

OO第一单元总结
OO第一单元总结
一、总体思路
(一)表达式的解析
这三次作业,表达式的解析思路都是相同的,变的只是因子的种类以及限制条件,所以总体的架构基本保持不变。对于表达式的解析,我采取的是按表达式、项、因子层层解析的结构。表达式即用加减号连接起来的项;项即用乘号连接的因子;而因子则是最有趣的,因为不但有常量、幂函数因子,表达式也算是一种因子。这样就形成了一种树形结构,只不过树的结点有两种,一种是因子(包括表达式),另一种是项。那么很自然就可以想到让所有的因子都实现一个Factor接口或者继承Factor类,这样表达式的解析就等价于将输入的表达式一层层拆分为项(Term)和因子(Factor)。
(二)迭代开发
以上所说的思路虽然是基于第一次作业,但稍微想想就能发现,在此基础上扩展是比较简便的。比如第二次作业,增加了三角函数、自定义函数、求和函数,那我们只要将自定义函数和求和函数提前处理掉,增加三角函数这种因子,得到的还是同样的树型结构。再比如第三次作业,增加了括号和自定义函数的嵌套,那只需要在递归向下解析的过程中去括号和自定义函数,自定义函数在代入具体的参数后其实也就是个表达式,所以处理自定义函数可以分为两步,第一步将参数代入,第二步当成表达式处理。所以这三次作业归根结底都逃不过这种架构,无非是因子数量的增加。
(三)计算和化简
要想将解析出来的表达式最终化简还需要为所有的项和因子找到一个基准项,任何项和因子都能写成基准项的和。在第一次作业中,基准项为:\(ax^b\);第二次和第三次作业中的基准项为:\(ax^b\Pi sin(f(x_i))\Pi cos(g(x_i))\)。有了基准项,我们的计算和化简就能够进行了。
计算无非就是系数的加减乘,指数的加,三角函数的合并。所以要先实现两个基准项的加减乘,再扩展到一个基准项乘多个基准项的和(一×多),最后再扩展到多×多。那么只需要在解析完毕后调用相应的函数就可以了,整个计算的过程恰好是递归向下的逆过程。
关于在何时化简,有两种思路,一种是边计算边化简,一种是计算完毕后一起化简。这两种方法我都试过,我个人觉得各有优劣,就性能而言肯定是边计算边化简速度快,但这样的缺点就是要注意的地方很多,容易出bug。而计算完毕后一起化简算法相对简单,规避了很多可能存在的问题,之后在bug部分会讲到。化简主要包括系数的合并,三角函数指数的合并,如果再考虑多一点的话还可以结合三角函数的性质化简,这里就不细说了。
二、具体实现
具体实现部分我就直接使用第三次作业的代码来分析,类图中只展示了一些重要的属性和方法。
(一)预处理
这是预处理的类图:
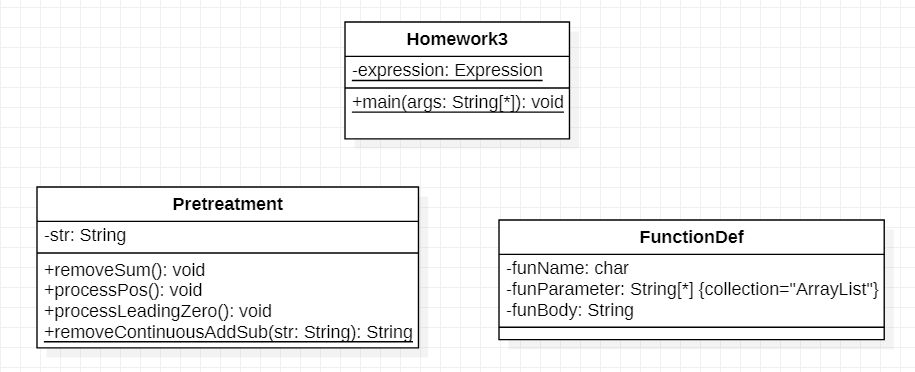
Homework3是主类,其中定义了输入的表达式expression。
输入函数时,用FunctionDef类来处理,这个类会读入函数表达式,将表达式拆分为函数名、函数参数、函数体三部分,如类图所示的三个私有属性。
而Pretreatment类是预处理表达式的类,其中定义了一些重要的方法:
