
频繁FullGC的原因竟然是“开源代码”
 我们主要探究Full GC的角度出发分析我在开发运营后台的时候遇到的频繁Full GC过程。
我们主要探究Full GC的角度出发分析我在开发运营后台的时候遇到的频繁Full GC过程。
前言
首先java语言的特性是不需像C和C++那样自己手动释放内存,因为java本身有垃圾回收机制(垃圾回收称为GC),顾名思义就是释放垃圾占用的空间,防止内存泄露。JVM运行时占用内存最大的空间就是堆内存,另外栈区和方法区也会占用空间但是占用有限本章就不探究了。那么堆中的空间又分为年轻代和老年代,所以我们粗略的把垃圾回收分为两种:年轻代的垃圾回收称为Young GC,老年代的垃圾回收称为Full GC,实际上此处的Full GC也包含了新生代,老年代,元空间等的回收。
因为Full GC的回收过程会使系统的所有线程STW(Stop The World),那么我们一定希望让系统尽量不要进行Full GC,或者必须要进行FullGC的时候执行的时间越短越好。下面我们主要探究Full GC的角度出发分析我在开发运营后台的时候遇到的频繁Full GC过程。
事件背景
项目介绍:
我们团队做的是一个后台管理系统,因为针对不同用户负责的功能不同那么需要的权限也就不一样,所以引入了主流的shiro框架做权限控制,该框架可以控制菜单栏,按钮,操作框等。在引入这个框架时一并引入了辅助组件shiro-redis,该组件是一个缓存层方便管理用户登录信息,内存泄漏的问题也是就现在这个辅助组件上。
事件还原:
在周五的中午11:30分收到了监控的报警信息提示系统在频繁Full GC,此时我们立刻做两件事情:
第一:登录公司的UMP监控平台(开源监控可以参考:【Prometheus+grafana监控】)查看该机器的系统指标,发现确实在频繁FullGC从11点持续到了11点半

第二:保留一台机器作为证据收集,其他机器进行重启保障业务能正常访问,重启后full gc正常
第三:堆栈信息操作指令 ./jmap -F -dump:live,format=b,file=/jmapfile.hprof 18362 (-F操作是强制导出堆栈信息,18362是应用pid,通过 top -c 指令获取)
第四:因为个人无权限导出堆栈信息,马上电话联系运维通过上面指令导出该机器上的堆栈文件,就是抓取现场证据,因为过了这个时间堆内存可能就正常了
根据JVM知识分析,常见Full GC时的五种情况如下:
1. 老年代内存不足(大对象过多或内存泄漏)
2. Metaspace 空间不足
3. 代码主动触发 System.gc()
4. YGC 时的悲观策略
5. dump live 的内存信息时,比如 jmap -dump:live
分析原因
1、查看公司SGM监控平台(开源监控可以参考:【Prometheus+grafana监控】),元空间最大内存256M,FullGC发生前后为117M,排除Metaspace不足造成的原因

2、在系统中搜索第三方jar包,没有主动执行System.gc()操作的代码
3、查看JVM启动参数中有下面两个参数,所以排除了YGC时候的悲观策略原因
-XX:CMSInitiatingOccupancyFraction=70 # 堆内存达到 70%进行 FullGC
-XX:+UseCMSInitiatingOccupancyOnly # 禁止 YGC 时的悲观策略(YGC 前后判断是否需要 FullGC),只有达到阈值才进行 FullGc
4、通过和运维、研发组沟通没有人主动执行dump操作,查看系统的历史执行指令也没有dump操作,主动dump的原因排除
初步分析结果:
通过上面依靠监控平台、JVM启动参数、代码排除、指令分析,最终嫌疑最大的就是老年代内存空间不足造成频繁Full GC,但是作为技术者,排除法显然不能作为原因定位的依据,我们还需要继续确定我们的猜想,下面会结合JVM启动参数,Tomcat启动参数,堆栈文件三大关键要素做具体分析。
下图是进行FullGC时候的老年代内存情况,把下面的72%、1794Mb、2496Mb、448Mb先记住,下面会跟这些值做对比

