
原文地址:http://www.cnblogs.com/KID-XiaoYuan/p/7228669.html
单一变量的线性回归
让我们依然以房屋为例,如果输入的样本特征是房子的尺寸,我们需要研究房屋尺寸和房屋价格之间的关系,假设我们的回归模型训练集如下

其中我们用
m表示训练集实例中的实例数量,
x代表特征(输入)变量,
y代表目标变量
(x,y)代表实例
根据线性回归模型hΘ(x) = Θ0+Θ1*x1 (Θ是模型参数)
需要找出Θ0,Θ1,使得平均误差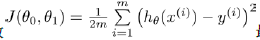 最小。J(Θ0,Θ1)称为代价函数。
最小。J(Θ0,Θ1)称为代价函数。
根据不同的特征值,我们按照如下步骤进行迭代更新,以此来得到不同的Θ:
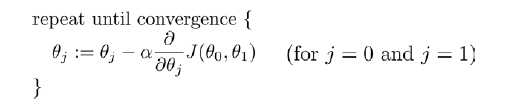
执行过程中,同步更新Θ0,Θ1
其中的α是学习速率,也就是所谓的迈出的步幅,一个合适的步幅有助于函数更快的收敛,每次迭代的过程实质就是对J(Θ)求偏导数,得到当前点要往下一步迈出的方向,之后根据α进行更新到新的点。如果步幅过大容易导致迭代过程发散,过小的情况下容易导致收敛过于慢。
在上个式子中,我们吧J(Θ)带入,然后我们可以得到新的算法表达式:
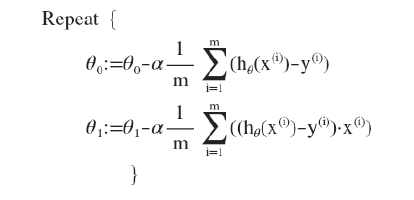
以上只是对特殊情况,即一元的线性回归,那么在更通常的情况下,我们所要解决的问题是多元的现行回归。
多元线性回归:
现在假设有以下特征向量:
| x1 | x2 | x3 | x4 | y |
| 2014 | 5 | 1 | 45 | 460 |
| 1416 | 3 | 2 | 40 | 232 |
| …… | …… | …… | …… | …… |
| x1(m) | x2(m) | x3(m) | x4(m) | y(m) |
对于上述学习资料,我们用
x(i)表示第i组训练样本的特征向量,如x(2)=[1416, 3,2,40]表示第二组特征向量
xj(i)表示第i组训练样本的第j个特征。
多元线性回归假的设函数
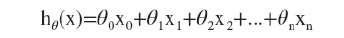
此时模型中的参数是一个n+1维的向量,任意一个训练实例也是,特征矩阵是一个m*(n+1)维的。此时公式可以化简为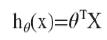 ,其中θT是转置矩阵。
,其中θT是转置矩阵。
同理我们可以写出它的代价函数,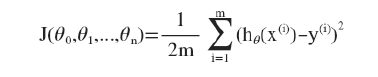 (以后用J(θ)简化表示)
(以后用J(θ)简化表示)
同理,我们可以得出它的梯度下降算法:

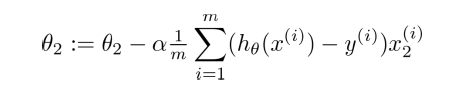
开始随机选择一系列的参数值,计算所有的预测结果,再给所有的参数一个新的值,直到函数收敛。
梯度下降算法的优化与数学分析:
在面对数值差距过大的不同特征值时,比如x1大多在1000左右,x2,x3在10左右,那么这时如果我们之间进行收敛,它的等高图中看我们的收敛过程如图所示:
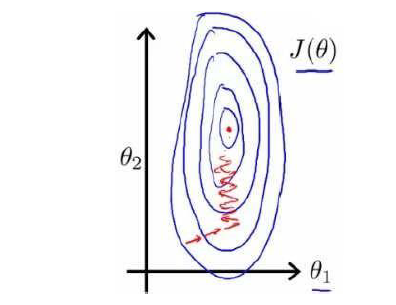
这时容易导致步幅过大而难以收敛,解决方法是尽可能让xn尽可能的接近,我们把x1 x2除以一个合适的数值,使得他们的范围都在0-1左右,这时图像会变成下图所示
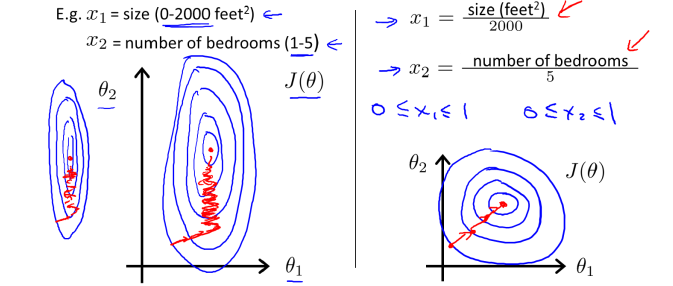
简单的说,处理方法通常可以表示为

