

spark编程入门-idea环境搭建
原文引自:http://blog.csdn.net/huanbia/article/details/69084895
1、环境准备
idea采用2017.3.1版本。
创建一个文件a.txt

2、构建maven工程
点击File->New->Project…
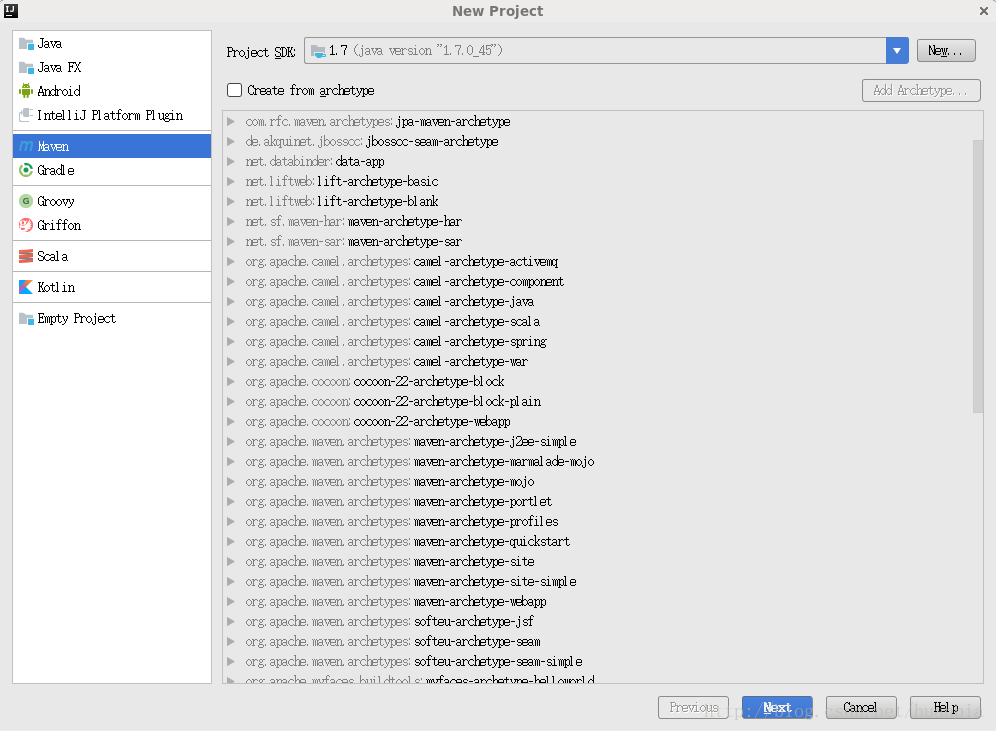
点击Next,其中GroupId和ArtifactId可随意命名

点击Next
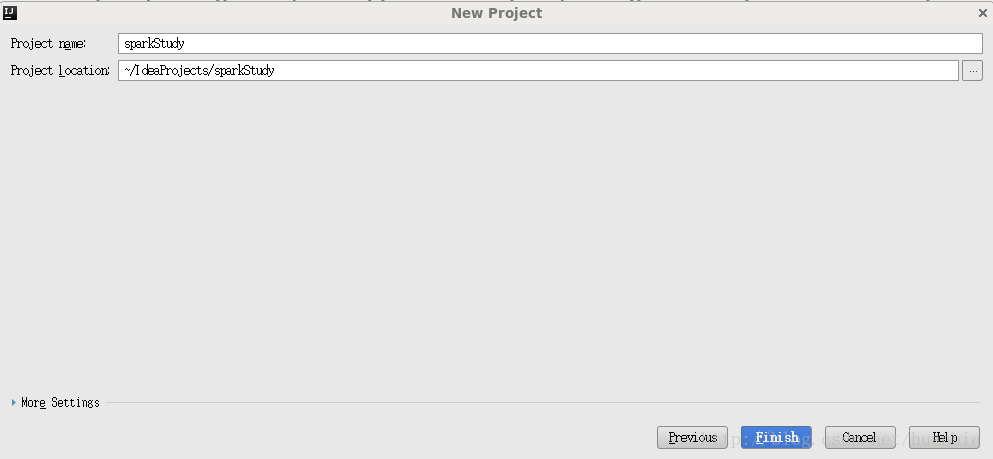
点击Finish,出现如下界面:
3、书写wordCount代码
请在pom.xml中的version标签后追加如下配置
1 <properties> 2 <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> 3 </properties> 4 <dependencies> 5 <dependency> 6 <groupId>junit</groupId> 7 <artifactId>junit</artifactId> 8 <version>3.8.1</version> 9 <scope>test</scope> 10 </dependency> 11 <dependency> 12 <groupId>org.apache.spark</groupId> 13 <artifactId>spark-core_2.10</artifactId> 14 <version>1.6.1</version> 15 </dependency> 16 <dependency> 17 <groupId>org.apache.spark</groupId> 18 <artifactId>spark-sql_2.10</artifactId> 19 <version>1.6.1</version> 20 </dependency> 21 <dependency> 22 <groupId>org.apache.spark</groupId> 23 <artifactId>spark-hive_2.10</artifactId> 24 <version>1.6.1</version> 25 </dependency> 26 <dependency> 27 <groupId>org.apache.spark</groupId> 28 <artifactId>spark-streaming_2.10</artifactId> 29 <version>1.6.1</version> 30 </dependency> 31 <dependency> 32 <groupId>org.apache.hadoop</groupId> 33 <artifactId>hadoop-client</artifactId> 34 <version>2.7.1</version> 35 </dependency> 36 <dependency> 37 <groupId>org.apache.spark</groupId> 38 <artifactId>spark-streaming-kafka_2.10</artifactId> 39 <version>1.6.1</version> 40 </dependency> 41 <dependency> 42 <groupId>org.apache.spark</groupId> 43 <artifactId>spark-graphx_2.10</artifactId> 44 <version>1.6.1</version> 45 </dependency> 46 <dependency> 47 <groupId>org.apache.maven.plugins</groupId> 48 <artifactId>maven-assembly-plugin</artifactId> 49 <version>2.2-beta-5</version> 50 </dependency> 51 <dependency> 52 <groupId>commons-lang</groupId> 53 <artifactId>commons-lang</artifactId> 54 <version>2.3</version> 55 </dependency> 56 </dependencies> 57 <build> 58 <sourceDirectory>src/main/java</sourceDirectory> 59 <testSourceDirectory>src/test/java</testSourceDirectory> 60 <plugins> 61 <plugin> 62 <artifactId>maven-assembly-plugin</artifactId> 63 <configuration> 64 <descriptorRefs> 65 <descriptorRef>jar-with-dependencies</descriptorRef> 66 </descriptorRefs> 67 <archive> 68 <manifest> 69 <maniClass></maniClass> 70 </manifest> 71 </archive> 72 </configuration> 73 <executions> 74 <execution> 75 <id>make-assembly</id> 