
保姆级教程:用GPU云主机搭建AI大语言模型并用Flask封装成API,实现用户与模型对话
 在本文中,我们将以chatglm-6b为例详细介绍GPU云主机搭建AI大语言模型的过程,并使用Flask构建前端界面与该模型进行对话。
在本文中,我们将以chatglm-6b为例详细介绍GPU云主机搭建AI大语言模型的过程,并使用Flask构建前端界面与该模型进行对话。
导读
在当今的人工智能时代,大型AI模型已成为获得人工智能应用程序的关键。但是,这些巨大的模型需要庞大的计算资源和存储空间,因此搭建这些模型并对它们进行交互需要强大的计算能力,这通常需要使用云计算服务。从云产品性能上来看,GPU云主机是最适合的工具之一,对于业务方或者个人开发者来讲,使用GPU云主机搭建AI大语言模型有以下优势:
•高性能计算:GPU云主机提供了高性能GPU处理器,加速模型的训练和推理;
•高性价比:灵活资源管理、可扩展性、弹性伸缩等云计算优势,根据业务或个人训练的需要,快速调整计算资源,满足模型的训练和部署需求;
•开放性:云计算的开放性让用户更容易进行资源的共享和协作,为AI模型的研究和应用提供了更广泛的合作机会;
•丰富的API和SDK:云计算厂商提供了丰富的API和SDK,使得用户能够轻松地接入云平台的各种服务和功能,进行定制化开发和集成。
在本文中,我们将以chatglm-6b为例详细介绍GPU云主机搭建AI大语言模型的过程,并使用Flask构建前端界面与该模型进行对话。