removeContinuousAddSub():用于处理连续的加减号
processPos():用于处理多余的加号
processLeadingZero():用于处理前导零
removeSum():用于处理sum求和函数,将sum展开
之所以将这些方法单独用一个预处理类,是因为这些处理只需要进行一次,采用预处理会使之后的解析方便许多
(二)解析表达式
这是整个数据结构的类图:
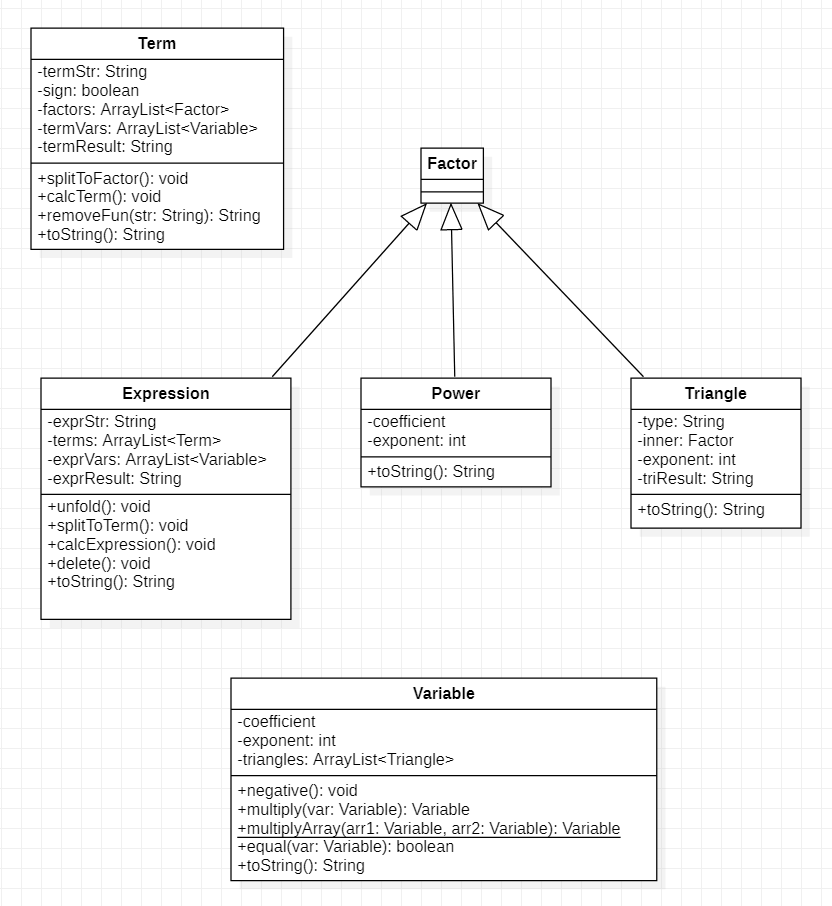
正如之前的设计逻辑,数据结构分为项和因子,因子包括表达式、幂函数(幂函数包括了常数)、三角函数。那我们就来逐个看看类的内部是如何设计的。
1. 解析算法
- Term类:在构造Term类时会传入一个字符串,Term将其保存在termStr里。factors表示项中包含的因子,在构造函数中会调用方法splitToFactor,从而将解析出的因子存入factors。根据因子类型的不同,在构造因子时调用的构造方法也不同:
- 幂函数因子:调用幂函数因子的构造方法,传入该幂函数的字符串。
- 三角函数因子:调用三角函数因子的构造方法,传入该三角函数的字符串。
- 表达式因子:调用表达式因子的构造方法,传入去掉括号后的字符串。
- 自定义函数因子:调用方法removeFun将自定义函数转化为字符串,再调用表达式因子的构造方法。
- Factor类:里面什么都没有写,单独作为一个父类。
- Expression类:在构造时传入一个字符串,Expression将其保存在exprStr里。terms表示表达式中包含的项,在构造方法中先调用unfold展开当前表达式最外层括号后面的指数,然后调用splitToTerm解析出表达式中的项。根据项前的符号不同,可以分为两类:
- 如果前面是加号:设置Term的sign属性为true,代表这一项为正。
- 如果前面是负号:设置Term的sign属性为false,代表这一项为负。
- Power类:在构造时,将传入的字符串解析为系数和指数信息并存入私有属性coefficient和exponent中。
- Triangle类:从传入的字符串中解析出三角函数名、三角函数内部的表达式、指数。三角函数的内部表达式也是一个因子,又会调用相关因子的构造函数。
2. 基准项
在类图中可以看到Variable类,类中的属性有系数、指数和三角函数,这便是基准项,所有的项、表达式都可以表示成基准项的和,从而进行计算和化简。在基准项Variable中定义了一些重要的方法:
- negative方法:当Term的sign属性为false时,用于对系数取反。
- multiply方法:该方法为两个Variable相乘时调用的方法,返回结果也为Variable。
- multiplyArray方法:该方法为多个Variable乘多个Variable的方法,设置为静态方法方便调用,返回值也为Variable集合。该方法其实是通过在内部循环调用multiply方法实现的。