76 <phase>package</phase> 77 <goals> 78 <goal>single</goal> 79 </goals> 80 </execution> 81 </executions> 82 </plugin> 83 <plugin> 84 <groupId>org.codehaus.mojo</groupId> 85 <artifactId>exec-maven-plugin</artifactId> 86 <version>1.3.1</version> 87 <executions> 88 <execution> 89 <goals> 90 <goal>exec</goal> 91 </goals> 92 </execution> 93 </executions> 94 <configuration> 95 <executable>java</executable> 96 <includeProjectDependencies>false</includeProjectDependencies> 97 <classpathScope>compile</classpathScope> 98 <mainClass>com.dt.spark.SparkApps.App</mainClass> 99 </configuration> 100 </plugin> 101 <plugin> 102 <groupId>org.apache.maven.plugins</groupId> 103 <artifactId>maven-compiler-plugin</artifactId> 104 105 106 <configuration> 107 <source>1.6</source> 108 <target>1.6</target> 109 </configuration> 110 </plugin> 111 </plugins> 112 </build>
点击右下角的Import Changes导入相应的包

点击File->Project Structure…->Moudules,将src和main都选为Sources文件
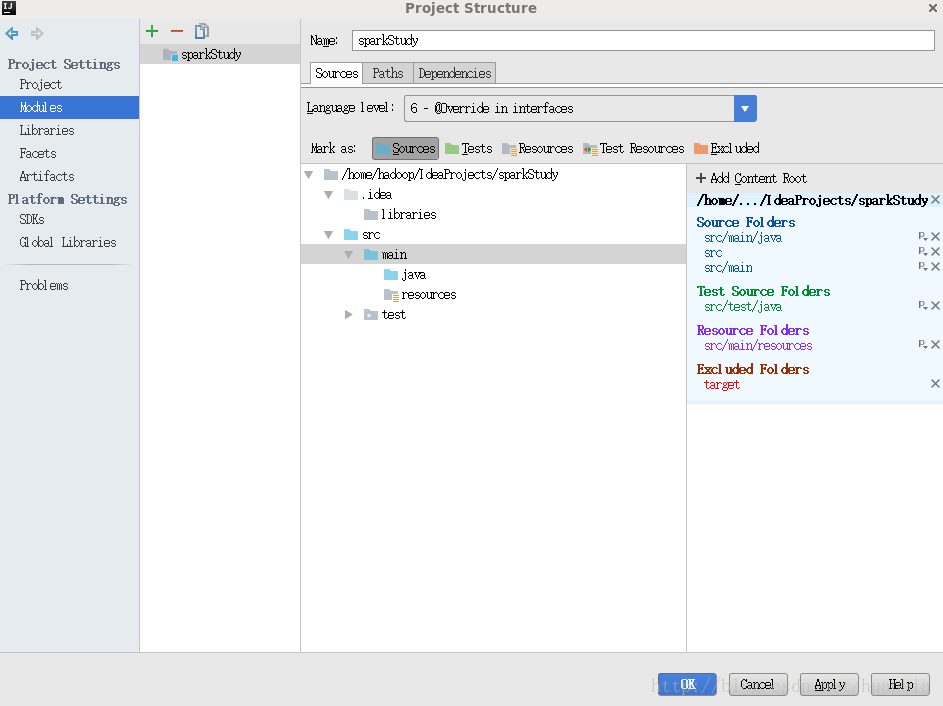
在java文件夹下创建SparkWordCount java文件
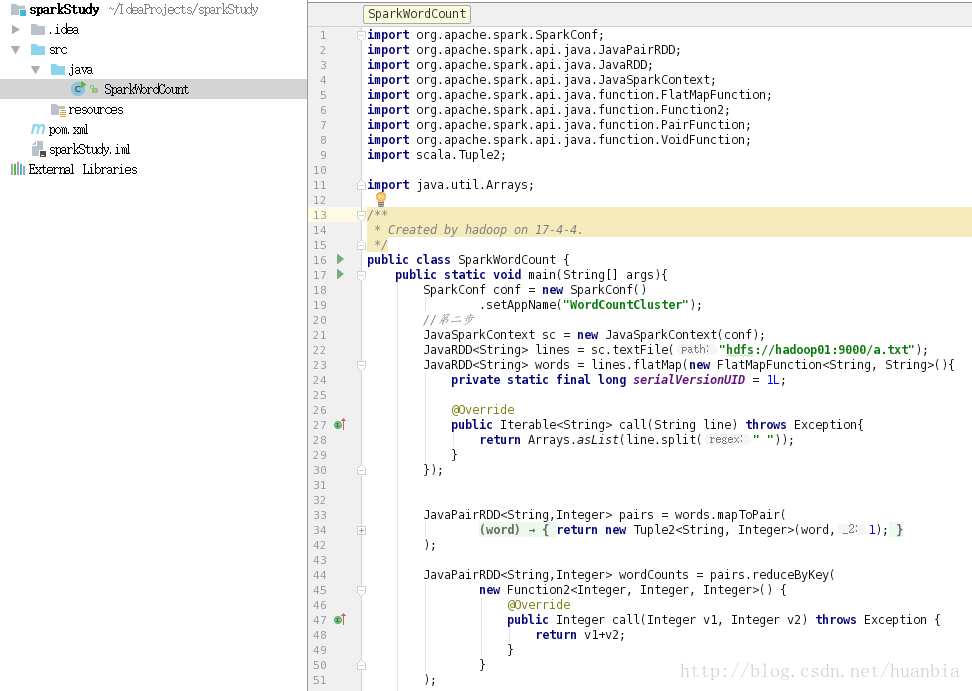
该文件代码为:
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import scala.Tuple2;
import java.util.Arrays;
/**
* Created by hadoop on 17-4-4.
