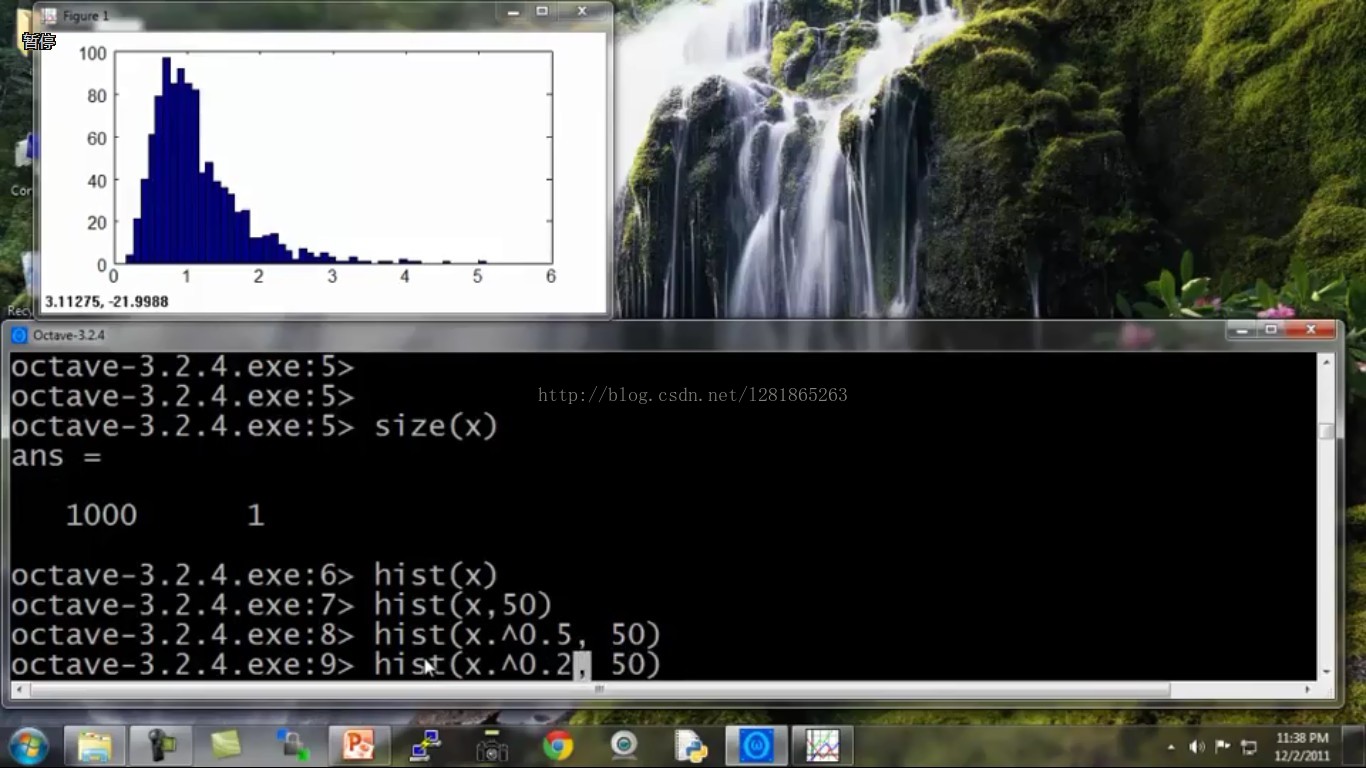
越来越像高斯分布了,调调函数的参数试试:
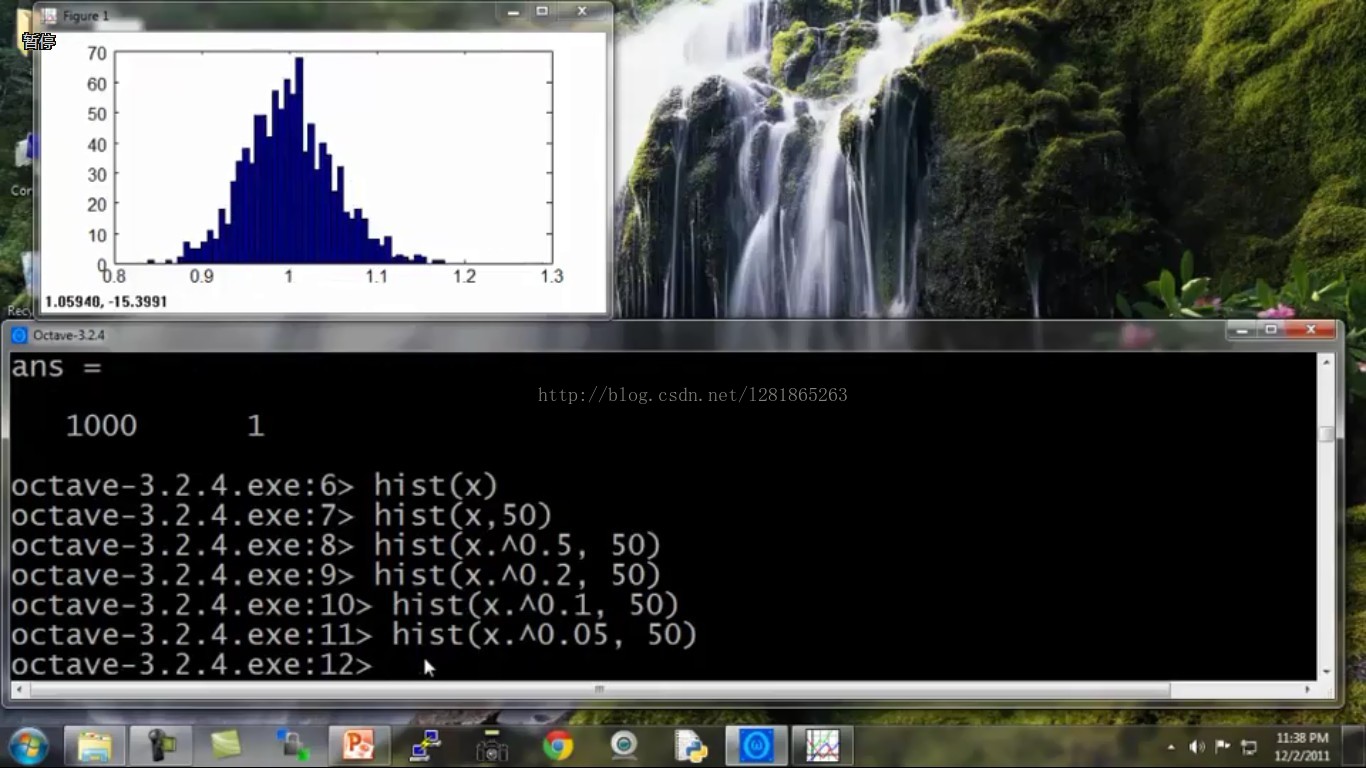
很好,这下更接近高斯分布了。
再试试别的函数,发现可能一下就搞定了,哈哈:
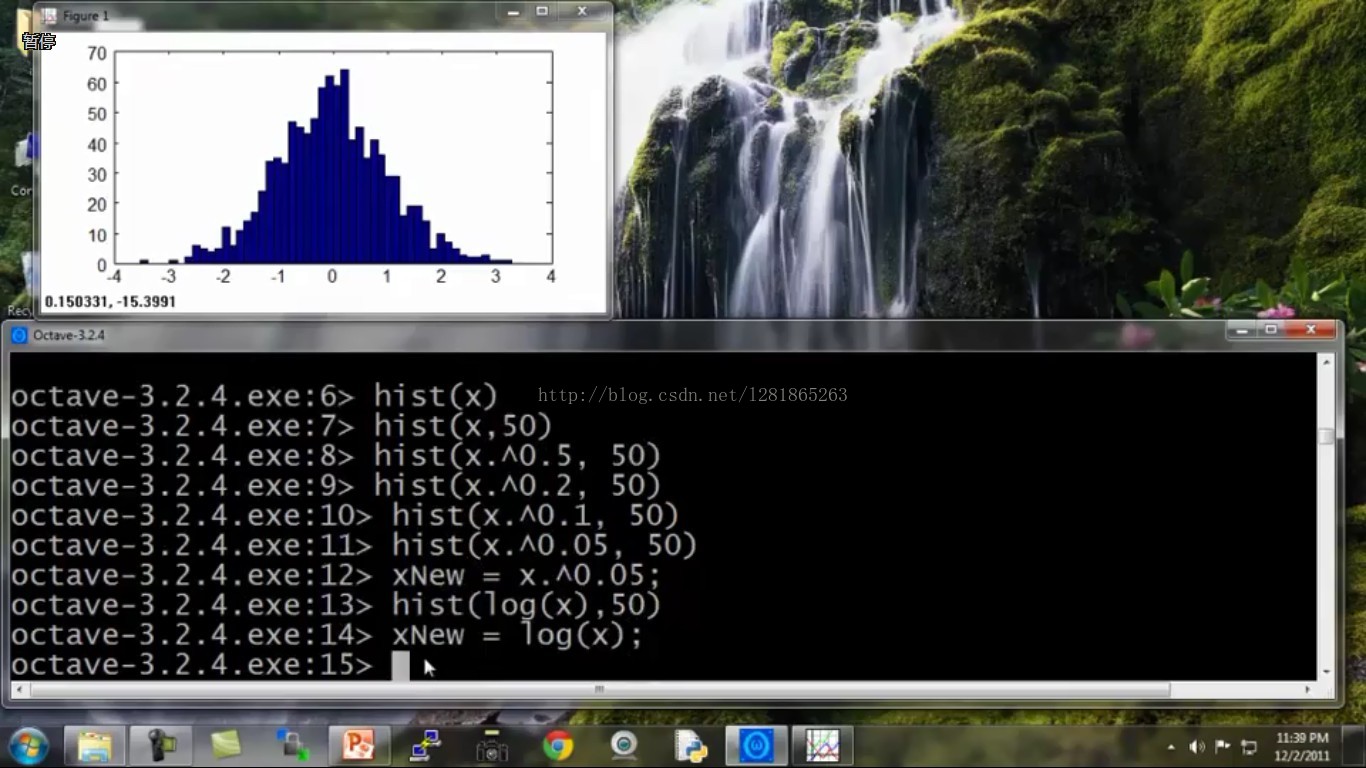
将变换后的符合高斯分布的数据赋值给新的xNew,拿xNew去估计高斯分布的两个参数即可。大功告成!
二、增加更具辨别力的feature
此外,由于我们是靠概率阈值来区分正常和异常样本的,我们当然是希望异常样本的概率值小且正常样本的概率值大。这时容易碰到的问题便是,如果一个测试样本的预测概率值不大不小恰好在阈值附近的话,预测结果出错的可能性就比较大了。如下图所示:
在绿色X样本的位置,预测概率值对于正常和异常样本来说都挺大的,很难给出一个正确的判断。