指标信息:
JVM核心参数:
-Xms2048M # 系统启动初始化堆空间
-Xmx4096M # 系统最大堆空间
-Xmn1600M # 年轻代空间(包括 From 区和 To),From 和 To 默认占年轻代 20%
-XX:MaxPermSize=256M # 最大非堆内存,按需分配
-XX:MetaspaceSize=256M # 元空间大小,JDK1.8 取消了永久代(PermGen)新增元空间,元空间并不在虚拟机中,而是使用本地内存。因此,默认情况下,元空间的大小仅受本地内存限制,存储类和类加载器的元数据信息
-XX:CMSInitiatingOccupancyFraction=70 # 堆内存达到 70%进行 FullGC
-XX:+UseCMSInitiatingOccupancyOnly # 禁止 YGC 时的悲观策略(YGC 前后判断是否需要 FullGC),只有达到阈值才进行 FullGc
-XX:+UseConcMarkSweepGC # 使用 CMS 作为垃圾收集器
Tomcat核心参数:
maxThreads=750 # Tomcat 线程池最多能起的线程数
minSpareThreads=50 # Tomcat 初始化的线程池大小或者说 Tomcat 线程池最少会有这么多线程
acceptCount=1000 # Tomcat 维护最大的队列数
通过上边的指标信息我们能对系统的性能瓶颈有大致了解,首先根据JVM参数分析结果如下:
堆最大空间4096M
年轻代占用空间1600M(包括Eden区1280M,Survivor From160M,Survivor To160M)
老年代最大占用空间2496M(跟上面的2496Mb对应)
系统初始化堆内存2048M
那么老年代初始内存(448M) (跟上面的448Mb对应)= 初始化堆内存(2048M) - 年轻代内存(1600M)
根据JVM启动参数确定堆内存达到70时进行垃圾回收, 系统进行垃圾回收时堆内存占比72%(跟上面的72%对应)一直大于70%,那么使用内存是0.72 * 2496Mb ≈ 1794Mb(跟上面的1794Mb对应)
堆栈分析:
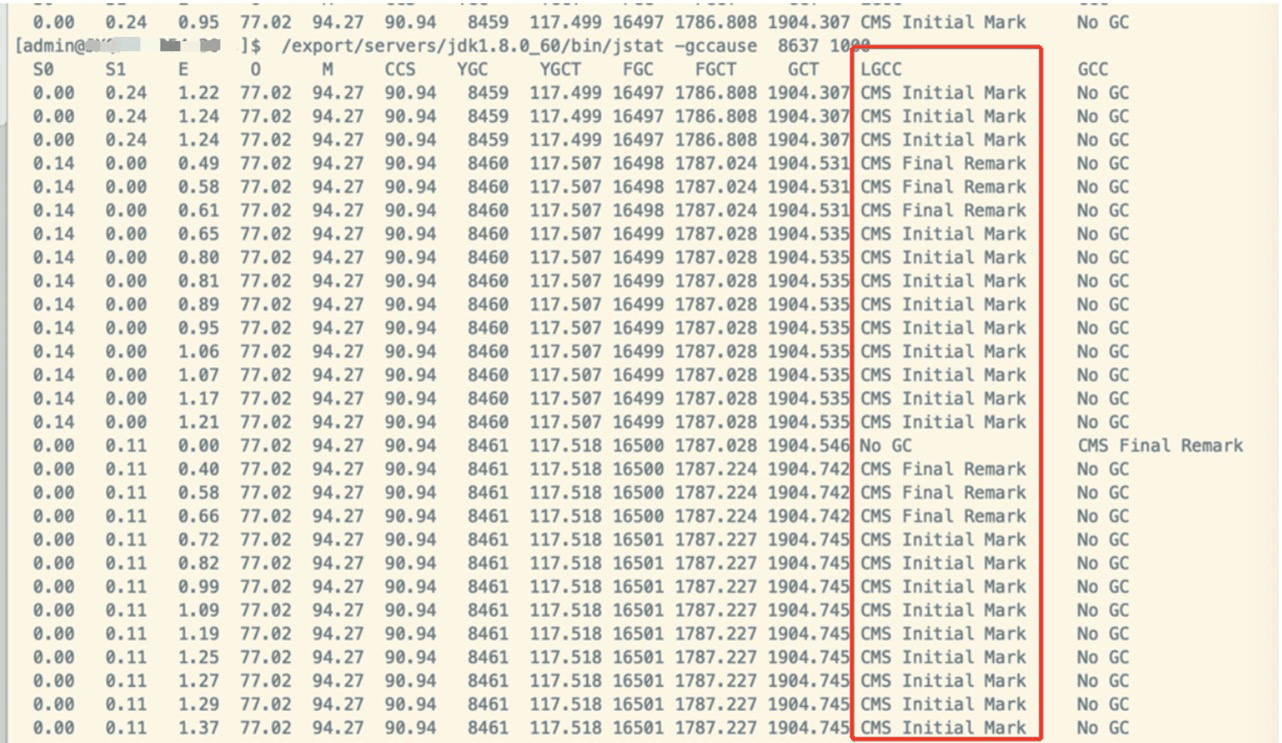
在查询堆栈前执行GC原因指令:jstat -gccause [pid] 1000,执行结果如下图,可以看到 LGCC 这一列代表了最后执行 gc 的原因。CMS Initial Mark 和 CMS Final Remark 这两个阶段是 CMS 垃圾回收的初始标记和最终标记阶段是耗时最长也是造成 STW(Stop The World)的两个阶段
导出堆栈指令:jmap -dump:live,format=b,file=jmapfile.hprof [pid]。导出的文件需要使用MAT软件分析,全称 MemoryAnalyzer,主要分析堆内存。参考下载链接:http://eclipse.org/mat/downloads.php
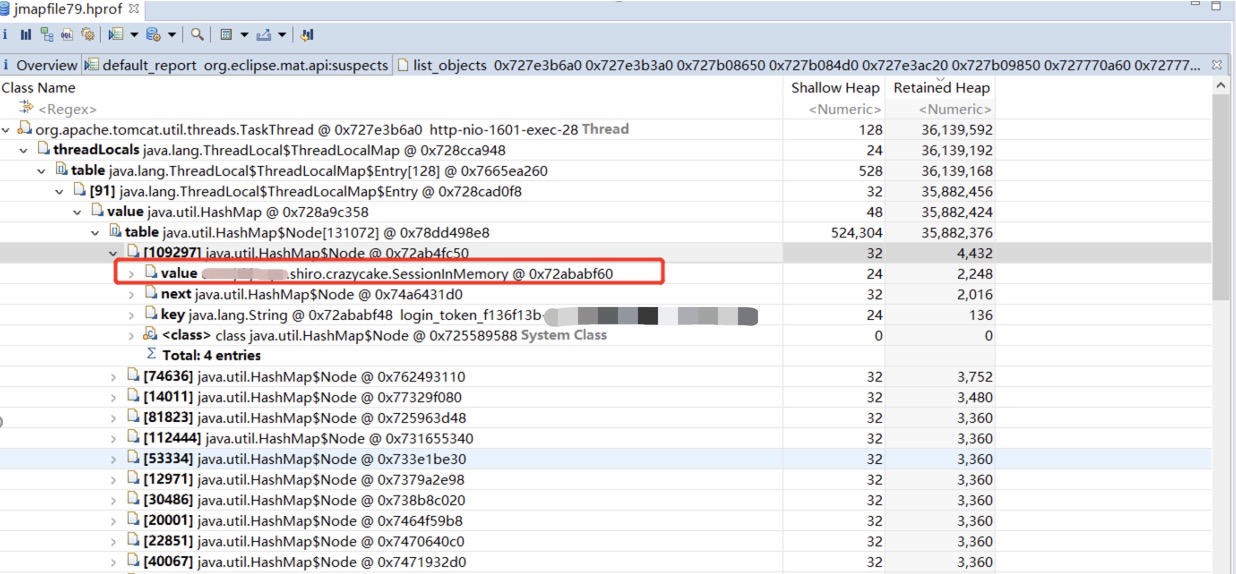
从堆栈文件分析结果中发现有50个org.apache.tomcat.util.threads.TaskThread占用空间很大。共占用空间96.16%