- equal方法:用于判断两个Variable是否可以合并,内部通过判断指数和三角函数确定是否相等,其中三角函数是通过直接比较字符串。
3. 计算
如果我们把整个解析表达式看成是一颗树的话,那么Power类和Triangle类就是树上的叶节点,而Expression类和Term类则是树上的分支节点。因此我们只需要在分支节点上写计算的方法就可以了,在类图中的Expression类和Term类中都定义了计算的方法calc。而计算的实现主要又是依靠Variable类的multiplyArray方法来计算的。
4. 合并
之前讲了合并的两种方法。如果是采取边计算边合并的方法,那么在每个calc方法中写上相关合并的代码就可以了。如果是最后才合并,那么只需要对最后的Variable集合进行合并处理。
三、优化
这里的优化主要是指对最后表达式长度的优化。
(一)合并同类项优化
这是最自然最容易想到的优化方法,它的难点在于如何判断两个Variable是同类项,像第一次作业中只需要判断指数,而第二次作业就需要判断简单的三角函数,到了第三次作业,三角函数也有了递归结构,更难判断。
但仔细理一理思路,要判断两个Variable是否相等,首先要比较指数,如果指数相等,再比较三角函数数量,数量相等再依次比较每一个三角函数。那如何确保两个相同的三角函数恰好一一对应呢,这就需要根据一定的规则进行排序了,比如我们可以规定先比较sin再比较cos,三角函数类型相同就比较内部的表达式,而内部的表达式又要进行排序,这样的话整个比较过程也是一个递归向下的过程。这种递归的思路可能比较费劲,因此我们可以简化为字符串的对比,比如比较两个三角函数中的表达式,我们先将表达式按加减号拆分为字符串,将这些字符串排序组合成一个新的字符串,那么我们比较表达式就只需要比较字符串是否相等就可以了。如此我们就能够找出同类项,进行化简。
(二)三角函数化简
- 对于一些简单的三角函数,我们可以进行直接化简,比如\(sin(0)=0\)、\(cos(0)=1\)。
- 利用诱导公式进行化简:\(sin(-x)=-sin(x)\)、 \(cos(-x)=cos(x)\)。
- 下面就是一些比较高级的化简了,比如利用二倍角公式和\(sin^2(x)+cos^2(x)=1\)。当然从理论上说这样确实可以使表达式更简,但笔者认为这样性价比不高,而且算法复杂,就止步于第二种化简了。
(三)”无关紧要“的化简
- 开头如果是一个正的表达式会比一个负的表达式少输出一个符号,所以可以有意的将一个正的表达式放在最前面。
- 细心的同学可能会发现 \(x*x\) 比 \(x**2\) 短,但我认为这些都无关紧要,想化简就化简吧。
四、度量分析
(一)基础知识
1. 方法的衡量指标
- CogC(Cognitive complexity)认知复杂度:衡量一个方法的控制流程有多困难去理解。具有高认知复杂度的方法将难以维护。sonar要求复杂度要在15以下。计算的大致思路是统计方法中控制流程语句的个数。