这时,如果我们有另外一个维度的特征,在绿色X的位置附近对于正常和异常样本更有区分度,那么我们可能就可以对绿色X做出正确的判断了。如下图所示,我们增加x2特征以后,发现绿色X样本在x2这个特征维度上的概率p(x2)很小,与p(x1)的乘积自然也较小。从而,当特征x1无法区分时,特征x2帮助模型成功辨别了该样本。
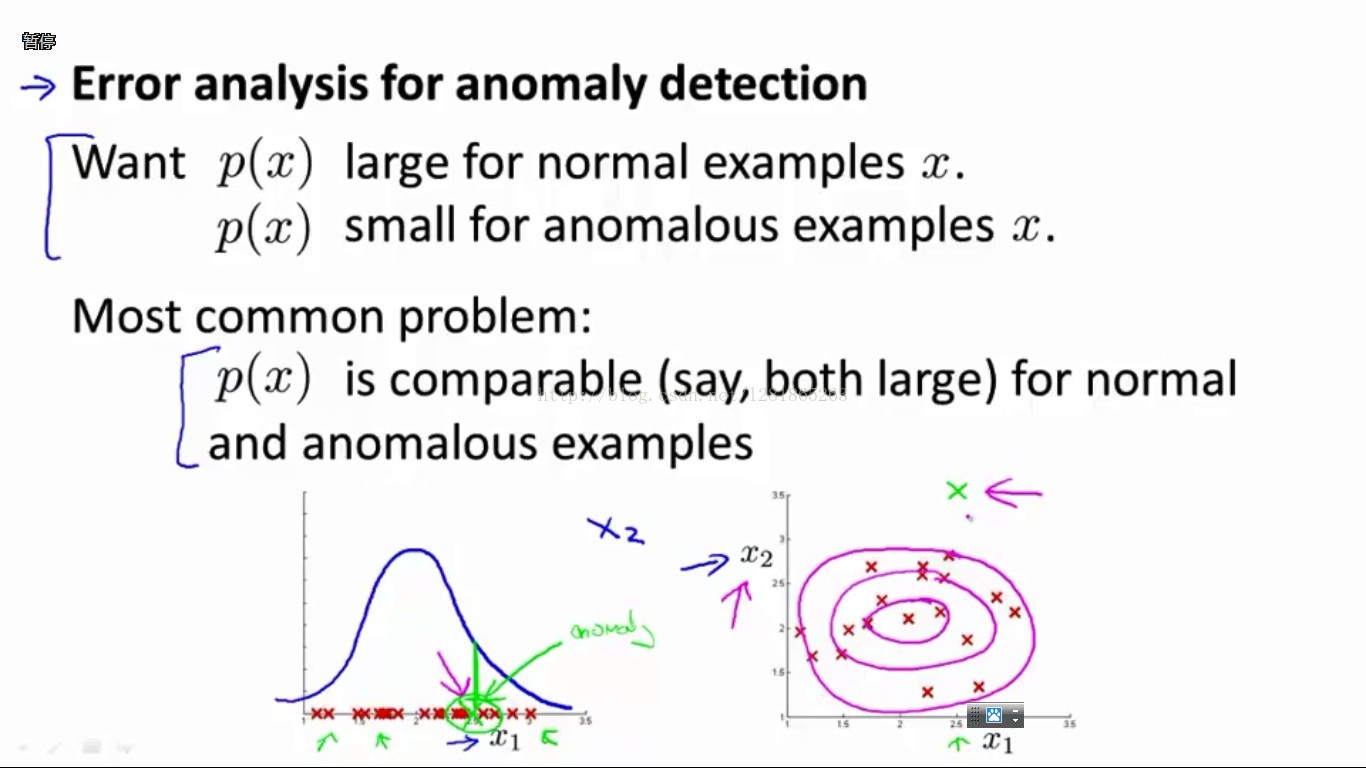
综上,选取特征时注意两点:
1、当特征数据不符合高斯分布时,通过统计数据的直方图分布,尝试用多种函数变换数据,使直方图分布特性符合高斯模型。
2、当前特征区分度不够时,可设计增加更有区分度的特征,以帮助模型更具辨别力。
(六)、异常检测 VS 监督学习
异常检测介绍到这里,可能会有人发出这样的疑问:同样都是需要正负样本做训练,然后对测试样本预测label,异常检测和监督学习的区别和联系是什么?什么样的问题适合用异常检测学得的模型解决?同时什么样的问题是应该用监督学习的?本节就来分析一下二者的特点和区别,知道了它们的区别,自然也就知道了两种方法分别适合什么样的问题场景了。