每个TaskThread实例占用空间36M左右

查看内存详情保存最大最多的对象是ThreadLocal中存储的SessionInMemory对象
最终原因:
通过分析上面的JVM参数、Tomcat参数、堆栈文件,内存泄漏的原因是每个线程中有一个ThreadLocal存储大量 SessionInMemory,因为Tomcat的启动核心线程数是50个,每个线程的内存占用 36M 左右,共占用 1.8G,老年代内存达到 70%也就是 2496 * 0.7 = 1747.2M 就会进行垃圾回收,1.8G 刚好比 1747.2M 稍微大一些。但是线程中的对象又没办法被回收,所以就会看到系统再频繁 FullGC。
定位问题
通过上面内存分析已经定位到内存泄漏的原因是每个线程中有大量 SessionInMemory,下面步骤就认真分析代码找到其中创建如此多对象还不销毁的原因。
经过初步分析发现 SessionInMemory 是引用 shiro-redis 的工具包里面的对象,主要封装Session 信息和创建时间。主要作用是在当前线程的jvm中做一层缓存当系统频繁获取 Session 时不用去 redis 获取了。SessionInMemary对象是shiro判断用户登录成功时候存储的数据,主要包括用户信息,认证信息,权限信息等,因为用户登录成功后不会重复认证,shiro会对不同用户做权限判断
分析代码发现处理本地缓存Session的流程有明显问题,我画了一个简易的流程图,在介绍流程图前我先描述一下Session和用户登录操作如何联系起来
我们都知道运营后台需要用户登录,登录成功后会生成一个cookie保存到浏览器中,cookie存储一个关键字段sessionId用来标识用户的状态和信息,当用户访问页面调用接口的时候shiro会从请求Request中获取cookie中的sessionId,根据这个唯一标识生成Session来存储用户的登录态和登录信息等,这些信息会保存到redis中。shiro-redis组件负责从redis中获取的Session信息通过ThreadLoca做到线程隔离。

