Spark使用Java读取mysql数据和保存数据到mysql
原文引自:http://blog.csdn.net/fengzhimohan/article/details/78471952
项目应用需要利用Spark读取mysql数据进行数据分析,然后将分析结果保存到mysql中。
开发环境:
java:1.8
IDEA
spark:1.6.2
一.读取mysql数据
1.创建一个mysql数据库
user_test表结构如下:
1 create table user_test ( 2 id int(11) default null comment "id", 3 name varchar(64) default null comment "用户名", 4 password varchar(64) default null comment "密码", 5 age int(11) default null comment "年龄" 6 )engine=InnoDB default charset=utf-8;
2.插入数据
1 insert into user_test values(12, 'cassie', '123456', 25); 2 insert into user_test values(11, 'zhangs', '1234562', 26); 3 insert into user_test values(23, 'zhangs', '2321312', 27); 4 insert into user_test values(22, 'tom', 'asdfg', 28);
3.创建maven工程,命名为Test,添加java类SparkMysql
添加依赖包
pom文件内容:
1 <?xml version="1.0" encoding="UTF-8"?> 2 <project xmlns="http://maven.apache.org/POM/4.0.0" 3 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" 4 xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> 5 <modelVersion>4.0.0</modelVersion> 6 7 <groupId>SparkSQL</groupId> 8 <artifactId>com.sparksql.test</artifactId> 9 <version>1.0-SNAPSHOT</version> 10 <properties> 11 <java.version>1.8</java.version> 12 </properties> 13 <dependencies> 14 <dependency> 15 <groupId>mysql</groupId> 16 <artifactId>mysql-connector-java</artifactId> 17 <version>5.1.24</version> 18 </dependency> 19 <dependency> 20 <groupId>org.apache.hadoop</groupId> 21 <artifactId>hadoop-common</artifactId> 22 <version>2.6.0</version> 23 </dependency> 24 <dependency> 25 <groupId>net.sf.json-lib</groupId> 26 <artifactId>json-lib</artifactId> 27 <version>2.4</version> 28 <classifier>jdk15</classifier> 29 </dependency> 30 31 </dependencies> 32 33 </project>
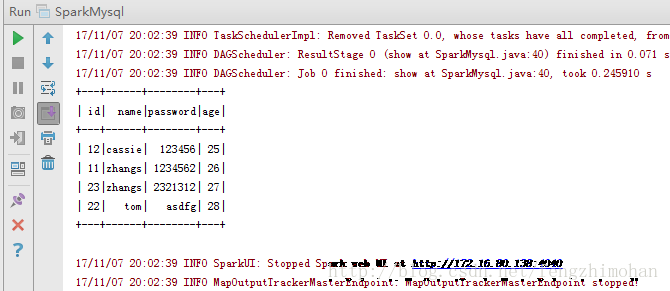
4.编写spark代码
1 import org.apache.spark.SparkConf; 2 import org.apache.spark.api.java.JavaSparkContext; 3 import org.apache.spark.sql.DataFrame; 4 import org.apache.spark.sql.SQLContext; 5 6 import java.util.Properties; 7 8 /** 9 * Created by Administrator on 2017/11/6. 10 */ 11 public class SparkMysql { 12 public static org.apache.log4j.Logger logger = org.apache.log4j.Logger.getLogger(SparkMysql.class); 13 14 public static void main(String[] args) { 15 JavaSparkContext sparkContext = new JavaSparkContext(new SparkConf().setAppName("SparkMysql").setMaster("local[5]")); 16 SQLContext sqlContext = new SQLContext(sparkContext); 17 //读取mysql数据 18 readMySQL(sqlContext); 19 20 //停止SparkContext 21 sparkContext.stop(); 22 } 23 private static void readMySQL(SQLContext sqlContext){ 24 //jdbc.url=jdbc:mysql://localhost:3306/database 25 String url = "jdbc:mysql://localhost:3306/test"; 26 //查找的表名 27 String table = "user_test"; 28 //增加数据库的用户名(user)密码(password),指定test数据库的驱动(driver) 29 Properties connectionProperties = new Properties(); 30 connectionProperties.put("user","root"); 31 connectionProperties.put("password","123456"); 32 connectionProperties.put("driver","com.mysql.jdbc.Driver"); 33 34 //SparkJdbc读取Postgresql的products表内容 35 System.out.println("读取test数据库中的user_test表内容"); 36 // 读取表中所有数据 37 DataFrame jdbcDF = sqlContext.read().jdbc(url,table,connectionProperties).select("*"); 38 //显示数据 39 jdbcDF.show(); 40 } 41 }
