

GPU 内存类型-性能比较
【转】GPU Memory Types – Performance Comparison
原文地址:http://www.microway.com/hpc-tech-tips/gpu-memory-types-performance-comparison/
This post is Topic #3 (part 1) in our series Parallel Code: Maximizing your Performance Potential.
CUDA devices have several different memory spaces: Global, local, texture, constant, shared and register memory. Each type of memory on the device has its advantages and disadvantages. Incorrectly making use of the available memory in your application can can rob you of the performance you desire. With so many different types of memory, how can you be certain you’re using the correct type? Well, it is no easy task.
In terms of speed, if all the various types of device memory were to race here’s how the race would turn out:
- 1st place: Register file
- 2nd place: Shared Memory
- 3rd place: Constant Memory
- 4th: Texture Memory
- Tie for last place: Local Memory and Global Memory
Looking at the above list, it would seem that to have the best performance we’d only want to use register file, shared memory, and constant memory. In a simple world I’d agree with that statement. However, there are many more factors associated with choosing the best form of memory for various portions of your application.
Memory Features
The only two types of memory that actually reside on the GPU chip are register and shared memory. Local, Global, Constant, and Texture memory all reside off chip. Local, Constant, and Texture are all cached.
While it would seem that the fastest memory is the best, the other two characteristics of the memory that dictate how that type of memory should be utilized are the scope and lifetime of the memory:
- Data stored in register memory is visible only to the thread that wrote it and lasts only for the lifetime of that thread.
- Local memory has the same scope rules as register memory, but performs slower.
- Data stored in shared memory is visible to all threads within that block and lasts for the duration of the block. This is invaluable because this type of memory allows for threads to communicate and share data between one another.
- Data stored in global memory is visible to all threads within the application (including the host), and lasts for the duration of the host allocation.
- Constant and texture memory won’t be used here because they are beneficial for only very specific types of applications. Constant memory is used for data that will not change over the course of a kernel execution and is read only. Using constant rather than global memory can reduce the required memory bandwidth, however, this performance gain can only be realized when a warp of threads read the same location.Similar to constant memory, texture memory is another variety of read-only memory on the device. When all reads in a warp are physically adjacent, using texture memory can reduce memory traffic and increase performance compared to global memory.
How to Choose Memory Type
Knowing how and when to use each type of memory goes a long way towards optimizing the performance of your application. More often than not, it is best to make use of shared memory due to the fact that threads within the same block utilizing shared memory can communicate. Combined with its excellent performance, this makes shared memory a good ‘all around’ choice when used properly. In some cases however, it may be better to make use of the other types of available memory.
Shared Memory
A common problem arises when memory is shared: with all memory available to all threads, there will be many threads accessing the data simultaneously. To alleviate this potential bottleneck, shared memory is divided into 32 logical banks. Successive sections of memory are assigned to successive banks (see Figure 1).
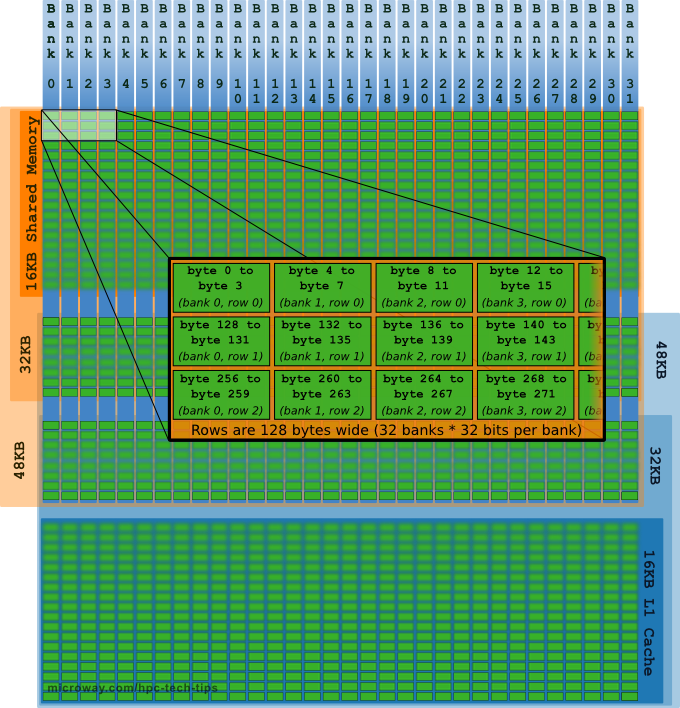
Figure 1: Shared Memory and L1 Cache
Some facts about shared memory:
- The total size of shared memory may be set to 16KB, 32KB or 48KB (with the remaining amount automatically used for L1 Cache) as shown in Figure 1. Shared memory defaults to 48KB (with 16KB remaining for L1 Cache).
- With the Kepler architecture, each bank has a bandwidth of 64 bits per clock cycle. The older Fermi architecture was clocked differently, but effectively offered half this bandwidth.
- There are 32 threads in a warp and exactly 32 shared memory banks. Because each bank services only one request per cycle, multiple simultaneous accesses to the same bank will result in what is known as a bank conflict. This will be discussed further in the next post.
- GPUs section memory banks into 32-bit words (4 bytes). Kepler architecture introduced the option to increase banks to 8 bytes using
cudaDeviceSetSharedMemConfig(cudaSharedMemBankSizeEightByte). This can help avoid bank conflicts when accessing double precision data.
When there are no bank conflicts present, shared memory performance is comparable to register memory. Use it properly and shared memory will be lightning fast.
Register Memory
In most cases, accessing a register consumes zero clock cycles per instruction. However, delays can occur due to read after write dependencies and bank conflicts. The latency of read after write dependencies is roughly 24 clock cycles. For newer CUDA devices that have 32 cores per multiprocessor, it may take up to 768 threads to completely hide latency.
In addition to the read after write latency, register pressure can severely detract from the performance of the application. Register pressure occurs when there are not enough registers available for a given task. When this occurs, the data is “spilled over” using local memory. See the following posts for further details.
Local Memory
Local memory is not a physical type of memory, but an abstraction of global memory. Its scope is local to the thread and it resides off-chip, which makes it as expensive to access as global memory. Local memory is used only to hold automatic variables. The compiler makes use of local memory when it determines that there is not enough register space to hold the variable. Automatic variables that are large structures or arrays are also typically placed in local memory.
Recommendation
All in all, for most applications my recommendation is definitely to try to make use of shared memory wherever possible. It is the most versatile and easy-to-use type of memory. Shared memory allows communication between threads within a warp which can make optimizing code much easier for beginner to intermediate programmers. The other types of memory all have their place in CUDA applications, but for the general case, shared memory is the way to go.
Conclusion
So now that you know a little bit about each of the various types of memory available to you in your GPU applications, you’re ready to learn how to efficiently use them. The next post will discuss how you can optimize the use of the various types of memory throughout your application.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号