二者的特点和区别罗列如下:
1、数据量方面:
异常检测:前面提到过,异常检测的数据属skewed class,即正负样本的数量非常不均衡,负样本(normal)很多,正样本(anomaly)很少,大部分都是normal的数据。
监督学习:正负样本数量都很多,因为学习算法需要同时看到尽可能多的正负样本,才能使学到的模型更具辨别力。
2、数据分布方面:
异常检测:前面介绍过,异常检测的算法是建立在训练数据的每一维特征都是服从高斯分布的假设基础上的,而参与训练的数据只有负样本。相反地,正样本(anomaly)数据则是各种各样的,分布非常不均匀,不同的正样本之间相似性很小,也就是Ng说的many different "types" of anomalies。这点其实不难理解,通俗的道理讲是:正常的都一样,不正常的各有各的奇葩之处。
监督学习:正负样本的数据分别均匀分布,同类别数据具有较强的相似性和关联性。
3、模型训练方面:
异常检测:鉴于上述数据量和数据分布的特点,正样本(anomaly)对于异常检测算法不具有很好的参考性,因为它数量少,且风格迥异,不适合给算法拿去学习。负样本(normal)就不同了,它们符合高斯分布,容易学到特征的分布特性。而设计异常检测系统时用到了labeled的正样本(anomaly)是为什么呢?注意:它们并没有参与训练,没有参与高斯模型估计,只是用作在validation或test set上的evaluation。
监督学习:正负样本均参与了训练过程,理由同样是上面分析的数据的特点。
综上所述,可见,辨别用异常检测还是监督学习模型的关键在于,了解手头数据的特点,包括数据量、数据分布等。
(七)、多元高斯分布及其在异常检测问题上的应用
一、Motivation
为什么又有了多元高斯分布的概念呢?下面为了引入motivation,我们举个用多元高斯分布比用上述高斯分布模型更靠谱的栗子