*/
public class SparkWordCount {
public static void main(String[] args){
SparkConf conf = new SparkConf()
.setAppName("WordCountCluster");
//第二步
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> lines = sc.textFile("hdfs://hadoop01:9000/a.txt");
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>(){
private static final long serialVersionUID = 1L;
@Override
public Iterable<String> call(String line) throws Exception{
return Arrays.asList(line.split(" "));
}
});
JavaPairRDD<String,Integer> pairs = words.mapToPair(
new PairFunction<String, String, Integer>() {
private static final long serialVersionUID = 1L;
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String, Integer>(word,1);
}
}
);
JavaPairRDD<String,Integer> wordCounts = pairs.reduceByKey(
new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1+v2;
}
}
);
wordCounts.foreach(new VoidFunction<Tuple2<String, Integer>>() {
@Override
public void call(Tuple2<String, Integer> wordCount) throws Exception {
System.out.println(wordCount._1+" : "+ wordCount._2 );
}
});
sc.close();
}
}
打包:
执行
会在output目录下 生成可执行jar包 sparkStudy
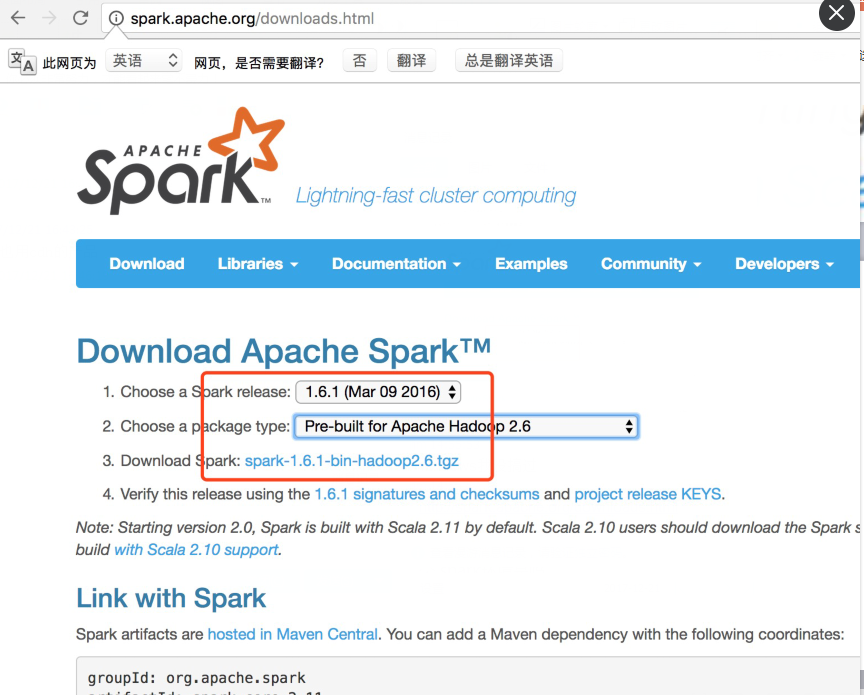
4、jar包上传到集群并执行
从spark官方网站 下载spark-1.6.1-bin-hadoop2.6.tgz
Spark目录:
bin包含用来和Spark交互的可执行文件,如Spark shell。
examples包含一些单机Spark job,可以研究和运行这些例子。
Spark的Shell:
Spark的shell能够处理分布在集群上的数据。
Spark把数据加载到节点的内存中,因此分布式处理可在秒级完成。
