
自然语言处理之文本分类
一、前言
该部分工作是研二期间总结的知识点,今天从有道云笔记上搬运过来。
二、深度学习框架-keras
人生苦短,我用keras。
官方keras例子:http://keras-cn.readthedocs.io/en/latest/getting_started/sequential_model/
三、基于深度学习的文本分类流程
1.首先将文本数据集中的单词用词嵌入矩阵中的索引表示,由于文本是由单词拼接出来的,所以最终得到一个由单词索引拼接起来的数字序列来表示该文本。
dataloader.py:数据预处理
def read_category(): """ Args: None Returns: categories: a list of label cat_to_id: a dict of label to id """ ##DBPedia # y1 = ['agent', 'device', 'event', 'place', 'species', 'sportsseason', 'topicalconcept', 'unitofwork', 'work'] # y2 = ['actor', 'amusementparkattraction', 'animal', 'artist', 'athlete', 'bodyofwater', 'boxer', 'britishroyalty', 'broadcaster', 'building', 'cartoon', 'celestialbody', 'cleric', 'clericaladministrativeregion', 'coach', 'comic', 'comicscharacter', 'company', 'database', 'educationalinstitution', 'engine', 'eukaryote', 'fictionalcharacter', 'floweringplant', 'footballleagueseason', 'genre', 'gridironfootballplayer', 'group', 'horse', 'infrastructure', 'legalcase', 'motorcyclerider', 'musicalartist', 'musicalwork', 'naturalevent', 'naturalplace', 'olympics', 'organisation', 'organisationmember', 'periodicalliterature', 'person', 'plant', 'politician', 'presenter', 'race', 'racetrack', 'racingdriver', 'routeoftransportation', 'satellite', 'scientist', 'settlement', 'societalevent', 'software', 'song', 'sportfacility', 'sportsevent', 'sportsleague', 'sportsmanager', 'sportsteam', 'sportsteamseason', 'station', 'stream', 'tournament', 'tower', 'venue', 'volleyballplayer', 'wintersportplayer', 'wrestler', 'writer', 'writtenwork'] # y3 = ['academicjournal', 'adultactor', 'airline', 'airport', 'album', 'amateurboxer', 'ambassador', 'americanfootballplayer', 'amphibian', 'animangacharacter', 'anime', 'arachnid', 'architect', 'artificialsatellite', 'artistdiscography', 'astronaut', 'australianfootballteam', 'australianrulesfootballplayer', 'automobileengine', 'badmintonplayer', 'band', 'bank', 'baronet', 'baseballleague', 'baseballplayer', 'baseballseason', 'basketballleague', 'basketballplayer', 'basketballteam', 'beachvolleyballplayer', 'beautyqueen', 'biologicaldatabase', 'bird', 'bodybuilder', 'brewery', 'bridge', 'broadcastnetwork', 'buscompany', 'businessperson', 'canadianfootballteam', 'canal', 'canoeist', 'cardinal', 'castle', 'cave', 'chef', 'chessplayer', 'christianbishop', 'classicalmusicartist', 'classicalmusiccomposition', 'collegecoach', 'comedian', 'comicscreator', 'comicstrip', 'congressman', 'conifer', 'convention', 'cricketer', 'cricketground', 'cricketteam', 'crustacean', 'cultivatedvariety', 'curler', 'cycad', 'cyclingrace', 'cyclingteam', 'cyclist', 'dam', 'dartsplayer', 'diocese', 'earthquake', 'economist', 'election', 'engineer', 'entomologist', 'eurovisionsongcontestentry', 'fashiondesigner', 'fern', 'figureskater', 'filmfestival', 'fish', 'footballmatch', 'formulaoneracer', 'fungus', 'gaelicgamesplayer', 'galaxy', 'glacier', 'golfcourse', 'golfplayer', 'golftournament', 'governor', 'grandprix', 'grape', 'greenalga', 'gymnast', 'handballplayer', 'handballteam', 'historian', 'historicbuilding', 'hockeyteam', 'hollywoodcartoon', 'horserace', 'horserider', 'horsetrainer', 'hospital', 'hotel', 'icehockeyleague', 'icehockeyplayer', 'insect', 'jockey', 'journalist', 