上图流程概括就是:用户访问页面先从本地缓存获取Session,如果存在且没有超过一秒就返回结果,如果没有Session或者过期了就把现在的Session删除并新建一个返回结果。整体看思路清晰,先获取Session,如果没有就新建返回,如果过期了就删除再新建返回。
流程图隐藏的问题(核心问题)
1、多个线程会复制多份相同Session使内存成倍增加(Session一样线程不同)
举个例子:用户登录后台生成一个Session,假设请求都到一台机器上,第一次请求到线程 1,第二个请求到线程 2,因为Session一样但是线程之间是隔离的,所以线程 1 和线程 2 都会创建一份相同 Session 存储到 ThreaLocal 中,Tomcat 最小空闲线程数越多复制的 Session 份数也越多。因为Tomcat的核心线程数不会关闭,所以里面的资源也不会释放。此处有个疑问ThreadLocad的key是弱引用但是为什么没回收呢?下面统统解答
2、旧Session无法清除(线程一样Session不同)
举个例子1:假设所有请求都到一台机器的同一个线程,用户第一次登录后台生成Session1,第一次请求到线程 1,1 秒内所有请求都执行完了,此时 Session 没有移除(因为Session移除策略是懒删除,需要等下次同一个Session访问时判断过期条件再删除),用户重新登录,生成了Session2,因为Session2在线程1中还没有就会重新创建,导致第一次登录时候用到的 Session1 就一直保存到该线程中了
举个例子2:参考例子1的思路,如果用户用Session1没有在1秒内把所有请求执行完,就会执行懒删除操作,但是删除后又新建了一个,那么用户重新登录后刚才新建的那个Session还是没有被删除,所以总结出来只要用户重新登录必定有一个旧的Session会保留到线程中
代码分析
1、在RedisSessionDAO.java文件中定义了一个ThreadLocal变量作为线程隔离

2、用户访问接口、js 文件、css 文件等资源的时候会进入 shiro 的拦截机制。在拦截过程中会频繁调用 doReasSession()方法获取用户的 Session 信息,主要是获取信息校验用户的权限控制等。
下面的方法主要整合了获取Session操作和设置Session操作,如果从ThreadLocal中没有获取到或者本地缓存超过1秒了就返回null,判断为null之后就会从redis中获取并新建一个Session存储到ThreadLoca中

3、从ThreadLocal中取出sessionMap,根据sessionId在sessionMap中寻找Session,如果没找到直接返回null,如果找到了再判断时间是否超过了1秒,如果没超过返回Session,如果超过了移除返回null

4、从ThreadLocal中获取sessionMap,如果为null就新建一个保存起来,因为用户第一次访问的时候线程中的sessionMap还没有呢所以要新建。然后向sessionMap中存储Session对象

