volatile关键字——数据可见性问题
1、缓存一致性问题
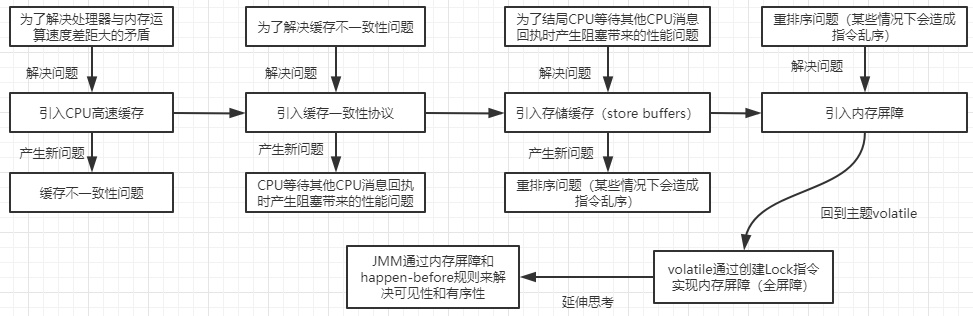
由于存储设备与处理器的运算速度差距很大,计算机系统在内存与处理器之间增加了一层高速缓存,将运算需要的数据复制到缓存中,让运算能快速进行。
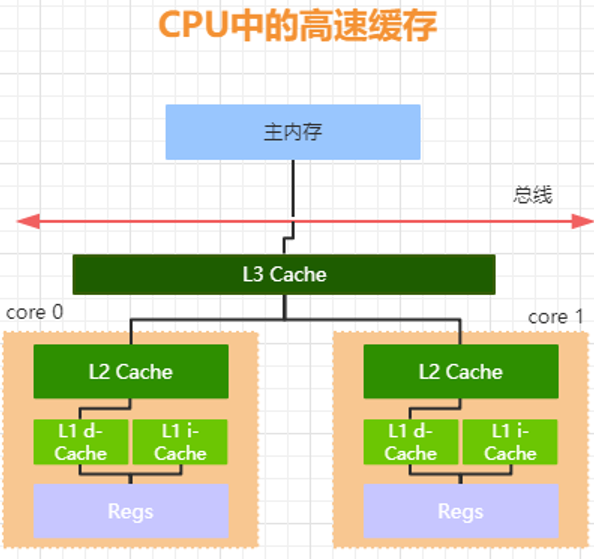
有了高速缓存的存在以后,每个CPU的处理过程是, 先将计算需要用到的数据缓存在CPU高速缓存中,在CPU 进行计算时,直接从高速缓存中读取数据并且在计算完成 之后写入到缓存中。在整个运算过程完成后,再把缓存中 的数据同步到主内存。
通过高速缓存很好解决了处理器与内存处理速度的矛盾,但是也带来了缓存一致性问题:不同的线程可能运行在不同的CPU内,同一个数据也会被缓存到多个CPU中,在不同CPU中运行的不同线程看到的同一份内存数据的不同值,这就是缓存一致性问题。
2、缓存锁——缓存一致性协议
为了解决缓存一致性问题,引入了缓存锁,缓存锁的核心机制就是缓存一致性协议。常见的就是MESI协议,MESI表示缓存行的四种状态:
* M(modify)表示共享数据只缓存在当前 CPU 缓存中, 并且是被修改状态,也就是缓存的数据和主内存中的数据不一致。
* E(exclusive)表示缓存的独占状态,数据只缓存在当前 CPU缓存中,并且没有被修改 。
* S(shared)表示数据可能被多个CPU缓存,并且各个缓 存中的数据和主内存数据一致。
* I(invalid)表示缓存已失效。
在 MESI 协议中,每个缓存的缓存控制器不仅知道自己的读写操作,而且也监听(snoop)其它Cache的读写操作。各缓存通过状态机制来实现数据的一致性。
MESI协议带来的问题:就是各个CPU缓存行的状态是通过消息传递来进行的。如果 CPU0 要对一个在缓存中共享的变量进行写入,首先需要发送一个失效的消息给到其他缓存了该数据的CPU。并且要等到他们的确认回执。CPU0 在这段时间内都会处于阻塞状态。为了避免阻塞带来的资源浪费。在cpu中引入了Store Bufferes。
3、store buffers(存储缓存)
CPU在写入共享数据时,直接把数据写入到store bufferes中,同时发送invalidate消息,然后继续去处理其 他指令。当收到其他所有CPU发送了invalidate acknowledge消息 时,再将 store bufferes 中的数据数据存储至 cache line 中。最后再从缓存行同步到主内存。

store buffers带来的问题:引入了storebufferes后,CPU会优先从store buffers中读取数据,这在一些情况下会导致CPU的乱序执行,也可以认为是一种重排序,这种重排序会带来可见性问题。
4、CPU层面的内存屏障
为了防止store buffers造成的CPU对内存的乱序访问,引入内存屏障来保证数据的可见性。
CPU层面的内存屏障包括读屏障、写屏障、全屏障:
* 写屏障:告诉处理器在写屏障之前的所有已经存储到存储缓存(store buffers)中的数据同步到主内存。
* 读屏障:使高速缓存中的数据失效,强制从主内存中读取数据。
* 全屏障:读屏障+写屏障。
volatile关键字会生成一个Lock汇编指令,这个指令就相当于实现了内存屏障。
5、java内存模型(JMM)
JMM属于语言级别的抽象内存模型,它定义了共享内存中多线程程序读写操作 的行为规范:在虚拟机中把共享变量存储到内存以及从内存中取出共享变量的底层实现细节,通过这些规则来规范对内存的读写操作从而保证指令的正 确性,它解决了CPU多级缓存、处理器优化、指令重排序 导致的内存访问问题,保证了并发场景下的可见性。JMM并没有限制处理器高速缓存和指令重排序,而是在JVM层面通过内存屏障指令和happen-before规则来解决可见性问题,volatile就是其中一种方式。
6、总结
从上面分析可以得出,导致数据可见性问题点额根本原因是:CPU高速缓存以及重排序。
7、注意点
volatile只是解决可见性,并没有解决原子性,它的可见性是针对一个原子操作。所以多线程情景下对volatile修饰的变量进行运算是不安全的,如:
volatile int arg;
在多线程下执行arg的加减乘除等运算或是arg++等,会出现混乱,因为这种运算是非原子的,如arg++是分为三步:获取arg,arg+1,将运算后的结果赋值给arg。所以这种情况下可以使用volatile AutoInteger arg,AutoInteger的原子性是基于cas实现的。