'judge', 'lacrosseplayer', 'lake', 'lawfirm', 'legislature', 'library', 'lighthouse', 'magazine', 'manga', 'martialartist', 'mayor', 'medician', 'memberofparliament', 'militaryconflict', 'militaryperson', 'militaryunit', 'mixedmartialartsevent', 'model', 'mollusca', 'monarch', 'moss', 'mountain', 'mountainpass', 'mountainrange', 'museum', 'musical', 'musicfestival', 'musicgenre', 'mythologicalfigure', 'nascardriver', 'nationalfootballleagueseason', 'ncaateamseason', 'netballplayer', 'newspaper', 'noble', 'officeholder', 'olympicevent', 'painter', 'philosopher', 'photographer', 'planet', 'play', 'playboyplaymate', 'poem', 'poet', 'pokerplayer', 'politicalparty', 'pope', 'president', 'primeminister', 'prison', 'publictransitsystem', 'publisher', 'racecourse', 'racehorse', 'radiohost', 'radiostation', 'railwayline', 'railwaystation', 'recordlabel', 'religious', 'reptile', 'restaurant', 'river', 'road', 'roadtunnel', 'rollercoaster', 'rower', 'rugbyclub', 'rugbyleague', 'rugbyplayer', 'saint', 'school', 'screenwriter', 'senator', 'shoppingmall', 'single', 'skater', 'skier', 'soapcharacter', 'soccerclubseason', 'soccerleague', 'soccermanager', 'soccerplayer', 'soccertournament', 'solareclipse', 'speedwayrider', 'sportsteammember', 'squashplayer', 'stadium', 'sumowrestler', 'supremecourtoftheunitedstatescase', 'swimmer', 'tabletennisplayer', 'televisionstation', 'tennisplayer', 'tennistournament', 'theatre', 'town', 'tradeunion', 'university', 'videogame', 'village', 'voiceactor', 'volcano', 'winery', 'womenstennisassociationtournament', 'wrestlingevent'] # y1_to_id=dict(zip(y1,range(len(y1)))) # y2_to_id = dict(zip(y2, range(len(y2)))) # y3_to_id = dict(zip(y3, range(len(y3)))) ##ws y1 = ['business', 'communications', 'computer', 'data management', 'digital media', 'other services', 'recreational activities', 'social undertakings', 'traffic'] # y1 = ['communications', 'data processing', 'digital media', 'economic', 'information technology', 'logistics', 'office', 'organization', 'other services', 'recreational activities', 'social undertakings'] y2 = ['advertising', 'analytics', 'application development', 'backend', 'banking', 'bitcoin', 'chat', 'cloud', 'data', 'database', 'domains', 'ecommerce', 'education', 'email', 'enterprise', 'entertainment', 'events', 'file sharing', 'financial', 'games', 'government', 'images', 'internet of things', 'mapping', 'marketing', 'media', 'medical', 'messaging', 'music', 'news services', 'other', 'payments', 'photos', 'project management', 'real estate', 'reference', 'science', 'search', 'security', 'shipping', 'social', 'sports', 'stocks', 'storage', 'telephony', 'tools', 'transportation', 'travel', 'video', 'weather'] y1_to_id=dict(zip(y1,range(len(y1)))) y2_to_id = dict(zip(y2, range(len(y2)))) return y1,y1_to_id,y2,y2_to_id def read_files(filename): contents, labels1, labels2 = [], [], [] i = 0 with codecs.open(filename, 'r', encoding='utf-8') as f: for line in f: try: content = line.split(' ') stopWords = stopwordslist( r'D:\赵鲸朋\pycharmModel0905\pycharmModel0905\PycharmProjects\Wos-Metadata2txt\output\stopwordds') # print(stopWords) ###################contents############################ # wordsFiltered = [] # for w in content: # if