- ev(G)(essential cyclomatic complexity):方法的基本圈复杂度,是用来衡量程序非结构化程度的,非结构成分降低了程序的质量,增加了代码的维护难度,使程序难于理解。因此,基本复杂度高意味着非结构化程度高,难以模块化和维护。实际上,消除了一个错误有时会引起其他的错误。
- iv(G)(Design complexity):模块设计复杂度,是用来衡量模块判定结构,即模块和其他模块的调用关系。软件模块设计复杂度高意味模块耦合度高,这将导致模块难于隔离、维护和复用。模块设计复杂度是从模块流程图中移去那些不包含调用子模块的判定和循环结构后得出的圈复杂度,因此模块设计复杂度不能大于圈复杂度,通常是远小于圈复杂度。
- v(G)(cyclomatic complexity):方法的圈复杂度,衡量判断模块的复杂度。数值越高说明独立路径越多,测试完备的难度越大。
2. 类的衡量指标
- OCavg(Average opearation complexity):平均操作复杂度。
- OCmax(Maximum operation complexity):最大操作复杂度。
- WMC(Weighted method complexity):加权方法复杂度。
(二)具体分析
1. 方法复杂度
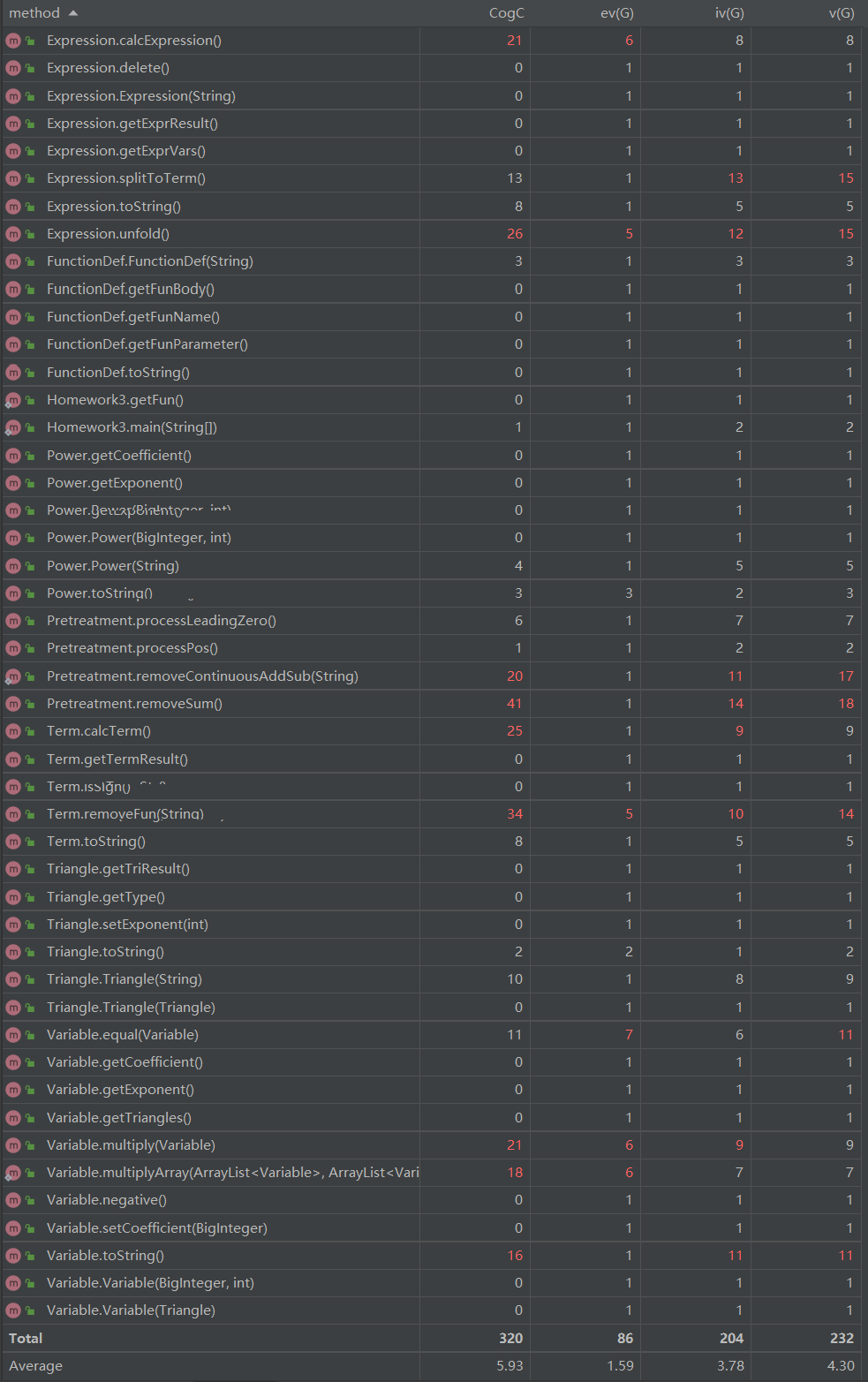
从图中可以看到有许多红色的数字,他们说明对应的方法复杂度较高。仔细的分析可以发现,这些复杂度较高的算法都与表达式的解析、计算、合并有关。在解析表达式时由于是纯字符串处理,所以结构较为复杂,不是自己写的想要看懂有难度。还有就是与计算相关的方法,因为涉及到合并同类项等等,方法复杂也可以理解。
CogC的平均值是5.93,就复杂度来说还能接受,只是个别方法今后还应用更为简便的方法去实现,比如利用Java自带的一些数据结构。
2. 类复杂度

从图中的数据来看:Expression、Pretreatment、Term、Variable类的复杂度较高,他们也正是整个解析的核心类,涉及较多的字符串等运算。如果要改进的话就是尽量让一个类实现功能相近的方法,而不是什么方法都往一个类里面写。
五、bug
其实我觉得bug可以分为两种,一种就是明显的逻辑错误,遇到出错的数据,调试一下就能发现bug的原因。另一种就是超出了你的设计,要么是你根本就没想到可能出现这个bug,要么是各种逻辑的奇妙组合成就了这个bug。
对于第一种bug,首先是读代码,找逻辑错误,然后就是构造数据调试。
对于第二种,可能真的要测试很多很强的数据才能发现,所以最好是自己写一个评测机。
(一)我遇到的bug
大致列一下我觉得比较有教育意义的bug:
- 前导零处理错误,纯属是处理逻辑写错了,它只判断后面的数字是不是非0,对于1000这种数字就会删掉中间的0,得到10。
- 对0的处理,其实很多程序都能处理十分复杂的数据,但就是会倒在及其简单的数据。比如我第一次作业强测都过了,结果一个简简单单