整个流程也比较简单:配置GPU云主机 → 搭建Jupyterlab开发环境 → 安装ChatGLM → 用Flask输出模型API
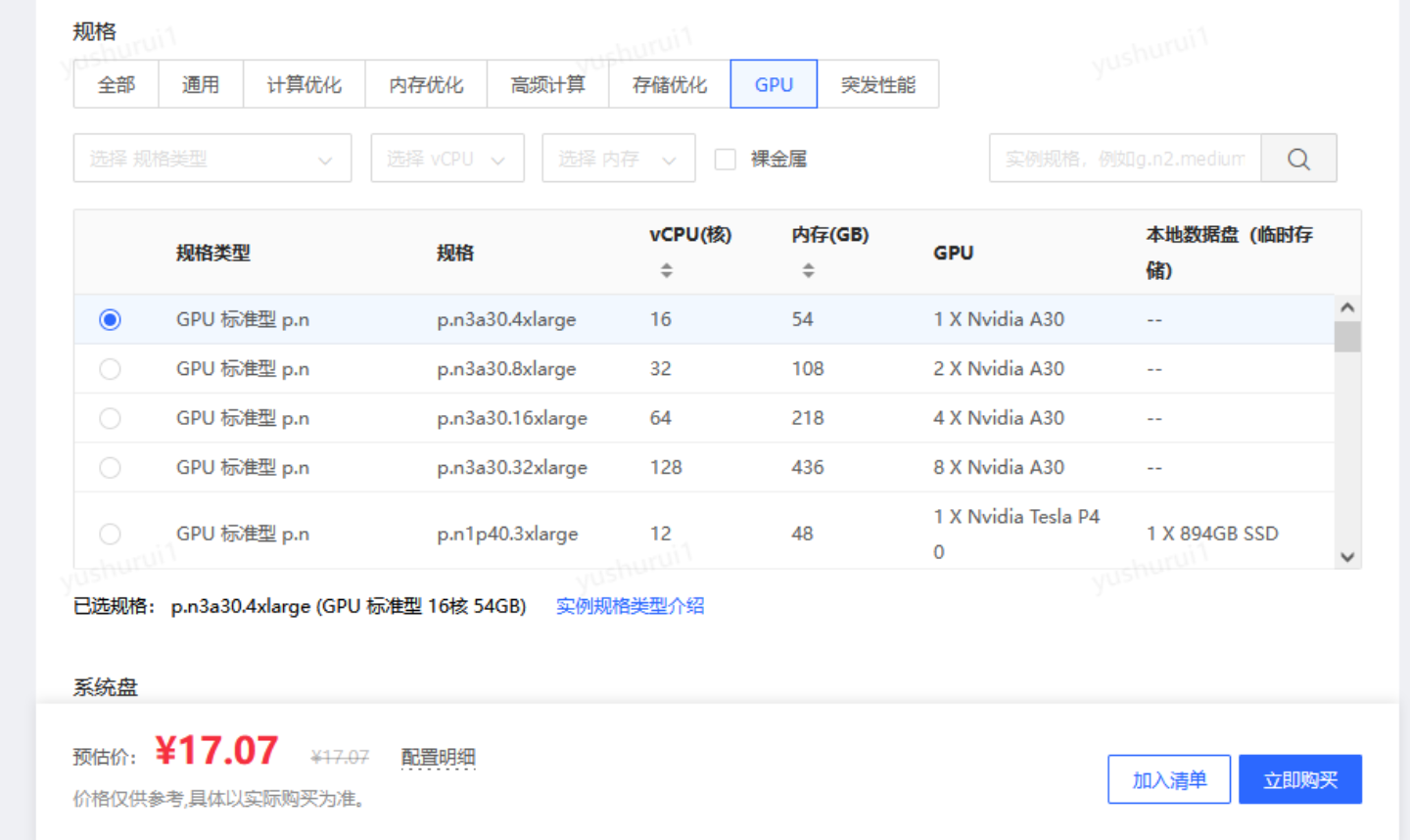
一、Start:配置GPU云主机
GPU 云主机(GPU Cloud Virtual Machine )是提供 GPU 算力的弹性计算服务,具有超强的并行计算能力,在深度学习、科学计算、图形图像处理、视频编解码等场景被广泛使用。GPU驱动,提供大量的GPU内存和强悍的计算性能,非常适合运行深度学习应用程序。
相对于实体卡,一张售价一般都是几万左右,而GPU云主机费用门槛很低,按时计费,一小时才十几元,可以根据自己的需求调配。
•本次选取的是P40卡: https://www.jdcloud.com/cn/calculator/calHost
•系统环境:Ubuntu 20.04 64位
二、搭建Jupyterlab开发环境
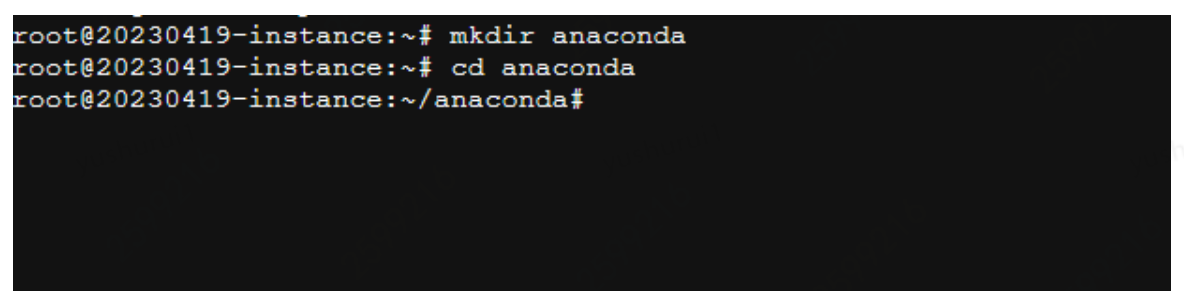


下载Anaconda包需要在终端里执行以下命令:
mkdir anaconda # 创建文件夹
cd anaconda # 进入文件夹
wget https://repo.anaconda.com/archive/Anaconda3-2023.03-Linux-x86_64.sh # 下载安装包
bash Anaconda3-2023.03-Linux-x86_64.sh # 安装