w not in stopWords and not isSymbol(w) and not hasNumbers(w) and len(w) >= 2: # wordsFiltered.append(w.rstrip('\n').rstrip('\r')) # contents.append(wordsFiltered) #####################label_y1 y2################################### wordsFiltered = [] for w in content: if len(w)>=2: wordsFiltered.append(w.rstrip('\n').rstrip('\r')) contents.append(wordsFiltered) ####################################################### i=i+1 except: pass print(len(contents)) return contents # filename = r"D:\赵鲸朋\pycharmModel0905\pycharmModel0905\PycharmProjects\Wos-Metadata2txt\data\wos\wos_clear_content.txt" # cont = read_files(filename) # # print(y1[:5]) # # # print(y2[:5]) # print(cont[:5]) ##20200415注释 # y1_file = r"D:\赵鲸朋\pycharmModel0905\pycharmModel0905\PycharmProjects\Wos-Metadata2txt\data\wos\wos_clear_y1.txt" # y1 = read_files(y1_file) # print(y1)def process_file(cont_file,y1_file,y2_file, word_to_id,y1_to_id,y2_to_id, max_length=300,y1_length = 2,y2_length = 2): """ Args: filename:train_filename or test_filename or val_filename word_to_id:get from def read_vocab() cat_to_id:get from def read_category() max_length:allow max length of sentence Returns: x_pad: sequence data from preprocessing sentence y_pad: sequence data from preprocessing label """ contents=read_files(cont_file) y1 = read_files(y1_file) y2 = read_files(y2_file) # y3 = read_files(y3_file) data_id,y1_id,y2_id,y3_id=[],[],[],[] y1_id_pad,y2_id_pad,y3_id_pad = [],[],[] label_y1 = [] label_y2 = [] label_y3 = [] for i in range(len(contents)): data_id.append([word_to_id[x] for x in contents[i] if x in word_to_id]) y1_id_pad.append([word_to_id[x] for x in y1[i] if x in word_to_id]) y2_id_pad.append([word_to_id[x] for x in y2[i] if x in word_to_id]) # y3_id_pad.append([word_to_id[x] for x in y3[i] if x in word_to_id]) ##############y[i]=['computer','science']转化为y[i]=['computer science']################################# str = "" for label in y1[i]: str = str+ label + " " label_y1.append(str.rstrip(' ')) # label_id.append(label_idd) str2 = "" for label in y2[i]: str2 = str2 + label + " " label_y2.append(str2.rstrip(' ')) # str3 = "" # for label in y3[i]: # str3 = str3 + label + " " # label_y3.append(str3.rstrip(' ')) y1_id.append(y1_to_id[label_y1[i]]) y2_id.append(y2_to_id[label_y2[i]]) # y3_id.append(y3_to_id[label_y3[i]]) ############################################### # y1_id.append(y1_to_id[y1[i]]) # y2_id.append(y2_to_id[y2[i]]) cont_pad=kr.preprocessing.sequence.pad_sequences(data_id,max_length,padding='post', truncating='post') y1_pad = kr.preprocessing.sequence.pad_sequences(y1_id_pad, y1_length, padding='post', truncating='post') y2_pad = kr.preprocessing.sequence.pad_sequences(y2_id_pad, y2_length, padding='post', truncating='post') # y3_pad = kr.preprocessing.sequence.pad_sequences(y3_id_pad, y3_length, padding='post', truncating='post') ################################## y1_index = kr.utils.to_categorical(y1_id) y2_index = kr.utils.to_categorical(y2_id) # y3_index = kr.utils.to_categorical(y3_id) ##################################### return cont_pad,y1_index,y2_index,y1_pad,y2_pad
datasequence.py:数据的输入输出在这里操作,然后调用dataloader.py