所以代码的完成流程总结:获取 Session 的操作是调用 getSessionFromThreadLocal()方法,如果没有获取到 Session 就返回 null,调用 setSessionToThreadLocal()方法会重新设置一个 Session。如果 Session 在当前线程的保存时间超过 1 秒就 remove。
通过上面分析JVM、Tomat、堆栈、代码已经把问题定位了,因为shiro-redis中存储的SessionInMemory对象处理不当导致线程间存储越来越多,最终使内存泄漏进而导致了频繁FullGC。因为我们引用的shiro-redis版本是3.2.2版本,所以存在这个漏洞,作者已于2019年3月升级jar包到3.2.3版本把该问题解决。备注:3.2.2及以下版本存在该问题
解决问题
解决问题的方案目前有四种。 针对我们系统使用的是方案 1+方案 4
| 序号 | 方案描述 | 优点 | 缺点 |
|---|---|---|---|
| 方案1 | 每次设置session时遍历删除以前过期或者为null的session | 主动删除,删除频次依赖用户的访问频次 | 如果在1秒内有大量用户访问,总session很多无效session很少,遍历所有session做了很多无用功导致访问变慢 |
| 方案2 | 取消threadLocal策略,所有请求直接查询缓存(redis) | 减少本地内存使用 | 访问缓存耗时比本地长,经过测试发现一个接口会调用16次左右的获取session操作,一个页面几十个接口,直接查询缓存性能存在问题 |
| 方案3 | 使用本地缓存(guavaCache或者EhCache等),并对缓存做移除策略 | 多个线程共用一份内存,节省内存空间,提升系统性能 | 对框架有深入了解,接入需要开发成本 |
| 方案4 | 把tomcat的核心线程数减小,比如把原来的50改成 5 | 减少系统资源,减少相同Session的复制份数,大于5的线程销毁资源也一起回收 | 处理并发能力略低 |
疑问解答
Q:在 RedisSessionDAO 里面只定义了一个 ThreadLocal 的变量 sessionsInThread,怎么就会是 50 个线程把相同的 Session 复制 50 份呢?
A:首先我们先理解 ThreadLocal 的结构,ThreadLocal 有一个静态类 ThreadLocalMap,ThreadLocalMap 里面还有一个 Entry,我们的 key 和 value 就是保存在 Entry 的,key 是一个弱引用的 ThreadLocal 类型,,这个 key 在所有的线程中都是一样的,实际上就是我们定义的静态 sessionsInThread。那又是怎么做到线程隔离的呢?
这就讲到Thread中的一个成员变量threadLocals,这个对象就是ThreadLocal.ThreadLocalMap类型,也就是每次创建一个线程都会new一个ThreadLocalMap,所以每个线程中的 ThreadLocalMap 都是不同的,但是里面 Entry 存储的 key 都是一样的,也就是我们前面定义的 sessionsInThread 静态变量。
当一个线程需要获取 Entry 中存储的 value 时候,调用 sessionsInThread.get()方法,这个方法做了三件事情,一是获取当前线程的实例,二是从线程实例中获取 ThreadLocalMap,三是从 ThreadLocalMap 中根据 ThreadLocal 这个 key 获取指定的 value

获取 Thread 中的 ThreadLocalMap

从 ThreadLocalMap 中获取指定的 value,又有个疑问,获取 Entry 为什么还要从一个 table数组中拿呢?这个很好理解一个线程不一定只有一个 ThreadLocal 变量吧,多个 ThreadLocal变量就是有多个 key,所以就放到 table 数组里面了

Q:都说 ThreadLocal 的 key 是一个弱引用,如果内存不足了会被垃圾回收,咱们的 key 从堆栈看并没有回收呀?
A:这是个好问题,首先我们的 RedisSessionDAO 是 Spring 注入的单例模式,ThreadLocal被定义成一个静态变量,静态变量在内存中是不会回收的。 补充:一般我们在使用 ThreadLocal 的时候都会定义成静态变量,如果定义成非静态变量创建一个对象就会 new 一个 ThreadLocal,那么 ThreadLocal 就没有存在的意义了。
Q:已经结束的线程,为什么还会存活,里面的对象也不会消失?
A:因为设置的最小空闲线程数是50,业务量不大并发数没有超过50,tomcat会保留最小的线程数量不会新建也不用回收,ThreadLocalMap是线程中的成员变量所以不会回收
Q:访问一次接口就会生成一个 sessionId 吗?
A:访问接口先判断用户信息是否有效,无效才会重新登录获取新的 sessionId
Q:shiro-redis在本地保存Session为什么设置1秒过期时间?
A:因为运营后台不同于业务接口会持续调用,后台接口大部分的场景是用户访问一个页面并停留在页面上做一些操作,访问一个页面的时候浏览器会加载多个资源,包括静态资源html,css,js等,和接口的动态数据,整个资源加载过程尽量保持在一秒内完成,如果超过一秒的话系统体验性能较差,所以本地缓存一秒足够了。
收获总结
报警前:
1.熟悉第三方jar包的工作原理,尤其是个人开发工具包,因为没有经过市场检验使用前要格外小心
2.可以使用jvisualvm进行本地压测观察jvm情况
3.关注监控报警,掌握监控平台操作,能够从监控中查询系统各项指标信息
4.根据业务合理配置JVM参数和Tomcat参数
报警后:
1.能够第一时间抓取系统的JVM信息,比如堆栈,GC信息,线程栈等
2.通过使用MAT内存辅助软件帮助自己分析问题原因
作者:京东科技 郭银利
来源:京东云开发者社区


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· CSnakes vs Python.NET:高效嵌入与灵活互通的跨语言方案对比
· DeepSeek “源神”启动!「GitHub 热点速览」
· 我与微信审核的“相爱相杀”看个人小程序副业
· Plotly.NET 一个为 .NET 打造的强大开源交互式图表库
· 上周热点回顾(2.17-2.23)