快速使用迭代式计算,实时查询、分析一般能够在shells中完成。
Spark提供了Python shells和Scala shells。
解压

这里需要先启动集群:
启动master: ./sbin/start-master.sh
启动worker: ./bin/spark-class org.apache.spark.deploy.worker.Worker spark://localhost:7077
这里的地址为:启动master后,在浏览器输入localhost:8080,查看到的master地址

启动成功后,jps查看进程:
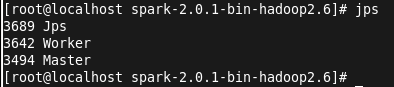
接下来执行提交命令,将打好的jar包上传到linux目录,jar包在项目目录下的out\artifacts下。
提交作业: ./bin/spark-submit --master spark://localhost:7077 --class WordCount /home/lucy/learnspark.jar
可以在4040端口查看job进度:
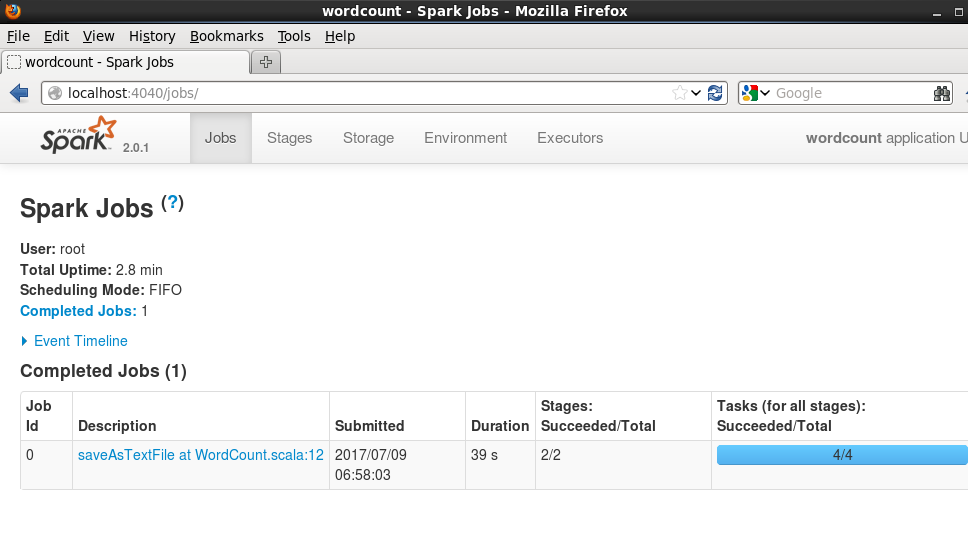
将执行的包上传到服务器上,封装执行的脚本。
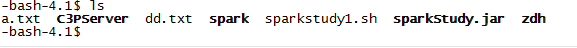

然后执行脚本,执行结果如下:
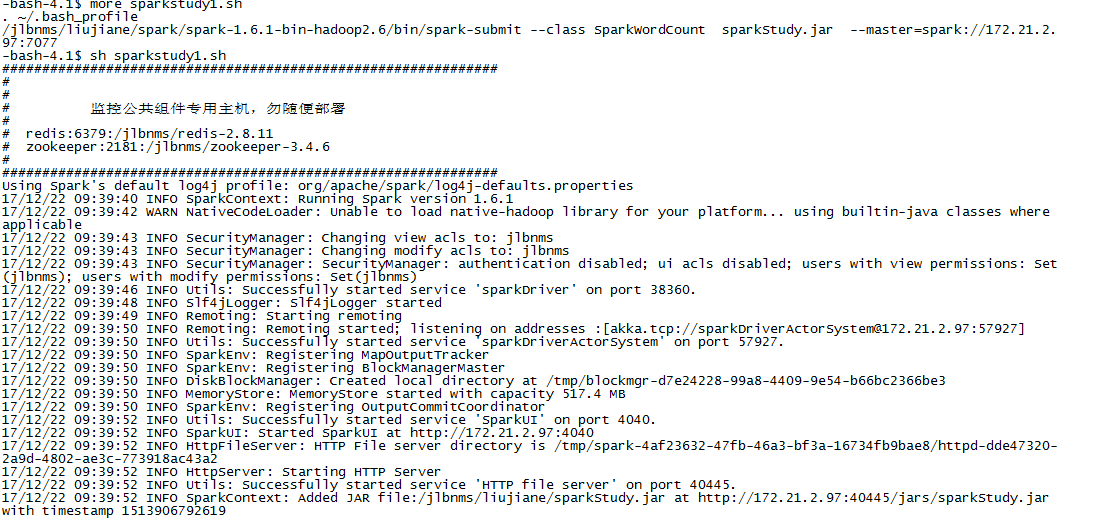
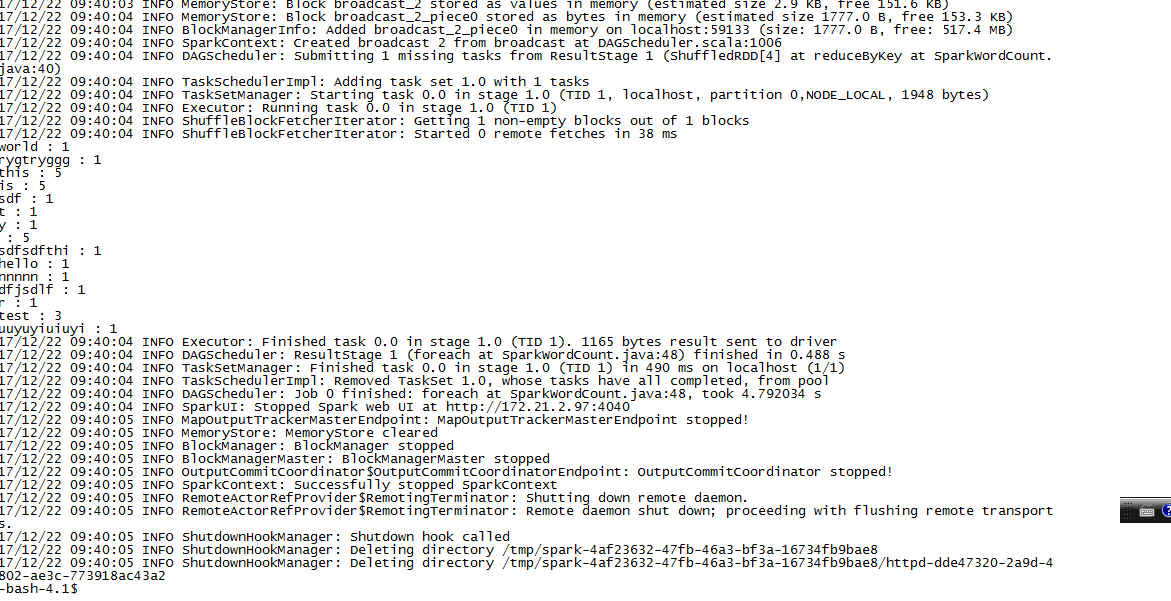
任务执行结束。