##将文本转变为向量 if __name__ == '__main__': start_time = time.time() # config = TextConfig() ############################################################### pretrained_w2v, word_to_id, _ = pl.load( open(r'D:\赵鲸朋\pycharmModel0905\pycharmModel0905\PycharmProjects\Wos-Metadata2txt\data\wos\emb_matrix_glove_300', 'rb')) cont_file = r"D:\赵鲸朋\pycharmModel0905\pycharmModel0905\PycharmProjects\Wos-Metadata2txt - webservice\data\WS\output0145\ws_clear_content.txt" y1_file = r"D:\赵鲸朋\pycharmModel0905\pycharmModel0905\PycharmProjects\Wos-Metadata2txt - webservice\data\WS\output0145\ws_clear_y1.txt" y2_file = r"D:\赵鲸朋\pycharmModel0905\pycharmModel0905\PycharmProjects\Wos-Metadata2txt - webservice\data\WS\output0145\ws_clear_y2.txt" # y3_file = r"D:\赵鲸朋\pycharmModel0905\pycharmModel0905\PycharmProjects\Wos-Metadata2txt\data\DBP\output2\DBP_clear_y3.txt" ######################################################################### y1, y1_to_id, y2, y2_to_id = read_category() # y1, y1_to_id, y2, y2_to_id, y3, y3_to_id= read_category() #################################################################### seq_length = 100 cont_pad,y1_index,y2_index,y1_pad,y2_pad= process_file(cont_file,y1_file,y2_file, word_to_id, y1_to_id, y2_to_id, seq_length) # x_val, y_val = process_file(file, word_to_id, cat_to_id, config.seq_length) print(cont_pad[:3]) print(y1_index[:3]) print(y2_index[:3]) print(y1_pad[:3]) print(y2_pad[:3]) with open('D:\赵鲸朋\pycharmModel0905\pycharmModel0905\PycharmProjects\Wos-Metadata2txt - webservice\data\WS\output0145\ws_txt_vector300dim_y1y2_2len_100len_zjp0145', 'wb') as f: pl.dump((cont_pad,y1_index,y2_index,y1_pad,y2_pad), f) # trans vector file to numpy file # if not os.path.exists(config.vector_word_npz): # export_word2vec_vectors(word_to_id, config.vector_word_filename, config.vector_word_npz) # with open('./train_val_txt_vector', 'wb') as f: # pl.dump((x_train, x_val, y_train, y_val ), f) print("Time cost: %.3f seconds...\n" % (time.time() - start_time))
2.然后将该索引序列喂入深度学习模型即可。索引在下面这段代码会直接映射为词嵌入矩阵中的词向量,然后放入深度学习模型进行拟合。
embedding_word_raw = Embedding(self.max_features, self.embedding_dims, weights=[self.word_embedding_matrix],input_length=self.maxlen,name='emb',trainable=False)(input)
Main.py:模型的输入输出在下面这里操作
maxlen = 100 max_features = 89098 batch_size = 64 embedding_dims = 300 epochs = 100 #######################调用GPU################# """GPU设置为按需增长""" import os import tensorflow as tf import keras.backend.tensorflow_backend as KTF # 指定第一块GPU可用 os.environ["CUDA_VISIBLE_DEVICES"] = "0" config = tf.ConfigProto() config.gpu_options.allow_growth=True #不全部占满显存, 按需分配 # config.gpu_options.per_process_gpu_memory_fraction = 0.6 # 每个GPU现存上届控制在60%以内 sess = tf.Session(config=config) KTF.set_session(sess) ############################################################################################################################ pretrained_w2v, _, _ = pl.load(open(r'D:\01zjp\E1106论文实验\Web服务分类\ServicesRecommend\data\emb_matrix_glove_300', 'rb')) ############################################################################################################################# print('Loading data...') x,y1,y2,y1_pad,y2_pad =pl.load(open(r'D:\01zjp\E1106论文实验\Web服务分类\ServicesRecommend\data\ws_txt_vector300dim_y1y2_2len_100len_zjp0145','rb')) x_train,x_test,y2_train,y2_test = train_test_split( x, y2, test_size=0.2, random_state=42) x_train,x_test,y1_train,y1_test = train_test_split( x, y1, test_size=0.2, random_state=42) ########################################################################################################################## print('Build model...') model = TextONLSTM(maxlen, max_features, embedding_dims, pretrained_w2v).get_model() ######################设置top5精度###################################################################################### def acc_top5(y_true, y_pred): return keras.metrics.top_k_categorical_accuracy(y_true, y_pred, k=5) ########################################################################################################################## model.compile('adam', 'categorical_crossentropy', metrics=['accuracy',acc_top5]) model.summary() print('Train...') fileweights = r"D:\01zjp\E1106论文实验\Web服务分类\ServicesRecommend\data\weights\Ay1pad_y2_best_weights.h5" checkpoint = ModelCheckpoint(fileweights, monitor='val_acc', verbose=1, save_best_only=True, mode='auto') early_stopping = EarlyStopping(monitor='val_acc', patience=5, mode='max') # 当评价指标不在提升时,减少学习率 from keras.callbacks import ReduceLROnPlateau reduce_lr = ReduceLROnPlateau(monitor='val_loss',factor=0.1, patience=3, mode='auto') ###########训练层次标签之间权重########################################################################################## model.fit(x_train, y1_train, # validation_split=0.1, batch_size=batch_size, epochs=epochs, callbacks=[early_stopping, checkpoint,reduce_lr], validation_data=(x_test, y1_test), shuffle= True)
Model.py:深度学校模型的结构在这里设计
class TextONLSTM(object): def __init__(self, maxlen, max_features, embedding_dims, word_embedding_matrix, class_num=9, last_activation='softmax'): self.maxlen = maxlen self.max_features = max_features self.embedding_dims = embedding_dims self.word_embedding_matrix = word_embedding_matrix self.class_num = class_num self.last_activation = last_activation def get_model(self): input = Input((self.maxlen,)) ############################################################### ################################################################# embedding_word_raw = Embedding(self.max_features, self.embedding_dims, weights=[self.word_embedding_matrix],input_length=self.maxlen,name='emb',trainable=False)(input) # embedding_word_raw = GlobalMaxPooling1D()(embedding_word_raw) embedding_word = Dropout(0.25,name='dropout1')(embedding_word_raw) ################################################################################## onlstm = ONLSTM(1024, 2, return_sequences=True, dropconnect=0.25, name="onlstm_1")(embedding_word) y0 = GlobalMaxPooling1D(name='pool1')(onlstm) ############################################################################## documentOut = Dense(512, activation="tanh", name="documentOut_1")(y0) # x_word = BatchNormalization()(documentOut) x_word = Dropout(0.5,name='Dropout2')(documentOut) output = Dense(self.class_num, activation=self.last_activation,name="output_1")(x_word) model = Model(inputs=input, outputs=output) return model
四、多标签分类和单标签分类
损失函数和最后一层激活函数要一一对应
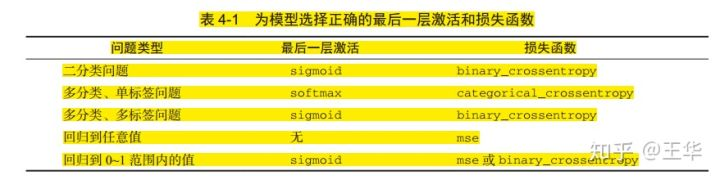
五、中文文本分类实例
1.数据集格式

2.先对其分词,然后根据分词生成一个词典
#labels = ['教育','体育','社会',……] #contents = [['我们','北京','上大学','研究生'],['今天','巴萨','战胜','火箭'],['住房','公积金','上涨']……]

