
基于Mapreduce的并行Dijkstra算法执行过程分析
1.图文件
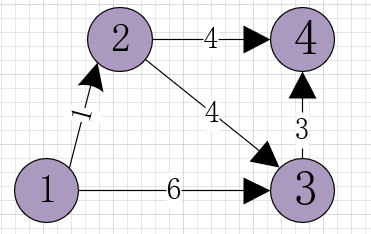
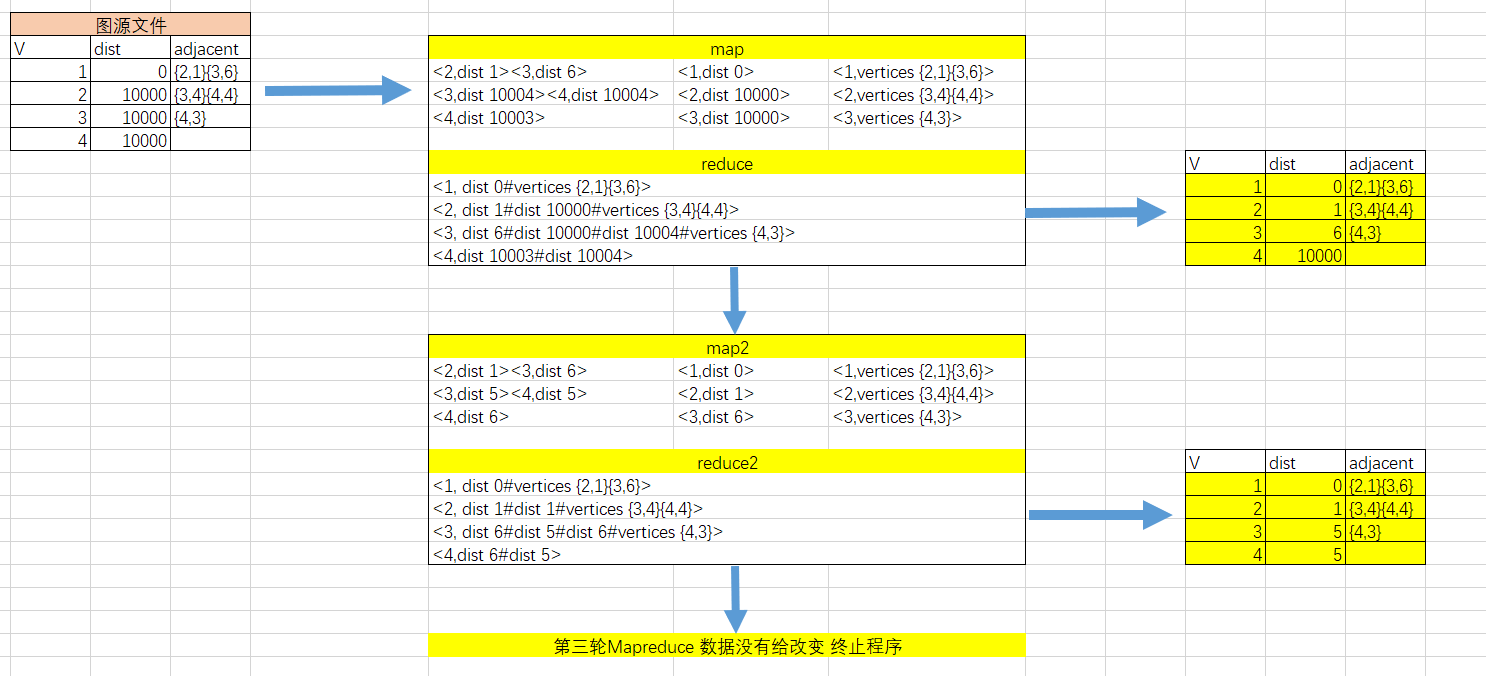
2.执行流程
源代码:https://github.com/masterzjp/dijkstraMapreduce
3.mapper


package com.hadoop.dijkstra; import java.io.IOException; import java.util.Arrays; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapred.MapReduceBase; import org.apache.hadoop.mapred.Mapper; import org.apache.hadoop.mapred.OutputCollector; import org.apache.hadoop.mapred.Reporter; public class DijkstraMapper extends MapReduceBase implements Mapper<LongWritable, Text, LongWritable, Text> { private static final int MINIMUM_NODE_TOKENS = 3; public void map(LongWritable key, Text value, OutputCollector<LongWritable, Text> output, Reporter reporter) throws IOException { String[] tokens = value.toString().split("\t"); System.out.println("tokens input map " + Arrays.toString(tokens)); if(tokens.length >= MINIMUM_NODE_TOKENS){ String[] adjacentNodeDetails = tokens[2].split(" "); String[][] neighborsNode = new String[adjacentNodeDetails.length][2]; for (int index = 0; index < adjacentNodeDetails.length; index++) { neighborsNode[index] = adjacentNodeDetails[index].substring(1, adjacentNodeDetails[index].length() - 1).split(","); } int sourceNodeWeight = Integer.parseInt(tokens[1]); //recorriendo los nodos vecinos for (int index = 0; index < adjacentNodeDetails.length; index++) { int weight = sourceNodeWeight + Integer.parseInt(neighborsNode[index][1]); //Nueva distancia desde el origen hacia los nodos vecinos output.collect(new LongWritable(Integer.parseInt(neighborsNode[index][0])), new Text("dist"+ "\t" + weight)); System.out.println("vecinos map key: " + neighborsNode[index][0]); System.out.println("vecinos map value: " + new Text("dist " + weight)); } } output.collect(new LongWritable(Integer.parseInt(tokens[0])), new Text("dist"+ "\t" + tokens[1])); if(tokens.length >= MINIMUM_NODE_TOKENS){ output.collect(new LongWritable(Integer.parseInt(tokens[0])), new Text("Vertices"+ "\t" + tokens[2])); System.out.println("map value vertices: " + new Text("Vertices "+ tokens[2])); } //print salida System.out.println("map value dist: " + new Text("dist "+ tokens[1]) ); } }
4.reducer
package com.hadoop.dijkstra; import java.io.IOException; import java.util.Arrays; import java.util.Iterator; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapred.MapReduceBase; import org.apache.hadoop.mapred.OutputCollector; import org.apache.hadoop.mapred.Reducer; import org.apache.hadoop.mapred.Reporter; public class DijkstraReducer extends MapReduceBase implements Reducer<LongWritable, Text, LongWritable, Text> { public void reduce(LongWritable key, Iterator<Text> values, OutputCollector<LongWritable, Text> output, Reporter reporter) throws IOException { int min = Integer.MAX_VALUE; String vertices = ""; //print valores de entrada System.out.println("input reduce key " + key); while (values.hasNext()) { String[] tokens = values.next().toString().split("\t"); System.out.println("tokens reduce " + Arrays.toString(tokens)); if(tokens[0].equals("Vertices")){ vertices = tokens[1]; } else if(tokens[0].equals("dist")){ min = Math.min(Integer.parseInt(tokens[1]), min); } } output.collect(key, new Text(min + "\t" + vertices)); System.out.println("vertices reduce " + vertices); } }

