
mysql redo log 和 undo log
一、事务的实现
事务的隔离性由锁实现,持久性、原子性由数据库的redo 和 undo来完成。
二、 redo与undo
1.redo log -- 保证事务的持久性
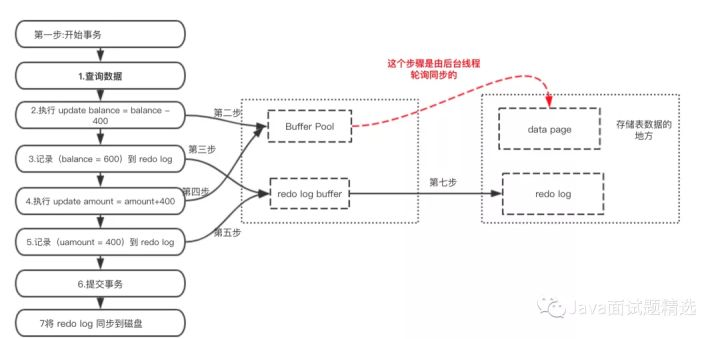
mysql 为了提升性能不会把每次的修改都实时同步到磁盘,而是会先存到Buffer Pool(缓冲池)里头,把这个当作缓存来用。然后使用后台线程去做缓冲池和磁盘之间的同步。
那么问题来了,如果还没来的同步的时候宕机或断电了怎么办?还没来得及执行上面图中红色的操作。这样会导致丢失部分已提交事务的修改信息!
所以引入了redo log,redo log来记录已成功提交事务的修改信息,并且会把redo log持久化到磁盘,系统重启之后在读取redo log恢复最新数据。
2.undo log--保证事务的原子性
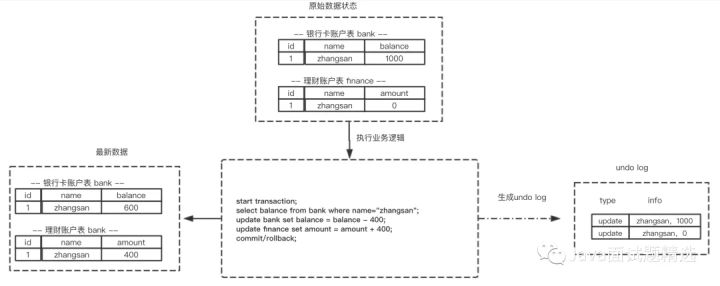
Undo log 主要用于记录数据被修改之前的日志,在表信息修改之前先会把数据拷贝到undo log 里,当事务进行回滚时可以通过undo log 里的日志进行数据还原。
3.事务的原子性和持久性
事务原子性的保障
根据上面redo log和undo log在事务中生成的过程我们可以知道,对数据进行一系列的修改之前都会把其历史数据保存到undo log,然后把更新的数据记录到redo log日志里。 当我们的事务进行commit后可以通过redo log日志来保证只要commit后的事务数据都会全部同步修改到数据库。当事务就行rollback时,我们可以通过undo log记录的历史版本来对整个事务关联的修改的数据进行回滚。
事务持久性的保障
持久性是在系统无论发生异常、崩溃的时候依然能保证我们的数据能正常的持久化到数据库中,在系统出现异常或崩溃的时候,我们可以通过对redo log进行回放,对于redo log 里已经commit的事务执行数据重做,对于redo log里没有commit的事务,我们则可以通过undo log来对事务涉及到的数据进行数据回滚从而最终保证事务数据的持久性。
4.redo log 、undo log 的生成过程
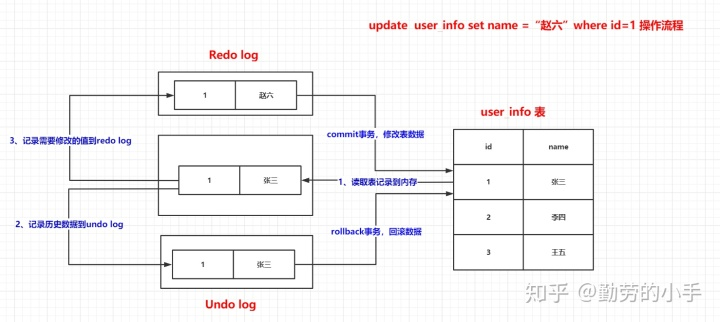
1、修改数据前首先把需要修改的数据从数据表中读取到内存。
2、把需原数据作为历史版本记录到undo log里。
3、把需要变更的数据记录到redo log里。
4、commit或rollback事务,修改表数据。
5. redo log 何时会被刷新到磁盘文件
(1)如果写入redo log buffer的日志已经占据了redo log buffer总容量的一半了,也就是超过了8MB的redo log在缓冲里了,此时就会把他们刷入到磁盘文件里去
(2)一个事务提交的时候,必须把他的那些redo log所在的redo log block都刷入到磁盘文件里去,只有这样,当事务提交之后,他修改的数据绝对不会丢失,因为redo log里有重做日志,随时可以恢复事务做的修改
(PS:这个redo log哪怕事务提交的时候写入磁盘文件,也是先进入os cache的,进入os的文件缓冲区里,所以是否提交事务就强行把redo log刷入物理磁盘文件中,这个需要设置对应的参数
(3)后台线程定时刷新,有一个后台线程每隔1秒就会把redo log buffer里的redo log block刷到磁盘文件里去)
(4)MySQL关闭的时候,redo log block都会刷入到磁盘里去
Redo log的用途