3.根据单词在词典中的索引,将句子序列化(用单词索引集合表示)
def process_file(filename,word_to_id,cat_to_id,max_length=600): """ Args: filename:train_filename or test_filename or val_filename word_to_id:get from def read_vocab() cat_to_id:get from def read_category() max_length:allow max length of sentence Returns: x_pad: sequence data from preprocessing sentence y_pad: sequence data from preprocessing label """ labels,contents=read_file(filename) data_id,label_id=[],[] for i in range(len(contents)): data_id.append([word_to_id[x] for x in contents[i] if x in word_to_id]) label_id.append(cat_to_id[labels[i]]) x_pad=kr.preprocessing.sequence.pad_sequences(data_id,max_length,padding='post', truncating='post') y_pad=kr.utils.to_categorical(label_id)#y_pad单标签的处理,与多标签不同 return x_pad,y_pad
5.根据数据集训练词向量(word2vec)(不依赖于前四步,独立出来)
re_han= re.compile(u"([\u4E00-\u9FD5a-zA-Z]+)") # the method of cutting text by punctuation
class Get_Sentences(object):
'''
Args:
filenames: a list of train_filename,test_filename,val_filename
Yield:
word:a list of word cut by jieba
'''
def __init__(self,filenames):
self.filenames= filenames
def __iter__(self):
for filename in self.filenames:
with codecs.open(filename, 'r', encoding='utf-8') as f:
for _,line in enumerate(f):
try:
line=line.strip()
line=line.split('\t')
assert len(line)==2
blocks=re_han.split(line[1])
word=[]
for blk in blocks:
if re_han.match(blk):
word.extend(jieba.lcut(blk))
yield word
except:
pass
def train_word2vec(filenames):
'''
use word2vec train word vector
argv:
filenames: a list of train_filename,test_filename,val_filename
return:
save word vector to config.vector_word_filename
'''
t1 = time.time()
sentences = Get_Sentences(filenames)
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
model = word2vec.Word2Vec(sentences, size=100, window=5, min_count=1, workers=6)
model.wv.save_word2vec_format(config.vector_word_filename, binary=False)
print('-------------------------------------------')
print("Training word2vec model cost %.3f seconds...\n" % (time.time() - t1))
if __name__ == '__main__':
config=TextConfig()
filenames=[config.train_filename,config.test_filename,config.val_filename]
train_word2vec(filenames)
6.把文本序列,以及词嵌入矩阵放入神经网络进行训练
六、文本分类代码论文科研神站
该网站会对文本分类的各种深度学习模型的性能进行一个排行
论文阅读笔记:
1.《CNN for Sentence Classification》(textcnn)阅读笔记 https://zhuanlan.zhihu.com/p/59988106 2.Recurrent Convolutional Neural Networks for Text Classification https://zhuanlan.zhihu.com/p/21253220 3.HAN 模型阅读笔记 https://zhuanlan.zhihu.com/p/26892711 4.Universal Language Model Fine-tuning for Text Classification(2018年ACL) https://zhuanlan.zhihu.com/p/47344283 5.基于Joint embedding of words and labels的文本分类(2018年ACL) https://zhuanlan.zhihu.com/p/54734708 6.关于 Adversarial Training 在 NLP 领域的一些思考 7.《基于语义单元的多标签文本分类》阅读笔记 8.图嵌入(Graph embedding)综述 《Graph Embedding Techniques, Applications, and Performance: A Survey》 https://zhuanlan.zhihu.com/p/62629465 9.【论文笔记】Structural Deep Network Embedding https://blog.csdn.net/jianbinzheng/article/details/83545754 10.【Graph Embedding】DeepWalk\LINE\Node2Vec\SDNE\Struc2Vec https://zhuanlan.zhihu.com/p/56733145 11.RMDL:随机多模型深度学习分类方法 https://blog.csdn.net/oYeZhou/article/details/89096099 https://zhuanlan.zhihu.com/p/68748697
