

对LSTM应用于图像的初步理解
循环神经网络用来处理序列化数据,因此要使用循环神经网络来处理CV领域的问题,首先要考虑将处理对象转换为序列形式的数据。
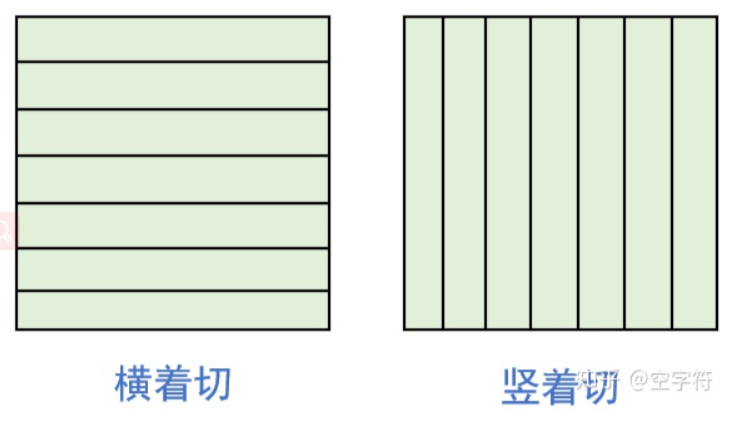
以MNIST数据集为例,其大小为28*28。将该数据序列化。如果将每一个像素点视作一个单元,则每幅图像可以用一个28*28长度的序列来表示,但这种表示过于粗暴,而且缺少一定的语义信息,处理起来也不容易,因此考虑扩大单元大小。可以考虑按照横向或者纵向进行分片,然后按照一定顺序链接起来形成序列数据。效果如下图所示。不同的切分方式会得到不同的结果,其表示也不同。序列化的数据本来是NLP领域的自然拥有的性质,比如一句话,一首诗等等。要实现NLP到CV的映射,就需要确定映射关系。
这里以RNNs的典型代表,标准形式的LSTM为例,叙述对数据集MNIST进行处理的过程。
在LSTM当中,需要确定time_step(时间步),时间步表征的是时刻长度。在NLP中指定是 一个句子的长度,这个句子的长度就是循环神经网络循环的次数,显然time_step过大,循环神经网络就会出现权重衰退或者权重爆炸等问题。关于time_step的理解:假设我们要训练LSTM,使其能够按照给定的开头创作一首诗。如果我们设置time_step为一个句子的长度,那么LSTM在训练的时候能够学习到一个句子长度以内的上下文的关系,这样我们得到的结果是:单个句子将是有意义的,但整首诗可能是无意义的。因此需要扩大time_step的长度,以整首诗的长度为序列长度,让LSTM能够学习到基于整首诗的上下文关系,这样得到的结果是有意义的。但每首诗的长度可能不同,因此存在一个max_step的问题,可用特定编码来补全。显然LSTM的学习能力越强越有可能出现权重衰退或权重爆炸的问题,因此在实际操作时需要注意。
假定batch_size=4,time_step=28,hidden_szie=50。
time_step=28意味着序列长度为28,意味着每个样本长度为28,意味着要将图片切分为长度是28的序列。对于28*28大小的MNIST来讲,恰好切分。注意,这里对每张图片来讲其被气氛为长度为28的patch,而每个patch的大小是1*28(对应NLP的词向量的维度),这个过程可以看成是重组图片的过程。其中序列长度time_step是指定的,而每个patch的大小不一定,且通常会在其上附加全局信息、局部信息、位置编码等等,用来增强该patch的特征。
hidden_size=50,指的是LSTM隐藏层的维度,LSTM隐藏层用来总结过往信息以便指导当前预测。
这样输入数据为:batch_size * 28 *28——》batch_size * 28 (序列长度time_step)* 28(词向量维度dim)
在pytorch的实现中,一般要转换输入数据的维度位置,将time_step放至第一维度,batch_size放置第二维度。即:batch_size * time_step * dim ——》time_step * batch_size * dim 这样做的目的是在存储时将一个batch_size内的各个样本的第一个词(patch)存放至一起,便于读取数据进行批处理。

此时:对每一时刻,LSTM的数据大小为:batch_size * dim = 4 * 28,一共有time_step个时刻,即LSTM会循环time_step次。后续处理则直接使用LSTM最后网络的最后一个时刻的输出即可。



输出层的大小为28*4*200。28指的是时间步长度,LSTM的长度(或是LSTM循环的次数),一个时间步输出的词的个数。4指的是批大小。200指的是隐变量的维度。这里是双LSTM,因此扩充了2倍。真实隐变量的维度是指定的100。下述的单LSTM得到的输出维度是双LSTM的一半,为指定的100。
# 执行单LSTM。
output_sig, (hn_sig, cn_sig) = rnn_sig(input, (h_sig, c_sig))
print("output_sig.shape", output_sig.shape)
print("hn_sig.shape", hn_sig.shape)
print("cn_sig.shape", cn_sig.shape)


这里所有的权重的横向维度应该是hidden_size=100,但由于具体实现的原因,将遗忘门、输出门、输入门、候选记忆单元的权重矩阵进行了拼接,因此是原先的4倍。
# 打印单LSTM权重信息 print(rnn_sig.weight_hh_l0.shape) print(rnn_sig.weight_ih_l0.shape) print(rnn_sig.bias_hh_l0.shape) print(rnn_sig.bias_ih_l0.shape)

pytorch实现LSTM时,会将计算输入门、输出门、遗忘门、候选记忆单元的权重矩阵进行拼接,也就是在计算h隐变量时:原本为hidden_size * hidden_size大小的权重矩阵变为 4*hidden_size * hidden_size大小。在计算输入时:原本为hidden_size * input_size变为4 * hidden_size * input_size。
这里的input_size就是NLP中词向量的维度,也是CV中patch的特征维度,为了使用NLP的方法,CV中需要对图片进行切片,将其转换为序列数据进行处理,这种转换需要按照一定的规则进行,排列也需要一定的顺序,这样可利用NLP可处理序列化数据的特性。切分的过程就是重组图片的过程,time_step是NLP中每个句子的长度,每个句子的长度可能不一,可使用特殊编码词补全。这里time_step转换到CV就是将图片切分的块数。而句子中每个词的词向量的长度就是表征这个词的特征向量的长度,这个特征向量通过编码得到,这个概念转换到CV中就是每个patch的特征向量,在CV中,每个patch中特征向量的成分是关键,一般这种特征需要包含局部信息和全局信息,以此来尽可能的表征该patch的属性,从而方便的用于各种目的。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构