-+-00表达式我就错了,这明显是对最基本情况的处理不到位。 - 第一次作业遇到
(....)**0的时候我会直接把括号这一块换成1,但由于第二次作业有三角函数,所以按照之前的逻辑,sin(...)**0会变成sin1,这可以说是很经典的错误,没有好好考虑原来的函数,而是直接拿过来用。 - 这个bug算是有点难处理的,就是如果一边计算一边化简的话,系数为0,理应直接删掉这一项,但如果这个表达式就是
(x-x),你把这一项删了不就啥都没有了吗。所以就会出现(x-x)*x的输出是x的情况,因为前一个因子什么都没有,连0都没有,什么都没有乘x当然等于x啦。所以这个问题一定要注意,就是如果一串Variable算出来全都消去了,一定还是要留一项0。 - 考虑不周到的问题,虽然题中明确说了不会有
2**2的情况,但如果这是在sum里面,i**2把i代入不就会出现2**2吗。这一方面反映了我思考得不够严密,另一方面也说明我还是太局限于题目了。
(二)怎么找别人的bug
1. 构造特殊数据
特殊数据其实还是很好构造的。首先去找边界数据,比如0啊、很大的数啊。其次是根据形式化表达去构造较为复杂的数据,比如第三次作业可以自定义函数嵌套,那你就套个三四层,看他的程序错不错。其实自己写的时候就会想一些特殊数据,所以尽力去构造就完了,构造数据这种东西构造多了就有感觉了。
还有一点老师上课讲的我觉得很有道理,就是你测试过的数据不要测完就扔了,一定要记录一下。一方面是你测下一个同学可能还用得上,另一方面是你得保证你的程序改了之后不会导致之前的数据又错了,一定要保证之前测过的数据是你当前程序能通过数据的子集。
2. 用评测机
其实说实话,自己去构造数据覆盖性真的太不全面了,可能别人的bug就是错一些简单的地方,你自己构造数据就是想不到。这个时候评测机就特别重要了,尤其是一个数据全覆盖的评测机,能够完美的帮助你找到别人的bug。至于如何写评测机,接着往下看。
六、评测机
评测机无非包括三个部分:数据生成,获取程序的输出和标准输出,比较结果。数据生成绝对是最核心的部分,没有一个覆盖面全的数据集,评测机几乎就白写了。像我们这三次作业就是自己生成表达式,其实按着那个形式化表述写函数生成就可以了。关于如何获取输出和评测,我也在讨论区发过帖子:第二次作业数据生成和自动化评测思路分享。
七、心得体会
第一单元整个做下来我感觉是有一定难度的,要写出来简单,但要真正做到性能好、bug少可太难了。这三次作业其实很注重程序的架构,架构好就可以避免反复的重构,增量开发也更容易。我也感受到了计算机学院的同学们对找bug(学习)的热情,讨论区确实是有很多高质量的帖子供我们去学习,有时候在没思路的时候真的可以去看看同学们的想法。
回过头来看,我的一些处理后来想起来都觉得不妥,有的时候改着改着就越改越乱,所以一开始就把情况考虑周到太重要了。以后我也要积极的去写代码,不要被ddl推着走,尽量去写评测机,对自己的代码能力也是很好的锻炼。