也可以用清华源,速度更快:https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/Anaconda3-2023.03-Linux-x86_64.sh

接下来进行环境变量设置
cd /root/anaconda3/bin
vim ~/.bashrc
在.bashrc下添加以下内容:#Anaconda
export PATH="/root/anaconda3/bin:$PATH"
然后退出编辑
source ~/.bashrc
conda create -n jabari python=3.8 安装python3.8版本
# 创建环境
jupyter lab --generate-config
# 生成配置文件
Writing default config to: /root/.jupyter/jupyter_lab_config.py
[root@lavm-ba6po1r9fh bin]# vim /root/.jupyter/jupyter_lab_config.py
# 编辑配置文件
c.ServerApp.ip = '*' # 设置访问的IP地址
c.ServerApp.open_browser = False
# 不自动打开浏览器
c.ServerApp.port = 6888 #(自己可以自己设置端口,这里设置了6888)
# ServerApp的端口号
c.MappingKernelManager.root_dir = '/root/jupyter_run'
# 设置Jupyter Notebook的根文件夹
c.ServerApp.allow_remote_access = True
# 允许远程访问
c.ServerApp.password = ''
# 不设置登录密码
c.ServerApp.allow_origin='*'
# 允许任何来源的请求
c.ServerApp.password_required = False
# 不需要密码
c.ServerApp.token = ''
# 不设置验证token
jupyter lab --allow-root # 启动JupyterLab
之后,在本地浏览器输入"服务器ip:端口号"访问即可:
也可以安装汉化软件:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple jupyterlab-language-pack-zh-CN
三、重点来了:开始安装ChatGLM语言模型
https://huggingface.co/THUDM/chatglm-6b
ChatGLM-6B 是一个开源的、支持中英双语问答的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。ChatGLM-6B 使用了和 ChatGLM 相同的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答。

先安装语言依赖
pip install protobuf==3.20.0 transformers==4.27.1 icetk cpm_kernels

然后在jupyter运行代码
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
response, history = model.chat(tokenizer, "你好", history=[])
print(response)
response, history = model.chat(tokenizer, "晚上睡不着应该怎么办", history=history)
print(response)
这里会直接从huggingface.co下载
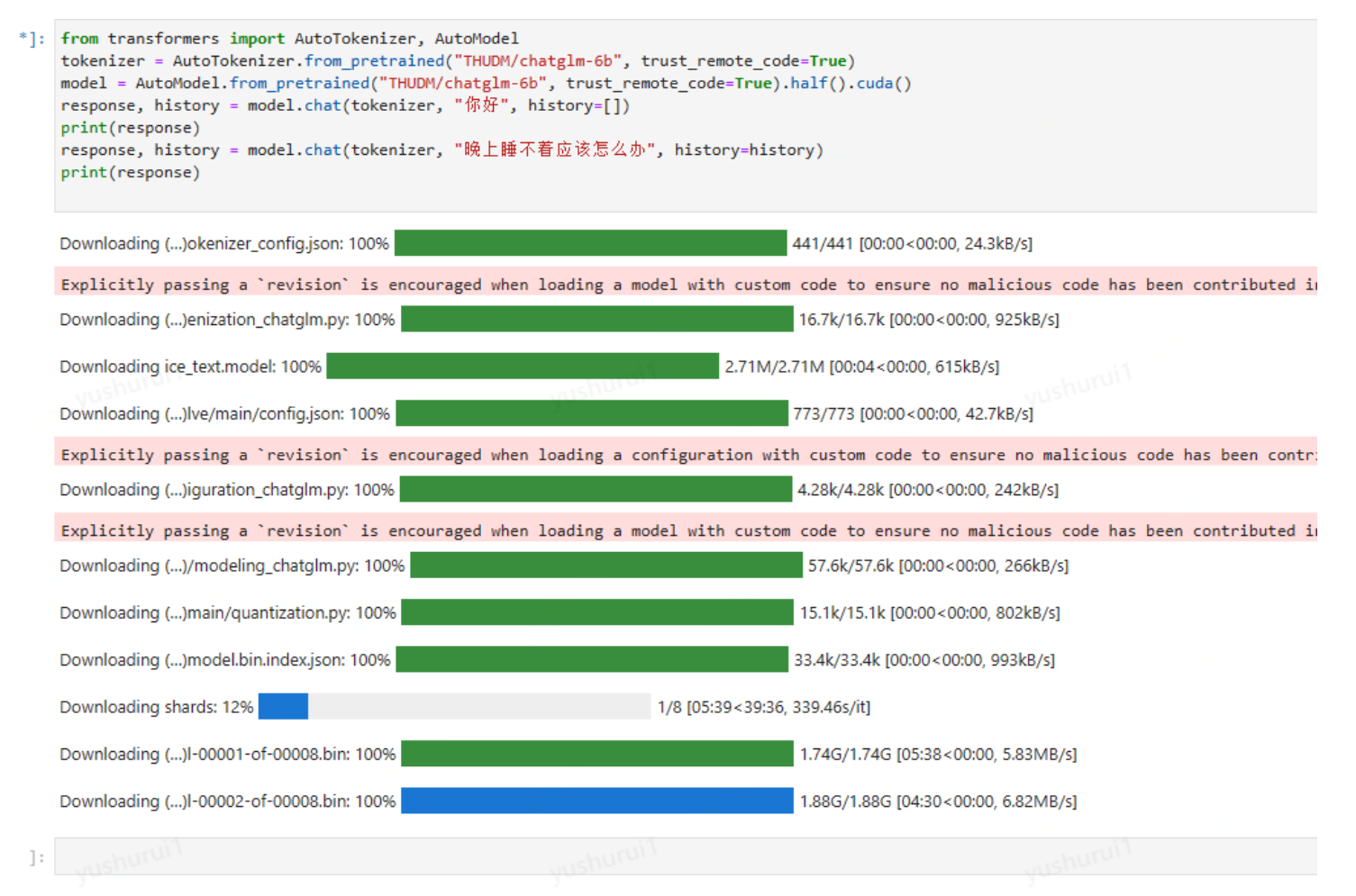
最终下载完后,再次运行,提示
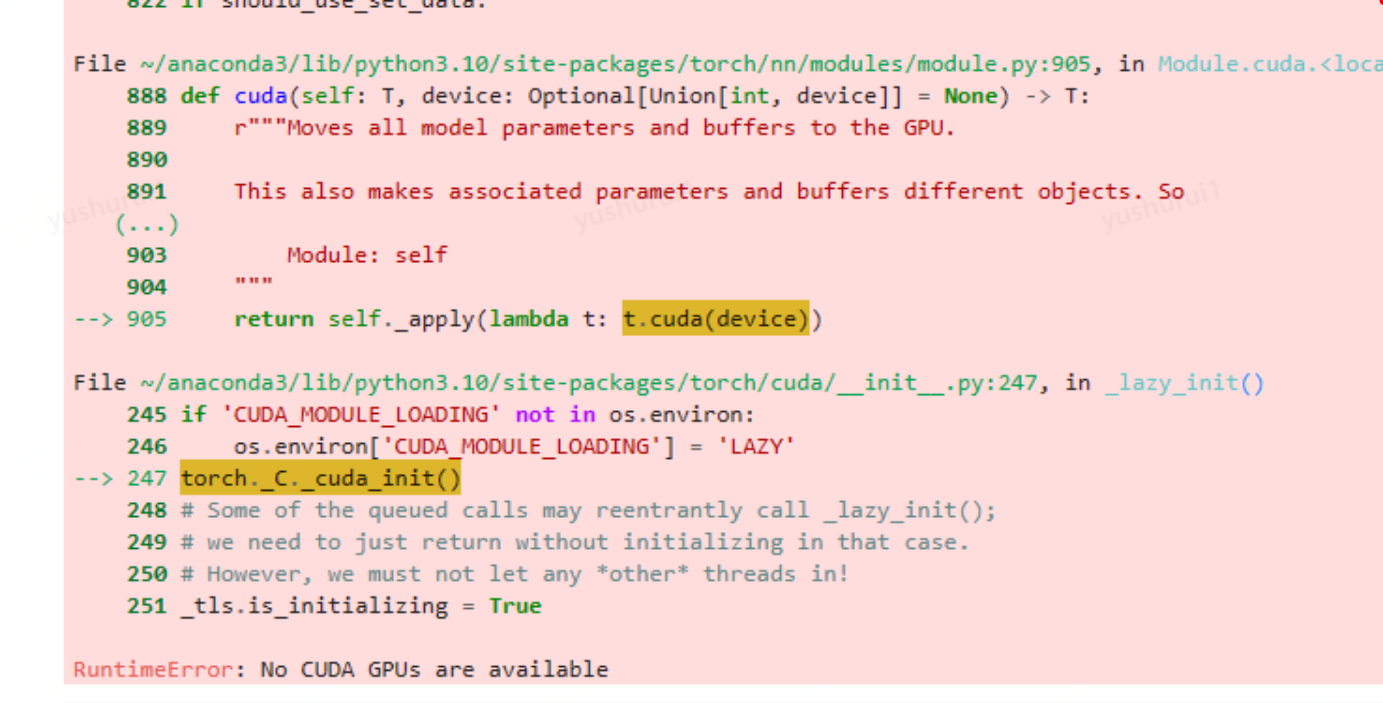
这里需要安装显卡驱动同时还要安装nvidia-cuda-toolkit
NVIDIA CUDA Toolkit 提供了一个开发环境,用于创建高性能 GPU 加速应用程序。
apt install nvidia-cuda-toolkit

再次运行,已经ok了,出现模型回复内容
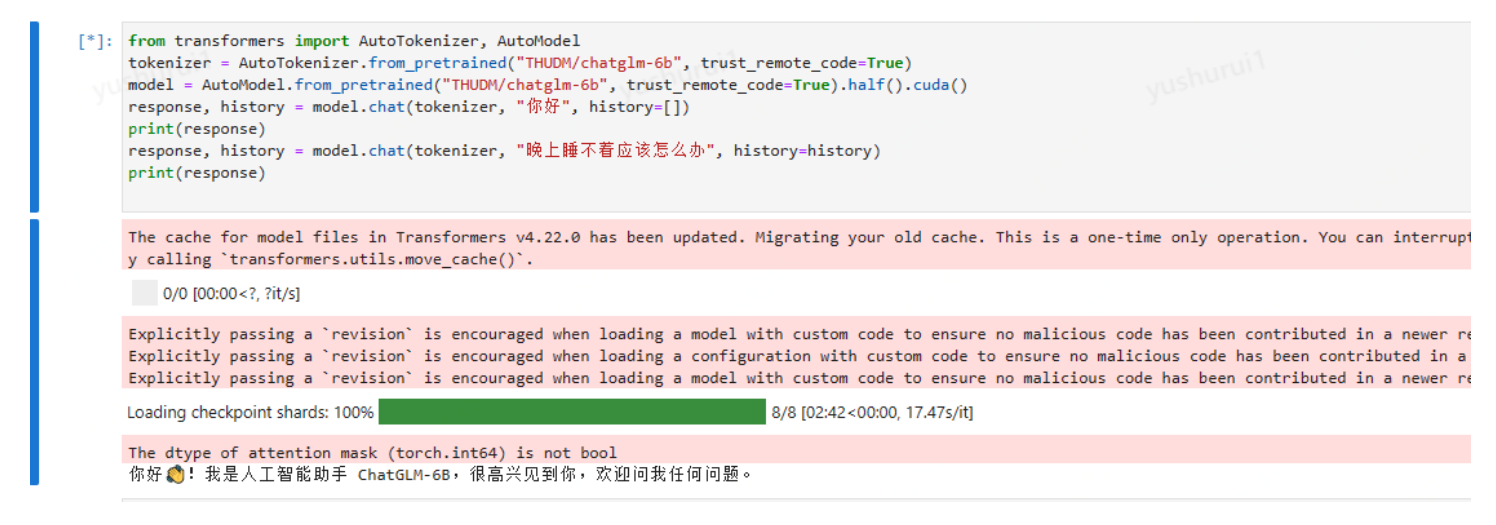
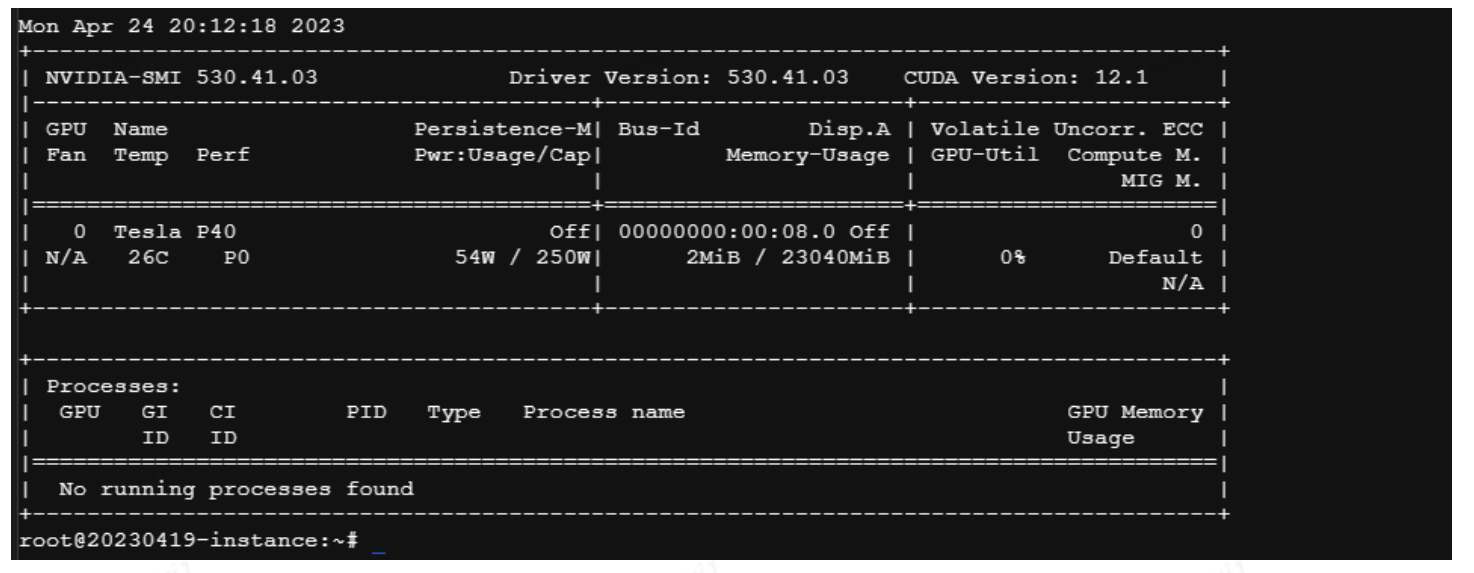