如下图所示,当x1和x2存在左图中的线性关系时(这里可以先不用在意二者的线性关系,后续会详细讲解),绿色X样本的p(x1)和p(x2)都在阈值范围内,也就是都没有小到判为异常样本的程度(如右图),那么它们的乘积自然很有可能也不满足异常样本的判定条件。具体地,如左图,紫色的圆圈越往外,属于正常样本的概率就越小,圆心点的概率最大。这时我们看到绿色X测试样本和几个红色X训练样本距离圆心的距离是相近的,也就是拥有相似的概率值,那么绿色点就会被判为和红色一样是正常样本了。

二、多元高斯模型公式
与上面介绍的假设每一维数据都是相互独立的高斯分布模型不同的是,多元高斯分布整体考虑所有维度的数据。
同样有两个参数,均值和协方差矩阵,公式如下图所示,其中 |Sigma| 表示的是协方差矩阵Sigma的行列式。

注意,我们上面所说的x1和x2存在的线性关系,实际上就蕴含在协方差矩阵中,所以也就是说多元高斯分布与相互独立的一元高斯分布之间的差异就在于,前者考虑了不同数据分布之间的关系,而后者则认为它们是无关的、独立的。
接下来举例说明多元高斯分布模型与数据关系之间的联系:
(1)如下图,当协方差矩阵的对角线元素相等时,三维空间中的模型曲面在两个维度上展开范围也是相等的
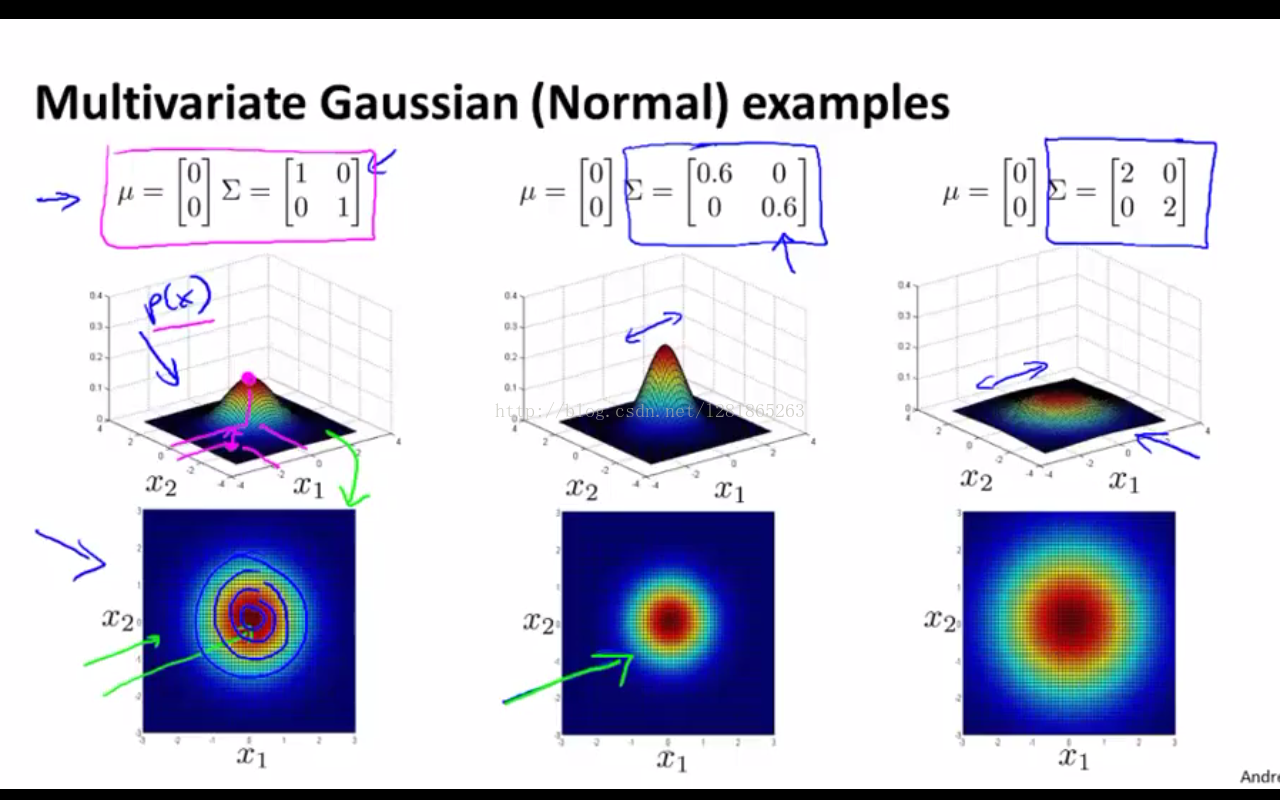
(2)如下图,当对角线元素不等时,曲面在两个维度上的展开范围大小有了区分。如右一的图,概率值沿x2方向比沿x1方向下降得快。

(3)下面几张图的变换也很重要,只是这里不做详细解释了。大家可通过观察协方差矩阵和均值向量的值,结合看相应的图形,来体会多元高斯模型与数据关系之间的联系。
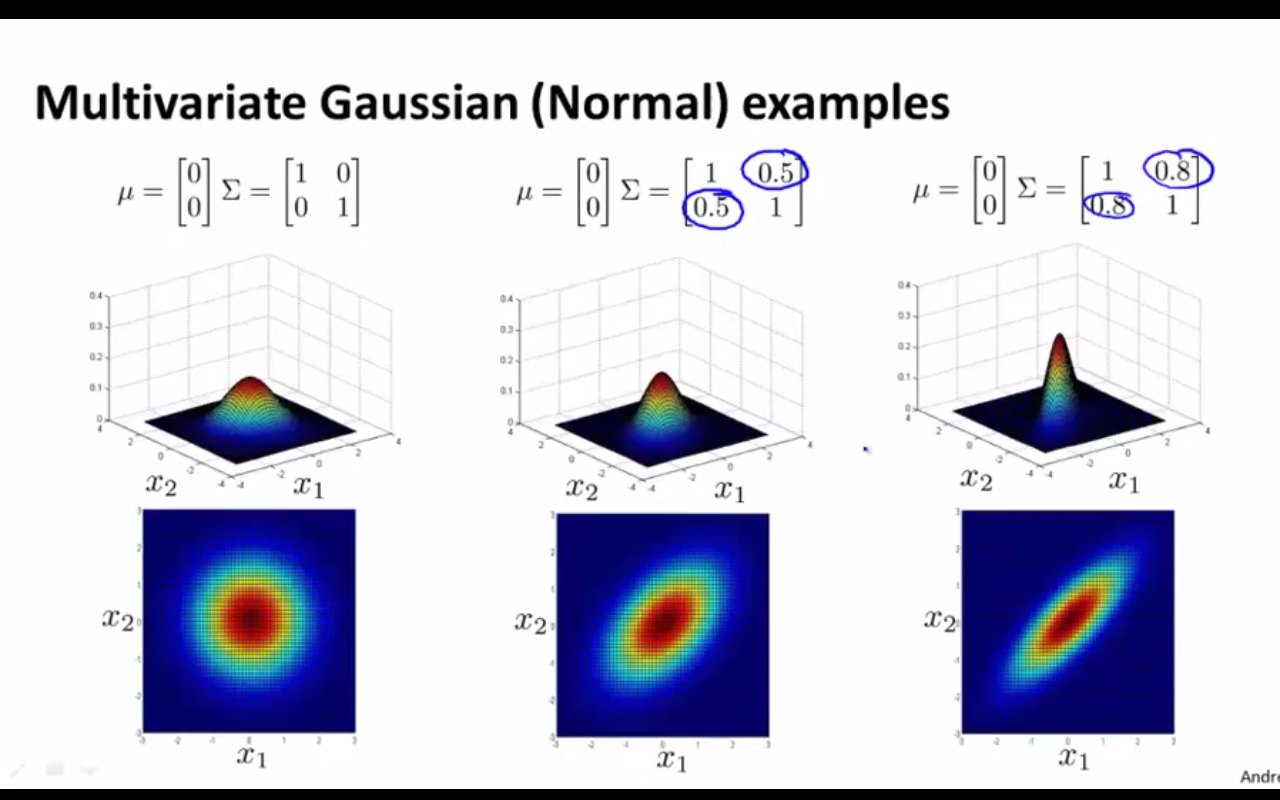
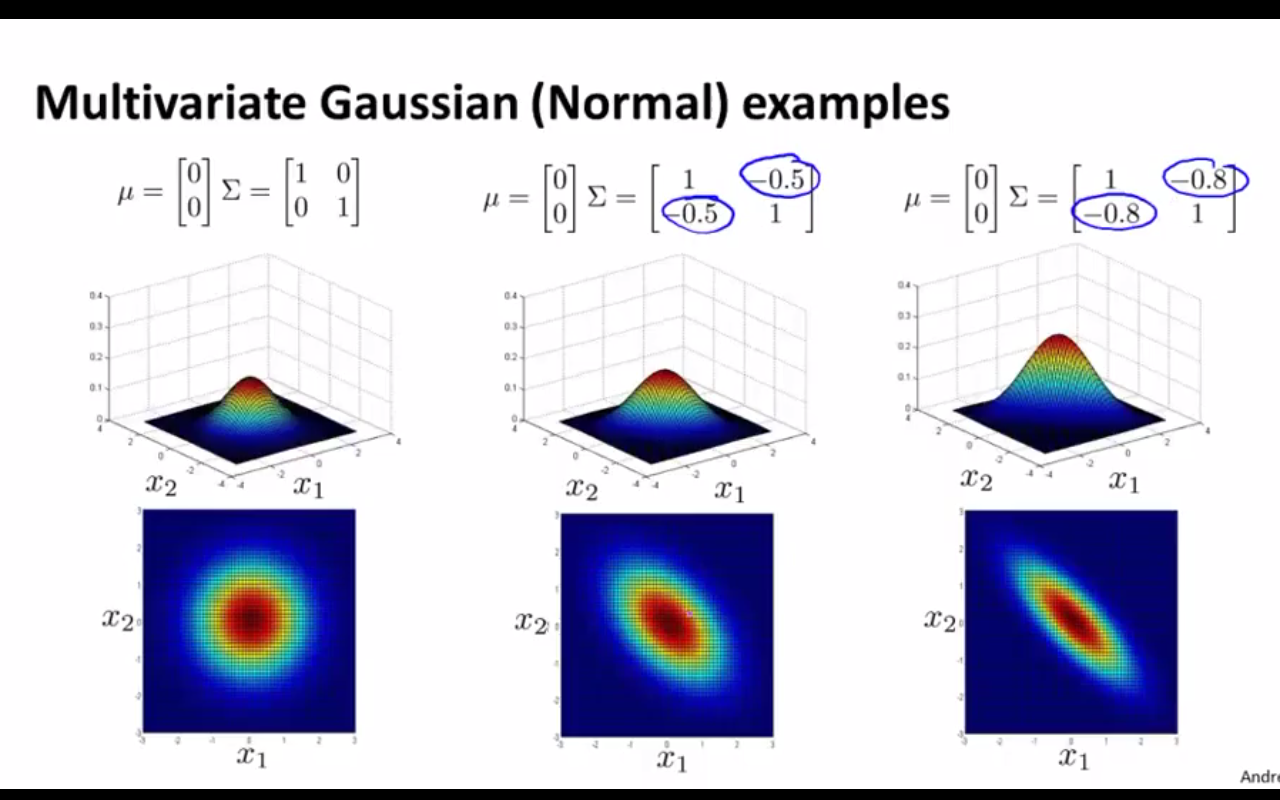
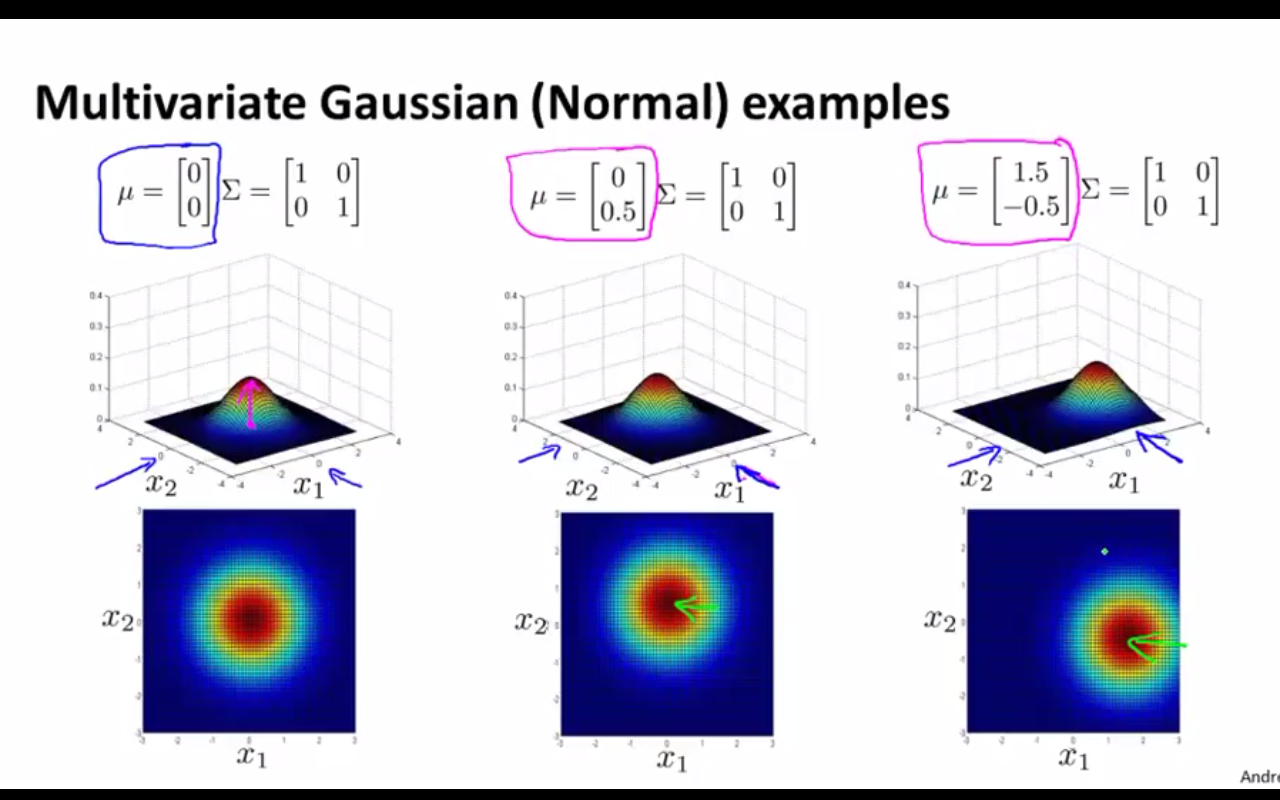
三、用多元高斯模型建模的异常检测算法
算法如下图所示:

观察上图的右图可见,当用多元高斯模型时,如果两个维度的数据存在某种线性关系,这种关系会很容易被捕捉到,并正确指导测试样本的判别。