如下简单的例子即可说明:
private volatile static int num = 0;
public static void main(String[] args) {
new Thread(()->{
num+=1;
System.out.println("thread 1——"+num);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
num+=1;
System.out.println("thread 1——"+num);
}).start();
new Thread(()->{
num+=1;
System.out.println("thread 2——"+num);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
num+=1;
System.out.println("thread 2——"+num);
}).start();
}
输出结果:

8、使用场景
volatile是通过告诉CPU在读取数据时不从存储缓存中取,而是到主内存中读取,这样就保证了数据的可见性,同时也避免了指令重排。正确使用它有两个必要条件:
• 写入变量不依赖当前值:变量的新值不能依赖于之前的旧值。如果变量的当前值与新值之间存在依赖关系,那么仅使用 volatile 是不够的,因为它不能保证一系列操作的原子性。比如 i++。
• 变量不参与与其他变量的不变性条件:如果一个变量是与其他变量共同参与不变性条件的一部分,那么简单地声明变量为 volatile 是不够的。如 a + b = 10,只设其中一个为volatile是不行的。
volatile比较适合多个线程读,一个线程写的场景,比如以下几种:
(1)状态标志
当我们需要用一个变量来作为状态标志,控制线程的执行流程时,使用 volatile 可以确保当一个线程修改了这个标志时,其他线程能够立即看到最新的值。
public class TaskRunner implements Runnable { private volatile boolean running = true; // 状态标志,控制任务是否继续执行 public void run() { while (running) { // 检查状态标志 // 执行任务 doSomething(); } } public void stop() { running = false; // 修改状态标志,使得线程能够停止执行 } private void doSomething() { // 实际任务逻辑 } }
(2)双重检查的单例模式
其实这也算一种状态标志的使用。
public class Singleton { // 使用 volatile 保证实例的可见性和有序性 private static volatile Singleton instance; private Singleton() { } public static Singleton getInstance() { if (instance == null) { // 第一次检查,避免不必要的同步 synchronized (Singleton.class) { // 锁定 if (instance == null) { // 第二次检查,确保只创建一次实例 instance = new Singleton(); } } } return instance; } }
(3)类似“读-写锁”的读多写少场景
“读-写锁”非常适合读多写少的场景,可以利用 volatile + 锁的机制减少公共代码路径的开销。
public class VolatileTest { private volatile int value; //读,不加锁,提供效率 public int getValue() { return value; } //写操作,使用锁,保证线程安全 public synchronized int increment() { return value++; } }
最后推荐两篇文章:
一篇是讲volatile可见性的:https://www.toutiao.com/i6845877313154843148/
一篇是讲volatile顺序性的:https://www.toutiao.com/i6848517661425402380/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号