为了保证数据能正确的持久化,在系统出现异常的时候通常会对redo log进行回放,把已经commit的事务进行数据重做。
Undo log 的用途
(1)保证事务进行rollback时的原子性,当事务进行回滚或者系统异常需要对数据进行回滚的的时候可以用undo log的日志进行数据重做。
(2)用于MVCC快照读的数据,在MVCC多版本控制中,通过读取undo log的历史版本数据可以实现不同事务版本号都拥有自己独立的快照数据版本。
undo log的原理
undo log是把所有没有COMMIT的事务回滚到事务开始前的状态,系统崩溃时,可能有些事务还没有COMMIT,在系统恢复时,这些没有COMMIT的事务就需要借助undo log来进行回滚。
redo log 的原理
redo log是指在回放日志的时候把已经COMMIT的事务重做一遍,对于没有commit的事务按照abort处理,不进行任何操作。
三、拓展
InnoDB引擎中,磁盘上存储的数据页和内存缓冲池中的页是不同步的,对于内存缓冲池中页的修改,先是写入重做日志文件,然后再写入磁盘,因此是一种异步的方式。
在innoDB的存储引擎中,事务日志通过重做(redo)日志和innoDB存储引擎的日志缓冲(InnoDB Log Buffer)实现。事务开启时,事务中的操作,都会先写入存储引擎的日志缓冲中,在事务提交之前,这些缓冲的日志都需要提前刷新到磁盘上持久化,这就是DBA们口中常说的“日志先行”(Write-Ahead Logging)。
当事务提交之后,在Buffer Pool中映射的数据文件才会慢慢刷新到磁盘。此时如果数据库崩溃或者宕机,那么当系统重启进行恢复时,就可以根据redo log中记录的日志,把数据库恢复到崩溃前的一个状态。未完成的事务,可以继续提交,也可以选择回滚,这基于恢复的策略而定。
-
在系统启动的时候,就已经为redo log分配了一块连续的存储空间,以顺序追加的方式记录Redo Log,通过顺序IO来改善性能。所有的事务共享redo log的存储空间,它们的Redo Log按语句的执行顺序,依次交替的记录在一起。如下一个简单示例:
记录1:<trx1, insert...>
记录2:<trx2, delete...>
记录3:<trx3, update...>
记录4:<trx1, update...>
记录5:<trx3, insert...>
-
undo log
undo log主要为事务的回滚服务。在事务执行的过程中,除了记录redo log,还会记录一定量的undo log。undo log记录了数据在每个操作前的状态,如果事务执行过程中需要回滚,就可以根据undo log进行回滚操作。单个事务的回滚,只会回滚当前事务做的操作,并不会影响到其他的事务做的操作。
以下是undo+redo事务的简化过程:
假设有2个数值,分别为A和B,值为1,2
1. start transaction;
2. 记录 A=1 到undo log;
3. update A = 3;
4. 记录 A=3 到redo log;
5. 记录 B=2 到undo log;
6. update B = 4;
7. 记录B = 4 到redo log;
8. 将redo log刷新到磁盘
9. commit
在1-8的任意一步系统宕机,事务未提交,该事务就不会对磁盘上的数据做任何影响。如果在8-9之间宕机,恢复之后可以选择回滚,也可以选择继续完成事务提交,因为此时redo log已经持久化。若在9之后系统宕机,内存映射中变更的数据还来不及刷回磁盘,那么系统恢复之后,可以根据redo log把数据刷回磁盘。