四、多元高斯模型与多个独立的一元高斯模型之间的联系
不难发现,其实,后者是前者的特殊形式,其关系如下:
当且仅当协方差矩阵是一个对角阵时,且对角元素等于各个维度的方差,则此时的多元高斯模型就等价于多个独立的一元高斯模型。如下图:

也就是说,这种特殊情况下,各个维度的feature之间相互独立,不存在任何线性或非线性关系,从而三维曲面只在不同维度上有不同的展开宽度,而不会像上面的几个例子那样产生45°的倾斜。
知道了两者的联系以后,我们就要想了,那什么时候用多元高斯模型什么时候假设相互独立的一元高斯模型呢?总结二者的区别如下(前者指多元高斯模型,后者指一元高斯模型):
1、特征选择:
对于同样的一组已知数据,假设{x1,x2},x1和x2都不能很好地区分的话,如果选用后者的模型,正如我们在特征选取一节中介绍的那样,可能需要我们人工设计一个更具辨别力的feature(比如x1/x2);但如果选用前者模型的话,多元高斯模型会自动学习x1和x2的关系,就无需人工设计feature了
2、计算效率:
后者的计算效率更快一些,因为它不涉及到协方差矩阵求逆等一些复杂的矩阵运算。所以当样本维度n很大时,一般n=100,000或10,000时认为很大了,更多采用后者的模型。否则协方差矩阵将是n*n大小的,求逆运算会很慢很慢。
3、关于样本数量m和样本维度n:
综上,当m比较小时,更适合用后者模型,因为少量的样本不容易学到数据间的复杂关系;当m>>n(比如m=10n)且协方差矩阵可逆时,就采用前者多元高斯分布模型。
-------------------------------------------
个性签名:无论在哪里做什么,只要坚持服务、创新、创造价值,其它的东西自然都会来的。
如果觉得这篇文章对你有小小的帮助的话,记得在右下角点个“推荐”哦,博主在此感谢!



· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 按钮权限的设计及实现