学习率的选择,选择一个合适的学习率有利于我们更快的让θ收敛

有时候,所给出的数据并不利于我们使用线性回归,这时候,我们就需要对特征值进行修改来适应我们的数据,比如x1是房屋临街的宽度x2是房屋的深度,x = x1 * x2 这时候我们需要一个二次方模型或者三次方模型来解决这些问题
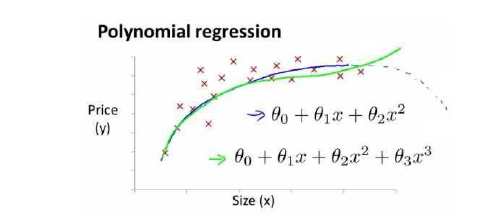
那么我们通常需要观察数据,通过函数特性x2 = x2^2 x3 = x3^3,从而将函数转化成我们可以解决的线性回归模型。
根据图形的特性,我们还可以修改h(θ)x 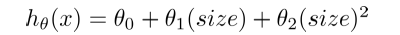
或者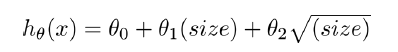 来解决问题。
来解决问题。
现在,我们再通过数学角度来看待这个问题,实际上我们可以直接算出收敛后的θ值,这个方法被称为正规方程法,例如我们假设训练集特征矩阵为x(包含了x0 = 1)并且我们的训练集特征结果为向量y,则利用正规方程我们可以计算出向量θ: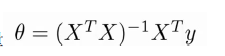 ,在Octcave中,我们可以用如下方法计算得出:pinv(x'*x)*x'*y 值得注明的是,对于不可逆的矩阵,(通常因为特征向量之间不独立),正规方程法是不能解决的。而且,对于过大的数据量(>10000),正规方程法因为矩阵过大而难以计算,所以此时我们会更多的用梯度下降法。
,在Octcave中,我们可以用如下方法计算得出:pinv(x'*x)*x'*y 值得注明的是,对于不可逆的矩阵,(通常因为特征向量之间不独立),正规方程法是不能解决的。而且,对于过大的数据量(>10000),正规方程法因为矩阵过大而难以计算,所以此时我们会更多的用梯度下降法。
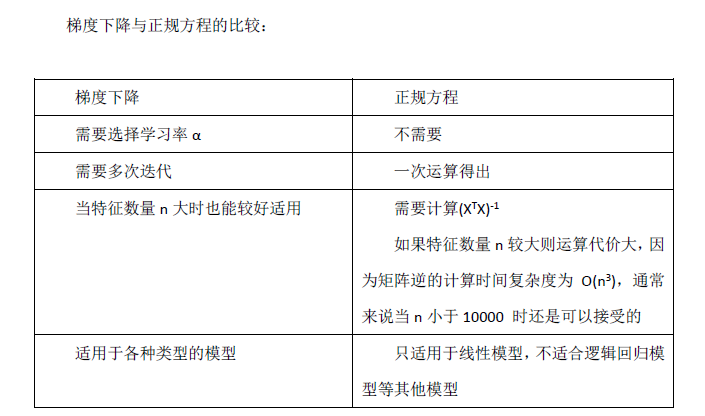
正规方程的不可逆性: 是不可逆的。
是不可逆的。
接下来会讨论如何同octave设计实践该算法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号