运行结果:
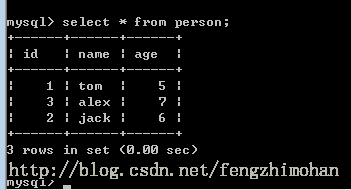
二.写入数据到mysql中
1 import org.apache.spark.SparkConf; 2 import org.apache.spark.api.java.JavaRDD; 3 import org.apache.spark.api.java.JavaSparkContext; 4 import org.apache.spark.api.java.function.Function; 5 import org.apache.spark.sql.DataFrame; 6 import org.apache.spark.sql.Row; 7 import org.apache.spark.sql.RowFactory; 8 import org.apache.spark.sql.SQLContext; 9 import org.apache.spark.sql.types.DataTypes; 10 import org.apache.spark.sql.types.StructType; 11 12 import java.util.ArrayList; 13 import java.util.Arrays; 14 import java.util.List; 15 import java.util.Properties; 16 17 /** 18 * Created by Administrator on 2017/11/6. 19 */ 20 public class SparkMysql { 21 public static org.apache.log4j.Logger logger = org.apache.log4j.Logger.getLogger(SparkMysql.class); 22 23 public static void main(String[] args) { 24 JavaSparkContext sparkContext = new JavaSparkContext(new SparkConf().setAppName("SparkMysql").setMaster("local[5]")); 25 SQLContext sqlContext = new SQLContext(sparkContext); 26 //写入的数据内容 27 JavaRDD<String> personData = sparkContext.parallelize(Arrays.asList("1 tom 5","2 jack 6","3 alex 7")); 28 //数据库内容 29 String url = "jdbc:mysql://localhost:3306/test"; 30 Properties connectionProperties = new Properties(); 31 connectionProperties.put("user","root"); 32 connectionProperties.put("password","123456"); 33 connectionProperties.put("driver","com.mysql.jdbc.Driver"); 34 /** 35 * 第一步:在RDD的基础上创建类型为Row的RDD 36 */ 37 //将RDD变成以Row为类型的RDD。Row可以简单理解为Table的一行数据 38 JavaRDD<Row> personsRDD = personData.map(new Function<String,Row>(){ 39 public Row call(String line) throws Exception { 40 String[] splited = line.split(" "); 41 return RowFactory.create(Integer.valueOf(splited[0]),splited[1],Integer.valueOf(splited[2])); 42 } 43 }); 44 45 /** 46 * 第二步:动态构造DataFrame的元数据。 47 */ 48 List structFields = new ArrayList(); 49 structFields.add(DataTypes.createStructField("id",DataTypes.IntegerType,true)); 50 structFields.add(DataTypes.createStructField("name",DataTypes.StringType,true)); 51 structFields.add(DataTypes.createStructField("age",DataTypes.IntegerType,true)); 52 53 //构建StructType,用于最后DataFrame元数据的描述 54 StructType structType = DataTypes.createStructType(structFields); 55 56 /** 57 * 第三步:基于已有的元数据以及RDD<Row>来构造DataFrame 58 */ 59 DataFrame personsDF = sqlContext.createDataFrame(personsRDD,structType); 60 61 /** 62 * 第四步:将数据写入到person表中 63 */ 64 personsDF.write().mode("append").jdbc(url,"person",connectionProperties); 65 66 //停止SparkContext 67 sparkContext.stop(); 68 } 69 }
运行结果: