HBase底层存储结构和原理
1、数据存储结构
(1)逻辑结构
逻辑上是一张表,有行有列,但是物理上是k-v存储的。
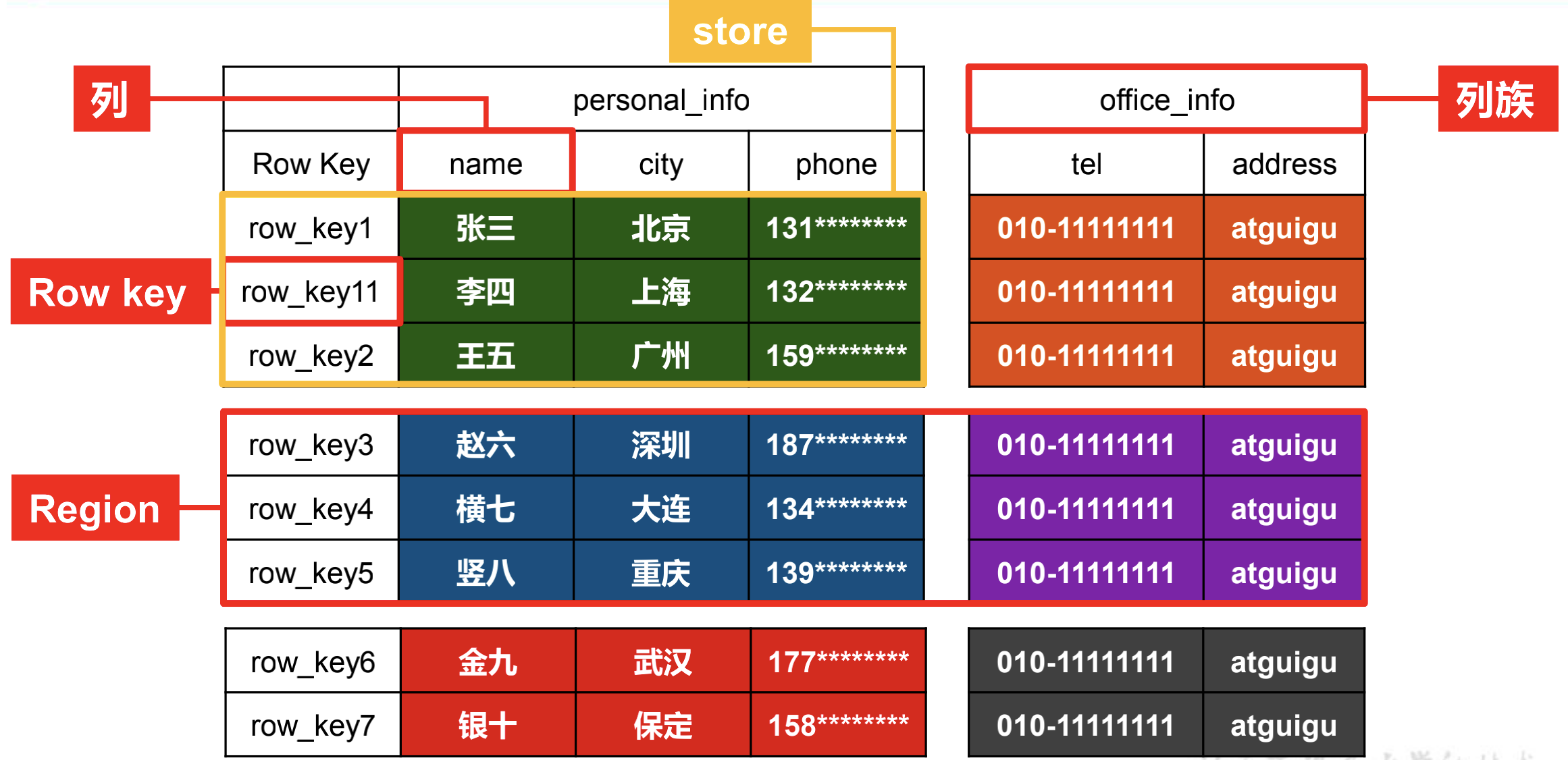
一个列族包含n个列,在屋里结构上一个列族就是一个文件夹。一个文件夹中包好多个store文件。
rowKey又叫行键,它是有序的(字典顺序)。
来看下它的数据模型:
(2)物理结构
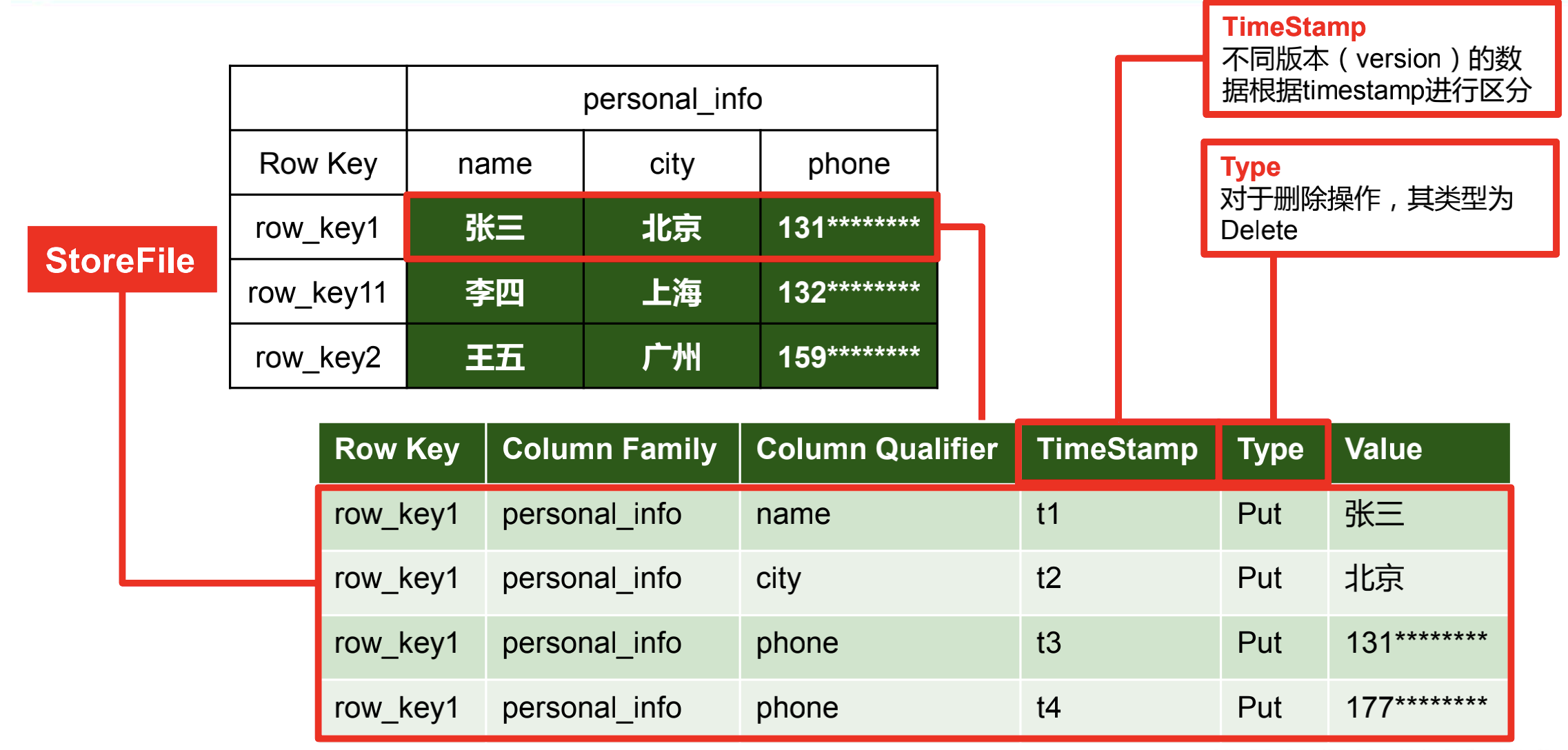
HBase在屋里上就是种种k-v存储的,实现在HDFS上随机写操作,就是通过timeStamp来进行版本控制实现的。这种存储方式很好地解决了稀疏性问题,因为空值不会占据存储空间,不像MySQL那样NULL值也要值一定的存储空间。
2、系统架构
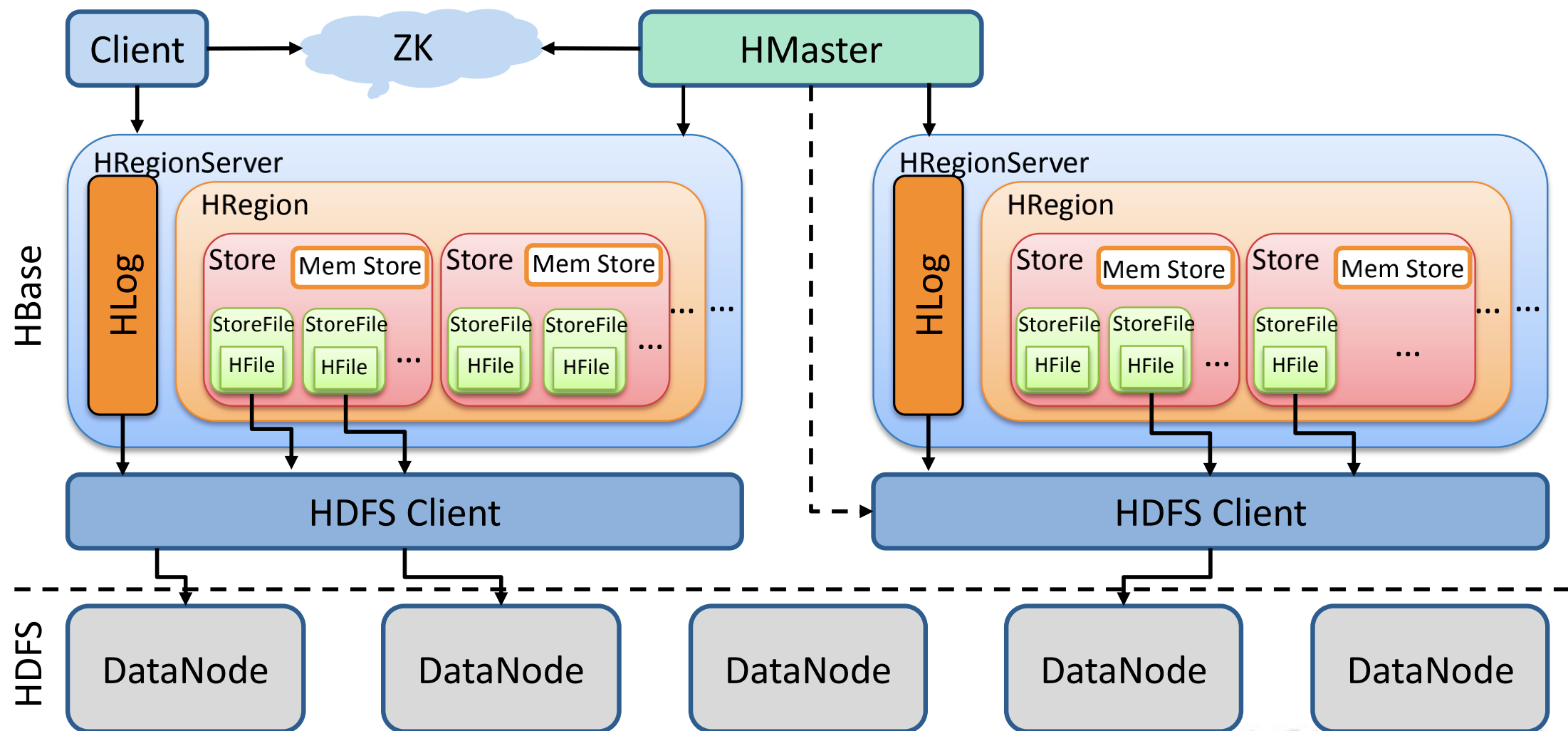
架构角色:
3、运行原理
(1)写数据流程
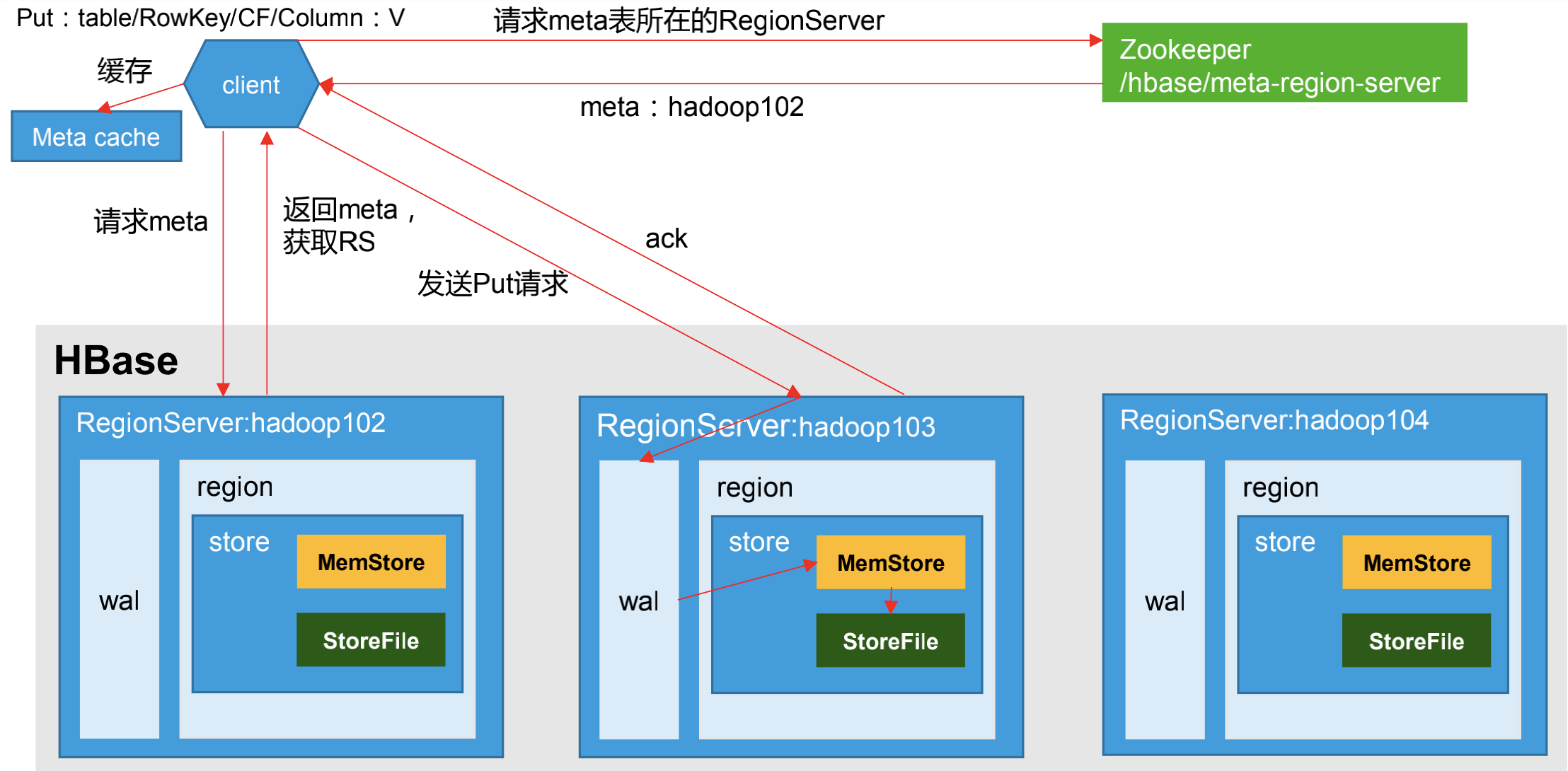
1)Client 先访问 zookeeper,获取 hbase:meta 表位于哪个 Region Server。
说明:写入数据时,逻辑顺序是先写入到WAL(HLog),再写入memStore,但实际源码流程如下:使用事务回滚机制来确保WAL和memStore同步写入。
1)先获取锁(JUC),保证数据不会写入成功前数据不会被查询到
2)更新时间戳(数据中没定义时间戳则使用系统时间),集群中个HRegionServer的系统时间误差不能超过配置时间,否则集群启动不成功
3)内存中构建WAL
4)将构建的WAL追加到最后写入的WAL,此时不会将WAL同步到HDFS中的HLog中
5)将数据写入到memStore
6)释放锁
7)同步WAL到HLog,如果同步失败,会回滚memStore(通过doRollBackMemstore=false控制)
8)9).........
(2)MemStore刷写(flush)
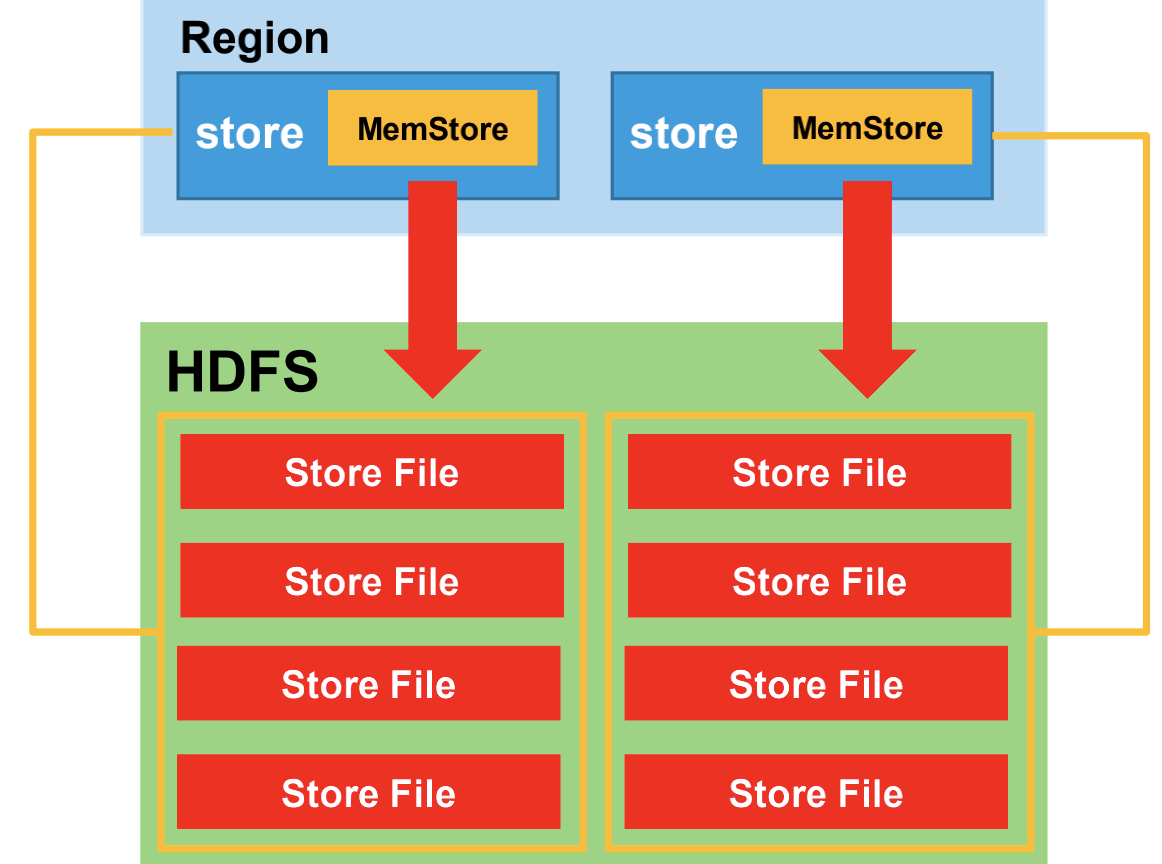
第一种触发条件:(Region级别Flush)
当某个 memstroe 的大小达到了 hbase.hregion.memstore.flush.size(默认值 128M),其所在 region 的所有 memstore 都会刷写。
如果写入速度太快超过了刷写速度,当 memstore 的大小达到了 hbase.hregion.memstore.flush.size * hbase.hregion.memstore.block.multiplier(默认值 4)大小时,会触发所有memstore 刷写并阻塞 Region 所有的写请求,
此时写数据会出现 RegionTooBusyException 异常。
<!-- 单个region里memstore的缓存大小,超过那么整个HRegion就会flush,默认128M --> <property> <name>hbase.hregion.memstore.flush.size</name> <value>134217728</value> <description> Memstore will be flushed to disk if size of the memstore exceeds this number of bytes. Value is checked by a thread that runs every hbase.server.thread.wakefrequency. </description> </property> <!-- 当一个HRegion上的memstore的大小满足hbase.hregion.memstore.block.multiplier * hbase.hregion.memstore.flush.size, 这个HRegion会执行flush操作并阻塞对该HRegion的写入 --> <property> <name>hbase.hregion.memstore.block.multiplier</name> <value>4</value> <description> Block updates if memstore has hbase.hregion.memstore.block.multiplier times hbase.hregion.memstore.flush.size bytes. Useful preventing runaway memstore during spikes in update traffic. Without an upper-bound, memstore fills such that when it flushes the resultant flush files take a long time to compact or split, or worse, we OOME. </description> </property>
第二种触发条件:(RegionServer级别Flush)
当 regionServer 中 memstore 的总大小达到 java_heapsize(堆内存)* hbase.regionserver.global.memstore.size(默认值 0.4)* hbase.regionserver.global.memstore.size.lower.limit(默认值 0.95),
region 会按照其所有 memstore 的大小顺序(由大到小)依次进行刷写。直到 regionServer 中所有 memstore 的总大小减小到上述值以下。
<!-- regionServer的全局memstore的大小,超过该大小会触发flush到磁盘的操作,默认是堆大小的40%,而且regionserver级别的 flush会阻塞客户端读写。如果RegionServer的堆内存设置为2G,则memstore总内存大小为 2 * 0.4 = 0.8G--> <property> <name>hbase.regionserver.global.memstore.size</name> <value></value> <description>Maximum size of all memstores in a region server before new updates are blocked and flushes are forced. Defaults to 40% of heap (0.4). Updates are blocked and flushes are forced until size of all memstores in a region server hits hbase.regionserver.global.memstore.size.lower.limit. The default value in this configuration has been intentionally left emtpy in order to honor the old hbase.regionserver.global.memstore.upperLimit property if present. </description> </property> <!--可以理解为一个安全的设置,有时候集群的“写负载”非常高,写入量一直超过flush的量,这时,我们就希望memstore不要超过一定的安全设置。 在这种情况下,写操作就要被阻塞一直到memstore恢复到一个“可管理”的大小, 这个大小就是默认值是堆大小 * 0.4 * 0.95,也就是当regionserver级别 的flush操作发送后,会阻塞客户端写,一直阻塞到整个regionserver级别的memstore的大小为 堆大小 * 0.4 *0.95为止 --> <property> <name>hbase.regionserver.global.memstore.size.lower.limit</name> <value></value> <description>Maximum size of all memstores in a region server before flushes are forced. Defaults to 95% of hbase.regionserver.global.memstore.size (0.95). A 100% value for this value causes the minimum possible flushing to occur when updates are blocked due to memstore limiting. The default value in this configuration has been intentionally left emtpy in order to honor the old hbase.regionserver.global.memstore.lowerLimit property if present. </description> </property>
第三种触发条件:(RegionServer级别Flush)
定期 hbase.regionserver.optionalcacheflushinterval(默认3600000即一个小时)进行 MemStore 的刷写,确保 MemStore 不会长时间没有持久化。为避免所有的 MemStore 在同一时间进行 flush 而导致问题,
定期的 flush 操作会有一定时间的随机延时。
第四种触发条件:(Region级别Flush)
第五种触发条件:
默认值 128M,单个 MemStore 大小超过该阈值就会触发 Flush。如果当前集群 Flush 比较频繁,并且内存资源比较充裕,建议适当调整为 256M。调大的副作用可能是造成宕机时需要分裂的 HLog 数量变多,从而延长故障恢复时间。
• hbase.hregion.memstore.block.multiplier
默认值 4,Region 中所有 MemStore 超过单个 MemStore 大小的倍数达到该参数值时,就会阻塞写请求并强制 Flush。一般不建议调整,但对于写入过快且内存充裕的场景,为避免写阻塞,可以适当调整到5~8。
• hbase.regionserver.global.memstore.size
默认值 0.4,RegionServer 中所有 MemStore 大小总和最多占 RegionServer 堆内存的 40%。这是写缓存的总比例,可以根据实际场景适当调整,且要与 HBase 读缓存参数 hfile.block.cache.size(默认也是0.4)配合调整。旧版本参数名称为 hbase.regionserver.global.memstore.upperLimit。
• hbase.regionserver.global.memstore.size.lower.limit
默认值 0.95,表示 RegionServer 中所有 MemStore 大小的低水位是 hbase.regionserver.global.memstore.size 的 95%,超过该比例就会强制 Flush。一般不建议调整。旧版本参数名称为 hbase.regionserver.global.memstore.lowerLimit。
• hbase.regionserver.optionalcacheflushinterval
默认值 3600000(即 1 小时),HBase 定期 Flush 所有 MemStore 的时间间隔。一般建议调大,比如 10 小时,因为很多场景下 1 小时 Flush 一次会产生很多小文件,一方面导致 Flush 比较频繁,另一方面导致小文件很多,影响随机读性能,因此建议设置较大值。
(3)读流程
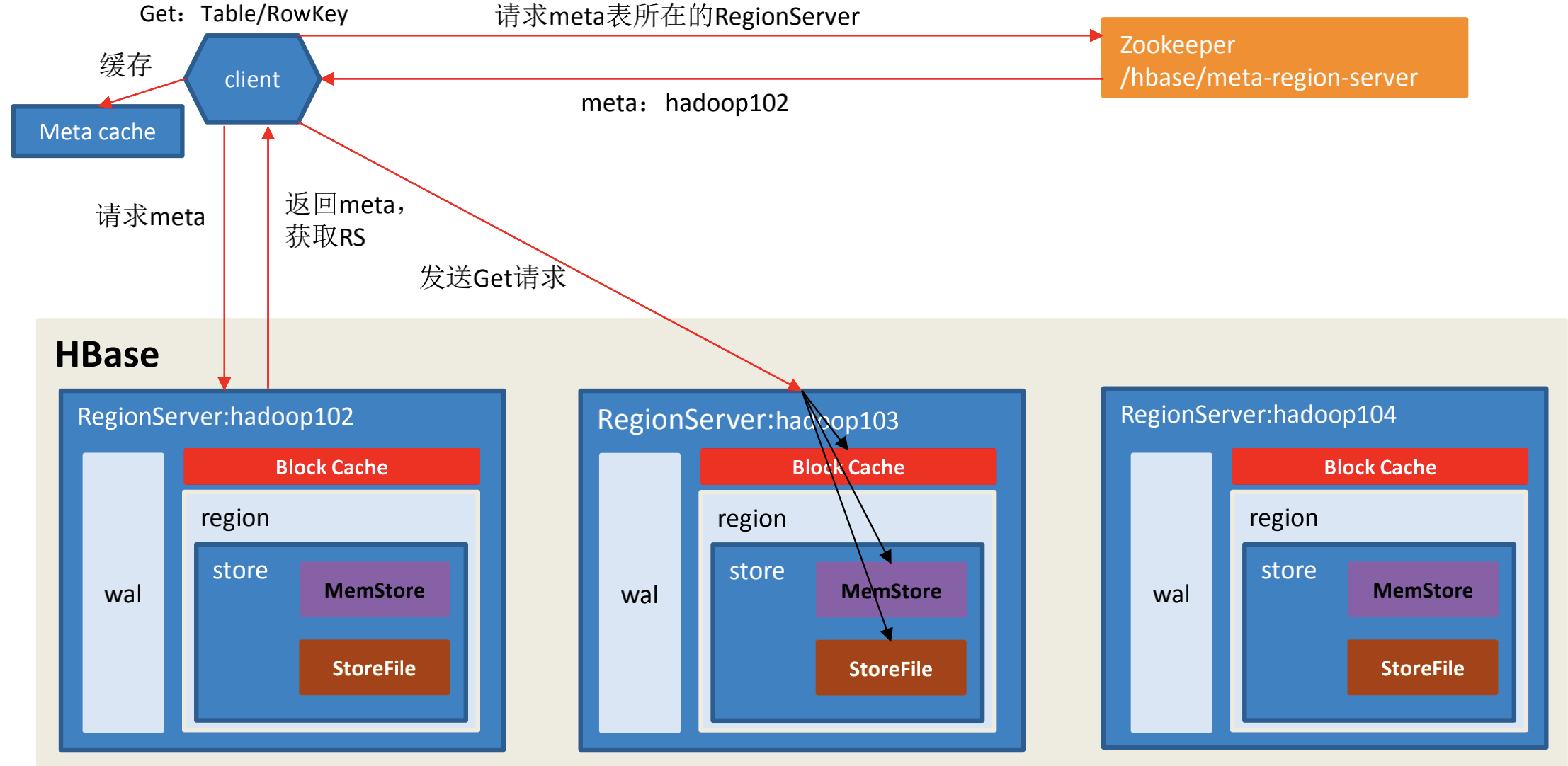
1)Client 先访问 zookeeper,获取 hbase:meta 表位于哪个 Region Server。
2)访问对应的 Region Server,获取 hbase:meta 表,根据读请求的 namespace:table/rowkey,查询出目标数据位于哪个 Region Server 中的哪个 Region 中。并将该 table 的 region 信息以
(4)StoreFile合并(Compaction)
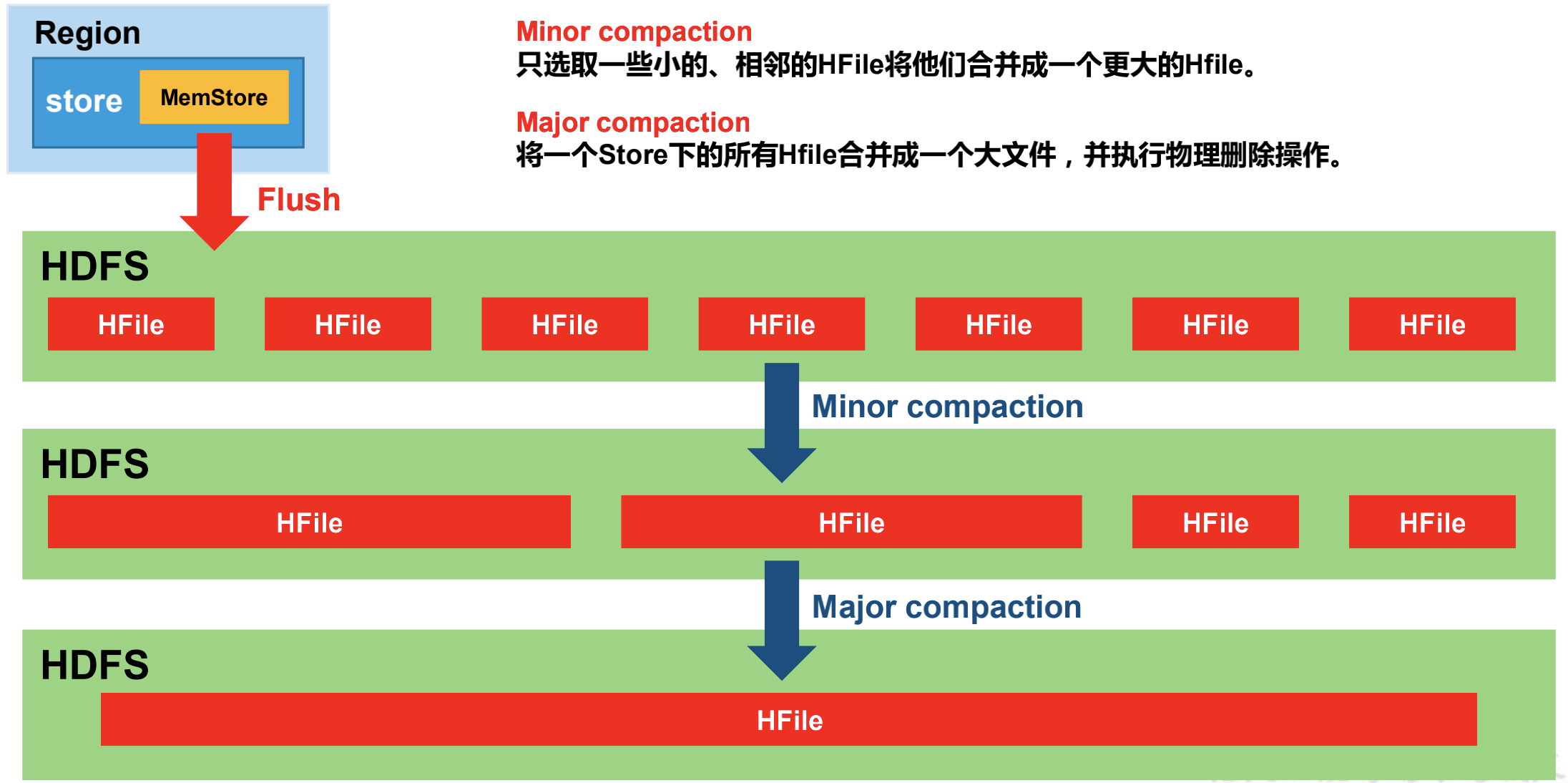
Minor Compaction 是指选取一些小的、相邻的 HFile 将他们合并成一个更大的 HFile。默认情况下,Minor Compaction 会删除所合并 HFile 中的 TTL 过期数据,但是不会删除手动删除(也就是 Delete 标记作用的数据)不会被删除。
概括的说,HBase 会在三种情况下检查是否要触发 Compaction,分别是 MemStore Flush、后台线程周期性检查、手动触发。
- MemStore Flush:可以说 Compaction 的根源就在于Flush,MemStore 达到一定阈值或触发条件就会执行 Flush 操作,在磁盘上生成 HFile 文件,正是因为 HFile 文件越来越多才需要 Compact。HBase 每次Flush 之后,都会判断是否要进行 Compaction,一旦满足 Minor Compaction 或 Major Compaction 的条件便会触发执行。
- 后台线程周期性检查: 后台线程 CompactionChecker 会定期检查是否需要执行 Compaction,检查周期为 hbase.server.thread.wakefrequency * hbase.server.compactchecker.interval.multiplier,这里主要考虑的是一段时间内没有写入仍然需要做 Compact 检查。其中参数 hbase.server.thread.wakefrequency 默认值 10000 即 10s,是 HBase 服务端线程唤醒时间间隔,用于 LogRoller、MemStoreFlusher 等的周期性检查;参数 hbase.server.compactchecker.interval.multiplier 默认值1000,是 Compaction 操作周期性检查乘数因子,10 * 1000 s 时间上约等于2hrs, 46mins, 40sec。
- 手动触发:通过 HBase Shell、Master UI 界面或 HBase API 等任一种方式执行 compact、major_compact等命令,会立即触发 Compaction。
• hbase.hstore.compaction.min
默认值 3,一个 Store 中 HFile 文件数量超过该阈值就会触发一次 Compaction(Minor Compaction),这里称该参数为 minFilesToCompact。一般不建议调小,重写场景下可以调大该参数,比如 5~10 之间,
注意相应调整下一个参数。老版本参数名称为 hbase.hstore.compactionthreshold。
• hbase.hstore.compaction.max
默认值 10,一次 Minor Compaction 最多合并的 HFile 文件数量,这里称该参数为 maxFilesToCompact。这个参数也控制着一次压缩的耗时。一般不建议调整,但如果上一个参数调整了,该参数也应该相应调整,
一般设为 minFilesToCompact 的 2~3 倍。
• hbase.regionserver.thread.compaction.throttle
HBase RegionServer 内部设计了两个线程池 large compactions 与 small compactions,用来分离处理 Compaction 操作,该参数就是控制一个 Compaction 交由哪一个线程池处理,
默认值是 2 * maxFilesToCompact * hbase.hregion.memstore.flush.size(默认2*10*128M=2560M即2.5G),建议不调整或稍微调大。
• hbase.regionserver.thread.compaction.large/small
默认值 1,表示 large compactions 与 small compactions 线程池的大小。一般建议调整到 2~5,不建议再调太大比如10,否则可能会消费过多的服务端资源造成不良影响。
• hbase.hstore.blockingStoreFiles
<!-- 每个store阻塞更新请求的阀值,表示如果当前hstore中文件数大于该值,系统将会强制执行compaction操作进行文件合并, 合并的过程会阻塞整个hstore的写入,这样有个好处是避免compaction操作赶不上Hfile文件的生成速率 --> <property> <name>hbase.hstore.blockingStoreFiles</name> <value>10</value> <description> If more than this number of StoreFiles in any one Store (one StoreFile is written per flush of MemStore) then updates are blocked for this HRegion until a compaction is completed, or until hbase.hstore.blockingWaitTime has been exceeded. </description> </property>
默认值 10,表示一个 Store 中 HFile 文件数量达到该值就会阻塞写入,等待 Compaction 的完成。一般建议调大点,比如设置为 100,避免出现阻塞更新的情况,阻塞日志如下:
too many store files; delaying flush up to 90000ms
生产环境建议认真根据实际业务量做好集群规模评估,如果小集群遇到了持续写入过快的场景,合理扩展集群也非常重要。
(5)数据切分(Split)
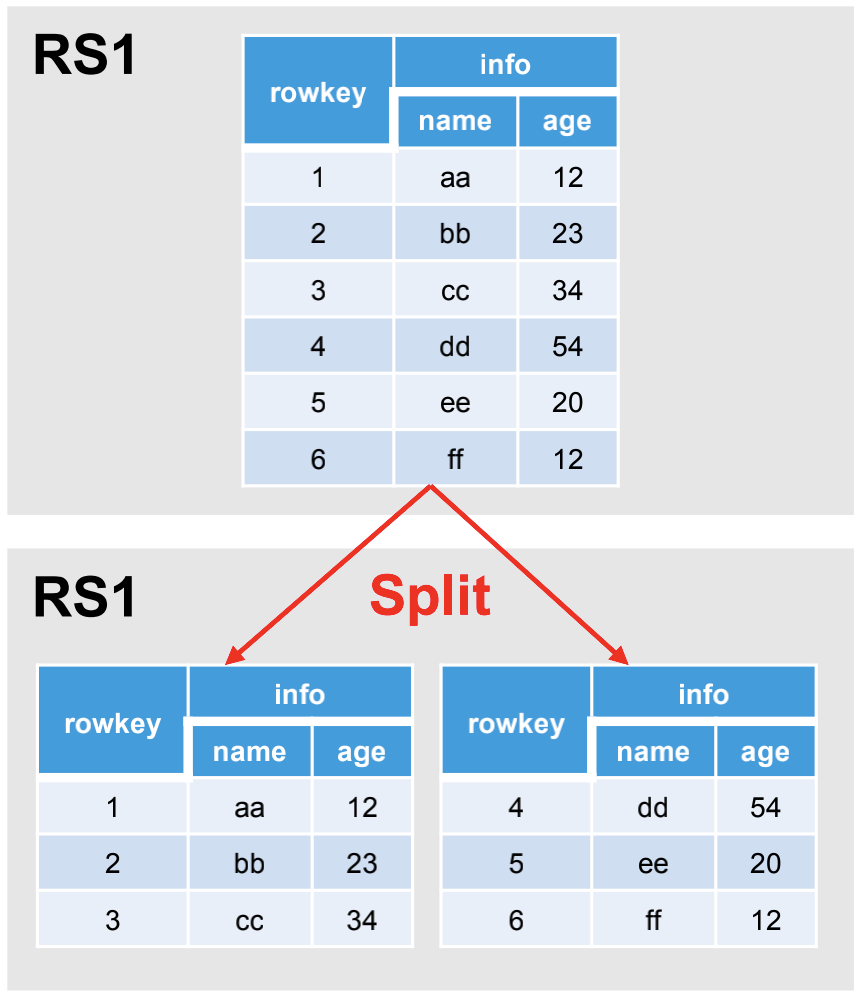
默认情况下,每个 Table 起初只有一个 Region,随着数据的不断写入,Region 会自动进行拆分。刚拆分时,两个子 Region 都位于当前的 Region Server,但处于负载均衡的考虑,HMaster 有可能会将某个 Region 转移给其他的 Region Server。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号