这里在命令行输入nvidia-smi 也看下显卡类型:
四、用Flask输出模型API
app.py的代码如下:
from gevent import pywsgi
from flask import Flask
from flask_restful import Resource, Api, reqparse
from transformers import AutoTokenizer, AutoModel
from flask_cors import CORS
app = Flask(__name__)
CORS(app, resources={r"/api/*": {"origins": "*"}})
api = Api(app)
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
parser = reqparse.RequestParser()
parser.add_argument('inputs', type=str, help='Inputs for chat')
parser.add_argument('history', type=str, action='append', help='Chat history')
class Chat(Resource):
def post(self):
args = parser.parse_args()
inputs = args['inputs']
history = args['history'] or []
response, new_history = model.chat(tokenizer, inputs, history)
return {'response': response, 'new_history': new_history}
api.add_resource(Chat, '/api/chat')
if __name__ == '__main__':
server = pywsgi.WSGIServer(('0.0.0.0', 80), app)
server.serve_forever()
最后在Terminal 里 执行python 目录地址/app.py

客户端,开发者可以通过API来获取数据:

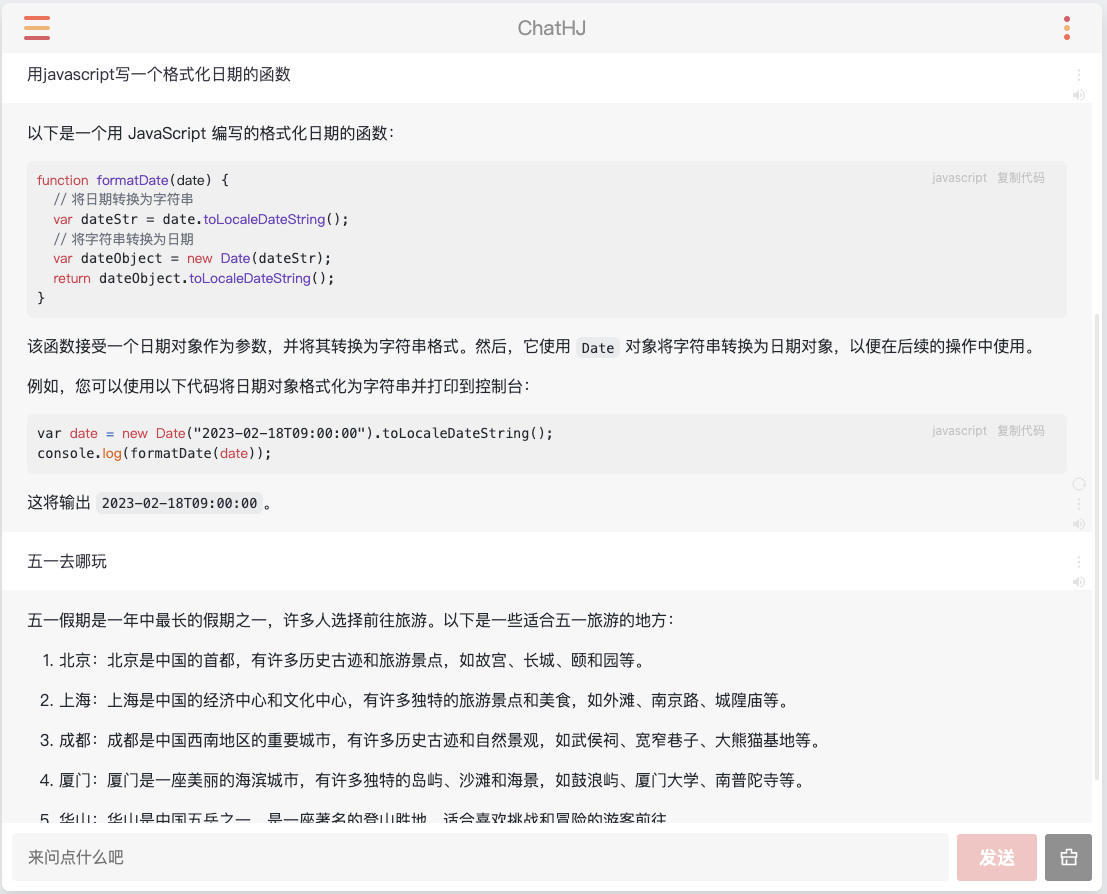
五、前端效果:问问五一去哪玩!
你可以自定义UI效果,比如胡老师用5分钟搞定的Demo——


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· CSnakes vs Python.NET:高效嵌入与灵活互通的跨语言方案对比
· DeepSeek “源神”启动!「GitHub 热点速览」
· 我与微信审核的“相爱相杀”看个人小程序副业
· Plotly.NET 一个为 .NET 打造的强大开源交互式图表库
· 上周热点回顾(2.17-2.23)